") 使用NVIDIA TAO工具包和Appen實現AI模型微調
使用NVIDIA TAO工具包和Appen實現AI模型微調
從頭開始構建人工智能模型需要大量的數據、時間、金錢和專業(yè)知識。這與在人工智能領域取得成功的條件不符:快速上市,以及快速發(fā)展和定制解決方案的能力。 NVIDIA TAO 是一個人工智能模型調整框架,與從頭開始的培訓相比,它可以讓您利用生產質量、預培訓的人工智能模型,并在很短的時間內對其進行微調。
要進一步微調這些模型,或確認模型的精度,需要額外的高質量訓練數據。 Appen 是 TAO 的數據注釋合作伙伴,如果您沒有合適的可用數據,它可以訪問高質量的數據集和服務,為您的數據添加標簽和注釋,以滿足您的獨特需求。
在帖子中,我將向你展示如何使用 NVIDIA TAO 工具包 一個基于 CLI 的NVIDIA TAO 框架的解決方案,以及 AppEN 的數據標記平臺,以簡化整個培訓過程,并為特定用例創(chuàng)建高度定制的模型。
在您的團隊確定了要使用 ML 解決的業(yè)務問題后,您可以從 NVIDIA 收集的計算機視覺和對話人工智能中的預訓練人工智能模型中進行選擇。計算機視覺模型可以包括人臉檢測模型、文本識別、分割等。然后,您可以應用 TAO 工具包來構建、培訓、測試和部署您的解決方案。
為了加快數據收集和擴充過程,您現在可以使用 Appen 數據注釋平臺為您的用例創(chuàng)建正確的培訓數據。該強大的平臺使您能夠訪問 Appen 全球超過 100 萬名熟練的注釋員,他們來自 170 多個國家,講 235 種語言。 Appen 的數據注釋平臺 和專業(yè)知識還為您提供了其他資源:
高質量數據集(用于需要數據時)
全球采購的人工標簽機,用于為未標記的數據添加注釋
一個易于使用的平臺,您可以在其中啟動注釋作業(yè)并監(jiān)控關鍵指標
質量保證檢查和數據安全控制
有了干凈、高質量的數據,您可以調整 經過訓練的 NVIDIA 模型以滿足您的需求,并進行修剪和再培訓,以達到所需的性能水平。
如何使用 Appen 的平臺準備數據
如果您還沒有用于訓練模型的數據,您可以自己收集這些數據,也可以求助于 Appen ,找到適合您的用例的源數據集。 Appen 數據注釋平臺( ADAP )可使用多種格式:
音頻(. wav ,. mp3 )
圖像(. jpeg ,. png )
文本(. txt )
視頻(網址)
完成數據收集階段后,除非您計劃與 Appen 合作以滿足數據收集需求,否則您可以使用 Appen 的平臺快速標記您收集的數據。每行數據批注都需要 Appen 平臺許可證和預算。
在此基礎上,完成以下步驟,部署一個特別適合您需求的模型。在本文中,假設您正在為對象檢測模型注釋圖像。
準備好你的數據
首先,將圖像數據加載到網絡可訪問的位置:云或 ADAP 可以訪問的位置,例如私有 Amazon S3 存儲桶。
接下來,用兩列結構輸入 CSV 文件。第一列包含文件名,第二列包含圖像的 URL 。您可以通過以下三種方式之一提供 URL :
對數據使用公開可用的 URL 。
使用預先簽名的 URL 。
使用 Appen 的安全數據訪問工具,您可以使用該工具將數據庫安全地連接到平臺; Appen 僅在需要時訪問您的數據。
第二列包含設備上的本地文件名。圖 1 顯示了 CSV 文件的外觀。
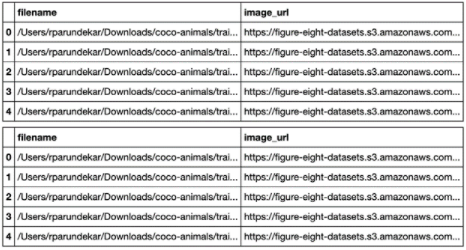
圖 1 。用于 ADAP 中數據上傳的 CSV 結構
創(chuàng)建作業(yè)并上載數據
如果尚未登錄,可以 創(chuàng)建 ADAP 帳戶 并登錄。在運行新作業(yè)之前,您必須擁有平臺的活動許可證。要了解更多有關計劃和定價的信息, 聯系 Appen 。
登錄后,在Jobs下選擇創(chuàng)造就業(yè)機會。
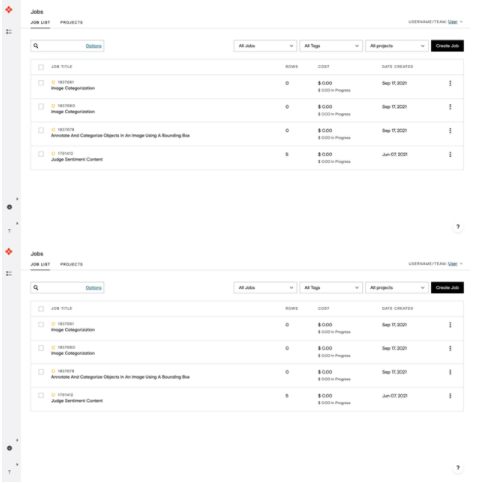
圖 2 。 ADAP 工作概述頁面
選擇最適合工作的模板(情緒分析、搜索相關性等)。對于本例,請選擇Image Annotation。
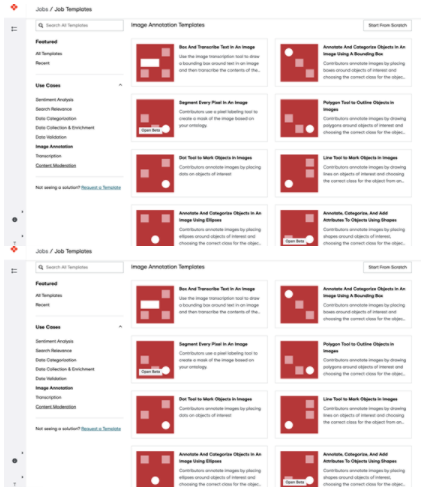
圖 3 。 ADAP 作業(yè)模板頁面–圖像注釋
在Image Annotation下,選擇使用邊界框對圖像中的對象進行注釋和分類。將 CSV 文件拖放到Upload選項卡中,上傳 CSV 文件。
設計你的工作
為 Appen 的 100 多萬名數據標簽員提供指導,說明他們應該尋找什么,以及他們應該知道的任何要求。該模板提供了一個簡單的工作設計來幫助您開始。
接下來,選擇管理圖像注釋本體,在這里定義應該檢測的類。更新說明,以提供有關用例的更多上下文,并描述注釋者應如何識別和標記圖像中的對象。您可以預覽作業(yè),并查看注釋員將如何查看它。
最后,創(chuàng)建測試問題來測量和跟蹤貼標機的性能。
啟動作業(yè)
在平臺上正式啟動注釋作業(yè)之前,先進行測試運行。在你開始工作后, Appen 的全球數據標簽員會根據你的規(guī)格標注你的數據。
班長
實時監(jiān)控注釋的準確率。在工作設計、試題或注釋員等領域根據需要進行調整。
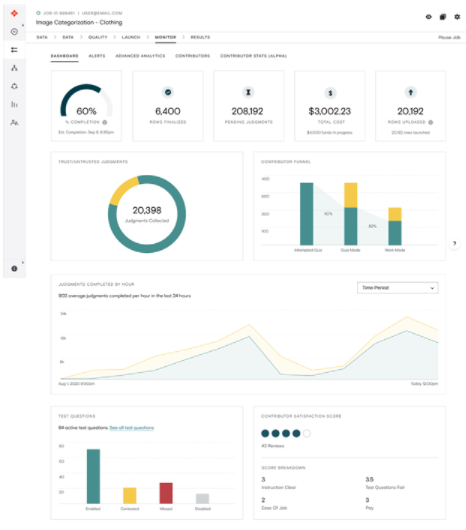
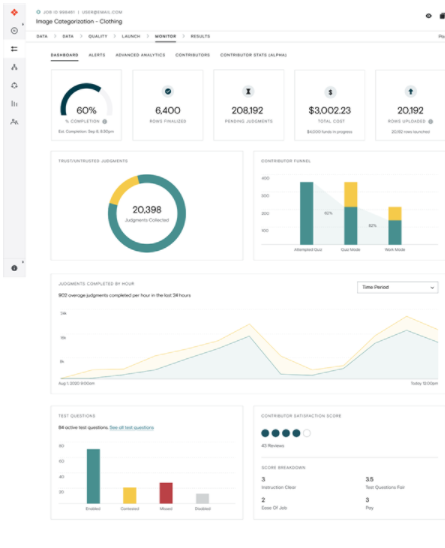
圖 8 。 ADAP 注釋進度監(jiān)控頁面
后果
選擇Download、Full下載標簽數據輸出的報告。
將輸出轉換為 KITTI 格式
從這里開始,您需要一個腳本來將標記的數據轉換為可供 TAO 工具包使用的格式,例如 KITTI 格式。
使用上一步的輸出,可以使用以下部分將標記的數據轉換為類似 Pascal Visual Object Class ( VOC )格式的格式。
訓練你的模特
用 Appen 注釋的數據現在可以用于訓練對象檢測模型。 TAO 工具包允許您根據數據調整流行的網絡架構和主干,從而訓練、微調、刪減和導出高度優(yōu)化和精確的人工智能模型,以供部署。對于本例,您可以選擇 YOLOV3 對象檢測模型,如下例所示:
$ wget --content-disposition https://api.ngc.nvidia.com/v2/resources/nvidia/tlt_cv_samples/versions/v1.0.2/zip -O tlt_cv_samples_v1.0.2.zip $ unzip -u tlt_cv_samples_v1.0.2.zip -d ./tlt_cv_samples_v1.0.2 && rm -rf tlt_cv_samples_v1.0.2.zip && cd ./tlt_cv_samples_v1.0.2
下載筆記本示例后,您可以使用以下命令啟動筆記本:
$ jupyter notebook --ip 0.0.0.0 --port 8888 --allow-root
在 localhost 上打開 internet 瀏覽器并打開以下 URL :
http://0.0.0.0:8888
因為您正在創(chuàng)建一個 YOLOv3 模型,所以打開 yolo _ v3 / yolo _ v3 。 ipynb 筆記本。按照筆記本上的說明訓練模型。
根據結果,微調模型,直到達到度量目標。如果需要,您可以在此階段創(chuàng)建自己的主動學習循環(huán)。根據置信度或其他選擇指標,使用 CSV 文件方法對數據進行優(yōu)先級排序,如前面步驟所述。您還可以提前加載數據(包括輸入和預測),這樣 Appen 的注釋員可以在模型經過培訓后驗證模型,并使用我們的領域專家和 open crowd 查看預測。
Pro tip:使用 Appen 解決方案 Workflows 輕松構建和自動化多步驟數據注釋項目。
迭代
隨著您不斷提高模型性能, Appen 可以在后續(xù)的模型培訓中進一步幫助您進行數據收集和注釋。為了避免模型漂移或適應不斷變化的業(yè)務需求,請定期對模型進行再培訓。
結論
NVIDIATAO 工具包與 Appen 的數據平臺相結合,使您能夠訓練、微調和優(yōu)化預訓練模型,以更快地啟動人工智能解決方案。在不犧牲質量的情況下,將開發(fā)時間縮短十倍。在NVIDIA 和 Appen 的綜合專業(yè)知識和工具的幫助下,您將滿懷信心地推出人工智能。
關于作者
Titus Capilnean 領導 Appen 的營銷傳播,推動負責任、包容的人工智能,并與全球公司進行培訓數據對話。他擁有 2016 年的機器學習證書、霍爾特國際商學院( Hult International Business School )的行政 MBA 學位,并在 Forbes 上發(fā)表了幾篇關于人工智能的評論文章。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
4949瀏覽量
102826 -
人工智能
+關注
關注
1791文章
46896瀏覽量
237669
發(fā)布評論請先 登錄
相關推薦
基于EasyGo Vs工具包和Nl veristand軟件進行的永磁同步電機實時仿真
基于NVIDIA TAO工具包訓練汽車目標識別模型
FPGA仿真工具包軟件EasyGo Vs Addon介紹

采用德州儀器 (TI) 工具包進行模擬前端設計應用說明

NVIDIA RTX AI套件簡化AI驅動的應用開發(fā)
NVIDIA AI Foundry 為全球企業(yè)打造自定義 Llama 3.1 生成式 AI 模型

AI大模型與AI框架的關系
大模型為什么要微調?大模型微調的原理
MediaTek與NVIDIA TAO加速物聯網邊緣AI應用發(fā)展
Edge Impulse發(fā)布新工具,助 NVIDIA 模型大規(guī)模部署
QE for Motor V1.3.0:汽車開發(fā)輔助工具解決方案工具包
NVIDIA TAO 5.2版本發(fā)布
怎樣使用NVIDIA TAO為數萬億臺設備開發(fā)和優(yōu)化視覺AI模型呢?
用上這個工具包,大模型推理性能加速達40倍





 工商網監(jiān)
工商網監(jiān)
評論