 世界最小嵌入式AI超級計算機Jetson Xavier NX
世界最小嵌入式AI超級計算機Jetson Xavier NX
NVIDIA 發布了Jetson Xavier NX,這是世界上最小、最先進的嵌入式 AI 超級計算機,用于自主機器人和邊緣計算設備。Jetson Xavier NX 能夠在緊湊的 70x45mm 外形尺寸中部署服務器級性能,在 15W 功率下提供高達 21 TOPS 的計算,或在 10W 下提供高達 14 TOPS 的計算。Jetson Xavier NX 模塊(圖 1)與 Jetson Nano 引腳兼容,并基于 NVIDIA 的 Xavier SoC 的低功耗版本,該版本在邊緣 SoC 中領先于最近的MLPerf Inference 0.5結果,為部署要求苛刻的基于 AI 的邊緣的工作負載可能會受到尺寸、重量、功率和成本等因素的限制。
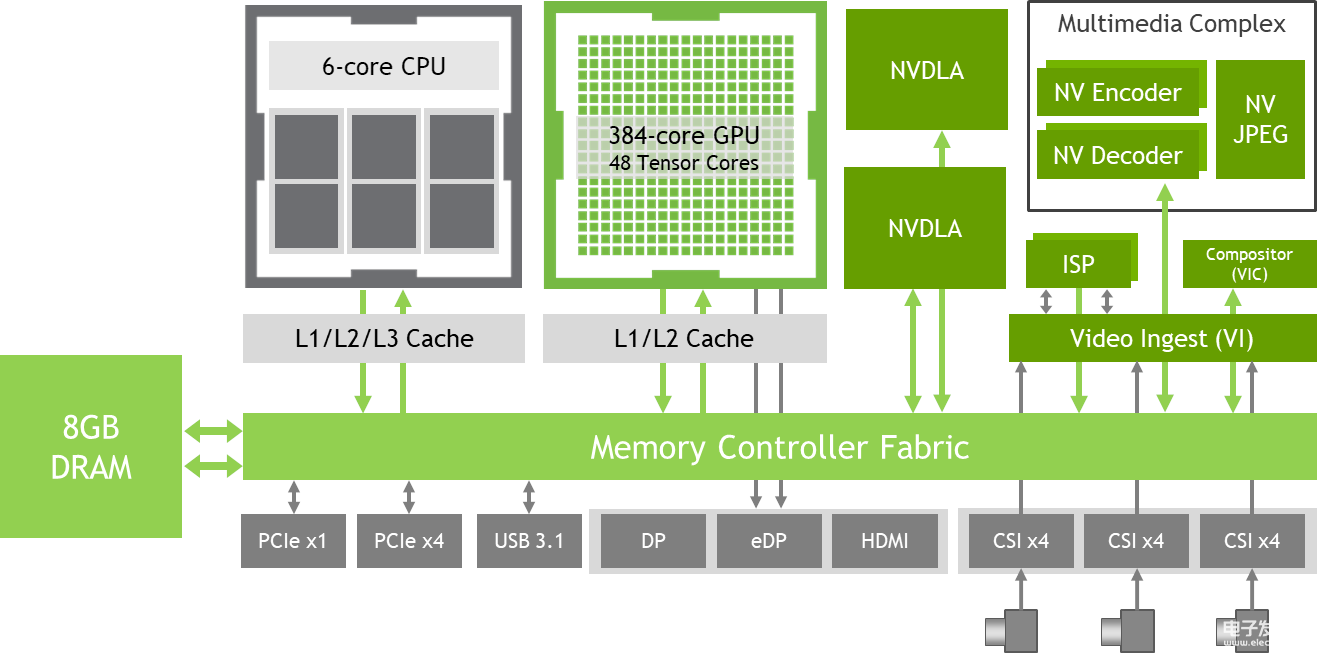
圖 2:Jetson Xavier NX 處理器引擎的框圖,包括高速 I/O 和內存結構。
如圖 2 所示,Jetson Xavier NX 包括一個集成的 384 核 NVIDIA Volta GPU,具有 48 個 Tensor 核心、6 核 NVIDIA Carmel ARMv8.2 64 位 CPU、8GB 128 位 LPDDR4x、雙 NVIDIA 深度學習加速器 (NVDLA)引擎、4K 視頻編碼器和解碼器、用于多達 6 個同步高分辨率傳感器流的專用攝像頭攝取、PCIe Gen 3 擴展、雙 DisplayPort/HDMI 4K 顯示器、USB 3.1 和 GPIO,包括 SPI、I2C、I2S、CAN 總線和UART。請參閱下表 1,了解功能列表和Jetson Xavier NX 模塊數據表,了解完整規格。共享內存結構允許處理器自由共享內存,而不會產生額外的內存副本(稱為 ZeroCopy),從而有效地提高了系統的帶寬利用率和吞吐量。

表 1:Jetson Xavier NX 計算模塊特性和功能
* CPU 最大工作頻率在 4/6 核模式下為 1400MHz,或在雙核模式下為 1900MHz
? 最大并發流數達到總吞吐量。支持的視頻編解碼器:H.265、H.264、VP9有關特定編解碼器和配置文件規范,
請參閱Jetson Xavier NX 模塊數據表。
?? MIPI CSI-2,D-PHY V1.2(每通道 2.5Gb/s,總計高達 30Gbps)。
? PCIe 1×1 僅支持根端口,1×1/2/4 支持根端口或端點模式
^ 工作溫度范圍,Xavier SoC 結溫 (Tj)
Jetson Xavier NX 得到 NVIDIA 完整的 CUDA-X 軟件堆棧和用于 AI 開發的JetPack SDK的支持,除了實時計算機視覺、加速圖形和豐富的多媒體應用程序之外,還能在多個高分辨率傳感器流上同時運行流行的機器學習框架和復雜的 DNN在完整的桌面 Linux 環境中。Jetson 與 NVIDIA 的 AI 加速計算平臺的兼容性使得開發和云與邊緣之間的無縫遷移變得容易。
Jetson Xavier NX 模塊將于 2020 年 3 月以 399 美元的批量供貨,嵌入式設計人員可以參考可供下載的設計資料,包括Jetson Xavier NX 設計指南,為 Jetson Xavier NX 模塊創建生產設備和系統。與 Jetson Nano 的引腳兼容性允許共享設計和對 Jetson Xavier NX 的直接技術插入升級。Jetson 生態系統的硬件設計合作伙伴除了提供現成的載體、傳感器和配件外,還能夠提供定制設計服務和系統集成。
軟件開發人員現在可以開始為 Jetson Xavier NX 構建 AI 應用程序,方法是使用 Jetson AGX Xavier 開發工具包,并將設備配置補丁應用到 JetPack,使設備表現得像 Jetson Xavier NX。除了設置整個系統的核心時鐘頻率和電壓外,它還將通過軟件改變可用的 CPU 和 GPU 核心的數量。該補丁是完全可逆的,可用于在硬件可用之前估算 Jetson Xavier NX 的性能。
Jetson Xavier NX 定義了 10 和 15W 的默認功率模式,根據活動模式實現 14 到 21 TOPS 的峰值性能。用于管理電源配置文件的 nvpmodel 工具調整 CPU、GPU、內存控制器和其他 SoC 時鐘的最大時鐘頻率,以及在線 CPU 集群的數量——這些設置顯示在表 2 中,用于預定義的 10W 和Jetson Xavier NX 的 15W 模式。CPU 布置在三個集群中,每個集群有 2 個內核,在 4/6 核模式下的最高工作頻率為 1400MHz,在雙核模式下最高可達 1900MHz,適用于可能需要更多單線程與多線程的應用程序表現。
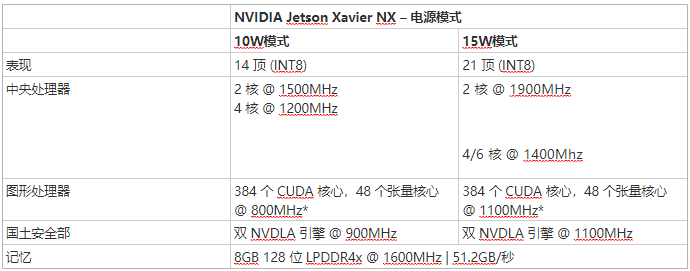
表 2:Jetson Xavier NX 在 10W 和 15W 功率模式下的最大工作頻率和核心配置。
* 使用 NVDLA 時,GPU 最高工作頻率為 600MHz(10W 模式)和 1000MHz(15W 模式)
根據工作負載,動態電壓和頻率縮放 (DVFS) 調節器在運行時將頻率縮放到活動 nvpmodel 定義的最大限制,因此在空閑時降低功耗并取決于處理器利用率。nvpmodel 工具還可以根據應用要求和 TDP 輕松創建和自定義新的電源模式。可以編輯電源配置文件并將其添加到 /etc/nvpmodel.conf 配置文件中,并且在 Ubuntu 狀態欄中添加了一個 GUI 小部件,以便在運行時輕松管理和切換電源模式。
深度學習推理基準
NVIDIA 還宣布,它在MLPerf Inference 0.5基準測試的 5 個類別中的 4 個類別中奪冠,其中 Jetson AGX Xavier 是邊緣計算 SoC 的領導者,包括所有基于視覺的任務:使用 Mobilenet 進行圖像分類和ResNet-50,以及使用 SSD-Mobilenet 和 SSD-ResNet 進行對象檢測。在 MLPerf 定義的所有五項推理測試中,NVIDIA GPU 是十種競爭芯片架構中唯一提交結果的一種。
為了參考 Jetson 系列成員之間的可擴展性,我們還在流行的 DNN 模型上測量了 Jetson Nano、Jetson TX2、Jetson Xavier NX 和 Jetson AGX Xavier 的推理性能,用于圖像分類、對象檢測、姿勢估計、分割等。這些結果(如下圖 3 所示)是使用 JetPack 和 NVIDIA 的 TensorRT 推理加速器庫運行的,該庫可優化網絡以實現實時性能,這些網絡在 TensorFlow、PyTorch、Caffe、MXNet 等流行的機器學習框架中進行了訓練。
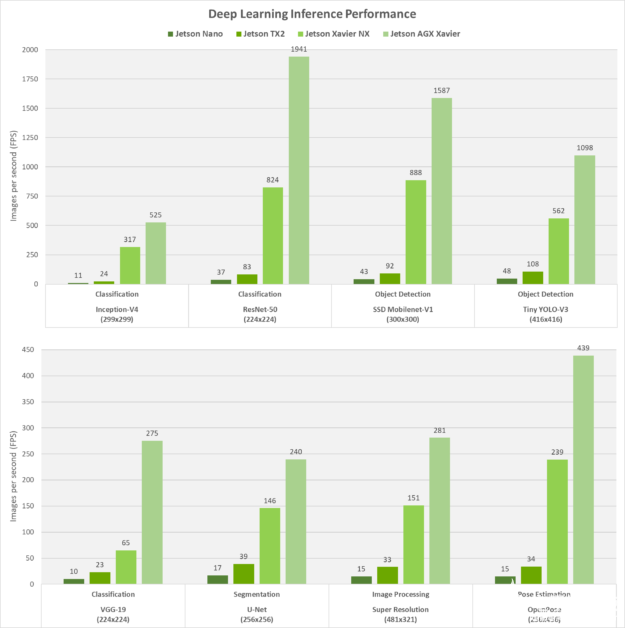
圖 3. Jetson 系列中使用 TensorRT 的各種基于視覺的 DNN 模型的推理性能。
Jetson Xavier NX 的性能比 Jetson TX2 高出多達 10 倍,功率相同,占用空間減少 25%。在這些基準測試中,每個平臺都以最高性能運行(Jetson AGX Xavier 為 MAX-N 模式,Xavier NX 和 TX2 為 15W,Nano 為 10W)。最大吞吐量是在批處理大小不超過 16 毫秒延遲閾值的情況下獲得的,否則對于平臺超過此延遲閾值的網絡,批處理大小為 1。這種方法在實時應用程序的確定性低延遲要求和多流用例場景的最大性能之間提供了平衡。
在 Jetson Xavier NX 和 Jetson AGX Xavier 上,NVDLA 引擎和 GPU 以 INT8 精度同時運行,而在 Jetson Nano 和 Jetson TX2 上,GPU 以 FP16 精度運行。Jetson Xavier NX 中帶有 Tensor Cores 的 Volta 架構 GPU 能夠進行高達 12.3 TOPS 的計算,而該模塊的 DLA 引擎每個可產生高達 4.5 TOPS。
除了使用 TensorRT 運行神經網絡之外,ML 框架還可以通過 CUDA 和 cuDNN 本地安裝在 Jetson 上,包括 TensorFlow、PyTorch、Caffe/Caffe2、MXNet、Keras 等。除了 AWS Greengrass 等物聯網框架和 Docker 和 Kubernetes 等容器引擎之外, Jetson Zoo還包括預構建的安裝程序和構建說明。
Jetson Xavier NX 為部署下一代自主系統和智能邊緣設備開辟了新的機會,這些設備需要高性能 AI 和復雜的 DNN 在小尺寸、低功耗的足跡中——想想移動機器人、無人機、智能相機、便攜式醫療設備、嵌入式物聯網系統等等。支持 CUDA-X 的 NVIDIA JetPack SDK 提供了完整的工具來開發尖端的 AI 解決方案,并以世界領先的性能在云和邊緣之間擴展您的應用程序。
關于作者
Dustin 是 NVIDIA Jetson 團隊的一名開發人員推廣員。Dustin 擁有機器人技術和嵌入式系統方面的背景,喜歡在社區中提供幫助并與 Jetson 合作開展項目。
審核編輯:郭婷
-
機器人
+關注
關注
210文章
28231瀏覽量
206614 -
AI
+關注
關注
87文章
30239瀏覽量
268474 -
無人機
+關注
關注
228文章
10356瀏覽量
179693 -
嵌入式AI
+關注
關注
0文章
34瀏覽量
814
發布評論請先 登錄
相關推薦
NVIDIA 以太網加速 xAI 構建的全球最大 AI 超級計算機

丹麥推出首臺AI超級計算機Gefion
NVIDIA助力丹麥發布首臺AI超級計算機
ARMxy嵌入式計算機在機器視覺中的卓越表現

ARMxy ARM嵌入式計算機支持Ubuntu OS快速部署AIoT解決方案

ARMxy ARM嵌入式計算機搭載 1 TOPS NPU支持深度學習
如何選擇嵌入式主板或單板計算機

富士通使用富岳超級計算機訓練LLM
微軟和OpenAI計劃投資1000億美元建造“星際之門”AI超級計算機
人形機器人主板:jetson orin nx核心模塊與SOM-7583核心模塊結合在一塊主板上

諾和諾德基金會將聯手英偉達打造丹麥AI超級計算機
NVIDIA Jetson為嵌入式計算領域探索AI可能


最適合 AI 應用的計算機視覺類型是什么?





 工商網監
工商網監
評論