") 使用NVIDIA Triton推理服務(wù)器簡(jiǎn)化邊緣AI模型部署
使用NVIDIA Triton推理服務(wù)器簡(jiǎn)化邊緣AI模型部署
人工智能機(jī)器學(xué)習(xí)( ML )和深度學(xué)習(xí)( DL )正在成為解決機(jī)器人、零售、醫(yī)療保健、工業(yè)等領(lǐng)域各種計(jì)算問(wèn)題的有效工具。對(duì)低延遲、實(shí)時(shí)響應(yīng)和隱私的需求使運(yùn)行 AI 應(yīng)用程序處于邊緣。
然而,在邊緣的應(yīng)用程序和服務(wù)中部署 AI 模型對(duì)基礎(chǔ)設(shè)施和運(yùn)營(yíng)團(tuán)隊(duì)來(lái)說(shuō)可能是一項(xiàng)挑戰(zhàn)。不同的框架、端到端延遲要求以及缺乏標(biāo)準(zhǔn)化實(shí)施等因素可能會(huì)使 AI 部署具有挑戰(zhàn)性。在這篇文章中,我們將探討如何應(yīng)對(duì)這些挑戰(zhàn),并在邊緣生產(chǎn)中部署 AI 模型。
以下是部署推理模型的最常見(jiàn)挑戰(zhàn):
多模型框架:數(shù)據(jù)科學(xué)家和研究人員使用不同的人工智能和深度學(xué)習(xí)框架,如 TensorFlow 、 PyTorch 、 TensorRT 、 ONNX 運(yùn)行時(shí)或純 Python 來(lái)構(gòu)建模型。這些框架中的每一個(gè)都需要一個(gè)執(zhí)行后端來(lái)在生產(chǎn)環(huán)境中運(yùn)行模型。同時(shí)管理多個(gè)框架后端可能成本高昂,并導(dǎo)致可伸縮性和維護(hù)問(wèn)題。
不同的推理查詢類型:邊緣推理服務(wù)需要處理多個(gè)同時(shí)查詢、不同類型的查詢,如實(shí)時(shí)在線預(yù)測(cè)、流式數(shù)據(jù)和多個(gè)模型的復(fù)雜管道。每一項(xiàng)都需要特殊的推理處理。
不斷發(fā)展的模型:在這個(gè)不斷變化的世界中,人工智能模型不斷地根據(jù)新數(shù)據(jù)和新算法進(jìn)行重新訓(xùn)練和更新。生產(chǎn)中的型號(hào)必須在不重新啟動(dòng)設(shè)備的情況下持續(xù)更新。典型的 AI 應(yīng)用程序使用許多不同的模型。它使問(wèn)題的規(guī)模進(jìn)一步擴(kuò)大,以更新現(xiàn)場(chǎng)的模型。
NVIDIA Triton 推理服務(wù)器是一款開(kāi)源推理服務(wù)軟件,通過(guò)解決這些復(fù)雜性簡(jiǎn)化了推理服務(wù)。 NVIDIA Triton 提供了一個(gè)單一的標(biāo)準(zhǔn)化推理平臺(tái),可支持在多框架模型和不同部署環(huán)境(如數(shù)據(jù)中心、云、嵌入式設(shè)備、,以及虛擬化環(huán)境。它通過(guò)高級(jí)批處理和調(diào)度算法支持不同類型的推理查詢,并支持實(shí)時(shí)模型更新。 NVIDIA Triton 還旨在通過(guò)并發(fā)模型執(zhí)行和動(dòng)態(tài)批處理最大限度地提高硬件利用率,從而提高推理性能。
我們用 2021 年 8 月發(fā)布的 Jetson JetPack 4.6 將 Triton 推理服務(wù)器引入 Jetson 。有了 NVIDIA Triton , AI 部署現(xiàn)在可以跨云、數(shù)據(jù)中心和邊緣標(biāo)準(zhǔn)化。
主要特征
以下是 NVIDIA Triton 的一些關(guān)鍵功能,它們可以幫助您簡(jiǎn)化 Jetson 中的模型部署。
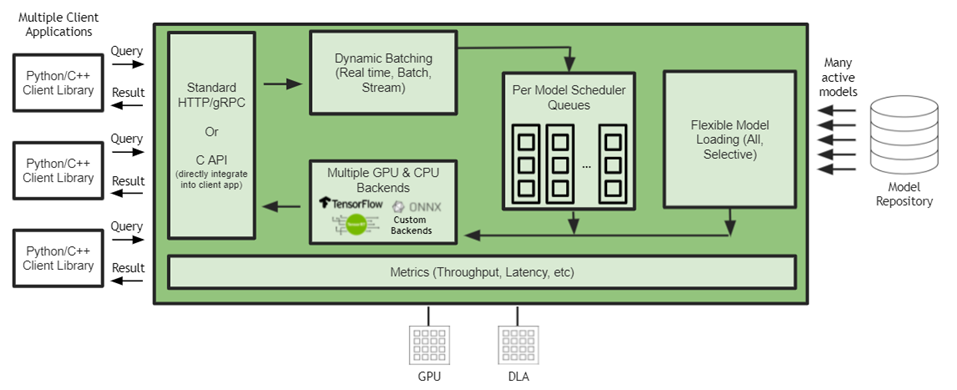
圖 1 Jetson Jetson 上的 Triton 推理服務(wù)器架構(gòu)
嵌入式應(yīng)用集成
客戶機(jī)應(yīng)用程序和 Triton 推理服務(wù)器之間的通信支持直接 C-API 集成,但也支持 gRPC 和 HTTP / REST 。在 Jetson 上,當(dāng)客戶端應(yīng)用程序和推理服務(wù)都在同一設(shè)備上運(yùn)行時(shí),客戶端應(yīng)用程序可以直接調(diào)用 Triton 推理服務(wù)器 API ,而通信開(kāi)銷為零。 NVIDIA Triton 是一個(gè)帶有 C API 的共享庫(kù),可使完整功能直接包含在應(yīng)用程序中。這最適合基于 Jetson 的嵌入式應(yīng)用程序。
多框架支持
NVIDIA Triton 在本機(jī)集成了流行的框架后端,如 TensorFlow 1 。 x / 2 。 x 、 ONNX 運(yùn)行時(shí) TensorRT ,甚至自定義后端。這允許開(kāi)發(fā)人員直接在 Jetson 上運(yùn)行他們的模型,而無(wú)需經(jīng)過(guò)轉(zhuǎn)換過(guò)程。 NVIDIA Triton 還支持添加自定義后端的靈活性。開(kāi)發(fā)人員有自己的選擇,基礎(chǔ)設(shè)施團(tuán)隊(duì)使用單個(gè)推理引擎優(yōu)化部署。
DLA 支持
Jetson 上的 Triton 推理服務(wù)器可以在 GPU 和 DLA 上運(yùn)行模型。 DLA 是 Jetson Xavier NX 和 Jetson AGX Xavier 上提供的深度學(xué)習(xí)加速器。
并發(fā)模型執(zhí)行
Triton 推理服務(wù)器通過(guò)在 Jetson 上同時(shí)運(yùn)行多個(gè)模型,最大限度地提高性能并減少端到端延遲。這些模型可以是所有相同的模型,也可以是來(lái)自不同框架的不同模型。 GPU 內(nèi)存大小是對(duì)可同時(shí)運(yùn)行的型號(hào)數(shù)量的唯一限制。
動(dòng)態(tài)配料
批處理是一種提高推理吞吐量的技術(shù)。批處理推理請(qǐng)求有兩種方法:客戶端批處理和服務(wù)器批處理。 NVIDIA Triton 通過(guò)將單個(gè)推理請(qǐng)求組合在一起來(lái)實(shí)現(xiàn)服務(wù)器批處理,以提高推理吞吐量。它是動(dòng)態(tài)的,因?yàn)樗鼧?gòu)建一個(gè)批處理,直到達(dá)到一個(gè)可配置的延遲閾值。當(dāng)達(dá)到閾值時(shí), NVIDIA Triton 安排當(dāng)前批執(zhí)行。調(diào)度和批處理決策對(duì)請(qǐng)求推斷的客戶機(jī)是透明的,并且根據(jù)模型進(jìn)行配置。通過(guò)動(dòng)態(tài)批處理, NVIDIA Triton 在滿足嚴(yán)格延遲要求的同時(shí)最大限度地提高吞吐量。
動(dòng)態(tài)批處理的一個(gè)例子是,應(yīng)用程序同時(shí)運(yùn)行檢測(cè)和分類模型,其中分類模型的輸入是從檢測(cè)模型檢測(cè)到的對(duì)象。在這種情況下,由于可以對(duì)任意數(shù)量的檢測(cè)進(jìn)行分類,因此動(dòng)態(tài)批處理可以確保可以動(dòng)態(tài)創(chuàng)建檢測(cè)對(duì)象的批,并且可以將分類作為批處理請(qǐng)求運(yùn)行,從而減少總體延遲并提高應(yīng)用程序的性能。
模型組合
模型集成功能用于創(chuàng)建不同模型和預(yù)處理或后處理操作的管道,以處理各種工作負(fù)載。 NVIDIA Triton 集成允許用戶將多個(gè)模型和預(yù)處理或后處理操作縫合到一個(gè)具有連接輸入和輸出的管道中。 NVIDIA Triton 只需從客戶端應(yīng)用程序向集成發(fā)出一個(gè)推斷請(qǐng)求,即可輕松管理整個(gè)管道的執(zhí)行。例如,嘗試對(duì)車輛進(jìn)行分類的應(yīng)用程序可以使用 NVIDIA Triton 模型集成來(lái)運(yùn)行車輛檢測(cè)模型,然后在檢測(cè)到的車輛上運(yùn)行車輛分類模型。
定制后端
除了流行的 AI 后端, NVIDIA Triton 還支持執(zhí)行定制的 C ++后端。這些工具對(duì)于創(chuàng)建特殊的邏輯非常有用,比如預(yù)處理和后處理,甚至是常規(guī)模型。
動(dòng)態(tài)模型加載
NVIDIA Triton 有一個(gè)模型控制 API ,可用于動(dòng)態(tài)加載和卸載模型。這使設(shè)備能夠在應(yīng)用程序需要時(shí)使用這些型號(hào)。此外,當(dāng)模型使用新數(shù)據(jù)重新訓(xùn)練時(shí),它可以無(wú)縫地重新部署在 NVIDIA Triton 上,而不會(huì)重新啟動(dòng)任何應(yīng)用程序或中斷服務(wù),從而允許實(shí)時(shí)模型更新。
結(jié)論
Triton 推理服務(wù)器作為 Jetson 的共享庫(kù)發(fā)布。 NVIDIA Triton 每月發(fā)布一次,增加了新功能并支持最新的框架后端。有關(guān)更多信息,請(qǐng)參閱 Triton 推理服務(wù)器對(duì) Jetson 和 JetPack 的支持。
NVIDIA Triton 有助于在每個(gè)數(shù)據(jù)中心、云和嵌入式設(shè)備中實(shí)現(xiàn)標(biāo)準(zhǔn)化的可擴(kuò)展生產(chǎn) AI 。它支持多個(gè)框架,在 GPU 和 DLA 等多個(gè)計(jì)算引擎上運(yùn)行模型,處理不同類型的推理查詢。通過(guò)與 NVIDIA JetPack 的集成, NVIDIA Triton 可用于嵌入式應(yīng)用。
關(guān)于作者
Shankar Chandrasekaran 是 NVIDIA 數(shù)據(jù)中心 GPU 團(tuán)隊(duì)的高級(jí)產(chǎn)品營(yíng)銷經(jīng)理。他負(fù)責(zé) GPU 軟件基礎(chǔ)架構(gòu)營(yíng)銷,以幫助 IT 和 DevOps 輕松采用 GPU 并將其無(wú)縫集成到其基礎(chǔ)架構(gòu)中。在 NVIDIA 之前,他曾在小型和大型科技公司擔(dān)任工程、運(yùn)營(yíng)和營(yíng)銷職位。他擁有商業(yè)和工程學(xué)位。
Suhas Sheshadri 是 NVIDIA 的產(chǎn)品經(jīng)理,專注于 Jetson 軟件。此前,他曾在 NVIDIA 與自主駕駛團(tuán)隊(duì)合作,為 NVIDIA 驅(qū)動(dòng)平臺(tái)優(yōu)化系統(tǒng)軟件。Mahan Salehi 是 NVIDIA 的深度學(xué)習(xí)軟件產(chǎn)品經(jīng)理,專注于 Triton 推理服務(wù)器。在 NVIDIA 之前,他是一家人工智能初創(chuàng)公司的聯(lián)合創(chuàng)始人兼首席執(zhí)行官,此前也曾在醫(yī)療器械行業(yè)工作。他擁有多倫多大學(xué)的工程學(xué)學(xué)位。
審核編輯:郭婷
-
NVIDIA
+關(guān)注
關(guān)注
14文章
4940瀏覽量
102816 -
數(shù)據(jù)中心
+關(guān)注
關(guān)注
16文章
4688瀏覽量
71956 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5492瀏覽量
120977
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
研華科技打造整體邊緣AI服務(wù)器解決方案
AMD助力HyperAccel開(kāi)發(fā)全新AI推理服務(wù)器






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論