") 使用TensorFlow決策森林創(chuàng)建提升樹(shù)模型
使用TensorFlow決策森林創(chuàng)建提升樹(shù)模型
發(fā)布人:TensorFlow 團(tuán)隊(duì)的 Mathieu Guillame-Bert 和 Josh Gordon
隨機(jī)森林和梯度提升樹(shù)這類(lèi)的決策森林模型通常是處理表格數(shù)據(jù)最有效的可用工具。與神經(jīng)網(wǎng)絡(luò)相比,決策森林具有更多優(yōu)勢(shì),如配置過(guò)程更輕松、訓(xùn)練速度更快等。使用樹(shù)可大幅減少準(zhǔn)備數(shù)據(jù)集所需的代碼量,因?yàn)檫@些樹(shù)本身就可以處理數(shù)字、分類(lèi)和缺失的特征。此外,這些樹(shù)通常還可提供開(kāi)箱即用的良好結(jié)果,并具有可解釋的屬性。
盡管我們通常將 TensorFlow 視為訓(xùn)練神經(jīng)網(wǎng)絡(luò)的內(nèi)容庫(kù),但 Google 的一個(gè)常見(jiàn)用例是使用 TensorFlow 創(chuàng)建決策森林。

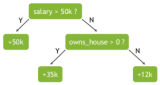
對(duì)數(shù)據(jù)開(kāi)展分類(lèi)的決策樹(shù)動(dòng)畫(huà)
如果您曾使用 2019 年推出的 tf.estimator.BoostedTrees 創(chuàng)建基于樹(shù)的模型,您可參考本文所提供的指南進(jìn)行遷移。雖然 Estimator API 基本可以應(yīng)對(duì)在生產(chǎn)環(huán)境中使用模型的復(fù)雜性,包括分布式訓(xùn)練和序列化,但是我們不建議您將其用于新代碼。
如果您要開(kāi)始一個(gè)新項(xiàng)目,我們建議您使用 TensorFlow 決策森林 (TF-DF)。該內(nèi)容庫(kù)可為訓(xùn)練、服務(wù)和解讀決策森林模型提供最先進(jìn)的算法,相較于先前的方法更具優(yōu)勢(shì),特別是在質(zhì)量、速度和易用性方面表現(xiàn)尤為出色。
首先,讓我們來(lái)比較一下使用 Estimator API 和 TF-DF 創(chuàng)建提升樹(shù)模型的等效示例。
以下是使用 tf.estimator.BoostedTrees 訓(xùn)練梯度提升樹(shù)模型的舊方法(不再推薦使用)
import tensorflow as tf
# Dataset generators
def make_dataset_fn(dataset_path):
def make_dataset():
data = ... # read dataset
return tf.data.Dataset.from_tensor_slices(...data...).repeat(10).batch(64)
return make_dataset
# List the possible values for the feature "f_2".
f_2_dictionary = ["NA", "red", "blue", "green"]
# The feature columns define the input features of the model.
feature_columns = [
tf.feature_column.numeric_column("f_1"),
tf.feature_column.indicator_column(
tf.feature_column.categorical_column_with_vocabulary_list("f_2",
f_2_dictionary,
# A special value "missing" is used to represent missing values.
default_value=0)
),
]
# Configure the estimator
estimator = boosted_trees.BoostedTreesClassifier(
n_trees=1000,
feature_columns=feature_columns,
n_classes=3,
# Rule of thumb proposed in the BoostedTreesClassifier documentation.
n_batches_per_layer=max(2, int(len(train_df) / 2 / FLAGS.batch_size)),
)
# Stop the training is the validation loss stop decreasing.
early_stopping_hook = early_stopping.stop_if_no_decrease_hook(
estimator,
metric_name="loss",
max_steps_without_decrease=100,
min_steps=50)
tf.estimator.train_and_evaluate(
estimator,
train_spec=tf.estimator.TrainSpec(
make_dataset_fn(train_path),
hooks=[
# Early stopping needs a CheckpointSaverHook.
tf.train.CheckpointSaverHook(
checkpoint_dir=input_config.raw.temp_dir, save_steps=500),
early_stopping_hook,
]),
eval_spec=tf.estimator.EvalSpec(make_dataset_fn(valid_path)))
使用 TensorFlow 決策森林訓(xùn)練相同的模型
import tensorflow_decision_forests as tfdf
# Load the datasets
# This code is similar to the estimator.
def make_dataset(dataset_path):
data = ... # read dataset
return tf.data.Dataset.from_tensor_slices(...data...).batch(64)
train_dataset = make_dataset(train_path)
valid_dataset = make_dataset(valid_path)
# List the input features of the model.
features = [
tfdf.keras.FeatureUsage("f_1", keras.FeatureSemantic.NUMERICAL),
tfdf.keras.FeatureUsage("f_2", keras.FeatureSemantic.CATEGORICAL),
]
model = tfdf.keras.GradientBoostedTreesModel(
task = tfdf.keras.Task.CLASSIFICATION,
num_trees=1000,
features=features,
exclude_non_specified_features=True)
model.fit(train_dataset, valid_dataset)
# Export the model to a SavedModel.
model.save("project/model")
附注
-
雖然在此示例中沒(méi)有明確說(shuō)明,但 TensorFlow 決策森林可自動(dòng)啟用和配置早停。
-
可自動(dòng)構(gòu)建和優(yōu)化“f_2”特征字典(例如,將稀有值合并到一個(gè)未登錄詞項(xiàng)目中)。
-
可從數(shù)據(jù)集中自動(dòng)確定類(lèi)別數(shù)(本例中為 3 個(gè))。
-
批次大小(本例中為 64)對(duì)模型訓(xùn)練沒(méi)有影響。以較大值為宜,因?yàn)檫@可以增加讀取數(shù)據(jù)集的效率。
TF-DF 的亮點(diǎn)就在于簡(jiǎn)單易用,我們還可進(jìn)一步簡(jiǎn)化和完善上述示例,如下所示。
如何訓(xùn)練 TensorFlow 決策森林(推薦解決方案)
import tensorflow_decision_forests as tfdf
import pandas as pd
# Pandas dataset can be used easily with pd_dataframe_to_tf_dataset.
train_df = pd.read_csv("project/train.csv")
# Convert the Pandas dataframe into a TensorFlow dataset.
train_ds = tfdf.keras.pd_dataframe_to_tf_dataset(train_df, label="my_label")
model = tfdf.keras.GradientBoostedTreeModel(num_trees=1000)
model.fit(train_dataset)
附注
-
我們未指定特征的語(yǔ)義(例如數(shù)字或分類(lèi))。在這種情況下,系統(tǒng)將自動(dòng)推斷語(yǔ)義。
-
我們也沒(méi)有列出要使用的輸入特征。在這種情況下,系統(tǒng)將使用所有列(標(biāo)簽除外)。可在訓(xùn)練日志中查看輸入特征的列表和語(yǔ)義,或通過(guò)模型檢查器 API 查看。
-
我們沒(méi)有指定任何驗(yàn)證數(shù)據(jù)集。每個(gè)算法都可以從訓(xùn)練樣本中提取一個(gè)驗(yàn)證數(shù)據(jù)集作為算法的最佳選擇。例如,默認(rèn)情況下,如果未提供驗(yàn)證數(shù)據(jù)集,則 GradientBoostedTreeModel 將使用 10% 的訓(xùn)練數(shù)據(jù)進(jìn)行驗(yàn)證。
下面我們將介紹 Estimator API 和 TF-DF 的一些區(qū)別。
Estimator API 和 TF-DF 的區(qū)別
算法類(lèi)型
TF-DF 是決策森林算法的集合,包括(但不限于)Estimator API 提供的梯度提升樹(shù)。請(qǐng)注意,TF-DF 還支持隨機(jī)森林(非常適用于干擾數(shù)據(jù)集)和 CART 實(shí)現(xiàn)(非常適用于解讀模型)。
此外,對(duì)于每個(gè)算法,TF-DF 都包含許多在文獻(xiàn)資料中發(fā)現(xiàn)并經(jīng)過(guò)實(shí)驗(yàn)驗(yàn)證的變體 [1, 2, 3]。
精確與近似分塊的對(duì)比
TF1 GBT Estimator 是一種近似的樹(shù)學(xué)習(xí)算法。非正式情況下,Estimator 通過(guò)僅考慮樣本的隨機(jī)子集和每個(gè)步驟條件的隨機(jī)子集來(lái)構(gòu)建樹(shù)。
默認(rèn)情況下,TF-DF 是一種精確的樹(shù)訓(xùn)練算法。非正式情況下,TF-DF 會(huì)考慮所有訓(xùn)練樣本和每個(gè)步驟的所有可能分塊。這是一種更常見(jiàn)且通常表現(xiàn)更佳的解決方案。
雖然對(duì)于較大的數(shù)據(jù)集(具有百億數(shù)量級(jí)以上的“樣本和特征”數(shù)組)而言,有時(shí) Estimator 的速度更快,但其近似值通常不太準(zhǔn)確(因?yàn)樾枰N植更多樹(shù)才能達(dá)到相同的質(zhì)量)。而對(duì)于小型數(shù)據(jù)集(所含的“樣本和特征”數(shù)組數(shù)目不足一億)而言,使用 Estimator 實(shí)現(xiàn)近似訓(xùn)練形式的速度甚至可能比精確訓(xùn)練更慢。
TF-DF 還支持不同類(lèi)型的“近似”樹(shù)訓(xùn)練。我們建議您使用精確訓(xùn)練法,并選擇使用大型數(shù)據(jù)集測(cè)試近似訓(xùn)練。
推理
Estimator 使用自上而下的樹(shù)路由算法運(yùn)行模型推理。TF-DF 使用 QuickScorer 算法的擴(kuò)展程序。
雖然兩種算法返回的結(jié)果完全相同,但自上而下的算法效率較低,因?yàn)檫@種算法的計(jì)算量會(huì)超出分支預(yù)測(cè)并導(dǎo)致緩存未命中。對(duì)于同一模型,TF-DF 的推理速度通常可提升 10 倍。
TF-DF 可為延遲關(guān)鍵應(yīng)用程序提供 C++ API。其推理時(shí)間約為每核心每樣本 1 微秒。與 TF SavedModel 推理相比,這通常可將速度提升 50 至 1000 倍(對(duì)小型批次的效果更佳)。
多頭模型
Estimator 支持多頭模型(即輸出多種預(yù)測(cè)的模型)。目前,TF-DF 無(wú)法直接支持多頭模型,但是借助 Keras Functional API,TF-DF 可以將多個(gè)并行訓(xùn)練的 TF-DF 模型組成一個(gè)多頭模型。
了解詳情
您可以訪問(wèn)此網(wǎng)址,詳細(xì)了解 TensorFlow 決策森林。
如果您是首次接觸該內(nèi)容庫(kù),我們建議您從初學(xué)者示例開(kāi)始。經(jīng)驗(yàn)豐富的 TensorFlow 用戶可以訪問(wèn)此指南,詳細(xì)了解有關(guān)在 TensorFlow 中使用決策森林和神經(jīng)網(wǎng)絡(luò)的區(qū)別要點(diǎn),包括如何配置訓(xùn)練流水線和關(guān)于數(shù)據(jù)集 I/O 的提示。
您還可以仔細(xì)閱讀從Estimator 遷移到 Keras API,了解如何從 Estimator 遷移到 Keras。
原文標(biāo)題:如何從提升樹(shù) Estimator 遷移到 TensorFlow 決策森林
文章出處:【微信公眾號(hào):谷歌開(kāi)發(fā)者】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
Google
+關(guān)注
關(guān)注
5文章
1758瀏覽量
57417 -
模型
+關(guān)注
關(guān)注
1文章
3174瀏覽量
48720 -
tensorflow
+關(guān)注
關(guān)注
13文章
329瀏覽量
60499
原文標(biāo)題:如何從提升樹(shù) Estimator 遷移到 TensorFlow 決策森林
文章出處:【微信號(hào):Google_Developers,微信公眾號(hào):谷歌開(kāi)發(fā)者】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
快速部署Tensorflow和TFLITE模型在Jacinto7 Soc

stm32mp135d的板子可不可以跑tensorflow的模型啊?
TensorFlow是什么?TensorFlow怎么用?
使用TensorFlow進(jìn)行神經(jīng)網(wǎng)絡(luò)模型更新
請(qǐng)問(wèn)ESP32如何運(yùn)行TensorFlow模型?
tensorflow簡(jiǎn)單的模型訓(xùn)練
keras模型轉(zhuǎn)tensorflow session
如何使用Tensorflow保存或加載模型
如何在TensorFlow中構(gòu)建并訓(xùn)練CNN模型
使用電腦上tensorflow創(chuàng)建的模型,轉(zhuǎn)換為tflite格式了,導(dǎo)入后進(jìn)度條反復(fù)出現(xiàn)0-100%變化,為什么?
什么是隨機(jī)森林?隨機(jī)森林的工作原理
基于TensorFlow和Keras的圖像識(shí)別

如何使用TensorFlow構(gòu)建機(jī)器學(xué)習(xí)模型

如何使用RMxprt創(chuàng)建電機(jī)模型
決策樹(shù):技術(shù)全解與案例實(shí)戰(zhàn)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論