 如何在TensorFlow2中高效培訓1130億參數推薦系統
如何在TensorFlow2中高效培訓1130億參數推薦系統
深度學習推薦系統通常使用大型嵌入表。很難將它們放入 GPU 內存中。
這篇文章向你展示了如何結合使用模型并行和數據并行訓練范例來解決這個記憶問題,從而更快地訓練大型深度學習推薦系統。我分享了我的團隊在 TensorFlow 2 中高效培訓 1130 億參數推薦系統所采取的步驟,該模型的所有嵌入的總大小為 421 GiB 。
通過在 GPU 和 CPU 之間拆分模型和嵌入,我的團隊實現了 43 倍的加速。然而,將嵌入分布到多個 GPU 上,帶來了令人難以置信的 672 倍的加速。這種多 GPU 方法實現了顯著的加速,使您能夠在幾分鐘內而不是幾天內訓練大型推薦系統。
您可以使用 NVIDIA 深度學習示例 GitHub 存儲庫 中提供的代碼自己復制這些結果。
嵌入層的模型并行訓練
在數據并行訓練中,每個 GPU 存儲模型的相同副本,但在不同的數據上訓練。這對于許多深度學習應用程序來說都很方便,因為它易于實現,并且通信開銷相對較低。然而,這種模式要求神經網絡的權重適合單個設備。
如果模型大小大于設備內存,一種方法是將模型分成子部分,并在不同的 GPU 上訓練每個子部分。這被稱為模型并行訓練。
表的每一行對應于要映射到密集表示的輸入變量的值。表中的每一列表示輸出空間的不同維度,表示所有向量中一個值的切片。因為一個典型的深度學習推薦程序會吸收多個分類特征,所以它需要多個嵌入表。
對于具有多個大型嵌入的推薦程序,有三種實現模型并行性的方法:
Table-wise split——每個嵌入表完全放在一個設備上;每個設備只包含所有嵌入的一個子集。(圖 1 )
Column-wise split–每個 GPU 包含每個嵌入表中的一個子集列。(圖 2 )
Row-wise split–每個 GPU 保存每個嵌入表中的行子集。
由于負載平衡問題,行分割比其他兩個選項更難實現。在本文中,我將重點介紹表拆分和列拆分。混合和匹配多種方法是一個可行的選擇,但為了簡單起見,我不會在本文中集中討論這一點。
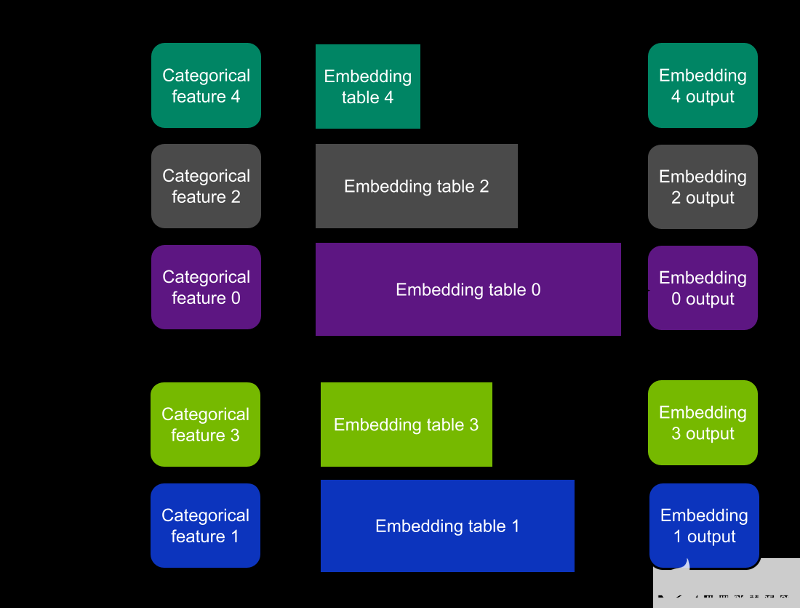
圖 1 。按表拆分模式是指每個 GPU 存儲所有嵌入表的子集

圖 2 。按列拆分模式是指每個設備存儲來自每個嵌入表的列的子集
這些方法之間有一些關鍵區別(表 1 )。簡言之,按表拆分模式更易于使用,而且可能更快,具體取決于具體的工作負載。
一個缺點是它不支持嵌入跨越多個 GPU 的表。相比之下,按列拆分模式支持嵌入跨多個 GPU 的表,但速度可能會稍慢,尤其是對于窄表。

表 1 。表拆分和列拆分模式之間的比較。
高效訓練推薦系統的混合并行方法
典型的推薦程序在嵌入后運行算術密集型層,如線性或點積。處理模型這一部分的一種幼稚方法是將嵌入查找的結果收集到單個 GPU 上,并在此 GPU 上運行這些密集層。然而,這是非常低效的,因為在這段時間內沒有使用用于保存嵌入的另一個 GPU 。
更好的方法是使用所有 GPU 通過數據并行運行密集層。這可以通過按批量大小拆分嵌入查找的結果來實現。也就是說,對于 N 和八 GPU 的全局批量,每個 GPU 只處理 N / 8 個訓練樣本。實際上,這意味著密集層以數據并行模式運行。
由于這種方法結合了嵌入的模型并行性和多層感知器( MLP )的數據并行性,因此被稱為混合并行訓練(圖 3 )。
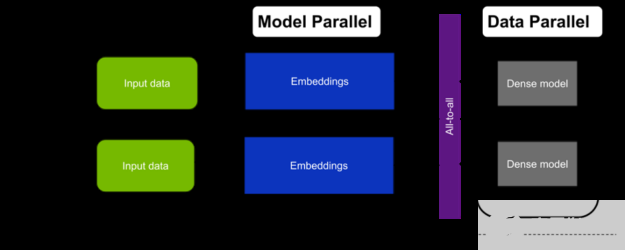
圖 3 。訓練大型推薦系統的通用混合并行方法
Horovod all-to-all
從模型并行到數據并行范式需要一個多 GPU 集體通信操作:全部對全部。
All to All 是一種靈活的集體通信原語,可在每對 GPU 之間交換數據。這是必需的,因為在嵌入查找階段結束時,每個 GPU 都保存所有樣本的查找結果。但是,僅適用于表的子集(用于按表拆分)或列的子集(用于按列拆分)。
由于 all-to-all 操作會在 GPU 之間洗牌數據,因此需要注意的是,每個 GPU 都會保存所有表的所有列的嵌入查找結果,但只保存樣本子集的嵌入查找結果。例如,對于一個 8 GPU 場景,本地批量大小畢竟是之前的 8 倍。
通信由 Horovod 庫的 hvd.alltoall 函數處理。在引擎蓋下,霍洛伍德稱 NCCL 實施 為了獲得最佳性能。如果你的系統上有 NVLink ,它也會利用它。
在本節中,我將描述一種用于 TensorFlow 2 中訓練的 1130 億參數推薦系統的混合并行訓練方法。完整的源代碼可以在 NVIDIA 深度學習示例庫 中找到。
深度學習推薦模型的體系結構
對于這個例子,我使用 DLRM 體系結構(圖 4 )。 DLRM 是研究論文 面向個性化和推薦系統的深度學習推薦模型 中首次介紹的一類推薦模型。我之所以選擇它,是因為 MLPerf 基準測試使用了更小版本的 DLRM ,因此,它是演示推薦系統性能的當前行業標準。
DLRM 同時使用分類和數字功能。分類特征被輸入到嵌入層中,而數字特征則由一個小的 MLP 子網絡處理。
然后將這些層的結果輸入點交互層和另一個 MLP 。然后使用二元交叉熵損失函數通過反向傳播對模型進行訓練,并根據隨機梯度下降( SGD )方法更新權重。
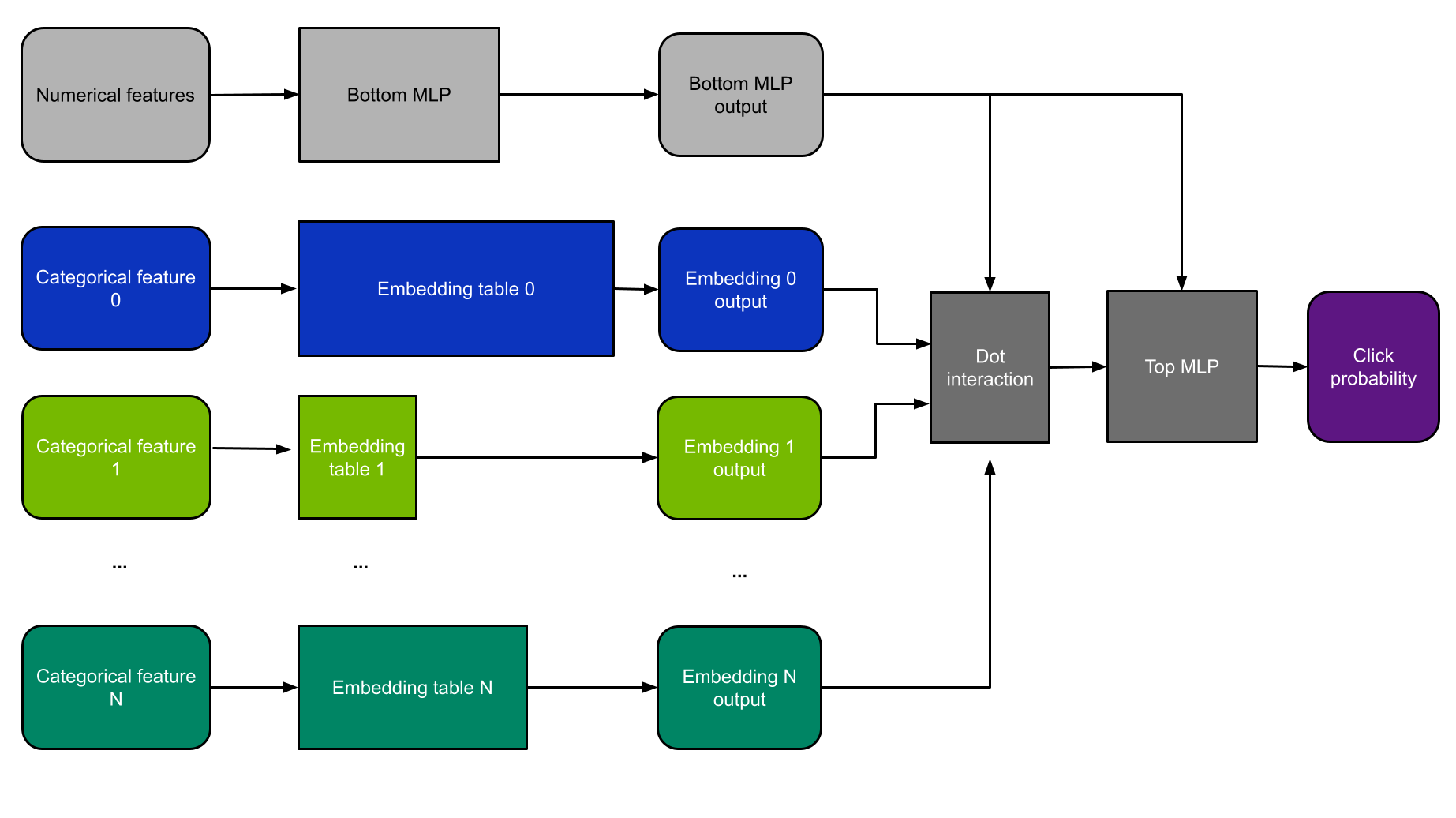
圖 4 。 DLRM 體系結構圖。
修改以支持寬深度模型
雖然我選擇在本例中使用 DLRM 體系結構,但也可以支持相關模型(如 Wide & Deep )。這需要進行以下修改:
添加 wide & Deep 的“ wide ”部分,并在純數據并行模式下運行它,完全繞過 all to all 。
為寬部分添加第二個優化器。
在深部,移除底部 MLP ,并將數字特征直接傳遞到頂部 MLP 。
移除點交互層。
同步文件夾
DLRM 可以在由數字和分類特征組成的任何表格數據集上進行訓練。在本例中,我使用 Criteo 的 TB 點擊日志數據集 ,因為它是最大的公開點擊率數據集。
該數據集由 26 個分類變量和 13 個數值變量組成。在未經處理的數據中,獨特類別的總數為 8.82 億,其中 2.92 億是在最大的特征中發現的。
遵循 MLPerf 推薦基準,對嵌入使用單精度,每個特征的嵌入維度為 128 。這意味著參數總數為 882M × 128 = 1130 億。所有 26 個表的總大小為 1130 億× 4 字節/ 230= 421 GiB ,最大表為 139.6 GiB 。因為最大的表不適合單個 GPU ,所以必須使用按列拆分模式將表分片,并將每個表分布到多個 GPU 中。
從理論上講,您可以只對超過單個 GPU 內存的少數表執行此操作,并對其余的表使用按表拆分。然而,這將不必要地使代碼復雜化,而沒有任何明顯的好處。因此,對所有表使用按列拆分模式。
性能優化
為了提高訓練速度,我的團隊實施了以下性能優化,如代碼所示。這些是可以應用于其他深度學習推薦系統以及其他深度學習框架的通用策略。
自動混合精度
混合精度是計算方法中不同數值精度的組合使用。有關如何啟用它的更多信息,請參閱 TensorFlow 核心文檔中的 Mixed precision 。與 A100 上默認的 TF32 精度相比,該模型使用混合精度使其速度提高了 23% 。
相同寬度的融合嵌入表
當多個嵌入表具有相同的向量大小時——這是 DLRM 中使用embedding_dim=128的情況——它們可以沿零軸連接。這允許對一個大表執行單個查找,而不是對許多較小的表執行多個查找。
啟動一個大內核而不是多個小內核要高效得多。在本例中,將表連接起來可使訓練速度提高 39% 。
XLA
我的團隊使用 TensorFlow 加速線性代數( XLA )編譯器來提高性能。對于這個特定的用例,應用 XLA 比不使用它產生 3.36X 的加速。這個值是在打開所有其他優化的情況下實現的: AMP 、串聯嵌入等等。
廣播數據加載器
在每個 GPU 上運行每個嵌入表的一部分意味著每個 GPU 必須訪問每個訓練樣本的每個特性。在每個過程中分別加載和解析所有這些輸入數據效率低下,可能會導致嚴重的瓶頸。我通過只在第一個 worker 上加載輸入數據并通過 NVLink 將其廣播給其他 worker 來解決這個問題。這提供了 32% 的加速。
把這一切放在一起
圖 5 顯示了具有八個 GPU 的混合并行 DLRM 的設備放置示例。該圖顯示 GPU 0 和 7 。為了簡單起見,它只顯示分類功能 0 和 25 。
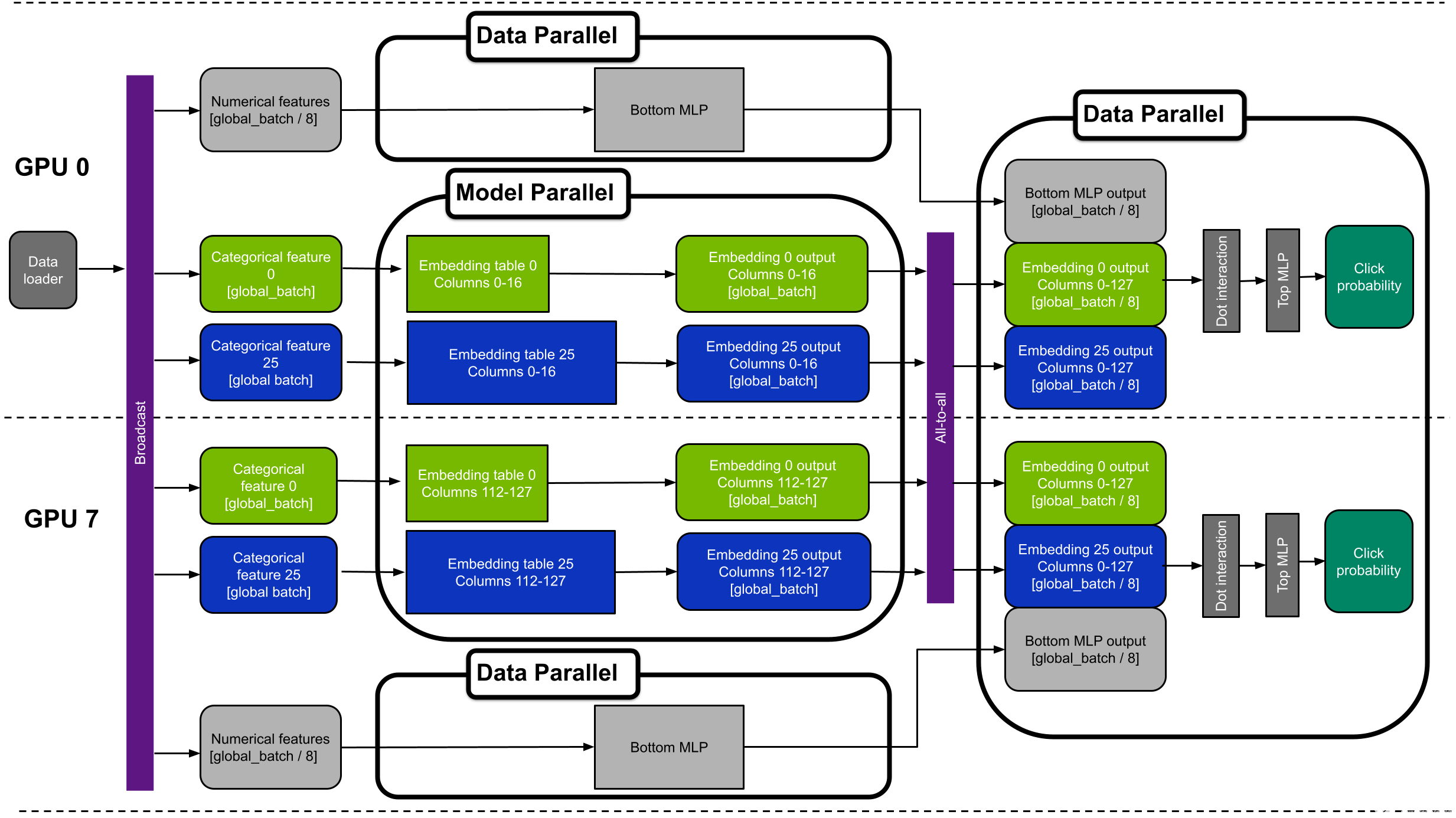
圖 5 。具有 1130 億個參數的混合并行 DLRM 的簡化圖。
替代方法:將大型嵌入存儲在 CPU 上
存儲大型嵌入矩陣的一個簡單替代方法是將它們放入主機內存中。小型嵌入表和計算密集型層仍然可以放置在 GPU 上,以獲得最佳性能。雖然簡單得多,但與將所有變量保留在 GPU 上相比,這種方法也較慢。
這有兩個根本原因:
嵌入查找是一種內存受限的操作。 CPU 內存比 GPU 內存慢得多。雙插槽 AMD Epyc 7742 的總內存帶寬為 409.6 GB / s ,而單插槽 A100-80GB GPU 的總內存帶寬為 2 TB / s ,而 8 個 A100-80GB GPU 的總內存帶寬為 16 TB / s 。
GPU 之間的數據交換速度明顯快于 CPU 和 GPU 之間的數據交換速度。這是因為將 CPU 連接到 GPU 之間的 PCIe 鏈路可能會成為瓶頸。
當使用 CPU 存儲嵌入時, CPU 和 GPU 之間的傳輸必須首先通過提供 31.5 GB / s 帶寬的 PCIe 接口。相反,在混合并行范例中,嵌入查找的結果通過 GPU 之間的 NVSwitch 結構進行傳輸。 DGX A100 采用第二代 NVSwitch 技術,支持每秒 600 GB 的峰值 GPU 到 – GPU 通信。
盡管速度有所放緩,但這種替代方法仍然比僅在 CPU 上運行整個網絡快得多。
基準結果
下表顯示了訓練 113B 參數 DLRM 模型的基準測試結果。它只比較了三種硬件設置: CPU ,一種使用 CPU 內存的單一 GPU 用于最大的嵌入表,以及一種使用完整 DGX A100-80GB 的混合并行方法。

表 2 。比較 1130 億參數深度學習推薦模型( DLRM )的 CPU 和 GPU 訓練吞吐量。
比較前兩行,你可以看到用一個 A100 GPU 來補充兩個 CPU 可以使吞吐量增加 43 倍。之所以會出現這種情況,是因為 GPU 非常適合運行計算密集型線性層和適合其 80-GB 內存的較小嵌入層。
此外,使用八個 GPU 的完整 DGX A100 比在單個 A100 GPU 上訓練快 15.5 倍。 DGX A100 使您能夠將整個型號安裝到 GPU 內存中,并消除了昂貴的設備到主機和主機到設備傳輸的需要。
總的來說, DGX A100 解決這項任務的速度是雙插座 CPU 系統的 672 倍。
結論
在這篇文章中,我介紹了使用混合并行來訓練大型推薦系統的想法。測試結果表明, DGX A100 是在 TensorFlow 2 中訓練參數超過 1000 億的推薦系統的極好工具。它在雙插槽 CPU 上實現了 672 倍的加速。
高內存帶寬和快速的 GPU 到 – GPU 通信使快速培訓推薦人成為可能。因此,與僅使用 CPU 服務器相比,您的培訓時間更短。這降低了培訓成本,同時為從業者提供了更快的實驗。
關于作者
Tomasz Grel 是一名深度學習工程師。在NVIDIA ,他專注于確保眾多推薦系統的質量和執行速度,包括 NCF 、 VAE-CF 和 DLRM 。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
4940瀏覽量
102818 -
gpu
+關注
關注
28文章
4702瀏覽量
128709 -
深度學習
+關注
關注
73文章
5493瀏覽量
120979
發布評論請先 登錄
相關推薦
芯青年,新征程——中科億海微2024年度新員工培訓順利開班

如何在Tensorflow中實現反卷積
TensorFlow是什么?TensorFlow怎么用?
tensorflow和pytorch哪個更簡單?
tensorflow和pytorch哪個好
tensorflow簡單的模型訓練
keras模型轉tensorflow session
如何在TensorFlow中構建并訓練CNN模型
TensorFlow的定義和使用方法
培訓進行中!米爾與瑞薩基于RZ/G2L的OpenAMP混合部署實戰培訓

雙節鋰電池拓撲交叉充電,主動平衡充電——ZCC1130T

【飛騰派4G版免費試用】第二章:在PC端使用 TensorFlow2 訓練目標檢測模型
【飛騰派4G版免費試用】 第二章:在PC端使用 TensorFlow2 訓練目標檢測模型





 工商網監
工商網監
評論