") 如何通過組件配置為深度學(xué)習(xí)培訓(xùn)選擇企業(yè)服務(wù)器
如何通過組件配置為深度學(xué)習(xí)培訓(xùn)選擇企業(yè)服務(wù)器
深度學(xué)習(xí)已經(jīng)成為執(zhí)行許多人工智能任務(wù)的最常見的神經(jīng)網(wǎng)絡(luò)實(shí)現(xiàn)。數(shù)據(jù)科學(xué)家使用 TensorFlow 和 PyTorch 等軟件框架來開發(fā)和運(yùn)行 DL 算法。
到目前為止,已經(jīng)有很多關(guān)于深度學(xué)習(xí)的文章,你可以從許多來源找到更詳細(xì)的信息。有關(guān)良好的高層總結(jié),請參見 人工智能、機(jī)器學(xué)習(xí)和深度學(xué)習(xí)之間有什么區(qū)別?
開始深度學(xué)習(xí)的一種流行方式是在云中運(yùn)行這些框架。然而,隨著企業(yè)開始增長和成熟其人工智能專業(yè)技能,他們會尋找在自己的數(shù)據(jù)中心運(yùn)行這些框架的方法,以避免基于云的人工智能的成本和其他挑戰(zhàn)。
在本文中,我將討論如何為 深度學(xué)習(xí)培訓(xùn)選擇企業(yè)服務(wù)器。我回顧了這個獨(dú)特工作負(fù)載的具體計算需求,然后討論了如何通過組件配置的最佳選擇來滿足這些需求。
DL 培訓(xùn)的系統(tǒng)要求
深度學(xué)習(xí)培訓(xùn)通常被設(shè)計為數(shù)據(jù)處理管道。必須首先根據(jù)數(shù)據(jù)格式、大小和其他因素準(zhǔn)備原始輸入數(shù)據(jù)。
數(shù)據(jù)通常也會經(jīng)過預(yù)處理,以便相同的輸入可以以不同的方式呈現(xiàn)給模型,這取決于數(shù)據(jù)科學(xué)家所確定的將提供更強(qiáng)大的訓(xùn)練集的內(nèi)容。例如,圖像可以隨機(jī)旋轉(zhuǎn),以便模型學(xué)習(xí)識別對象,而不考慮方向。然后將準(zhǔn)備好的數(shù)據(jù)輸入 DL 算法。
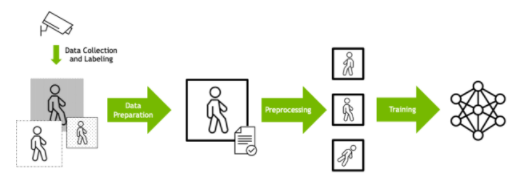
圖 1 深度學(xué)習(xí)培訓(xùn)數(shù)據(jù)管道
了解了 DL 培訓(xùn)的工作原理后,以下是以最快、最有效的方式執(zhí)行此任務(wù)的具體計算需求。
深度學(xué)習(xí)的核心是 GPU 。計算網(wǎng)絡(luò)每一層的值的過程最終是一組龐大的矩陣乘法。每個層的數(shù)據(jù)通常可以并行處理,各層之間有協(xié)調(diào)步驟。
GPU 設(shè)計用于以大規(guī)模并行方式執(zhí)行矩陣乘法,并已被證明是實(shí)現(xiàn) 深度學(xué)習(xí)的巨大速度 的理想選擇。
對于訓(xùn)練,模型的大小是驅(qū)動因素,因此具有更大更快內(nèi)存的 GPU ,比如 NVIDIA A100 GPU 核心張量 ,能夠更快地處理成批的訓(xùn)練數(shù)據(jù)。
中央處理器
DL 訓(xùn)練所需的數(shù)據(jù)準(zhǔn)備和預(yù)處理計算通常在 CPU 上執(zhí)行,盡管 recent innovations 已經(jīng)使越來越多的計算能夠在 GPU 上執(zhí)行。
使用高性能的 CPU 以足夠快的速度維持這些操作是至關(guān)重要的,這樣 GPU 就不會因?yàn)榈却龜?shù)據(jù)而感到饑餓。 CPU 應(yīng)該是企業(yè)級的,例如來自英特爾至強(qiáng)可擴(kuò)展處理器系列或 AMD EPYC 系列,而且 CPU 內(nèi)核與 GPU 的比例應(yīng)該足夠大,以保持流水線運(yùn)行。
系統(tǒng)存儲器
特別是對于當(dāng)今最大的機(jī)型, DL 訓(xùn)練只有在有大量輸入數(shù)據(jù)可供訓(xùn)練時才有效。這些數(shù)據(jù)從存儲器中批量檢索,然后由 CPU 在系統(tǒng)內(nèi)存中處理,然后再饋送到 GPU 。
為了保持該進(jìn)程以持續(xù)的速度運(yùn)行,系統(tǒng)內(nèi)存應(yīng)該足夠大,以便 CPU 處理的速率可以與 GPU 處理數(shù)據(jù)的速率相匹配。這可以用系統(tǒng)內(nèi)存與 GPU 內(nèi)存的比率來表示(在服務(wù)器中的所有 GPU 中)。
不同的模型和算法需要不同的比率,但最好有更高的比率,這樣 GPU 就永遠(yuǎn)不會等待數(shù)據(jù)。
網(wǎng)絡(luò)適配器
隨著 DL 模型變得越來越大,已經(jīng)開發(fā)出了多種技術(shù)來執(zhí)行訓(xùn)練,多個 GPU 一起工作。當(dāng)一臺服務(wù)器中安裝了多個 GPU 時,它們可以通過 PCIe 總線相互通信,盡管可以使用 NVLink 和 NVSwitch 等更專業(yè)的技術(shù)來實(shí)現(xiàn)最高性能。
Multi- GPU 培訓(xùn)也可以擴(kuò)展到跨多臺服務(wù)器的工作。在這種情況下,網(wǎng)絡(luò)適配器成為服務(wù)器設(shè)計的關(guān)鍵組件。在執(zhí)行多節(jié)點(diǎn) DL 訓(xùn)練時,需要高帶寬 Ethernet 或 InfiniBand 適配器來最大限度地減少由于數(shù)據(jù)傳輸而產(chǎn)生的瓶頸。
DL 框架利用 NCCL 等庫以最佳和性能的方式執(zhí)行 GPU 之間的協(xié)調(diào)。 GPUDirect RDMA 等技術(shù)使數(shù)據(jù)能夠從網(wǎng)絡(luò)直接傳輸?shù)?GPU ,而無需通過 CPU ,從而消除了延遲源。
理想情況下,系統(tǒng)中每一兩個 GPU 就應(yīng)該有一個網(wǎng)絡(luò)適配器,以便在必須傳輸數(shù)據(jù)時最大限度地減少爭用。
存儲
DL 培訓(xùn)數(shù)據(jù)通常駐留在外部存儲陣列上。服務(wù)器上的 NVMe 驅(qū)動器通過提供緩存數(shù)據(jù)的方法,可以大大加快培訓(xùn)過程。
DL I / O 模式通常由讀取訓(xùn)練數(shù)據(jù)的多次迭代組成。訓(xùn)練的第一步(或 epoch )讀取用于開始訓(xùn)練模型的數(shù)據(jù)。如果在節(jié)點(diǎn)上提供了足夠的本地緩存,則后續(xù)的數(shù)據(jù)傳遞可以避免從遠(yuǎn)程存儲中重新讀取數(shù)據(jù)。
為了避免從遠(yuǎn)程存儲中提取數(shù)據(jù)時發(fā)生爭用,每個 CPU 應(yīng)該有一個 NVMe 驅(qū)動器。
PCIe 拓?fù)?/p>
由于 CPU 、 GPU 和網(wǎng)絡(luò)之間存在復(fù)雜的相互作用,因此應(yīng)該清楚的是,具有減少 DL 培訓(xùn)管道中任何潛在瓶頸的連接設(shè)計對于實(shí)現(xiàn)最佳性能至關(guān)重要。
如今,大多數(shù)企業(yè)服務(wù)器使用 PCIe 作為組件之間的通信手段。 PCIe 總線上的主要流量發(fā)生在以下路徑上:
從系統(tǒng)內(nèi)存到 GPU
在多次 GPU 培訓(xùn)期間,在相同服務(wù)器上的 GPU 之間
在多節(jié)點(diǎn)培訓(xùn)期間 GPU 與網(wǎng)絡(luò)適配器之間
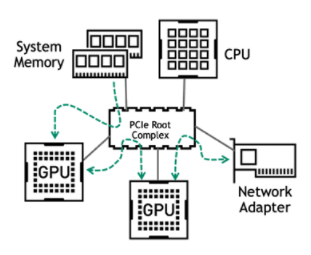
圖 2 主 PCIe 數(shù)據(jù)通信路徑
用于深度學(xué)習(xí)的服務(wù)器應(yīng)具有平衡的 PCIe 拓?fù)浣Y(jié)構(gòu), GPU 均勻分布在 CPU 插槽和 PCIe 根端口上。在所有情況下,每個 GPU 的 PCIe 通道數(shù)應(yīng)為支持的最大數(shù)量。
如果存在多個 GPU ,且 CPU 的 PCIe 通道數(shù)量不足以容納所有通道,則可能需要 PCIe 交換機(jī)。在這種情況下, PCIe 交換機(jī)層的數(shù)量應(yīng)限制為一層或兩層,以最小化 PCIe 延遲。
類似地,網(wǎng)絡(luò)適配器和 NVMe 驅(qū)動器應(yīng)與 GPU 處于同一 PCIe 交換機(jī)或 PCIe 根復(fù)合體之下。在使用 PCIe 交換機(jī)的服務(wù)器配置中,這些設(shè)備應(yīng)與 GPU 位于同一 PCIe 交換機(jī)下,以獲得最佳性能。
選擇支持 DL 培訓(xùn)的經(jīng)過驗(yàn)證的系統(tǒng)
設(shè)計一個為 DL 培訓(xùn)而優(yōu)化的服務(wù)器很復(fù)雜。 NVIDIA 已經(jīng)發(fā)布了 關(guān)于為各種類型的加速工作負(fù)載配置服務(wù)器的指南 ,基于多年在這些工作負(fù)載方面的經(jīng)驗(yàn),并與開發(fā)人員合作優(yōu)化代碼。
為了讓你更容易上手,NVIDIA 開發(fā)了 NVIDIA-Certified Systems 程序。系統(tǒng)供應(yīng)商合作伙伴已使用特定的 NVIDIA GPU 和網(wǎng)絡(luò)適配器配置并測試了多種形式的服務(wù)器型號,以驗(yàn)證 優(yōu)化設(shè)計以獲得最佳性能 的有效性。
驗(yàn)證還包括生產(chǎn)部署的其他重要功能,如可管理性、安全性和可伸縮性。系統(tǒng)經(jīng)過針對不同工作負(fù)載類型的一系列類別認(rèn)證。 合格系統(tǒng)目錄 有一份由 NVIDIA partners 提供的經(jīng) NVIDIA 認(rèn)證的系統(tǒng)列表。數(shù)據(jù)中心類別的服務(wù)器已經(jīng)過驗(yàn)證,可以為 DL 培訓(xùn)提供最佳性能。
NVIDIA 人工智能企業(yè)
除了合適的硬件,企業(yè)客戶還希望為 AI 工作負(fù)載選擇受支持的軟件解決方案。 NVIDIA 人工智能企業(yè) 是一套端到端、云計算原生的人工智能和數(shù)據(jù)分析軟件。它經(jīng)過優(yōu)化,因此每個組織都可以擅長人工智能,經(jīng)過認(rèn)證可以部署在從企業(yè)數(shù)據(jù)中心到公共云的任何地方。人工智能企業(yè)包括全球企業(yè)支持,以便人工智能項(xiàng)目保持正常運(yùn)行。
當(dāng)您在優(yōu)化配置的服務(wù)器上運(yùn)行 NVIDIA AI Enterprise 時,您可以放心,您正在從硬件和軟件投資中獲得最佳回報。
總結(jié)
在本文中,我向您展示了如何為 深度學(xué)習(xí)培訓(xùn) 選擇具有特定計算需求的企業(yè)服務(wù)器。希望您已經(jīng)學(xué)會了如何通過組件配置的最佳選擇來滿足這些需求。
關(guān)于作者
Charu Chaubal 在NVIDIA 企業(yè)計算平臺集團(tuán)從事產(chǎn)品營銷工作。他在市場營銷、客戶教育以及技術(shù)產(chǎn)品和服務(wù)的售前工作方面擁有 20 多年的經(jīng)驗(yàn)。 Charu 曾在云計算、超融合基礎(chǔ)設(shè)施和 IT 安全等多個領(lǐng)域工作。作為 VMware 的技術(shù)營銷領(lǐng)導(dǎo)者,他幫助推出了許多產(chǎn)品,這些產(chǎn)品共同發(fā)展成為數(shù)十億美元的業(yè)務(wù)。此前,他曾在 Sun Microsystems 工作,在那里他設(shè)計了分布式資源管理和 HPC 基礎(chǔ)設(shè)施軟件解決方案。查魯擁有化學(xué)工程博士學(xué)位,并擁有多項(xiàng)專利。
審核編輯:郭婷
-
NVIDIA
+關(guān)注
關(guān)注
14文章
4936瀏覽量
102814 -
云計算
+關(guān)注
關(guān)注
39文章
7733瀏覽量
137199 -
服務(wù)器
+關(guān)注
關(guān)注
12文章
9021瀏覽量
85183
發(fā)布評論請先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論