 如何使用NVAPI將DX12資源上傳到GPU
如何使用NVAPI將DX12資源上傳到GPU
如何通過 PCIe 總線優化從 CPU 到 GPU 的 DX12 資源上傳是一個老問題,有許多可能的解決方案,每個解決方案都有其優缺點。在這篇文章中,我將展示如何使用 NVAPI 將 DX12 上傳堆移動到 CPU-Visible VRAM ( CVV ),這是一個加速 PCIe 有限工作負載的簡單解決方案。
CPU-Visible VRAM :工具箱中的新工具
以頂點緩沖區( VB )上載為例,數據不能跨幀重用。將 VB 上載到 GPU 的最簡單方法是直接從 GPU 讀取 CPU 內存:
首先,應用程序創建 DX12 UPLOAD 堆或等效的 CUSTOM 堆。 DX12 上傳堆分配在系統內存中,也稱為 CPU 內存,其中 WRITE_COMBINE ( WC )頁面針對 CPU 寫入進行了優化。 CPU 首先將 VB 數據寫入此系統內存堆。
其次,應用程序使用 IASetVertexBuffers 命令將上載堆中的 VB 綁定到 GPU draw 命令。
在 GPU 中執行繪制時,將啟動頂點著色器。接下來,頂點屬性提取( VAF )單元通過 GPU 的二級緩存讀取 VB 數據,二級緩存本身從存儲在系統內存中的 DX12 上載堆加載 VB 數據:

圖 1 直接從 DX12 上傳堆獲取 VB 。
來自系統內存的 L2 訪問具有高延遲,因此最好在執行 draw 命令之前通過將數據從系統內存復制到 VRAM 來隱藏該延遲。
從 CPU 到 GPU 的預上載可以通過使用 copy 命令來完成,可以使用 COPY 隊列異步完成,也可以在主直接隊列上同步完成。
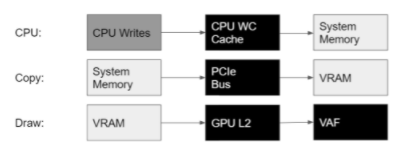
圖 2 使用 copy 命令將 VB 預加載到 VRAM
復制引擎可以在復制隊列中與其他 GPU 工作同時執行復制命令,并且可以同時使用多個復制隊列。但是,使用異步復制隊列的一個問題是,您必須注意將隊列與 DX12 Fences 同步,這可能很難實現,并且可能會有很大的開銷。
在 GTC 2021 的 Nsight Graphics : GPU Trace 的下一級優化建議 會議上,我們宣布 NVIDIA GPU 上 DX12 應用程序的替代解決方案是有效地使用 CPU 線程作為復制引擎。這可以通過使用 NVAPI 在 CVV 中創建 DX12 上載堆來實現。 CPU 然后通過 PCIe 總線將寫入此特殊上載堆的數據直接轉發到 VRAM (圖 3 )。

圖 3 在 CPU 線程中使用 CPU 寫操作將 VB 預加載到 VRAM
對于 DX12 ,以下 NVAPI 函數可用于查詢系統中可用的 CVV 量,并用于分配這種新風格的堆( CPU – 可寫 VRAM ,具有快速 CPU 寫入和慢速 CPU 讀取):
NvAPI_D3D12_QueryCpuVisibleVidmem
NvAPI_D3D12_CreateCommittedResource
NvAPI_D3D12_CreateHeap2
這些新功能需要最新的驅動程序: 466 。 11 或更高版本。
NvAPI_D3D12_QueryCpuVisibleVidmem 應報告以下 CVV 內存量:
使用 Windows 11 (例如,使用 Windows11 內幕預覽 )時 NVIDIA RTX 20xx 和 30xx GPU s 的容量為 200-256 MB 。
可調整大小的條_ RTX 30xx GPU s 在 Windows 10 或 Windows 11 中超過 256 MB ,且 NVIDIA 控制面板中的 可調整大小的條_ 報告為 NVIDIA 。有關如何啟用可調整大小欄的更多信息,請參閱 GeForce RTX 30 系列通過可調整大小的桿支撐加速性能 。
使用 Nsight Graphics 從 CPU-Visible VRAM 檢測并量化 GPU 性能增益機會
NVIDIA NSight 圖形 2021 。 3 中的 GPU 跟蹤工具可輕松檢測 GPU 性能提升機會。啟用 高級模式 時, GPU 內的 Analysis 面板將根據預測的幀減少百分比,通過修復此 GPU 工作負載中的特定問題,跟蹤幀內的顏色代碼 perf 標記。
以下是在 RTX NVIDIA 3080 上,從 看門狗:軍團 ( DX12 )預發布版本中選擇 Analyze 后的幀的外觀:
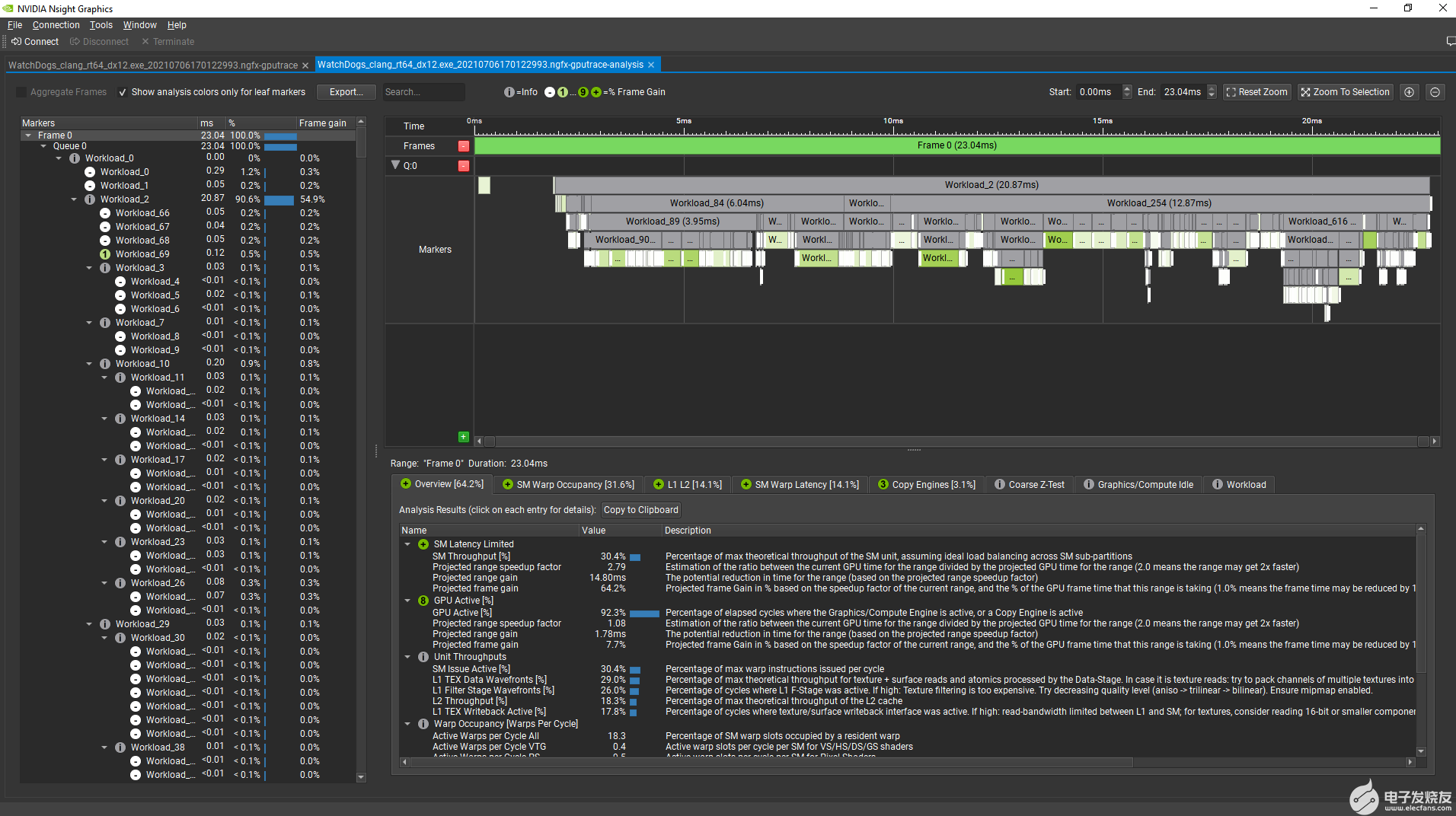
圖 4 帶有顏色編碼 GPU 工作負載的 GPU 跟蹤分析工具
(越綠,幀上的預計增益越高)。
現在,選擇幀末尾的用戶界面繪制命令,分析工具顯示,修復 二級未命中到系統內存 性能問題后 GPU 幀時間預計減少 0 。 9% 。該工具還顯示,通過二級緩存傳輸的大多數系統內存流量是由基本引擎請求的,該引擎包括頂點屬性獲取單元:
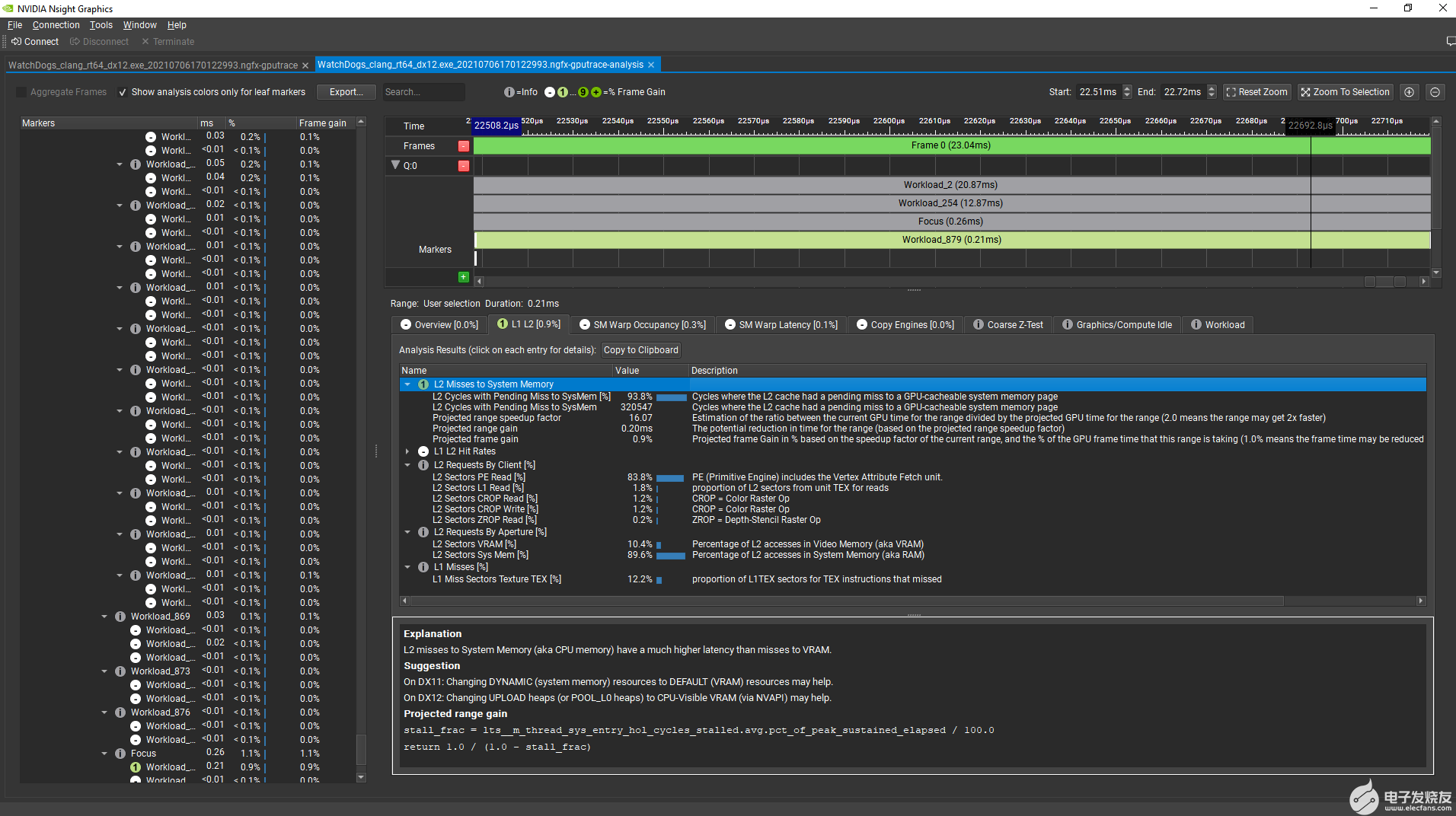
圖 5 GPU 跟蹤分析工具,關注單個工作負載。
通過在 CVV 中分配此 draw 命令的 VB ,而不是使用常規 DX12 上載堆分配系統內存,此機制的 GPU 時間從 0.2 ms 減少到 0.01 ms 以下。 GPU 幀時間也減少了 0.9% 。在此工作負載中, VB 數據現在直接從 VRAM 獲取:

圖 6 GPU 跟蹤分析工具,在優化了工作負載之后。
使用 Nsight 系統避免 CPU 讀取 CPU – 可見 VRAM
CPU 不應讀取常規 DX12 上載堆,而應僅將其寫入。與常規堆一樣, CVV 堆的 CPU 內存頁已啟用 寫合并 。這提供了快速的 CPU 寫入性能,但緩慢的非緩存 CPU 讀取性能。此外,由于從 CVV 讀取 CPU 會通過 PCIe 、 GPU L2 和 VRAM 進行往返,因此從 CVV 讀取的延遲遠大于從常規 DX12 上載堆讀取的延遲。
要檢測應用程序 CPU 的性能是否受到來自 CVV 的 CPU 讀取的負面影響,并獲取 CPU 調用導致這種情況的信息,我建議使用 Nsight 系統 2021.3 。
示例 1 : CVV CPU 讀取 ReadFromSubresource
下面是一個在 Nsight 系統跟蹤中從 DX12 ReadFromSubresource 讀取災難性 CPU 的示例。為了捕獲此跟蹤,在獲取跟蹤時,我在 Nsight 系統項目配置中啟用了新的 收集 GPU 指標 選項,以及默認設置,其中包括 樣本目標過程 。
以下是 Nsight Systems 在放大一個代表性幀后顯示的內容:
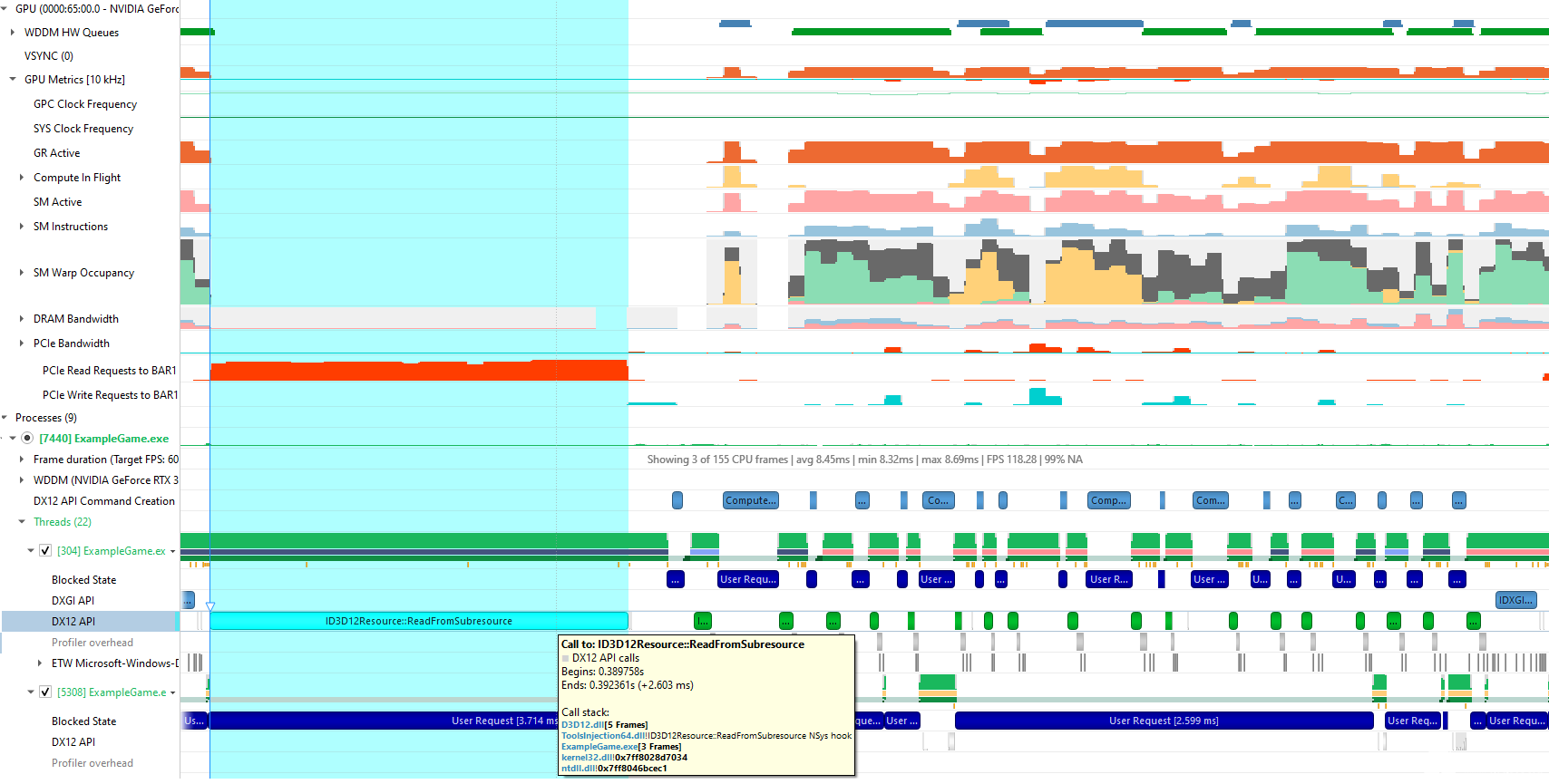
圖 7 Nsight 系統顯示 2 。 6 ms ReadFromSubresource 調用與來自 BAR1 的高 PCIe 讀取請求計數相關的 CPU 線程。
在這種情況下(單個 – GPU 機器), Nsight Systems 中的 對 BAR1 的 PCIe 讀取請求 GPU 指標測量發送到 PCIe 的 CPU 讀取請求數,以獲取 CVV ( BAR1 )中分配的資源。 Nsight Systems 顯示 CPU 線程上的長 DX12 ReadFromSubresource 調用與來自 CVV 的大量 PCIe 讀取請求之間存在明顯的相關性。因此,您可以得出結論,此調用很可能是從 CVV 執行 CPU 回讀,并在應用程序中修復此問題。
示例 2 : CVV CPU 從映射指針讀取
CPU 從 CVV 讀取的數據不限于 DX12 命令。當使用 DX12 資源映射調用返回的任何 CPU 內存指針時,它們可能發生在任何 CPU 線程中。這就是為什么建議使用 Nsight 系統對其進行調試,因為除了選定的 GPU 硬件指標外, Nsight 系統還可以定期對每個 CPU 線程的調用堆棧進行采樣。
以下是 Nsight 系統的一個示例,其中顯示了從 CVV 進行的 CPU 讀取與沒有 DX12 API 調用相關,但與 CPU 線程活動開始相關:
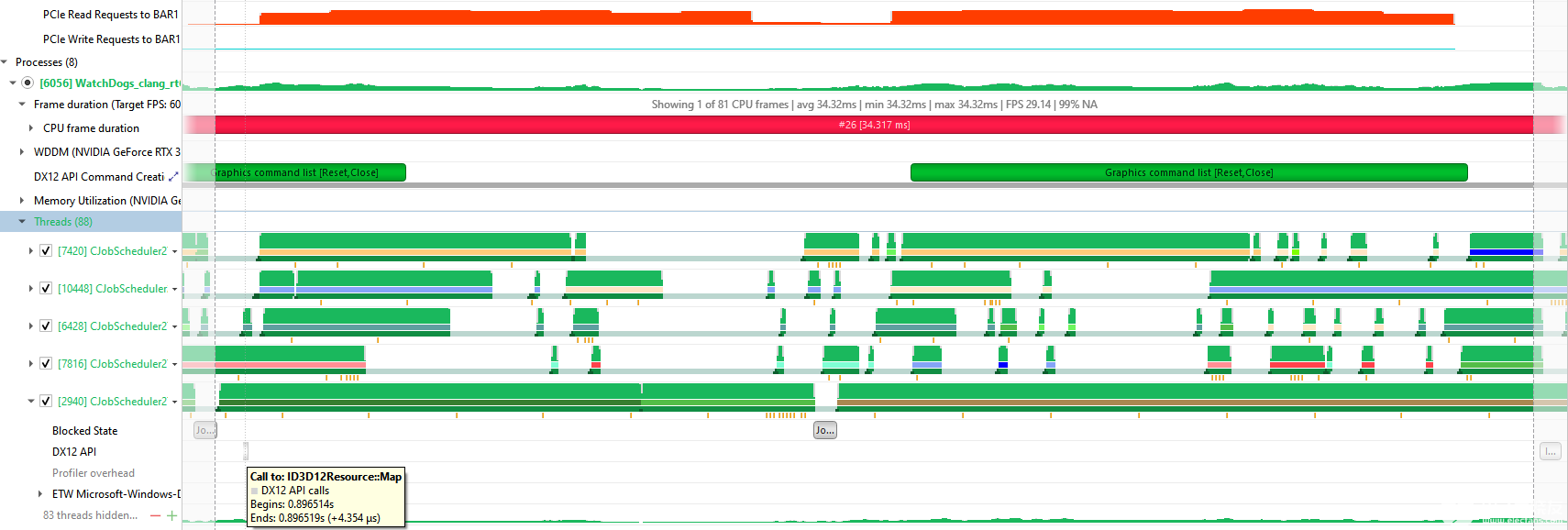
圖 8 Nsight Systems 顯示了執行映射調用的 CPU 線程與對 BAR1 的 PCIe 讀取請求之間的相關性,之后該相關性立即增加。
通過懸停在 CPU 線程下面的橙色采樣點,您可以看到該線程正在執行一個名為 RenderCollectedTrees 的 C ++方法,這對查找正在進行 CVV 堆讀/寫操作的代碼是有幫助的:

圖 9 Nsight Systems 顯示 CPU 線程的調用堆棧采樣點,該線程與對 BAR1 的高 PCIe 讀取請求相關。
在這種情況下,提高性能的一種方法是對 CPU 內存的單獨塊執行讀/寫訪問,而不是在 DX12 上載堆中。完成所有讀/寫更新后,從 CPU 讀/寫內存向上載堆執行 memcpy 調用。
結論
在 Windows 11 PC 上運行的所有 PC 游戲都可以在 NVIDIA RTX 20xx 和 30xx GPU s 上使用 256 MB 的 CVV 。 NVAPI 可用于查詢系統中可用 CVV 內存的總量,并在此空間中分配 DX12 內存。如果 CPU 從未從原始 DX12 上載堆讀取數據,則只需更改分配堆的代碼即可將 DX12 上載堆替換為 CVV 堆。
要檢測將 DX12 上載堆移動到 CVV 時 Nsight 圖形 的性能提升機會,建議使用 GPU 中的 GPU 跟蹤分析工具。要檢測和調試從 CVV 讀取 CPU 時的性能損失,我建議在啟用 GPU 指標的情況下使用 Nsight 系統 。
關于作者
Louis Bavoil 自 2007 年以來一直在 NVIDIA 的開發者技術小組工作,從事 GPU 性能優化和 GameWorks 軟件開發的混合工作,目標是幫助提高 PC 游戲的生產價值。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
4940瀏覽量
102816 -
gpu
+關注
關注
28文章
4701瀏覽量
128705 -
WINDOWS
+關注
關注
3文章
3524瀏覽量
88430
發布評論請先 登錄
相關推薦
英特爾12月或發布Battlemage GPU芯片
怎么把電表監測到的數據上傳平臺?

請問各位3256EVM-U通過麥克風采集到的數據能上傳到電腦嗎?
求助,如何將定制的2級引導加載程序上傳到指定的2級引導區?
如何使用httpclient.c中的ESP8266和http_post將文件上傳到服務器?
ESP下載工具必須連接到哪個UART才能檢測到它并可以將固件上傳到它?
FPGA在深度學習應用中或將取代GPU
DX11游戲抽查測評,2024英特爾銳炫又進步了嗎?
性價比拉滿!英特爾銳炫新驅動,提升可達418%!

【AWTK開源智能串口屏方案】設計UI界面并上傳到串口屏

是否有可能通過其USB或UART通道將新固件上傳到XMC4000微控制器?
是否需要SD卡才能將GUI文件從GUI設計軟件上傳到LCD?
將Arduino IDE中的文件上傳到XMC2GO時,彈出了一條調試器異常的原因?
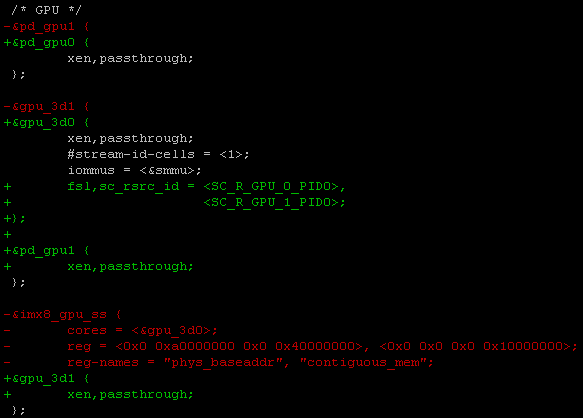
Xen雙系統GPU資源分配過程





 工商網監
工商網監
評論