 基于NVIDIA GPU加速機器學習模型推理
基于NVIDIA GPU加速機器學習模型推理
谷歌云與 NVIDIA 合作,宣布 Dataflow 將 GPU 帶入大數據處理領域,開啟新的可能性。使用數據流 GPU ,用戶現在可以在機器學習推理工作流中利用 NVIDIA GPU 的強大功能。下面我們將向您展示如何使用 BERT 獲得這些性能優勢。
Google Cloud 的 Dataflow 是一個托管服務,用于執行各種各樣的數據處理模式,包括流式處理和批處理分析。它最近添加了 GPU 支持 現在可以加速機器學習推理工作流,這些工作流運行在數據流管道上。
請查看 谷歌云發布 了解更多令人興奮的新功能。在這篇文章中,我們將展示 NVIDIA GPU 加速的性能優勢和 TCO 改進,方法是部署一個來自 Transformers ( BERT )模型的雙向編碼器表示,該模型對數據流上的“問答”任務進行了微調。我們將用 CPU 演示數據流中的 TensorFlow 推理,如何在 GPU 上運行相同的代碼,并顯著提高性能,展示通過 NVIDIA TensorRT 轉換模型后的最佳性能,以及通過 TensorRT 的 python API 和數據流進行部署。查看 NVIDIA 示例代碼 立即嘗試。
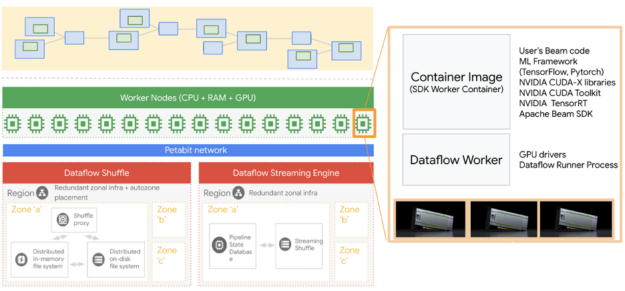
圖 1 .數據流架構和 GPU 運行時。
有幾個步驟,我們將在這個職位上觸及。我們首先在本地機器上創建一個環境來運行所有這些數據流作業。
創造環境
建議為 Python 創建一個虛擬環境,我們在這里使用 virtualenv :
virtualenv -p
使用 Dataflow 時,需要將開發環境中的 Python 版本與 Dataflow 運行時 Python 版本對齊。更具體地說,在運行數據流管道時,應該使用相同的 Python 版本和阿帕奇光束SDK 版本,以避免意外錯誤。
現在,我們激活虛擬環境。
在激活虛擬環境之前需要注意的最重要的一點是確保您沒有在另一個虛擬環境中操作,因為這通常會導致問題。
激活虛擬環境后,我們就可以安裝所需的軟件包了。即使我們的作業在 Dataflow 上運行,我們仍然需要一些本地包,這樣當我們在本地運行代碼時 Python 就不會抱怨了。
pip install apache-beam[gcp]
pip install TensorFlow==2.3.1
您可以嘗試使用 TensorFlow 的不同版本,但這里的關鍵是將這里的版本與您將在數據流環境中使用的版本保持一致。 apachebeam 及其 Google 云組件也是必需的。
獲得微調的 BERT 模型
NVIDIA NGC 有大量的資源,從 GPU – 優化的 containers 到微調的 models 。我們探索了幾個 NGC 資源。
我們將使用的第一個資源是 BERT 大型模型,它針對 SquadV2 問答任務進行了微調,包含 3 。 4 億個參數。以下命令將下載 BERT model 。
wget --content-disposition
https://api.ngc.nvidia.com/v2/models/nvidia/bert_tf_savedmodel_large_qa_squad2_amp_384/versions/19.03.0/zip -O bert_tf_savedmodel_large_qa_squad2_amp_384_19.03.0.zip
對于我們剛剛下載的 BERT 模型,在訓練過程中使用了自動混合精度( AMP ),序列長度為 384 。
我們還需要一個詞匯表文件,我們可以從 BERT 檢查點獲得它,該檢查點可以通過以下命令從 NGC 獲得:
wget --content-disposition
https://api.ngc.nvidia.com/v2/models/nvidia/bert_tf_ckpt_large_qa_squad2_amp_128/versions/19.03.1/zip -O bert_tf_ckpt_large_qa_squad2_amp_128_19.03.1.zip
在獲得這些資源之后,我們只需要解壓縮它們并將它們定位到我們的工作文件夾中。我們將使用自定義 docker 容器,這些模型將包含在我們的圖像中。
自定義 Dockerfile
我們將使用從 GPU 優化的 NGC TensorFlow 容器派生的自定義 Dockerfile 。 NGC TensorFlow ( TF )容器是使用 NVIDIA GPU 加速 TF 模型的最佳選擇。
然后我們再添加幾個步驟來復制這些模型和我們擁有的文件。您可以此處找到 Dockerfile ,下面是 Dockerfile 的快照。
FROM nvcr.io/nvidia/tensorflow:20.11-tf2-py3
RUN pip install --no-cache-dir apache-beam[gcp]==2.26.0 ipython pytest pandas && \
mkdir -p /workspace/tf_beam
COPY --from=apache/beam_python3.6_sdk:2.26.0 /opt/apache/beam /opt/apache/beam
ADD. /workspace/tf_beam
WORKDIR /workspace/tf_beam
ENTRYPOINT [ "/opt/apache/beam/boot"]
接下來的步驟是構建 docker 文件并將其推送到 Google 容器注冊中心( GCR )。您可以使用以下命令執行此操作。或者,您可以在此處使用我們創建的腳本。如果您使用的是我們回購的腳本,那么只需執行bash build_and_push.sh
project_id=""
docker build . -t "gcr.io/${project_id}/tf-dataflow-${USER}:latest"
docker push "gcr.io/${project_id}/tf-dataflow-${USER}:latest"
正在運行作業
如果您已經驗證了您的 Google 帳戶,只需調用 run_gpu.sh 和 run_gpu.sh 腳本即可運行我們提供的 Python 文件 here 。
數據流中的 CPU TensorFlow 引用( TF- CPU )
repo 中的 bert_squad2_qa_cpu.py 文件用于根據描述文本文檔回答問題。批量大小是 16 ,這意味著我們將在每個推理電話回答 16 個問題,有 16000 個問題( 1000 批問題)。請注意, BERT 可以針對給定特定用例的其他任務進行微調。
在 Dataflow 上運行作業時,默認情況下,它會根據實時 CPU 使用情況自動縮放。如果要禁用此功能,需要將 autoscaling_algorithm 設置為 NONE 。這將允許您選擇在整個工作周期中使用多少工人。或者,可以通過設置 max_num_workers parameter ,讓 Dataflow 自動縮放作業并限制要使用的最大工作線程數。
我們建議設置作業名稱,而不是使用自動生成的名稱,以便通過設置 job_name 參數更好地跟蹤作業。此作業名稱將是運行作業的計算實例的前綴。
用 GPU 加速( TF- GPU )
要在 GPU 支持下執行相同的數據流 TensorFlow 推斷作業,我們需要設置以下參數。有關更多信息,請參閱數據流 GPU 文檔。
--experiment "worker_accelerator=type:nvidia-tesla-t4;count:1;install-nvidia-driver"
前面的參數使我們能夠將一個 CUDAT4 張量核連接到 Dataflow worker VM ,它也可以作為運行作業的 Compute VM 實例看到。數據流將自動安裝所需的支持 NVIDIA 11 的 NVIDIA 驅動程序。
bert_squad2_qa_gpu.py文件與bert_squad2_qa_cpu.py文件幾乎相同。這意味著只需很少甚至不做任何更改,就可以使用 NVIDIA GPU s 運行作業。在我們的示例中,我們有幾個額外的 GPU 設置,比如用下面的代碼設置內存增長。
physical_devices = tf.config.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(physical_devices[0], True)
NVIDIA 優化庫的推理
NVIDIA TensorRT 優化了推理的深度學習模型,并提供了低延遲和高吞吐量(對于更多的 information )。在這里,我們使用 NVIDIA TensorRT 優化到 BERT 模型,并用它來回答 GPU 在光速下的數據流管道上的問題。用戶可以按照 TensorRT 演示 BERT github 存儲庫 進行操作。
我們還使用了 Polygraphy, ,它是 TensorRT 的高級 python API 來加載 TensorRT 引擎文件并運行推斷。在數據流代碼中, TensorRT 模型被封裝為一個共享實用程序類,允許來自數據流工作進程的所有線程使用它。
比較 CPU 和 GPU 運行
在表 10 中,我們提供了用于示例運行的總運行時間和資源。數據流作業的最終成本是總 v CPU 時間、總內存時間和總硬盤使用量的線性組合。對于 GPU 情況,還有一個 GPU 組件。
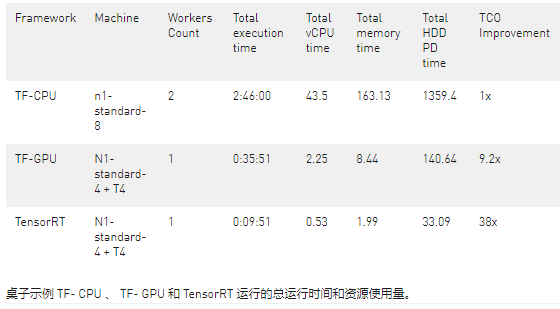
請注意,上表是基于一次運行編譯的,確切的數字或許略有波動,但根據我們的實驗,比率變化不大。
當使用 NVIDIA GPU( TF- GPU )加速我們的模型時,與使用 CPU ( TF- CPU )相比,包括成本和運行時在內的總節省是 10 倍以上。這意味著,當我們使用 NVIDIA GPU 來推斷此任務時,與僅使用 CPU 運行模型相比,我們可以獲得更快的運行時間和更低的成本。
使用 NVIDIA 優化的推理庫(如 TensorRT ),用戶可以在數據流中的 GPU 上運行更復雜和更大的模型。 TensorRT 進一步加速同一作業,比使用 TF- GPU 運行快 3 。 6 倍,從而節省 4 。 2 倍的成本。與 TensorRT 和 TF- CPU 相比,我們的執行時間減少了 17 倍,提供的賬單減少了 38 倍。
概括
在本文中,我們比較了 TF- CPU 、 TF- GPU 和 TensorRT 在 Google 云數據流上運行的問答任務的推理性能。數據流用戶可以通過利用 GPU 工人和 NVIDIA 優化庫獲得巨大的好處。
用 NVIDIA GPU s 和 NVIDIA 軟件加速深度學習模型推理非常簡單。通過添加或更改兩行,我們可以使用 TF- GPU 或 TensorRT 運行模型。我們在這里和這里提供了腳本和源文件供參考。
關于作者
Ethem Can NVIDIA 的數據科學家。他在解決客戶問題的機器學習應用程序方面擁有超過 12 年的研發經驗。在 NVIDIA 之前,他是主要的機器學習開發人員。埃森完成了他的博士學位。在麻州大學計算機科學系, Amherst
Dong Meng 是 NVIDIA 的解決方案架構工程師。董先生在大數據平臺和加速器性能優化方面經驗豐富。他與公共云服務提供商合作,為機器學習培訓/推理和數據分析部署基于云的 GPU 加速解決方案。
Rajan Arora 是 NVIDIA 的解決方案架構師經理,專門從事面向消費互聯網行業的機器學習和數據科學應用。 Rajan 在 NVIDIA 工作了 4 年多,致力于開發系統基礎設施和廣泛的深度學習應用程序。他有博士學位。亞特蘭大喬治亞理工學院電子和計算機工程專業。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
4940瀏覽量
102816 -
gpu
+關注
關注
28文章
4701瀏覽量
128706
發布評論請先 登錄
相關推薦
基于NVIDIA GPU的加速服務 為AI、機器學習和AI工作負載提速
Nvidia GPU風扇和電源顯示ERR怎么解決
在Ubuntu上使用Nvidia GPU訓練模型
壓縮模型會加速推理嗎?
NVIDIA GPU加速AI推理洞察,推動跨行業創新
Microsoft使用NVIDIA Triton加速AI Transformer模型應用
用NVIDIA TSPP和Triton推理服務器加速模型推理





 工商網監
工商網監
評論