 TPU的系統架構
TPU的系統架構
簡單解釋:專門用于機器學習的高性能芯片,圍繞128x128 16 位乘法累加脈動陣列矩陣單元(“MXU”)設計的加速器。如果這句話能為你解釋清楚,那就太好了!如果沒有,那么請繼續閱讀......
介紹
您可能聽說過 Google 有一個用于機器學習的特殊芯片,它被稱為 TPU(“Tensor Processing Unit,張量處理單元”),它構成了 Google 努力將盡可能多的機器學習能力放入單個芯片中。谷歌云為開發者提供了使用這種能力的機會,但芯片本身感覺是一個黑匣子……今天,讓我們剝離這些隱藏的“面紗”,看看我們是否能看到魔法里面的東西。
在本文中,我將嘗試講解 TPU 的系統架構,同時保持足夠簡單,以使硬件經驗最少的軟件開發人員也能看懂。
高性能推理
訓練和運行神經網絡需要大量的計算能力。早在 2013 年,Google 進行了一些簡單的計算,以了解他們需要什么來運行語音搜索,結果令人驚訝:
如果我們考慮人們每天只使用三分鐘谷歌語音搜索的場景,并且我們在我們使用的處理單元上為我們的語音識別系統運行深度神經網絡,我們將不得不將谷歌數據中心的數量增加一倍! — Norm Jouppi( Google 的杰出工程師。他以在計算機內存系統方面的創新而聞名)
神經網絡是強大的工具,但要在標準計算機上隨處運行,它們的成本太高(即使對谷歌來說也是如此)。
值得慶幸的是,這不需要標準計算機來完成繁重的工作。在某些時候,設計一個定制芯片來承載這個任務變得具有成本效益。此定制芯片是專用集成電路(ASIC)。
通常,ASIC 帶來的麻煩多于其價值。他們需要很長時間來設計:Google 花了15 個月的時間來開發 TPUv1,這個速度快得驚人。它們最初很昂貴,需要專門的工程師和大約一百萬美元的制造成本。而且它們不靈活:一旦完成,就無法更換芯片設計。
但是,如果ASIC的數量足夠,那么經濟性的好處可以彌補最初的缺點。ASIC 通常是完成任務的最快、最節能的方式。谷歌希望這種性能能夠運行神經網絡,而 TPU 就是結果。
標量、向量、矩陣
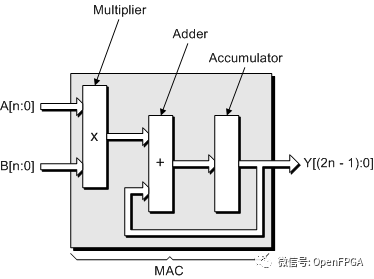
神經網絡需要大量的數學運算,但大多數數學運算都非常簡單:將一堆數字相乘,然后將結果相加。可以在一個稱為乘法累加(MAC) 的操作中將這兩者連接在一起。如果我們不需要做任何其他事情,我們可以非常非常快地進行乘法累加。
如果沒有新芯片,我們將使用 CPU 或 GPU 來實現。CPU 是一臺標量機器,這意味著它一次處理一個指令。這非常適合通用應用程序,例如您的筆記本電腦或服務器,但我們可以通過專業化來擠出更多性能。
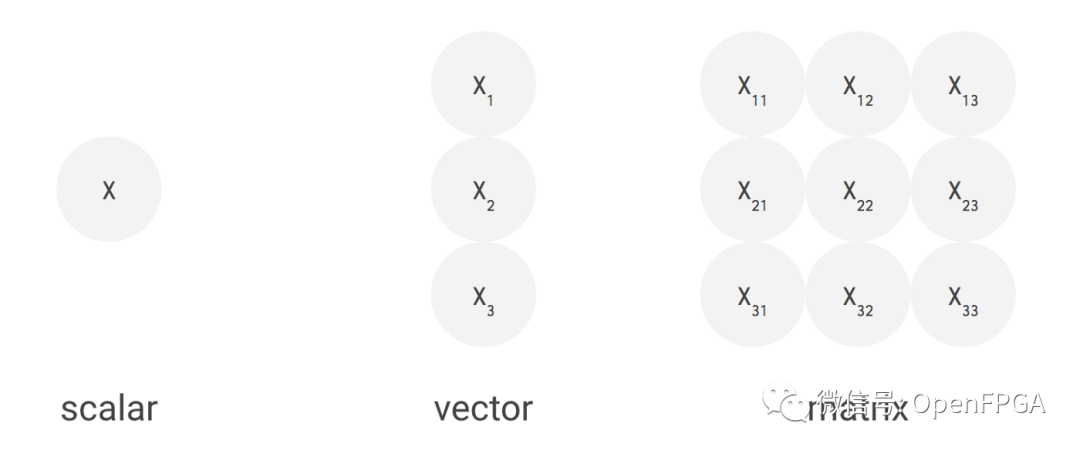
數據維度
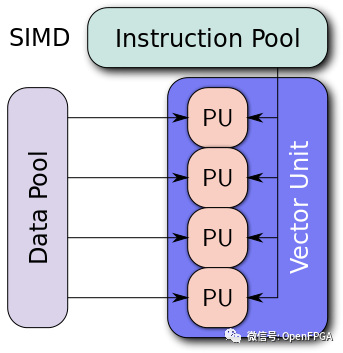
一個簡化的向量架構
GPU 是一個向量機(vector machine)。你可以給它一個很長的數據列表——一個一維向量——并同時在整個列表上運行計算。這樣,我們每秒可以執行更多的計算,但我們必須對數據向量并行執行相同的計算。這種計算非常適合圖形或加密挖掘,其中一項工作必須執行多次。
但我們仍然可以做得更好。神經網絡的數據以矩陣形式排列,即二維向量。因此,我們將構建一個矩陣機(matrix machine)。而且我們真的只關心乘法累加,所以我們會優先考慮處理器通常支持的其他指令。我們將把大部分芯片用于執行矩陣乘法的 MAC,而忽略大多其他操作。
重復這個N 次,你就得到了圖片
脈動陣列Enter the Systolic Array
提升矩陣計算性能的方法是通過一種稱為脈動陣列的架構。這是有趣的一點,這也是 TPU 具有高性能的原因。脈動陣列是一種硬件算法,它描述了計算矩陣乘法的芯片上的單元模式。“Systolic”描述了數據如何在芯片中以波浪的形式移動,就像人類心臟的跳動。
TPU 中實現脈動陣列版本設計有一些變化。
考慮一個矩陣乘法運算:
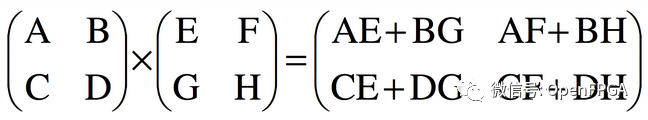
2x2 矩陣相乘
對于 2x2 輸入,輸出中的每一項都是兩個乘積的總和。沒有元素被重復使用,但個別元素被重復使用。
我們將通過構建一個 2x2 網格來實現這一點。(它實際上是一個網格,而不僅僅是一個抽象——硬件就是這樣有趣)。請注意,2x2 是一個玩具示例,而全尺寸 MXU 是一個巨大的 128x128。
假設 AB/CD 代表我們的激活值,EF/GH代表我們的權重。對于我們的數組,我們首先 像這樣加載權重:

稍后我將討論我們如何做到這一點
接下來激活進入輸入隊列,在我們的示例中,該隊列位于每一行的左側。
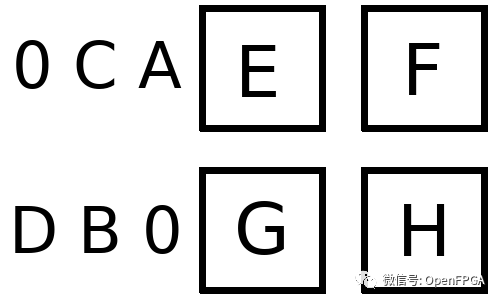
注意用零填充:這可以確保數據在正確的時刻進入數組
每個時鐘周期 ,每個單元都會并行執行以下步驟:
乘以我們的權重和來自左側的激活。如果左側沒有單元格,則從輸入隊列中取出。
將該產品添加到從上面傳入的部分總和中。如果上面沒有單元格,則上面的部分總和為零。
將激活傳遞到右側的單元格。如果右側沒有單元格,則丟棄激活。
將部分總和傳遞到底部的單元格。如果底部沒有單元格,則收集部分總和作為輸出。
上面的Python偽代碼:
?
https://github.com/antonpaquin/SystolicArrayDemo/blob/master/systolic.py
通過這些規則,可以看到激活將從左側開始,每個周期向右移動一個單元格,部分和將從頂部開始,每個周期向下移動一個單元格。
數據流將如下所示:
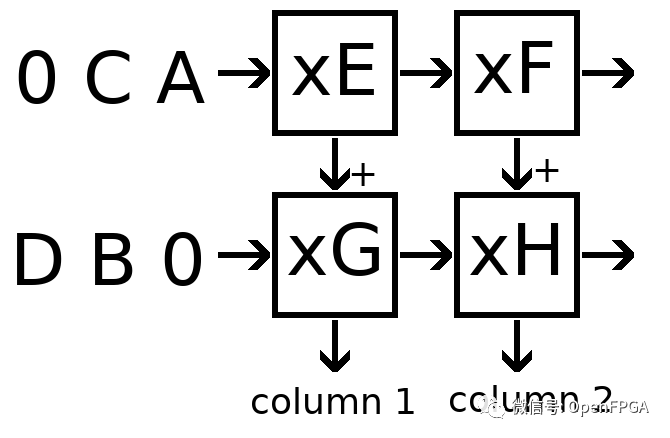
這就是上面構建的陣列!讓我們來看看第一個輸出的執行:
周期 1
左上角從輸入隊列中讀取 A,乘以權重 E 以產生產品 AE。
AE 從上面添加到部分和 0,產生部分和 AE。
激活 A 傳遞到右上角的單元格。
部分和 AE 傳遞到左下角的單元格。
周期 2
左下角從輸入隊列中讀取 B,乘以權重 G 生成產品 BG
BG 從上面添加到部分和 AE,產生部分和 AE + BG
激活 B 傳遞到右下角的單元格
部分和 AE + BG 是一個輸出。
可以看到我們已經正確計算了輸出矩陣的第一項。同時,在第 2 周期中,我們還在左上角計算 CE,在右上角計算 AF。這些將通過單元格傳播,到第 4 周期,將產生整個 2x2 輸出。
這里有一些來自谷歌的圖表,它們提供了更多的視覺畫面。
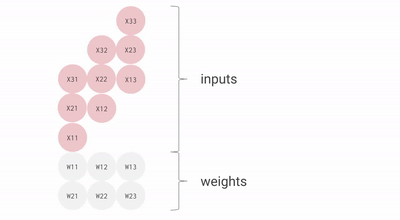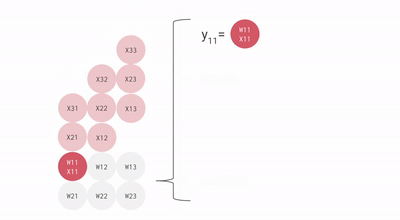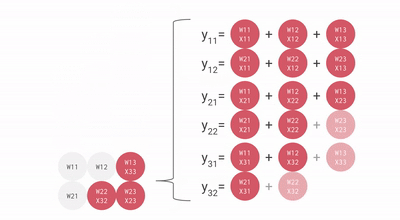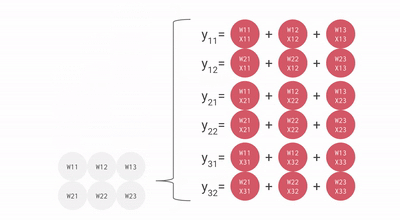
流經數組的數據動畫。相對于本文中的其他圖像,這個 gif 是轉置的——順時針旋轉 90 度,然后水平翻轉。
會看到輸入激活與零交錯,以確保它們在正確的時刻進入數組,并且離開數組的輸出也同樣交錯。完全計算結果矩陣需要 3n-2 個周期,而標準的順序解決方案是 n3。這是一個不錯的結果,將計算量大大降低。
【科普】Xilinx 3D IC技術簡介
谷歌的 MXU 圖。
因為我們正在并行運行 128x128 MAC 操作。在硬件中實現乘法器通常很大且成本很高,但脈動陣列的高密度讓 Google 可以將其中的 16,384 個裝入 MXU。這直接轉化為速度訓練和運行網絡。
權重的加載方式與激活方式大致相同——通過輸入隊列。我們只是發送一個特殊的控制信號(上圖中的紅色)來告訴數組在權重經過時存儲權重,而不是運行 MAC 操作。權重保留在相同的處理元素中,因此我們可以在加載新集合之前發送整個批次,從而減少開銷。
就是這樣!芯片的其余部分很重要,值得一試,但 TPU 的核心優勢在于它的 MXU——一個脈動陣列矩陣乘法單元。
TPU的其余部分
上面設計了出色的脈動陣列,但仍有大量工作需要構建支持和基礎部分以使其運行。首先,我們需要一種將數據輸入和輸出芯片本身的方法。然后我們需要在正確的時間將它進出數組。最后,我們需要一些方法來處理神經網絡中不是矩陣乘法的內容。讓我們看看這一切是如何在硬件中發生的。
完整的系統
下面是舊 TPUv1 的系統圖和布局模型。這些不一定適用于較新的 TPUv2 和 TPUv3 — 自本文檔發布以來,Google 已經進行了一些架構更改。
在最高級別,TPU 被設計為加速器。這意味著它將插入主機系統,主機將加載要在加速器上計算的數據和指令。結果通過相同的接口返回給主機。通過這種模型,加速器(TPU)可以加速耗時且昂貴的矩陣運算,而主機可以處理其他所有事情。
讓我們用一些框圖來檢查加速器內部的內容。我們將逐步介紹這些。
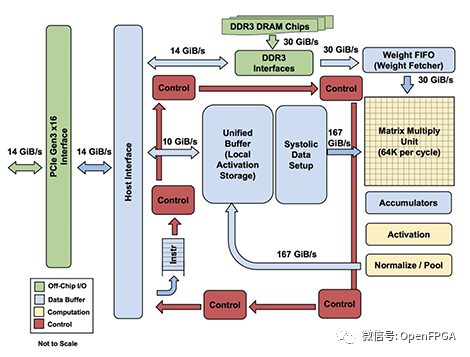
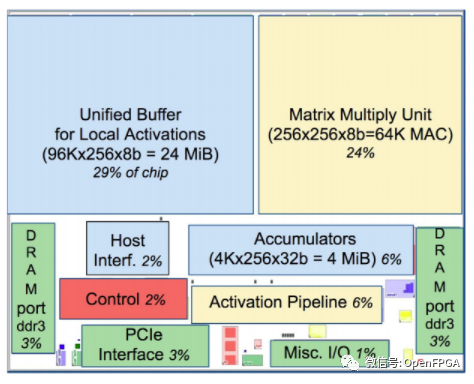
TPUv1 的系統圖和布局模型
主機接口將通過 PCIe 連接到加速器(TPU)。我們可以看到通過這個接口傳輸 3 種形式的數據:權重(到DDR3)、激活activations(到統一緩沖區)和控制指令(到紅色控制路徑)。
批次中所有輸入的權重相同,因此每批次將加載一次。與激活相比,這種情況很少見,因此可以將權重存儲在速度較慢的片外DDR3 DRAM中。我們可以連接主機接口來寫入這個 DDR3,當我們加載模型時我們會把所有的權重放在那里。在計算之前,權重從 DDR3 讀取到權重 FIFO中,這意味著我們可以在計算當前批次時預取下一組權重。
統一緩沖區保存我們的激活。在操作期間,主機需要快速訪問此緩沖區,以讀取結果并寫入新輸入。統一緩沖器直接連接到MXU,這兩個組件占據了芯片空間的最大份額(53%)。該緩沖區最多可容納 384 個尺寸為 256x256 的激活矩陣,這將是芯片支持的最大批次。這些激活被非常頻繁地讀取和寫入,這就是為什么我們將 30% 的布局專用于片上內存,以及 MXU 和統一緩沖區路徑周圍的 167 GiB/s 總線。
MXU 通過Accumulators寫回統一緩沖區。首先,累加器從 MXU 中收集數據。然后,激活管道(Activation Pipeline)應用標準的神經網絡函數(如 ReLU 和 Maxpool),這些函數的計算量不如矩陣乘法。完成后,我們可以將輸出放回統一緩沖區,為下一階段的處理做好準備。
然后是控制流:從主機獲取指令的紅色路徑。該路徑將執行諸如控制 MXU 何時乘法、權重 FIFO 將加載哪些權重或激活管道將執行哪些操作等操作。把它想象成告訴芯片的其余部分做什么的leader。
完整的流程如下:
1、芯片啟動,緩沖區和 DDR3 為空
2、用戶加載 TPU 編譯的模型,將權重放入 DDR3 內存
3、主機用輸入值填充激活緩沖區
4、發送控制信號將一層權重加載到 MXU(通過權重 FIFO)
5、主機觸發執行,激活通過 MXU 傳播到累加器
6、當輸出出來時,它們通過激活管道運行,新層替換緩沖區中的舊層
7、重復 4 到 6 直到我們到達最后一層
8、最后一層的激活被發送回主機
TPUv1 推理的全貌。在較新的 TPUv2 中經歷了類似的事情……
新一代 TPU 允許訓練(即更新權重),因此需要有一條從 MXU 到重量存儲。在 TPUv1 框圖中,情況并非如此。
但是,只要知道 TPUv2 能做什么,我們就可以猜到一些不同之處:
TPUv1 中的 MXU 是一個 8 位整數 256x256 數組,比 TPUv2 中的 16 位 bfloat16 128x128 MXU 更大但精度更低。
TPUv1 中的激活管道被 TPUv2 中的全向量和標量單元所取代。與 TPUv1 中有限的“激活”和“標準化/池”相比,這些功能為其提供了更廣泛的可用功能。
統一緩沖區似乎被高帶寬內存所取代。這將為芯片的其余部分騰出一些空間,但代價是延遲。
這些差異主要是因為 TPUv1 是為推理而非訓練而設計的,因此可以接受低精度算術和較少的操作。升級意味著新一代 TPU 更加靈活——足以讓谷歌輕松地將它們布置在他們的云上。
其他概念
bfloat16
大多數 CPU/GPU 機器學習計算都是使用 32 位浮點數完成的。當我們降到 16 位時,ML 工程師往往更擔心數字的范圍而不是精度。舍入小數點的幾個分數是可以的,但是超出數字表示的最大值或最小值是一件令人頭疼的事情。傳統的 float16 精度很高,但范圍不夠。谷歌對此的回答是 bfloat16 格式,它有更多的位用于指數,而更少的位用于有效位。
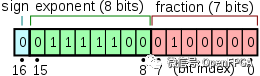
為了比較,浮點數中的位是:
float32:1 位符號,8 位指數,23 位有效數
float16:1 位符號,5 位指數,10 位有效數
bfloat16:1 位符號,8 位指數,7 位有效數
bfloat16.
因為它具有相同數量的指數位,所以 bfloat16 只是 float32 的兩個高位字節。這意味著它的范圍與 float32 大致相同,但精度較低。在實踐中,這種策略效果很好。在 TPU 上,大部分數據仍以 float32 格式存儲。但是,MXU 具有 bfloat16 乘法器和 float32 累加器。較小的乘法器降低了芯片的功率和面積要求,為更多以更快時鐘運行的乘法器留出了空間。這提高了芯片的性能,而不會降低精度。
XLA
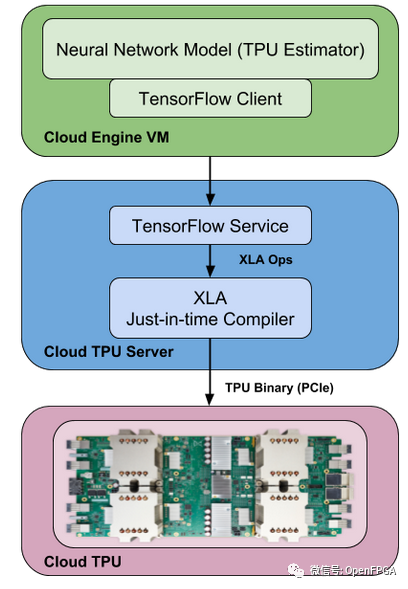
XLA 是一個用于 Tensorflow 后端的實驗性 JIT 編譯器。它將您的 TF 圖轉換為線性代數,并且它有自己的后端可以在 CPU、GPU 或 TPU 上運行。
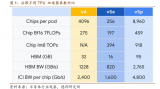
Pods
Google云中的 TPU 存在于“pod”中,它們是具有大量計算能力的大型機架。每個 pod 可容納 64 個 TPUv2 板,用于 11.5 petaflops的工作性能。
單個 TPU 通常不足以以所需的速度訓練大型模型,但訓練涉及頻繁的權重更新,需要在所有相關芯片之間分配。Pod 使 TPU 保持緊密的網絡連接,因此分布在 Pod 上的所有芯片之間的訓練幾乎可以線性擴展。
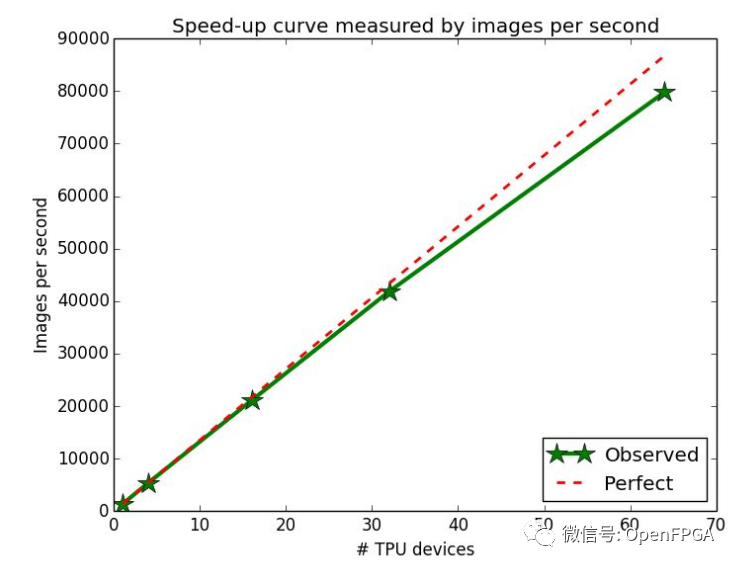
這種線性縮放是一個重要的原則。如果數據科學家想要更多的權力,他們會添加更多的芯片,沒有任何問題。
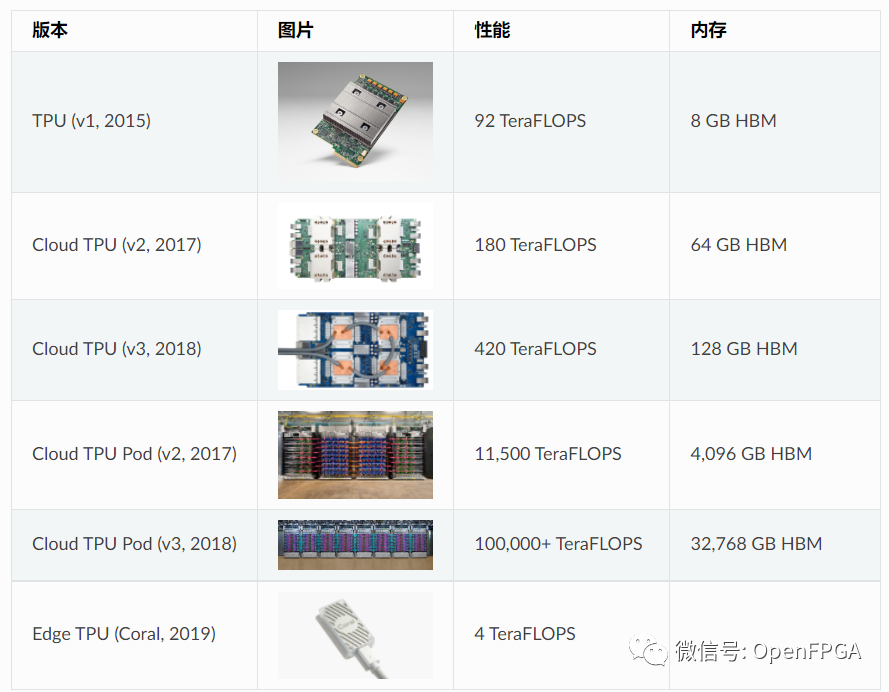
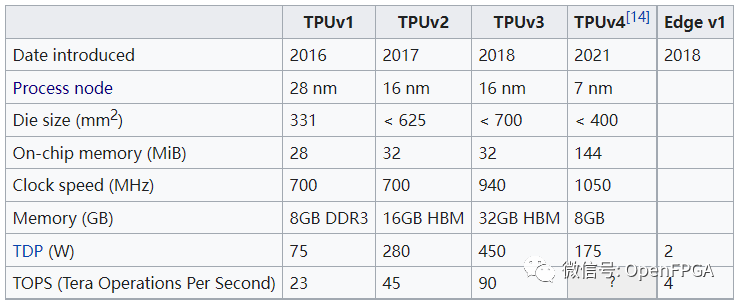
TPU發展歷史
結論
這是我能找到有關TPU工作原理的所有信息,可能她并不完整,但是我希望你明白了TPU的工作原理。
TPU 是一個非常好的硬件,但它可能在 v1 出現之前就已經存在多年了。這主要是因為谷歌做了很多線性代數(由機器學習驅動),這種芯片在商業上變得可行。其他公司也抓住了這一趨勢:Groq是 TPU 項目的衍生產品,英特爾希望盡快開始銷售Nervana芯片,還有 更多的公司 希望加入競爭。專用硬件有望降低訓練和運行模型的成本;希望這將加快我們創新的步伐。
審核編輯 :李倩
-
加速器
+關注
關注
2文章
795瀏覽量
37772 -
機器學習
+關注
關注
66文章
8382瀏覽量
132444 -
TPU
+關注
關注
0文章
138瀏覽量
20701
原文標題:【科普】什么是TPU?
文章出處:【微信號:Open_FPGA,微信公眾號:OpenFPGA】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
《算力芯片 高性能 CPUGPUNPU 微架構分析》第3篇閱讀心得:GPU革命:從圖形引擎到AI加速器的蛻變
【「大模型時代的基礎架構」閱讀體驗】+ 第一、二章學習感受
從TPU v1到Trillium TPU,蘋果等科技公司使用谷歌TPU進行AI計算
TPU編程競賽系列|2024中國國際大學生創新大賽產業命題賽道,算能11項命題入選!

龍芯CPU統一系統架構規范及參考設計下載
谷歌將推出第六代數據中心AI芯片Trillium TPU
Groq推出大模型推理芯片 超越了傳統GPU和谷歌TPU
tpu材料的用途和特點
TPU是什么材料做的
TPU-MLIR開發環境配置時出現的各種問題求解
谷歌TPU v5p超越Nvidia H100,成為人工智能領域的競爭對手
深入學習和掌握TPU硬件架構有困難?TDB助力你快速上手!
CPU與GPU與TPU之間有什么區別?
谷歌發布多模態Gemini大模型及新一代TPU系統Cloud TPU v5p





 工商網監
工商網監
評論