 什么是BERT?為何選擇BERT?
什么是BERT?為何選擇BERT?
BERT 是由 Google 開發的自然語言處理模型,可學習文本的雙向表示,顯著提升在情境中理解許多不同任務中的無標記文本的能力。
BERT 是整個類 BERT 模型(例如 RoBERTa、ALBERT 和 DistilBERT)系列的基礎。
什么是 BERT?
基于 Transformer (變換器)的雙向編碼器表示 (BERT) 技術由 Google 開發,通過在所有層中共同調整左右情境,利用無標記文本預先訓練深度雙向表示。該技術于 2018 年以開源許可的形式發布。Google 稱 BERT 為“第一個深度雙向、無監督式語言表示,僅使用純文本語料庫預先進行了訓練”(Devlin et al. 2018)。
雙向模型在自然語言處理 (NLP) 領域早已有應用。這些模型涉及從左到右以及從右到左兩種文本查看順序。BERT 的創新之處在于借助 Transformer 學習雙向表示,Transformer 是一種深度學習組件,不同于遞歸神經網絡 (RNN) 對順序的依賴性,它能夠并行處理整個序列。因此可以分析規模更大的數據集,并加快模型訓練速度。Transformer 能夠使用注意力機制收集詞語相關情境的信息,并以表示該情境的豐富向量進行編碼,從而同時處理(而非單獨處理)與句中所有其他詞語相關的詞語。該模型能夠學習如何從句段中的每個其他詞語衍生出給定詞語的含義。
之前的詞嵌入技術(如 GloVe 和 Word2vec)在沒有情境的情況下運行,生成序列中各個詞語的表示。例如,無論是指運動裝備還是夜行動物,“bat”一詞都會以同樣的方式表示。ELMo 通過雙向長短期記憶模型 (LSTM),對句中的每個詞語引入了基于句中其他詞語的深度情景化表示。但 ELMo 與 BERT 不同,它單獨考慮從左到右和從右到左的路徑,而不是將其視為整個情境的單一統一視圖。
由于絕大多數 BERT 參數專門用于創建高質量情境化詞嵌入,因此該框架非常適用于遷移學習。通過使用語言建模等自我監督任務(不需要人工標注的任務)訓練 BERT,可以利用 WikiText 和 BookCorpus 等大型無標記數據集,這些數據集包含超過 33 億個詞語。要學習其他任務(如問答),可以使用適合相應任務的內容替換并微調最后一層。
下圖中的箭頭表示三個不同 NLP 模型中從一層到下一層的信息流。
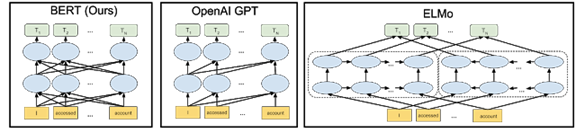
BERT 模型能夠更精細地理解表達的細微差別。例如,處理序列“Bob 需要一些藥。他的胃不舒服,可以給他拿一些抗酸藥嗎?” BERT 能更好地理解 “Bob”、“他的”和“他”都是指同一個人。以前,在“如何填寫 Bob 的處方”這一查詢中,模型可能無法理解第二句話引用的人是 Bob。應用 BERT 模型后,該模型能夠理解所有這些關聯點之間的關系。
雙向訓練很難實現,因為默認情況下,在前一個詞語和下一個詞語的基礎上調節每個詞都包括多層模型中預測的詞語。BERT 的開發者通過遮蔽語料庫中的預測詞語和其他隨機詞語解決了這個問題。BERT 還使用一種簡單的訓練技術,嘗試預測給定的兩個句子 A 和 B:B 和 A 是先后還是隨機關系。
為何選擇 BERT?
自然語言處理是當今許多商業人工智能研究的中心。例如,除搜索引擎外,NLP 還用在了數字助手、自動電話響應和車輛導航領域。BERT 是一項顛覆性技術,它提供基于大型數據集訓練的單一模型,而且已經證實該模型能夠在各種 NLP 任務中取得突破性成果。
BERT 的開發者表示,模型應用范圍很廣(包括解答問題和語言推理),而且無需對任務所需的具體架構做出大量修改。BERT 不需要使用標記好的數據預先進行訓練,因此可以使用任何純文本進行學習。
主要優勢(用例)
BERT 可以針對許多 NLP 任務進行微調。它是翻譯、問答、情感分析和句子分類等語言理解任務的理想之選。
目標式搜索
雖然如今的搜索引擎能夠非常出色地理解人們要尋找的內容(在人們使用正確查詢格式的前提下),但仍可以通過很多方式改善搜索體驗。對于語法能力差或不懂得搜索引擎提供商所用語言的人員而言,體驗可能令人不快。搜索引擎還經常需要用戶嘗試同一查詢的不同變體,才能查詢到理想結果。
用戶每天在 Google 上執行 35 億次搜索,搜索體驗改進后,一天就可以減少 10% 的搜索量,長期累積下來將大幅節省時間、帶寬和服務器資源。從業務角度來看,它還使搜索提供商能夠更好地了解用戶行為,并投放更具針對性的廣告。
通過幫助非技術用戶更準確地檢索信息,并減少因查詢格式錯誤帶來的錯誤,可以更好地理解自然語言,從而提高數據分析和商業智能工具的效果。
輔助性導航
在美國,超過八分之一的人有殘疾,而且許多人在物理和網絡空間中導航的能力受到了限制。對于必須使用語音來控制輪椅、與網站交互和操作周圍設備的人員而言,自然語言處理是生活必需品。通過提高對語音命令的響應能力,BERT 等技術可以提高生活質量,甚至可以在需要快速響應環境的情況下提高人身安全。
BERT 的重要意義
機器學習研究人員
BERT 在自然語言處理方面引發的變革等同于計算機視覺領域的 AlexNet,在該領域具有顯著的革命性意義。僅需替換網絡的最后一層,便可針對一些新任務定制網絡,這項功能意味著用戶可輕松將其應用于任何感興趣的研究領域。無論用戶的目標是翻譯、情感分析還是執行一些尚未提出的新任務,都可以快速配置網絡以進行嘗試。截至目前,有關該模型的引文超過 8000 篇,其衍生用例不斷證明該模型在處理語言任務方面的先進水平。
軟件開發者
由于針對大型數據集預先訓練過的模型的廣泛可用性,BERT 大大減少了先進模型在投入生產時受到的計算限制。此外,將 BERT 及其衍生項納入知名庫(如 Hugging Face)意味著,機器學習專家不需要啟動和運行基礎模型了。
BERT 在自然語言解讀方面達到了新的里程碑,與其他模型相比展現了更強大的功能,能夠理解更復雜的人類語音并能更精確地回答問題。
BERT 為何可在 GPU 上表現更突出
對話式 AI 是人類與智能機器和應用程序(從機器人和汽車到家庭助手和移動應用)互動的基礎構建塊。讓計算機理解人類語言及所有細微差別,并做出適當的反應,這是 AI 研究人員長期以來的追求。但是,在采用加速計算的現代 AI 技術出現之前,構建具有真正自然語言處理 (NLP) 功能的系統是無法實現的。
BERT 在采用 NVIDIA GPU 的超級計算機上運行,以訓練其龐大的神經網絡并實現超高的 NLP 準確性,從而影響已知的人類語言理解領域。雖然目前有許多自然語言處理方法,但讓 AI 具有類似人類的語言能力仍然是難以實現的目標。隨著 BERT 等基于 Transformer 的大規模語言模型的出現,以及 GPU 成為這些先進模型的基礎設施平臺,我們看到困難的語言理解任務快速取得了進展。數十年來,這種 AI 一直備受期待。有了 BERT,這一刻終于到來了。
模型復雜性提升了 NLP 準確性,而規模更大的語言模型可顯著提升問答、對話系統、總結和文章完結等自然語言處理 (NLP) 應用程序的技術水平。BERT-Base 使用 1.1 億個參數創建而成,而擴展的 BERT-Large 模型涉及 3.4 億個參數。訓練高度并行化,因此可以有效利用 GPU 上的分布式處理。BERT 模型已證明能夠有效擴展為 39 億個參數的 Megatron-BERT 等大規模模型。
BERT 的復雜性以及訓練大量數據集方面的需求對性能提出了很高的要求。這種組合需要可靠的計算平臺來處理所有必要的計算,以實現快速執行并提高準確性。這些模型可以處理大量無標記數據集,因此成為了現代 NLP 的創新中心,另外在很多用例中,對于即將推出的采用對話式 AI 應用程序的智能助手而言,這些模型都是上佳之選。
NVIDIA 平臺提供可編程性,可以加速各種不同的現代 AI,包括基于 Transformer 的模型。此外,數據中心擴展設計加上軟件庫,以及對先進 AI 框架的直接支持,為承擔艱巨 NLP 任務的開發者提供無縫的端到端平臺。
在使用 NVIDIA 的 DGX SuperPOD 系統(基于連接了 HDR InfiniBand 的大規模 DGX A100 GPU 服務器集群)進行的一項測試中,NVIDIA 使用 MLPerf Training v0.7 基準實現了 0.81 分鐘的 BERT 訓練時間,創造了記錄。相比之下,Google 的 TPUv3 在同一測試中所用時間超過了 56 分鐘。
審核編輯 :李倩
-
編碼器
+關注
關注
45文章
3595瀏覽量
134157 -
數據中心
+關注
關注
16文章
4688瀏覽量
71956 -
自然語言處理
+關注
關注
1文章
612瀏覽量
13504
原文標題:NVIDIA 大講堂 | 什么是 BERT ?
文章出處:【微信號:NVIDIA_China,微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
TAS5421的參考設計中,BOM表給出的470pF緩沖電容耐壓值為何選擇250V換成50V的耐壓值可以嗎?
內置誤碼率測試儀(BERT)和采樣示波器一體化測試儀器安立MP2110A

M8020A J-BERT 高性能比特誤碼率測試儀
AWG和BERT常見問題解答
llm模型有哪些格式
【大語言模型:原理與工程實踐】大語言模型的基礎技術
斯坦福繼Flash Attention V1和V2又推出Flash Decoding
適配器微調在推薦任務中的幾個關鍵因素

谷歌模型訓練軟件有哪些功能和作用
谷歌大型模型終于開放源代碼,遲到但重要的開源戰略

只修改一個關鍵參數,就會毀了整個百億參數大模型?
模型與人類的注意力視角下參數規模擴大與指令微調對模型語言理解的作用

ChatGPT是一個好的因果推理器嗎?

大語言模型背后的Transformer,與CNN和RNN有何不同

深入理解BigBird的塊稀疏高效實現方案





 工商網監
工商網監
評論