") 機器學習和深度學習算法流程
機器學習和深度學習算法流程
深度學習這幾年特別火,就像5年前的大數據一樣,不過深度學習其主要還是屬于機器學習的范疇領域內,所以這篇文章里面我們來嘮一嘮機器學習和深度學習的算法流程區(qū)別。
機器學習和深度學習算法流程
終于考上人工智能的研究僧啦,不知道機器學習和深度學習有啥區(qū)別,感覺一切都是深度學習。
挖槽,聽說學長已經調了10個月的參數準備發(fā)有2000億參數的T9開天霹靂模型,我要調參發(fā)T10準備拿個Best Paper。
現(xiàn)在搞傳統(tǒng)機器學習相關的研究論文確實占比不太高,有的人吐槽深度學習就是個系統(tǒng)工程而已,沒有數學含金量。
但是無可否認的是深度學習實在太好用啦!極大地簡化了傳統(tǒng)機器學習的整體算法分析和學習流程,更重要的是在一些通用的領域任務刷新了傳統(tǒng)機器學習算法達不到的精度和準確率。
深度學習這幾年特別火,就像5年前的大數據一樣,不過深度學習其主要還是屬于機器學習的范疇領域內,所以這篇文章里面我們來嘮一嘮機器學習和深度學習的算法流程區(qū)別。
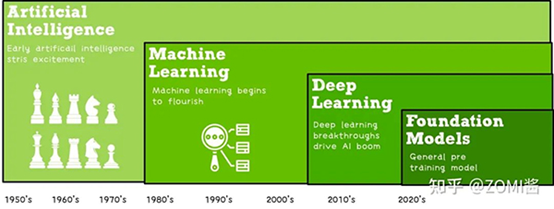
—01—機器學習的算法流程
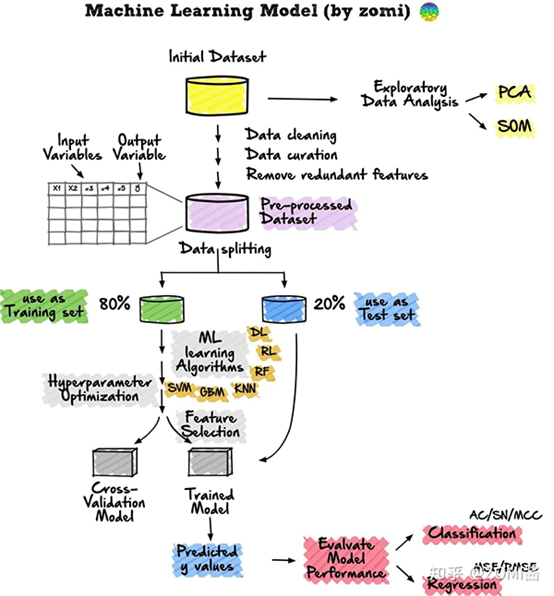
實際上機器學習研究的就是數據科學(聽上去有點無聊),下面是機器學習算法的主要流程:
(1)數據集準備
(2)探索性地對數據進行分析
(3)數據預處理
(4)數據分割
(5)機器學習算法建模
(6)選擇機器學習任務
(7)最后就是評價機器學習算法對實際數據的應用情況如何
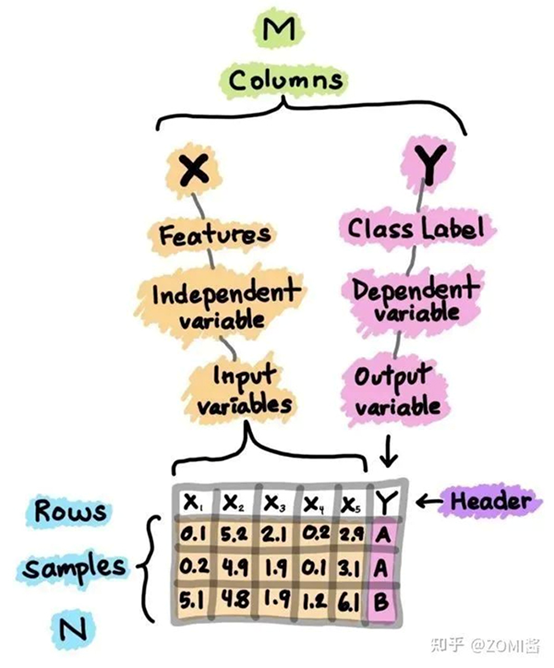
1.1數據集
首先我們要研究的是數據的問題,數據集是構建機器學習模型流程的起點。簡單來說,數據集本質上是一個M×N矩陣,其中M代表列(特征),N代表行(樣本)。
列可以分解為X和Y,X是可以指特征、獨立變量或者是輸入變量。Y也是可以指類別標簽、因變量和輸出變量。
1.2數據分析進行探索性數據分析(Exploratorydata analysis, EDA)是為了獲得對數據的初步了解。EDA主要的工作是:對數據進行清洗,對數據進行描述(描述統(tǒng)計量,圖表),查看數據的分布,比較數據之間的關系,培養(yǎng)對數據的直覺,對數據進行總結等。 探索性數據分析方法簡單來說就是去了解數據,分析數據,搞清楚數據的分布。主要注重數據的真實分布,強調數據的可視化,使分析者能一目了然看出數據中隱含的規(guī)律,從而得到啟發(fā),以此幫助分析者找到適合數據的模型。 在一個典型的機器學習算法流程和數據科學項目里面,我做的第一件事就是通過 "盯住數據",以便更好地了解數據。個人通常使用的三大EDA方法包括:描述性統(tǒng)計平均數、中位數、模式、標準差。
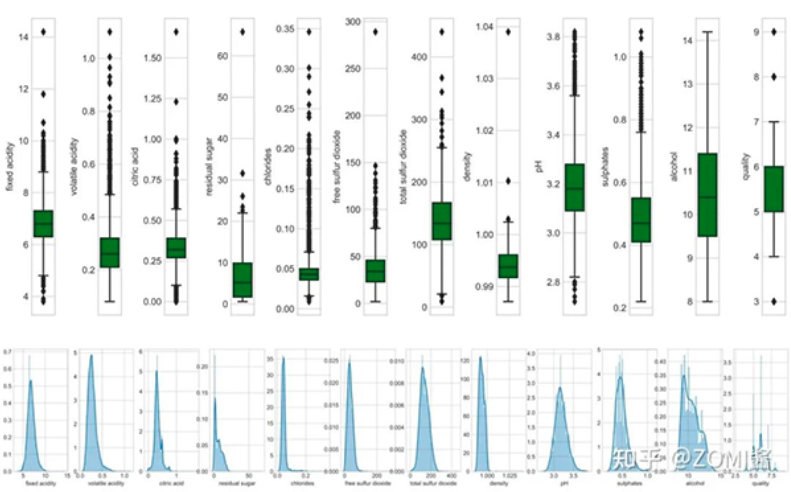
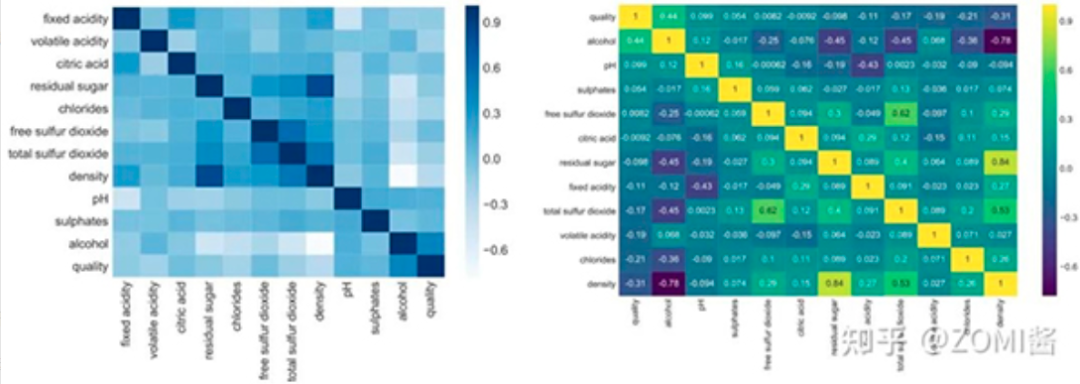
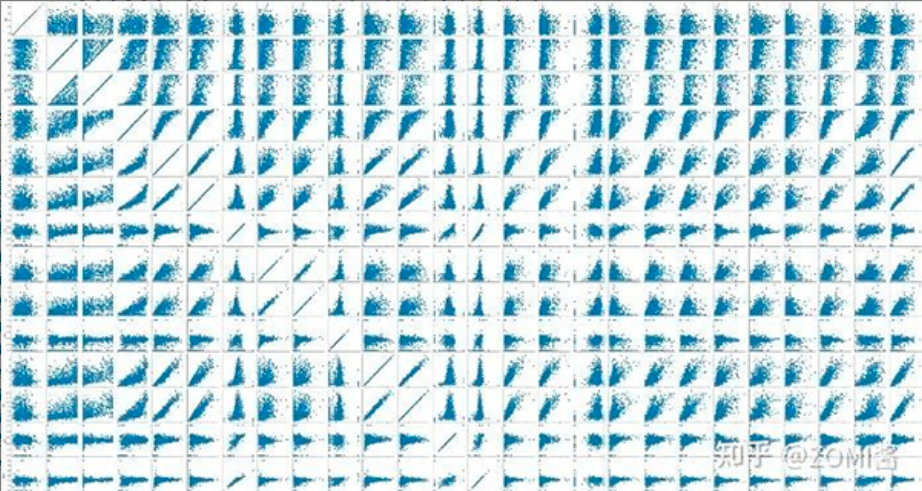
數據可視化
熱力圖(辨別特征內部相關性)、箱形圖(可視化群體差異)、散點圖(可視化特征之間的相關性)、主成分分析(可視化數據集中呈現(xiàn)的聚類分布)等。
數據整形
對數據進行透視、分組、過濾等。
1.3數據預處理
數據預處理,其實就是對數據進行清理、數據整理或普通數據處理。指對數據進行各種檢查和校正過程,以糾正缺失值、拼寫錯誤、使數值正常化/標準化以使其具有可比性、轉換數據(如對數轉換)等問題。
例如對圖像進行resize成統(tǒng)一的大小或者分辨率。
數據的質量將對機器學習算法模型的質量好壞產生很大的影響。因此,為了達到最好的機器學習模型質量,傳統(tǒng)的機器學習算法流程中,其實很大一部分工作就是在對數據進行分析和處理。
一般來說,數據預處理可以輕松地占到機器學習項目流程中80%的時間,而實際的模型建立階段和后續(xù)的模型分析大概僅占到剩余的20%。
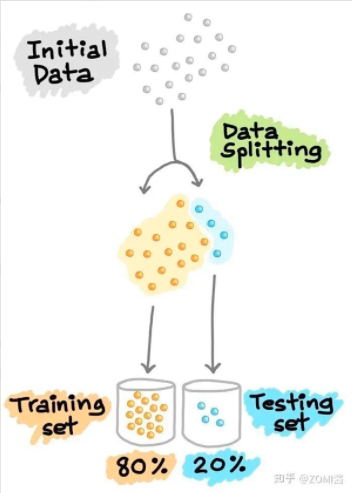
1.4數據分割訓練集 & 測試集
在機器學習模型的開發(fā)流程中,希望訓練好的模型能在新的、未見過的數據上表現(xiàn)良好。為了模擬新的、未見過的數據,對可用數據進行數據分割,從而將已經處理好的數據集分割成2部分:訓練集合測試集。
第一部分是較大的數據子集,用作訓練集(如占原始數據的80%);第二部分通常是較小的子集,用作測試集(其余20%的數據)。
接下來,利用訓練集建立預測模型,然后將這種訓練好的模型應用于測試集(即作為新的、未見過的數據)上進行預測。根據模型在測試集上的表現(xiàn)來選擇最佳模型,為了獲得最佳模型,還可以進行超參數優(yōu)化。
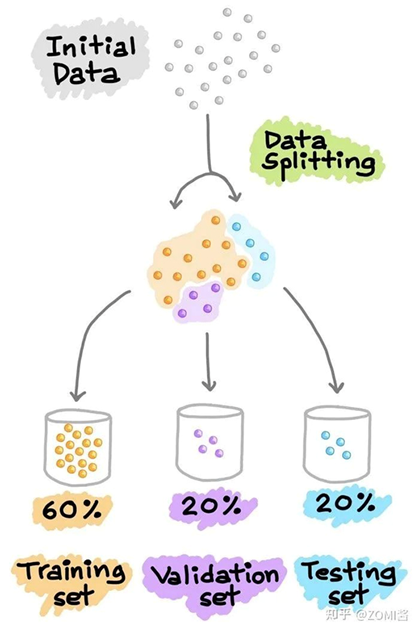
訓練集 & 驗證集 & 測試集
另一種常見的數據分割方法是將數據分割成3部分:
(1)訓練集
(2)驗證集
(3) 測試集
訓練集用于建立預測模型,同時對驗證集進行評估,據此進行預測,可以進行模型調優(yōu)(如超參數優(yōu)化),并根據驗證集的結果選擇性能最好的模型。
驗證集的操作方式跟訓練集類似。不過值得注意的是,測試集不參與機器學習模型的建立和準備,是機器學習模型訓練過程中單獨留出的樣本集,用于調整模型的超參數和對模型的能力進行初步評估。通常邊訓練邊驗證,這里的驗證就是用驗證集來檢驗模型的初步效果。
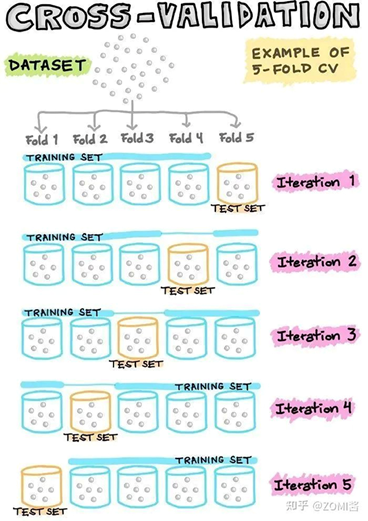
交叉驗證
實際上數據是機器學習流程中最寶貴的,為了更加經濟地利用現(xiàn)有數據,通常使用N倍交叉驗證,將數據集分割成N個。在這樣的N倍數據集中,其中一個被留作測試數據,而其余的則被用作建立模型的訓練數據。通過反復交叉迭代的方式來對機器學習流程進行驗證。
這種交叉驗證的方法在機器學習流程中被廣泛的使用,但是深度學習中使用得比較少哈。
1.5機器學習算法建模下面是最有趣的部分啦,數據篩選和處理過程其實都是很枯燥乏味的,現(xiàn)在可以使用精心準備的數據來建模。根據taget變量(通常稱為Y變量)的數據類型,可以建立一個分類或回歸模型。機器學習算法
機器學習算法可以大致分為以下三種類型之一:
(1)監(jiān)督學習
是一種機器學習任務,建立輸入X和輸出Y變量之間的數學(映射)關系。這樣的(X、Y)對構成了用于建立模型的標簽數據,以便學習如何從輸入中預測輸出。
(2)無監(jiān)督學習
是一種只利用輸入X變量的機器學習任務。X變量是未標記的數據,學習算法在建模時使用的是數據的固有結構。
(3)強化學習
是一種決定下一步行動方案的機器學習任務,它通過試錯學習(trial and error learning)來實現(xiàn)這一目標,努力使reward回報最大化。
參數調優(yōu)
傳說中的調參俠主要干的就是這個工作啦。超參數本質上是機器學習算法的參數,直接影響學習過程和預測性能。由于沒有萬能的超參數設置,可以普遍適用于所有數據集,因此需要進行超參數優(yōu)化。
以隨機森林為例。在使用randomForest時,通常會對兩個常見的超參數進行優(yōu)化,其中包括mtry和ntree參數。mtry(maxfeatures)代表在每次分裂時作為候選變量隨機采樣的變量數量,而ntree(nestimators)代表要生長的樹的數量。
另一種在10年前仍然非常主流的機器學習算法是支持向量機SVM。需要優(yōu)化的超參數是徑向基函數(RBF)內核的C參數和gamma參數。C參數是一個限制過擬合的懲罰項,而gamma參數則控制RBF核的寬度。
調優(yōu)通常是為了得出超參數的較佳值集,很多時候不要去追求找到超參一個最優(yōu)值,其實調參俠只是調侃調侃,真正需要理解掌握算法原理,找到適合數據和模型的參數就可以啦。
特征選擇
特征選擇從字面上看就是從最初的大量特征中選擇一個特征子集的過程。除了實現(xiàn)高精度的模型外,機器學習模型構建最重要的一個方面是獲得可操作的見解,為了實現(xiàn)這一目標,能夠從大量的特征中選擇出重要的特征子集非常重要。
特征選擇的任務本身就可以構成一個全新的研究領域,在這個領域中,大量的努力都是為了設計新穎的算法和方法。從眾多可用的特征選擇算法中,一些經典的方法是基于模擬退火和遺傳算法。除此之外,還有大量基于進化算法(如粒子群優(yōu)化、蟻群優(yōu)化等)和隨機方法(如蒙特卡洛)的方法。
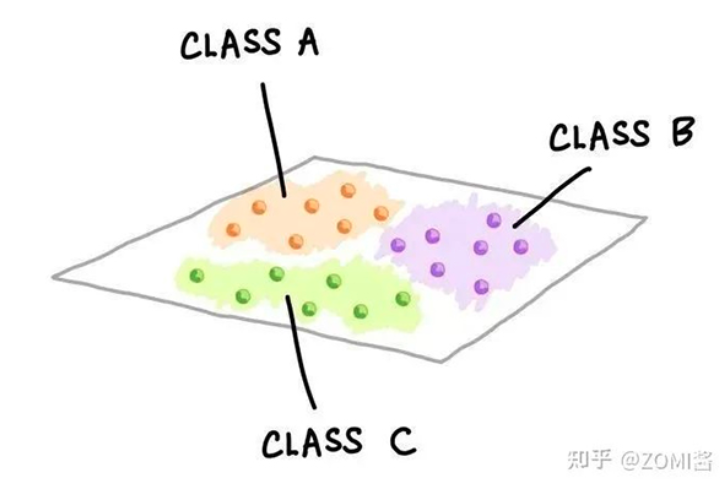
1.6機器學習任務在監(jiān)督學習中,兩個常見的機器學習任務包括分類和回歸。分類一個訓練好的分類模型將一組變量作為輸入,并預測輸出的類標簽。下圖是由不同顏色和標簽表示的三個類。每一個小的彩色球體代表一個數據樣本。三類數據樣本在二維中的顯示,這種可視化圖可以通過執(zhí)行PCA分析并顯示前兩個主成分(PC)來創(chuàng)建;或者也可以選擇兩個變量的簡單散點圖可視化。
性能指標如何知道訓練出來的機器學習模型表現(xiàn)好或壞?就是使用性能評價指標(metrics),一些常見的評估分類性能的指標包括準確率(AC)、靈敏度(SN)、特異性(SP)和馬太相關系數(MCC)。回歸最簡單的回歸模式,可以通過以下簡單等式很好地總結:Y = f(X)。其中,Y對應量化輸出變量,X指輸入變量,f指計算輸出值作為輸入特征的映射函數(從機器學習模型中得到)。
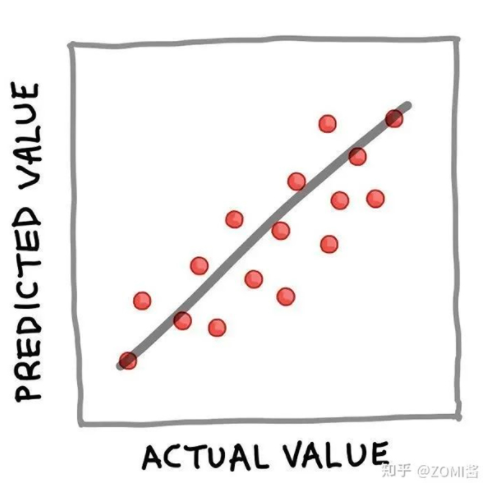
上面的回歸例子公式的實質是,如果X已知,就可以推導出Y。一旦Y被計算(預測)出來,一個流行的可視化方式是將實際值與預測值做一個簡單的散點圖,如下圖所示。 對回歸模型的性能進行評估,以評估擬合模型可以準確預測輸入數據值的程度。評估回歸模型性能的常用指標是確定系數(R2)。此外,均方誤差(MSE)以及均方根誤差(RMSE)也是衡量殘差或預測誤差的常用指標。 —02—深度學習算法流程
深度學習實際上是機器學習中的一種范式,所以他們的主要流程是差不多的。深度學習則是優(yōu)化了數據分析,建模過程的流程也是縮短了,由神經網絡統(tǒng)一了原來機器學習中百花齊放的算法。
在深度學習正式大規(guī)模使用之前呢,機器學習算法流程中要花費很多時間去收集數據,然后對數據進行篩選,嘗試各種不同的特征提取機器學習算法,或者結合多種不同的特征對數據進行分類和回歸。
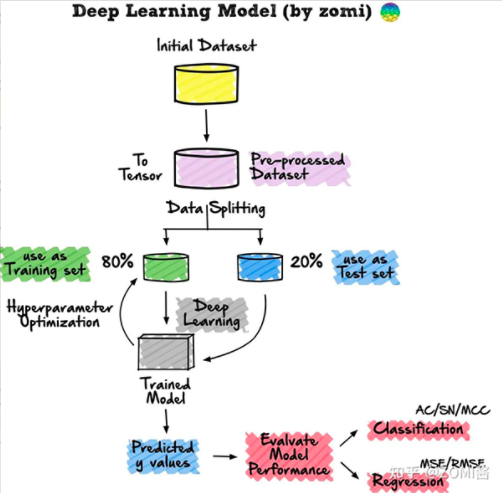
下面是機器學習算法的主要流程:主要從
(1)數據集準備 (2)數據預處理 (3)數據分割 (4)定義神經網絡模型 (5)訓練網絡 深度學習不需要我們自己去提取特征,而是通過神經網絡自動對數據進行高維抽象學習,減少了特征工程的構成,在這方面節(jié)約了很多時間。 但是同時因為引入了更加深、更復雜的網絡模型結構,所以調參工作變得更加繁重啦。例如:定義神經網絡模型結構、確認損失函數、確定優(yōu)化器,最后就是反復調整模型參數的過程。
審核編輯 :李倩
-
神經網絡
+關注
關注
42文章
4717瀏覽量
99983 -
機器學習
+關注
關注
66文章
8306瀏覽量
131834 -
深度學習
+關注
關注
73文章
5422瀏覽量
120584
原文標題:機器學習和深度學習的區(qū)別到底是什么?
文章出處:【微信號:cserversoft,微信公眾號:中服云工業(yè)新風向】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
利用Matlab函數實現(xiàn)深度學習算法
深度學習中的無監(jiān)督學習方法綜述
深度學習的基本原理與核心算法
人工智能、機器學習和深度學習是什么
機器學習算法原理詳解
深度學習與傳統(tǒng)機器學習的對比
機器學習的經典算法與應用

為什么深度學習的效果更好?
目前主流的深度學習算法模型和應用案例

深度學習在人工智能中的 8 種常見應用
深度學習算法和傳統(tǒng)機器視覺助力工業(yè)外觀檢測
機器學習的基本流程和十大算法

瑞薩電子深度學習算法在缺陷檢測領域的應用





 工商網監(jiān)
工商網監(jiān)
評論