 數據驅動的系統辨識研究
數據驅動的系統辨識研究
我們在上一篇深度學習用于動態系統建模(點擊跳轉)的文章中針對動態系統的特性與數據驅動的動機進行了論述。我們介紹了動態系統當前輸出不僅依賴于當前的輸入,還依賴于系統過去的行為(歷史輸入和歷史輸出)。我們也介紹了什么場景下使用深度學習/系統辨識來進行系統建模。本文我們主要介紹數據驅動的另一個主題:系統辨識。 為了更好地理解,我們可以設計一個簡單的線性系統[鏈接1],更具體的是一個連續時間狀態空間模型,來解釋系統辨識的適用場景:
? 我們創建一個旋轉體的狀態空間模型,包括轉動慣量J,阻尼力F和三個旋轉軸:
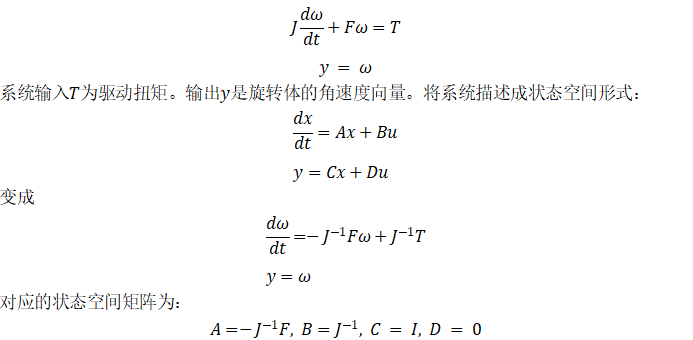
變成
對應的狀態空間矩陣為:
J = [8 -3 -3; -3 8 -3; -3 -3 8];
F = 0.2*eye(3);
A = -JF;
B = inv(J);
C = eye(3);
D = 0;
sys_mimo = ss(A,B,C,D);
?我們隨機生成控制輸入向量u的時間序列,作用于這個系統上,得到系統的輸出y。[鏈接2]
(滑動窗口查看完整代碼)
% 構建隨機步長的二值三維序列,N采樣數,Nu是控制量的維度
u = idinput([N,Nu],'prbs',frequency,Range);
for i = 1:Nu
% 為二值序列隨機賦值,得到不同幅值的序列
idx = find(diff(u(:,i))) + 1;
idx = [1;idx];
for j = 1:length(idx) - 1
u(idx(j):idx(j+1)-1,i) = randn*u(idx(j));
end
end
t = (1:N)*dt;
% 將控制輸入序列u作用系統上得到系統輸出
[y,t] = lsim(sys_mimo,u,t);
輸入 u=[u1 u2 u3] 應三個維度的扭矩輸入,輸出對應 y=[y1 y2 y3] 三個維度的。如下: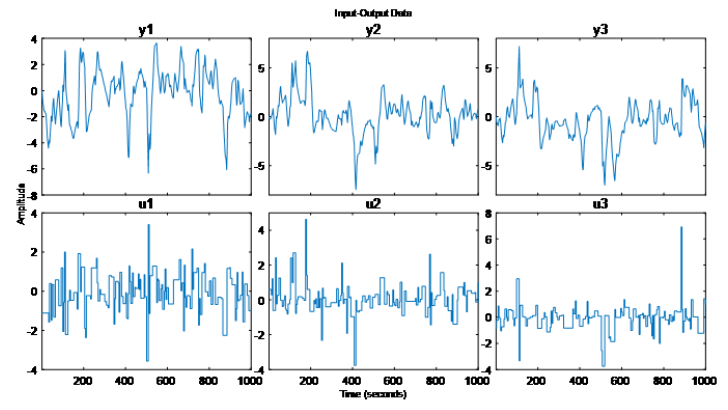 我們現在有系統的輸入 u,也有系統的輸出 y,這不就是數據科學的菜嗎,即使不知道系統模型,是不是也能“擬合”出來 y 和 u 的一個機器學習代理模型 (surrogate model)?我們工程中碰到的動態系統通常也是可以獲取系統輸入和輸出,當然比這個線性系統復雜多了,那能不能也用這種思路得到 y 和 u 的數據模型?接下來,是不是我們只需要把 y 和 u 作為輸出(真值)和輸入(特征)給到機器學習/深度學習算法,我們就能得到這樣一個動態系統的數據模型呢?并非那么簡單。原因我們上一篇文章也解釋過,動態系統的特殊性,狀態在時間維度上是有依賴的,并非某時刻有相同的控制輸入就有相同的狀態輸出,輸出也取決于當前系統的狀態。我們不妨就用剛才的數據 y 的第一個維度 y1 和 u,直接用幾種靜態機器學習算法對比動態系統辨識算法來說明這種現象:a)使用高斯過程回歸進行建模[鏈接3]
我們現在有系統的輸入 u,也有系統的輸出 y,這不就是數據科學的菜嗎,即使不知道系統模型,是不是也能“擬合”出來 y 和 u 的一個機器學習代理模型 (surrogate model)?我們工程中碰到的動態系統通常也是可以獲取系統輸入和輸出,當然比這個線性系統復雜多了,那能不能也用這種思路得到 y 和 u 的數據模型?接下來,是不是我們只需要把 y 和 u 作為輸出(真值)和輸入(特征)給到機器學習/深度學習算法,我們就能得到這樣一個動態系統的數據模型呢?并非那么簡單。原因我們上一篇文章也解釋過,動態系統的特殊性,狀態在時間維度上是有依賴的,并非某時刻有相同的控制輸入就有相同的狀態輸出,輸出也取決于當前系統的狀態。我們不妨就用剛才的數據 y 的第一個維度 y1 和 u,直接用幾種靜態機器學習算法對比動態系統辨識算法來說明這種現象:a)使用高斯過程回歸進行建模[鏈接3]
% 訓練回歸模型
regressionGP = fitrgp(...
predictors,...
response,...
'BasisFunction','constant',...
'KernelFunction','rationalquadratic',...
'Standardize',true);
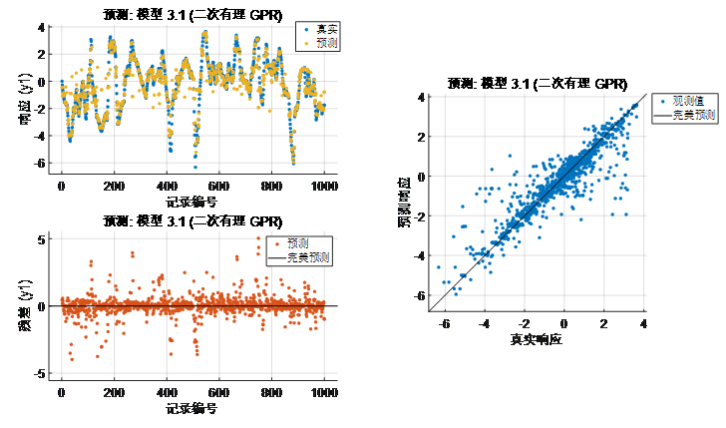 圖表 1高斯過程回歸RMSE(Validation):0.7953a) 梯度提升集成回歸[鏈接4]
圖表 1高斯過程回歸RMSE(Validation):0.7953a) 梯度提升集成回歸[鏈接4]% 訓練回歸模型
template = templateTree(...
'MinLeafSize',11, ...
'NumVariablesToSample',3);
regressionEnsemble = fitrensemble(...
predictors, ...
response, ...
'Method','LSBoost', ...
'NumLearningCycles',465, ...
'Learners', template,...
'LearnRate',0.2277131533235215);
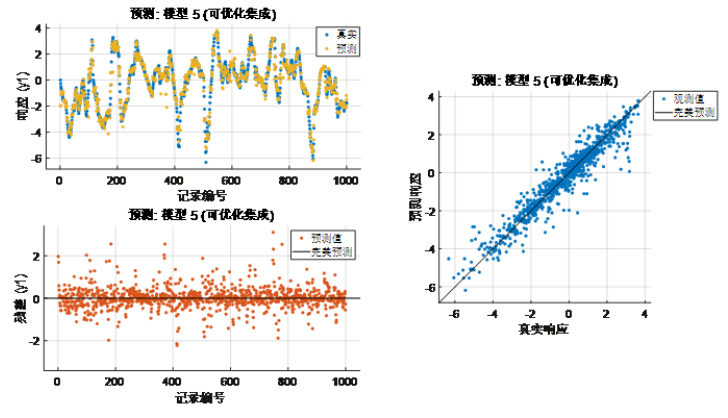 圖表 2 梯度提升集成RMSE(Validation):0.5279從上面的高斯過程和梯度提升樹表現結果來看,雖然可以捕捉一些系統的特性,尤其梯度提升算法在精度上比高斯過程也有一定的提升,但誤差還是較大,系統瞬態特征被“平均”了。上述方式訓練的機器學習靜態模型,在某瞬時只要輸入 u 是相同的,那么輸出 y 也是相同的,這與我們提到的動態系統當前時刻的輸出不止取決于輸入,還依賴于當前系統狀態(換句話說即使在某個時刻相同的輸入,系統也可以有不同的輸出)的特性是不相符合的。當然,可以通過一些特征衍生(例如不同尺度滑窗作用在輸入序列上生成新的特征等)的手段得到能夠反映狀態變化的多尺度特征用于模型訓練,這樣的方式也使一些統計方法或機器學習模型或前饋神經網絡等靜態模型可以用于動態系統建模(上篇文章我們也介紹了電池、電機的使用示例)。b) 如果我們換個思路(系統辨識),假使我們提前已經清楚這個系統可以用一個狀態空間模型表達,我們直接用動態模型來“擬合”這個動態系統,我們看看效果:nx = 3;sys = ssest(result,nx,'Ts',dt); % 進行狀態空間模型系統辨識compare(result,sys) % 查看訓練結果其實不必看結果我們也已經估摸到結果可以達到100% 的準確度,如下圖。當然這個例子并非嚴謹,我們只看了訓練過程,也沒有準備測試數據,數據本身也沒有噪聲,但對于說明系統辨識的應用場景還是比較直觀的。
圖表 2 梯度提升集成RMSE(Validation):0.5279從上面的高斯過程和梯度提升樹表現結果來看,雖然可以捕捉一些系統的特性,尤其梯度提升算法在精度上比高斯過程也有一定的提升,但誤差還是較大,系統瞬態特征被“平均”了。上述方式訓練的機器學習靜態模型,在某瞬時只要輸入 u 是相同的,那么輸出 y 也是相同的,這與我們提到的動態系統當前時刻的輸出不止取決于輸入,還依賴于當前系統狀態(換句話說即使在某個時刻相同的輸入,系統也可以有不同的輸出)的特性是不相符合的。當然,可以通過一些特征衍生(例如不同尺度滑窗作用在輸入序列上生成新的特征等)的手段得到能夠反映狀態變化的多尺度特征用于模型訓練,這樣的方式也使一些統計方法或機器學習模型或前饋神經網絡等靜態模型可以用于動態系統建模(上篇文章我們也介紹了電池、電機的使用示例)。b) 如果我們換個思路(系統辨識),假使我們提前已經清楚這個系統可以用一個狀態空間模型表達,我們直接用動態模型來“擬合”這個動態系統,我們看看效果:nx = 3;sys = ssest(result,nx,'Ts',dt); % 進行狀態空間模型系統辨識compare(result,sys) % 查看訓練結果其實不必看結果我們也已經估摸到結果可以達到100% 的準確度,如下圖。當然這個例子并非嚴謹,我們只看了訓練過程,也沒有準備測試數據,數據本身也沒有噪聲,但對于說明系統辨識的應用場景還是比較直觀的。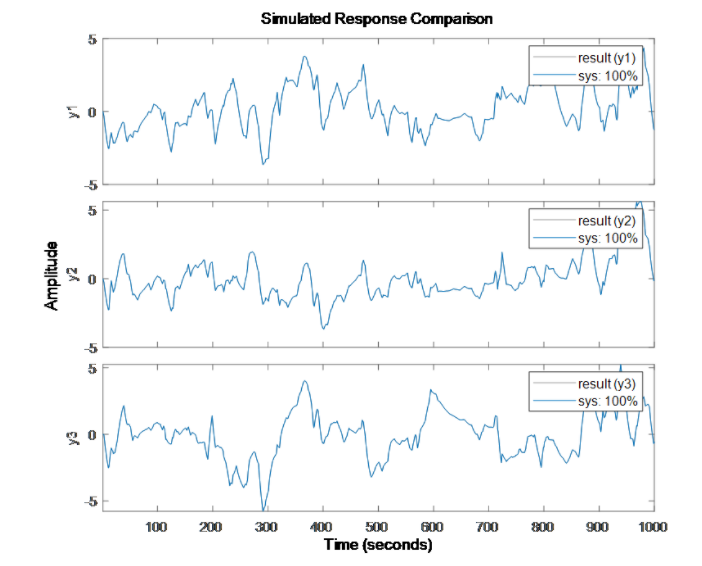
系統辨識利用測量得到的系統輸入和輸出信號來給那些不容易通過第一原理建模的動態系統構建數學模型。可以通過采集系統的輸入 - 輸出的時域和頻域數據來辨識連續時間或離散時間模型: 包括線性系統辨識,例如傳遞函數,過程模型,狀態空間模型,以及非線性系統動態特性辨識,Hammerstein-Weiner 模型和 NARX(帶外部輸入的非線性自回歸,包含小波網絡,樹分類,sigmoid 網絡等)模型。另外,如果我們對系統結構比較熟悉,也可以利用已有的理論定義含參的模型框架(微分方程),然后通過 Grey-Box 進行模型參數辨識。辨識計算的過程就是模型參數迭代的過程(類似優化算法),方法包括最大似然、預測誤差最小化 (PEM) 和子空間系統辨識。最后可以使用辨識好的模型進行響應預測與系統仿真。總結下來整個流程即:
 接下來我們通過 MATLAB 自帶文檔示例([鏈接5],示例中提到了數據來源和參考文獻[1],Dr. Jiandong Wang 和 Dr. Akira Sano)來介紹上述提到的不同的模型。也鼓勵大家多多查閱幫助文檔。通過該示例,我們展示如何使用阻尼器的速度和阻尼力的測量數據來對系統創建線性、非線性 ARX 和 Hammerstein-Wiener 模型。
接下來我們通過 MATLAB 自帶文檔示例([鏈接5],示例中提到了數據來源和參考文獻[1],Dr. Jiandong Wang 和 Dr. Akira Sano)來介紹上述提到的不同的模型。也鼓勵大家多多查閱幫助文檔。通過該示例,我們展示如何使用阻尼器的速度和阻尼力的測量數據來對系統創建線性、非線性 ARX 和 Hammerstein-Wiener 模型。示例背景介紹和數據準備
磁流變阻尼器是一種半主動控制裝置,用于降低動態結構的振動。磁流變液的粘度取決于輸入電壓/電流,因此可提供可控的阻尼力。為了研究這個系統的動態性能,將磁流變阻尼器一端固定在地面上,另一端連接到振動臺。每 0.005s 采樣一次阻尼力 f(t)。每 0.001s 采樣一次位移,用于在 0.005s 的采樣周期內估計速度 v(t)。系統單輸入單輸出。輸入 v(t)為阻尼器的速度 [cm/s],輸出為阻尼力 [N]。% F, V, Ts是load mrdamper.mat后加載的數據,將 F (output force), V (input% velocity) 和 Ts (sample time)封裝到iddata對象中.z = iddata(F, V, Ts,'Name', 'MR damper', ... 'InputName', 'v', 'OutputName', 'f',... 'InputUnit', 'cm/s', 'OutputUnit', 'N'); 將這個數據集 z 分成兩個子集,前 2000 個樣本 (ze) 用于估計/訓練,其余的 (zv) 用于驗證結果。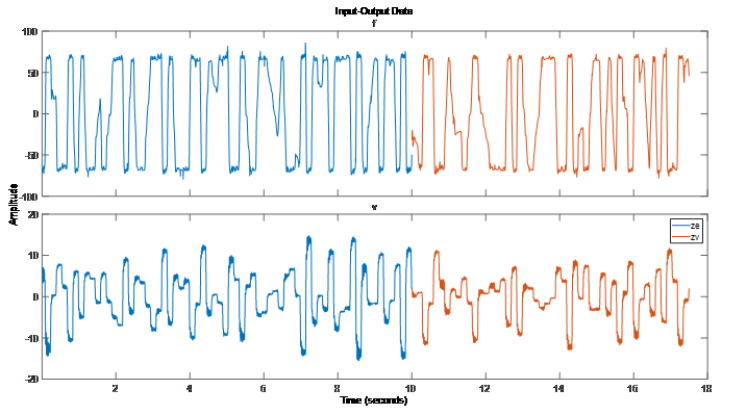
幾種線性系統模型
首先嘗試從簡單的線性模型開始。如果線性模型不能提供令人滿意的結果,那它也可以作為探索非線性模型的初值。ARX(Autoregressive with Extra Input) 模型ARX模型全稱帶外部輸入的自回歸(Autoregressive with Extra Input)。模型結構方程:
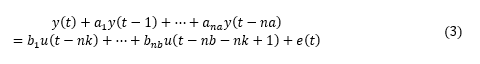
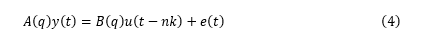
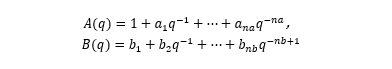 ?我們首先利用 ARX 模型來進行模型階數推薦。階數的定義取決于模型的類型。通常模型最優階數是通過試錯得到的。但是線性 ARX 模型的階數可以通過 arxstruc 和 selstruc 等函數自動計算出來。由此得到的階數也可以作為非線性模型嘗試使用的階數。我們先試著確定線性 ARX 模型的最優階數。V = arxstruc(ze,zv,struc(1:5, 1:5,1:5));% 嘗試讓na, nb, nk在[1:5]取值Order = selstruc(V,'aic') % 根據Akaike's Information Criterion 選擇階數Order =2 4 1AIC 準則選擇 Order = [na nb nk]=[2 4 1],即在選擇的 ARX 模型結構中,阻尼力 f(t) 使用 f(t-1)、f(t-2)、v(t-1)、v(t-2)、v(t-3)和v(t-4) 6 個回歸量 (regressor) 進行預測。我們先按前面 selstruc 推薦的階數對應的 ARX 模型進行估計:LinMod1 = arx(ze, [2 4 1]);% ARX 模型 Ay = Bu + e, 形式同上面方程(4)OE 模型
?我們首先利用 ARX 模型來進行模型階數推薦。階數的定義取決于模型的類型。通常模型最優階數是通過試錯得到的。但是線性 ARX 模型的階數可以通過 arxstruc 和 selstruc 等函數自動計算出來。由此得到的階數也可以作為非線性模型嘗試使用的階數。我們先試著確定線性 ARX 模型的最優階數。V = arxstruc(ze,zv,struc(1:5, 1:5,1:5));% 嘗試讓na, nb, nk在[1:5]取值Order = selstruc(V,'aic') % 根據Akaike's Information Criterion 選擇階數Order =2 4 1AIC 準則選擇 Order = [na nb nk]=[2 4 1],即在選擇的 ARX 模型結構中,阻尼力 f(t) 使用 f(t-1)、f(t-2)、v(t-1)、v(t-2)、v(t-3)和v(t-4) 6 個回歸量 (regressor) 進行預測。我們先按前面 selstruc 推薦的階數對應的 ARX 模型進行估計:LinMod1 = arx(ze, [2 4 1]);% ARX 模型 Ay = Bu + e, 形式同上面方程(4)OE 模型這里先簡單介紹一下OE模型,它和傳遞函數相同,用多項式的比描述系統的輸入和輸出之間的關系。
模型階數等于分母多項式的階數。分母多項式的根稱為模型極點。分子多項式的根稱為模型零點。傳遞函數模型的參數是它的極點(階數 nf)、零點(階數 nb)和傳輸延遲(階數 nk)。離散時間模型形式為:
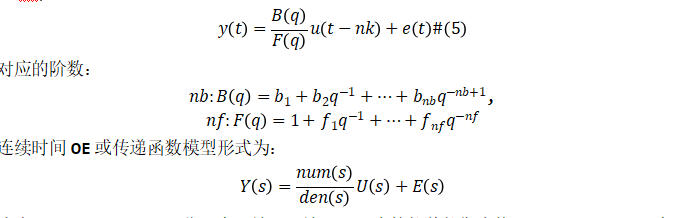
式中,Y(s)、U(s)、E(s) 分別表示輸出、輸入、噪聲的拉普拉斯變換。num(s)和 den(s)表示分子和分母多項式,定義了輸入和輸出之間的關系。
同樣我們用上面推薦的階數進行輸出誤差模型(OE)估計。LinMod2 = oe(ze, [4 2 1]); % OE 模型 y = B/F u + e,形式同方程(5)狀態空間模型
狀態空間模型用一組狀態變量的一階微分(連續時間)或差分(離散時間)方程來描述系統,而不是用一個或多個 n 階微分或差分方程來描述系統。狀態變量 x(t) 可以從測量的輸入-輸出數據中抽象出來的,但在實驗中它們本身不存在或不可測量的。狀態方程模型只需要你指定一個輸入,即這個模型階數 n。模型階數等于 x(t) 的維數,它和對應的線性差分方程中輸入輸出的延遲數相關,但不一定相等。定義參數化狀態空間模型時,連續時間形式通常比離散時間形式容易,因為連續時間就跟你寫物理常微分方程類似。連續時間狀態空間模型有如下形式:
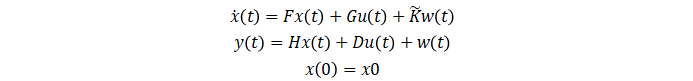
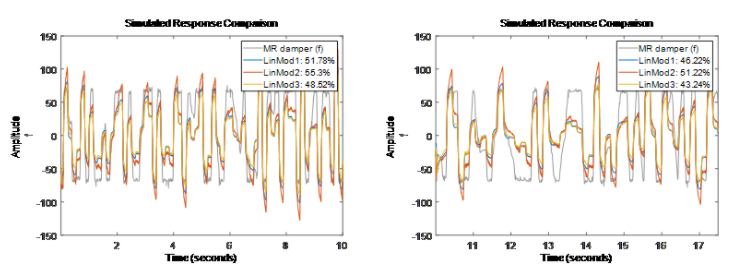
從驗證集的結果看最好的模型擬合有 51% 的擬合度(擬合度即 NRMSE值,100(1-
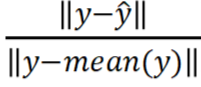 ),其中y是真實值,
),其中y是真實值,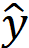 ?是模型預測值)。幾種非線性系統模型非線性 ARX 模型
?是模型預測值)。幾種非線性系統模型非線性 ARX 模型前面的嘗試看上去線性模型精度還有待提高,我們嘗試用 Nonlinear ARX (IDNLARX)模型。我們也可以用 advice 函數來查看系統的輸入輸出數據的非線性程度。
advice(ze, 'nonlinearity') % 查看系統的非線性建議There is an indication of nonlinearity in the data.A nonlinear ARX model of order [4 4 1] and idTreePartition function performs better prediction of output than the corresponding ARX model of the same order. Consider using nonlinear models, such as IDNLARX, or IDNLHW. You may also use the "isnlarx" command to test for nonlinearity with more options.非線性ARX模型對 ARX 做了一些擴展。它在結構中添加了非線性函數,如小波和 sigmoid 網絡,可以模擬復雜的非線性行為。對比線性 ARX 模型,見方程 (3),我們重新組織一下方程 (3),把當前輸出 y(t)寫成過去輸出 + 當前輸入 + 過去輸入之前權重和的形式, 我們把延遲數 nk 先設置成 0,噪聲也不考慮,模型結構簡化為:
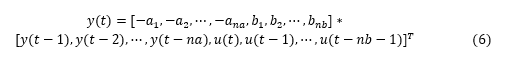
- 與方程 (6)不同處在于輸出 y(t)與回歸量之間的關系不是線性映射,而是一個非線性的映射 F。
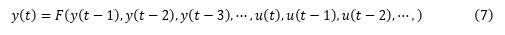
- F 的輸入也就是模型的回歸量 (regressors),這些回歸量對于線性 ARX 來說都是原始輸入和輸出的一些延遲項,非線性 ARX 則可以更復雜,可以是各種輸入輸出的非線性組合,例如:y(t-1)2,y(t-2)*u(t-1),abs(u(t-1)),max(y(t-3)*u(t-1),-10)。
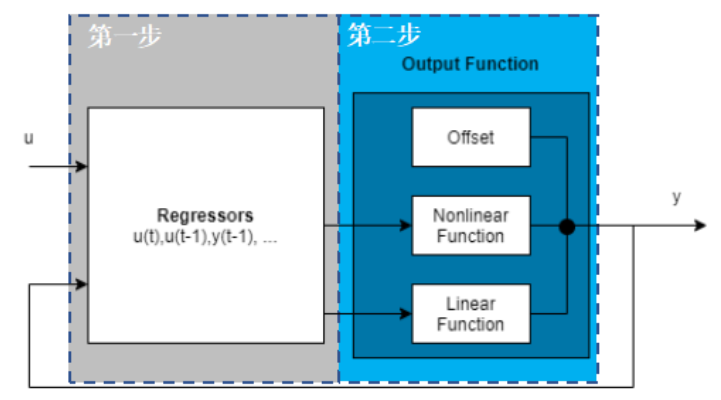 主要通過兩步來計算輸出有 y(t)1. 根據當前輸入 u(t)、歷史輸入 u(t-1)···、歷史輸出 y(t-1)··· 計算這些回歸量 (regressor) 的值。這些回歸量可以認為就是對應機器學習模型的特征量 (predictor),可以是線性項,例如 u(t-1),y(t-3),可以是多階多項式項 u(t-1)2,也可以是一些自定義的變換后的非線性項,例如 u(t-1)*y(t-3)。你可以把這些回歸量作為輸入指定給模型中的線性函數或者非線性函數。2. 使用輸出函數(同時包含線性和非線性兩部分)將前面計算的回歸量 regressor 映射到輸出。例如下面這個函數:
主要通過兩步來計算輸出有 y(t)1. 根據當前輸入 u(t)、歷史輸入 u(t-1)···、歷史輸出 y(t-1)··· 計算這些回歸量 (regressor) 的值。這些回歸量可以認為就是對應機器學習模型的特征量 (predictor),可以是線性項,例如 u(t-1),y(t-3),可以是多階多項式項 u(t-1)2,也可以是一些自定義的變換后的非線性項,例如 u(t-1)*y(t-3)。你可以把這些回歸量作為輸入指定給模型中的線性函數或者非線性函數。2. 使用輸出函數(同時包含線性和非線性兩部分)將前面計算的回歸量 regressor 映射到輸出。例如下面這個函數:
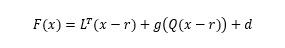
-
估計一個默認的非線性 ARX 模型
Options = nlarxOptions('SearchMethod','lm');% 使用
LevenbergMarquardt作為估計算法
Options.SearchOptions.MaxIterations = 50;
Narx1 = nlarx(ze, [2 4 1], idSigmoidNetwork,Options)% 模型階數設置為 [2 4 1],映射函數選擇 sigmoid 網絡,這個網絡用了一個 sigmoid 函數和一個回歸量的線性權重和來計算輸出,nlarx 函數用來估計非線性 ARX 模型
disp(Narx1.OutputFcn)
Sigmoid NetworkInputs: f(t-1), f(t-2), v(t-1), v(t-2), v(t-3), v(t-4)Output: fNonlinear Function: Sigmoid network with 10 unitsLinear Function: initialized to [48.3 -3.38 -3.34 -2.7 -1.38 2.15]Output Offset: initialized to -18.9因為階數[na nb nk] = [2 4 1],所以模型回歸量包含 f(t-1),f(t-2),v(t-1),v(t-2),v(t-3),v(t-4)。此處 f 代表輸出,v 代表輸入。分別在訓練集 ze 和驗證集 zv 上進行模型準確度驗證。
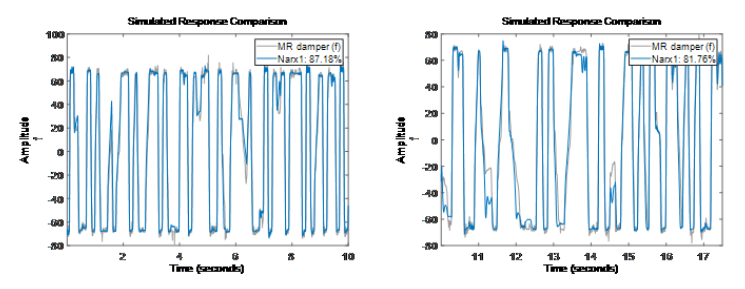 通過結果可以看到,同樣的階數情況下,非線性 ARX 比線性模型的結果還是有提升。我們有很多可以嘗試的方向來測試不同的模型參數。
通過結果可以看到,同樣的階數情況下,非線性 ARX 比線性模型的結果還是有提升。我們有很多可以嘗試的方向來測試不同的模型參數。-
嘗試不同的模型階數
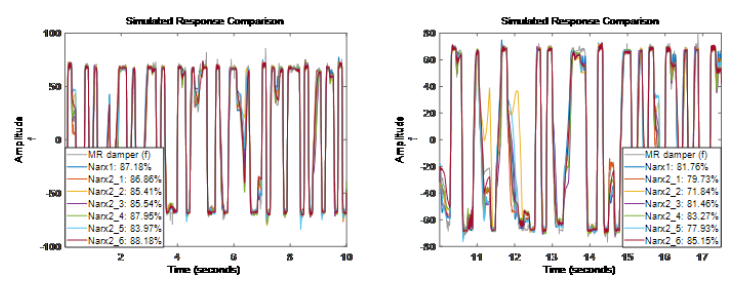 圖表 3Narx2 為不同階數的模型在測試集上的結果從結果看出 Narx2{6} 模型對估計(訓練)數據集和驗證數據集的擬合結果都很好,同時階數比 Narx1 的要小。因此,我們將階數矩陣 [1 3 1] 作為后續試驗的階數,同時將 Nlarx2{6} 作為參考進行擬合比較。階數矩陣選擇對應于使用 [f(t-1), v(t-1), v(t-2), v(t-3)] 作為回歸量 (regressor) 集合。
圖表 3Narx2 為不同階數的模型在測試集上的結果從結果看出 Narx2{6} 模型對估計(訓練)數據集和驗證數據集的擬合結果都很好,同時階數比 Narx1 的要小。因此,我們將階數矩陣 [1 3 1] 作為后續試驗的階數,同時將 Nlarx2{6} 作為參考進行擬合比較。階數矩陣選擇對應于使用 [f(t-1), v(t-1), v(t-2), v(t-3)] 作為回歸量 (regressor) 集合。-
嘗試修改 Sigmoid 網絡函數的隱含單元數
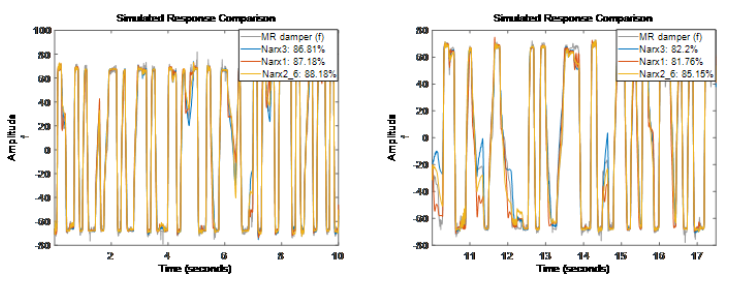 看上去增加隱含單元數并沒有帶來精度提升 (Narx3結果不如Narx2{6}),所以我們仍然用默認 10 個單元的 Sigmoid 網絡。
看上去增加隱含單元數并沒有帶來精度提升 (Narx3結果不如Narx2{6}),所以我們仍然用默認 10 個單元的 Sigmoid 網絡。-
特征選擇:給非線性映射函數選擇回歸量子集
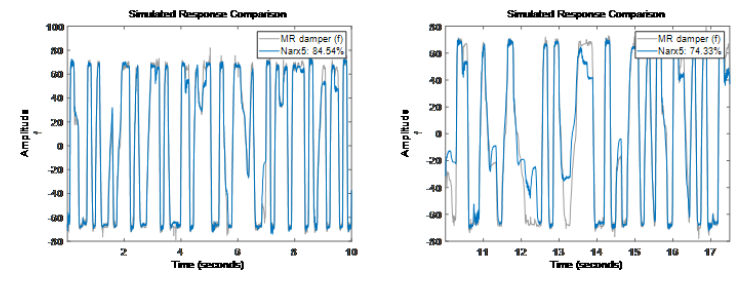 看上去 Narx5 模型在估計數據和驗證數據上表現還可以。
看上去 Narx5 模型在估計數據和驗證數據上表現還可以。-
嘗試不同的非線性映射函數
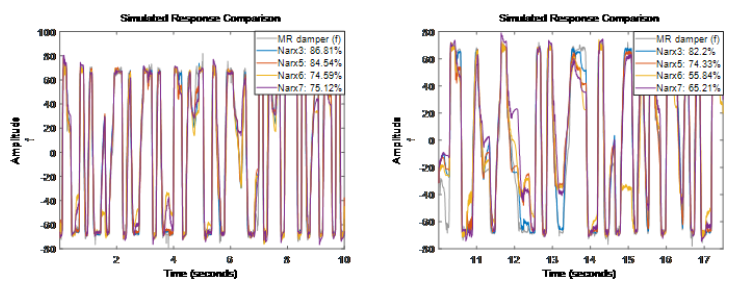 從目前嘗試的結果看 Narx6 和 Narx7 模型的表現比 Narx5 還差一些。
從目前嘗試的結果看 Narx6 和 Narx7 模型的表現比 Narx5 還差一些。-
分析估計出來的 IDNLARX 模型得到直觀解釋
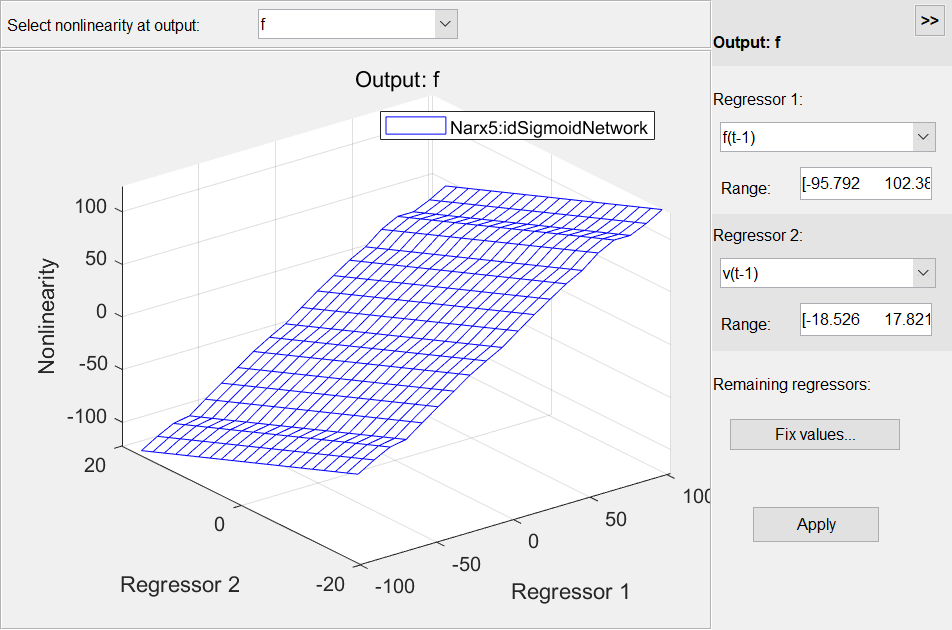 plot 函數窗口提供了選擇繪制橫截面的回歸量及其范圍的選項。殘差檢驗 (residual test) 可用于進一步模型分析。這個測試用于查看預測誤差是否為白噪聲且與輸入數據不相關。resid(zv, Narx3, Narx5)
plot 函數窗口提供了選擇繪制橫截面的回歸量及其范圍的選項。殘差檢驗 (residual test) 可用于進一步模型分析。這個測試用于查看預測誤差是否為白噪聲且與輸入數據不相關。resid(zv, Narx3, Narx5)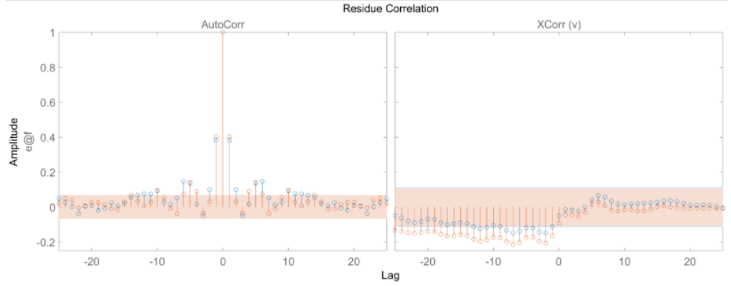 殘差測試結果失敗可能是由于模型沒有捕捉到系統的動態。從 Narx3 結果看殘差大多在 99% 的置信區間內。非線性 ARX Hammerstein-Wiener模型Hammerstein-Wiener模型首先是一個非線性模型,但對于動態部分,它其實是一個線性傳遞函數,那么非線性它怎么實現的?他其實是在輸入和輸出分別加了一個靜態的非線性變換,這樣通過一個先行傳遞函數來描述動態特性再加上輸入和輸出的兩個靜態非線性函數,就組成了 Hammerstein-Wiener 模型。
殘差測試結果失敗可能是由于模型沒有捕捉到系統的動態。從 Narx3 結果看殘差大多在 99% 的置信區間內。非線性 ARX Hammerstein-Wiener模型Hammerstein-Wiener模型首先是一個非線性模型,但對于動態部分,它其實是一個線性傳遞函數,那么非線性它怎么實現的?他其實是在輸入和輸出分別加了一個靜態的非線性變換,這樣通過一個先行傳遞函數來描述動態特性再加上輸入和輸出的兩個靜態非線性函數,就組成了 Hammerstein-Wiener 模型。 圖中,f 是一個非線性函數,將輸入數據 u(t) 轉換(靜態變換,t 時刻的輸出值只取決于 t 時刻的輸入值)為 w(t) = F (u(t))。B/F 是一個線性傳遞函數,將 w(t) 變換為 x(t) = (B/F)w(t),這是動態變換。B 和 F 類似于前面介紹的 OE 模型中的多項式。對于 ny 輸出和 nu 輸入,傳遞函數矩陣為:
圖中,f 是一個非線性函數,將輸入數據 u(t) 轉換(靜態變換,t 時刻的輸出值只取決于 t 時刻的輸入值)為 w(t) = F (u(t))。B/F 是一個線性傳遞函數,將 w(t) 變換為 x(t) = (B/F)w(t),這是動態變換。B 和 F 類似于前面介紹的 OE 模型中的多項式。對于 ny 輸出和 nu 輸入,傳遞函數矩陣為:
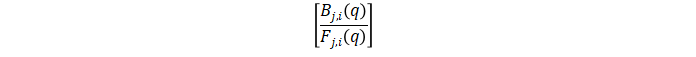
-
分析估計的 IDNLHW 模型
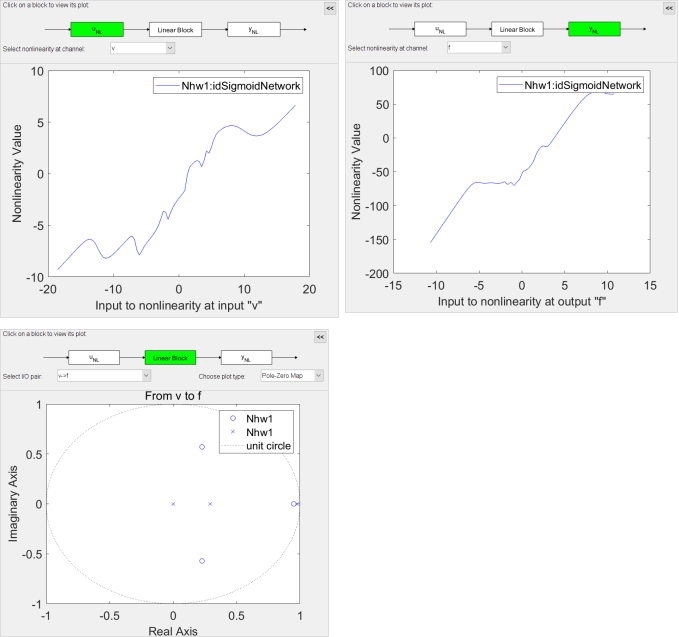 從結果可以看出輸入非線性函數(像一個飽和函數)和輸出非線性函數(像一個分段線性函數)的形狀。線性傳函模塊的零極點圖中有一個零點和一個極點非常接近,說明可以去掉它們,從而減少模型的階數。接下來和 IDNLARX 一樣我們可以嘗試不同的模型參數,包括階數和輸入輸出的非線性函數。此處不在贅述,大家可以根據示例自由嘗試。
從結果可以看出輸入非線性函數(像一個飽和函數)和輸出非線性函數(像一個分段線性函數)的形狀。線性傳函模塊的零極點圖中有一個零點和一個極點非常接近,說明可以去掉它們,從而減少模型的階數。接下來和 IDNLARX 一樣我們可以嘗試不同的模型參數,包括階數和輸入輸出的非線性函數。此處不在贅述,大家可以根據示例自由嘗試。Conclusions 總結
我們探索了各種非線性模型來表達輸入電壓和輸出阻尼力之間的動態關系。結果表明,在非線性 ARX 模型中,Narx2{6} 和 Narx5 表現最好,而在 Hammerstein-Wiener 模型中,Nhw1 表現最好。非線性ARX模型最好的描述了 MR 阻尼器的動態特性 (擬合度最好)。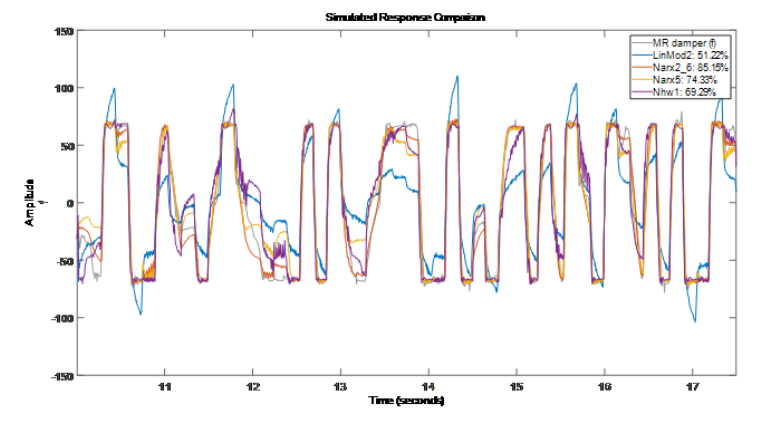 通過示例我們看到每種模型類型都有多個可用調項。例如對于非線性 ARX 模型,我們不僅可以指定模型的階數和非線性函數的類型,還可以修改和設置回歸量以及調整對應函數的屬性。對于 Hammerstein-Wiener 模型,我們可以選擇輸入輸出非線性函數的類型,以及線性傳函的階數。因此使用數據辨識模型可以在對模型結構或動力學缺乏明確原理的情況下,嘗試各種選項,并分析它們對結果模型質量的影響。當然這個示例本身是單輸入單輸出(SISO,Single Input Single Output)的系統, 對于多輸入多輸出(MIMO, Multi-Input Multi-Output)的系統上述大部分模型也都支持。具體的MIMO也可以查看文檔中更多的示例[鏈接6]。
通過示例我們看到每種模型類型都有多個可用調項。例如對于非線性 ARX 模型,我們不僅可以指定模型的階數和非線性函數的類型,還可以修改和設置回歸量以及調整對應函數的屬性。對于 Hammerstein-Wiener 模型,我們可以選擇輸入輸出非線性函數的類型,以及線性傳函的階數。因此使用數據辨識模型可以在對模型結構或動力學缺乏明確原理的情況下,嘗試各種選項,并分析它們對結果模型質量的影響。當然這個示例本身是單輸入單輸出(SISO,Single Input Single Output)的系統, 對于多輸入多輸出(MIMO, Multi-Input Multi-Output)的系統上述大部分模型也都支持。具體的MIMO也可以查看文檔中更多的示例[鏈接6]。
附言:
系統辨識還有很多內容文中示例沒有涉及,例如Grey-Box 模型估計,在線估計。附言中簡單介紹一下,也歡迎查閱相關詳細鏈接。
Grey-Box 模型
對于 Grey-Box 模型估計[鏈接7],總體思想是說你已經有了系統的微分/差分方程(線性,非線性)、狀態空間方程等等,但方程的系數是未知的,可以使用數據進行方程系數的估計。這種估計的難點通產是構建這個含參數的線性或非線性的系統方程。可以參考示例:包括車輛模型、電機模型、飛行器模型等等。
在線估計
在線估計[鏈接8]顧名思義就是說在物理系統(被控對象)運行過程中,利用實時流數據不斷地對模型的參數和狀態進行估計。- 針對在線參數估計,主要使用迭代算法,利用當前的實時測量數據和歷史的參數估計值來估計當前模型(文章前面提到的模型)的參數值,算法迭代效率比較高,也可以支持嵌入式。
- 針對在線狀態估計,主要包含幾種狀態估計器,Kalman Filter(線性系統),Extended Kalman Filter(可線性化的非線性系統),Unscented Kalman Filter(非線性系統), Particle Filter (類似 UKF)等。
原文標題:數據驅動的動態系統(Dynamical System)建模(二):系統辨識
文章出處:【微信公眾號:MATLAB】歡迎添加關注!文章轉載請注明出處。
-
數據驅動
+關注
關注
0文章
124瀏覽量
12319 -
系統辨識
+關注
關注
0文章
11瀏覽量
7279 -
動態系統
+關注
關注
0文章
3瀏覽量
5234
原文標題:數據驅動的動態系統(Dynamical System)建模(二):系統辨識
文章出處:【微信號:MATLAB,微信公眾號:MATLAB】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論