") 結(jié)合句子間差異的無(wú)監(jiān)督句子嵌入對(duì)比學(xué)習(xí)方法-DiffCSE
結(jié)合句子間差異的無(wú)監(jiān)督句子嵌入對(duì)比學(xué)習(xí)方法-DiffCSE
寫在前面
今天分享給大家一篇NAACL2022論文,結(jié)合句子間差異的無(wú)監(jiān)督句子嵌入對(duì)比學(xué)習(xí)方法-DiffCSE,全名《DiffCSE: Difference-based Contrastive Learning for Sentence Embeddings》。該篇論文主要是在SimCSE上進(jìn)行優(yōu)化,通過(guò)ELECTRA模型的生成偽造樣本和RTD(Replaced Token Detection)任務(wù),來(lái)學(xué)習(xí)原始句子與偽造句子之間的差異,以提高句向量表征模型的效果。
paper:https://arxiv.org/pdf/2204.10298.pdf
github:https://github.com/voidism/DiffCSE
介紹
句向量表征技術(shù)目前已經(jīng)通過(guò)對(duì)比學(xué)習(xí)獲取了很好的效果。而對(duì)比學(xué)習(xí)的宗旨就是拉近相似數(shù)據(jù),推開不相似數(shù)據(jù),有效地學(xué)習(xí)數(shù)據(jù)表征。SimCSE方法采用dropout技術(shù),對(duì)原始文本進(jìn)行數(shù)據(jù)增強(qiáng),構(gòu)造出正樣本,進(jìn)行后續(xù)對(duì)比學(xué)習(xí)訓(xùn)練,取得了較好的效果;并且在其實(shí)驗(yàn)中表明”dropout masks機(jī)制來(lái)構(gòu)建正樣本,比基于同義詞或掩碼語(yǔ)言模型的刪除或替換等更復(fù)雜的增強(qiáng)效果要好得多。“。這一現(xiàn)象也說(shuō)明,「直接增強(qiáng)(刪除或替換)往往改變句子本身語(yǔ)義」。
paper:https://aclanthology.org/2021.emnlp-main.552.pdf
github:https://github.com/princeton-nlp/SimCSE
論文解讀:https://zhuanlan.zhihu.com/p/452761704
Dangovski等人發(fā)現(xiàn),在圖像上,采用不變對(duì)比學(xué)習(xí)和可變對(duì)比學(xué)習(xí)相互結(jié)合的方法可以提高圖像表征的效果。而采用不敏感的圖像轉(zhuǎn)換(如,灰度變換)進(jìn)行數(shù)據(jù)增強(qiáng)再對(duì)比損失來(lái)改善視覺(jué)表征學(xué)習(xí),稱為「不變對(duì)比學(xué)習(xí)」。而「可變對(duì)比學(xué)習(xí)」,則是采用敏感的圖像轉(zhuǎn)換(如,旋轉(zhuǎn)變換)進(jìn)行數(shù)據(jù)增強(qiáng)的對(duì)比學(xué)習(xí)。如下圖所示,做左側(cè)為不變對(duì)比學(xué)習(xí),右側(cè)為可變對(duì)比學(xué)習(xí)。對(duì)于NLP來(lái)說(shuō),「dropout方法」進(jìn)行數(shù)據(jù)增強(qiáng)為不敏感變化,采用「詞語(yǔ)刪除或替換等」方法進(jìn)行數(shù)據(jù)增強(qiáng)為敏感變化。
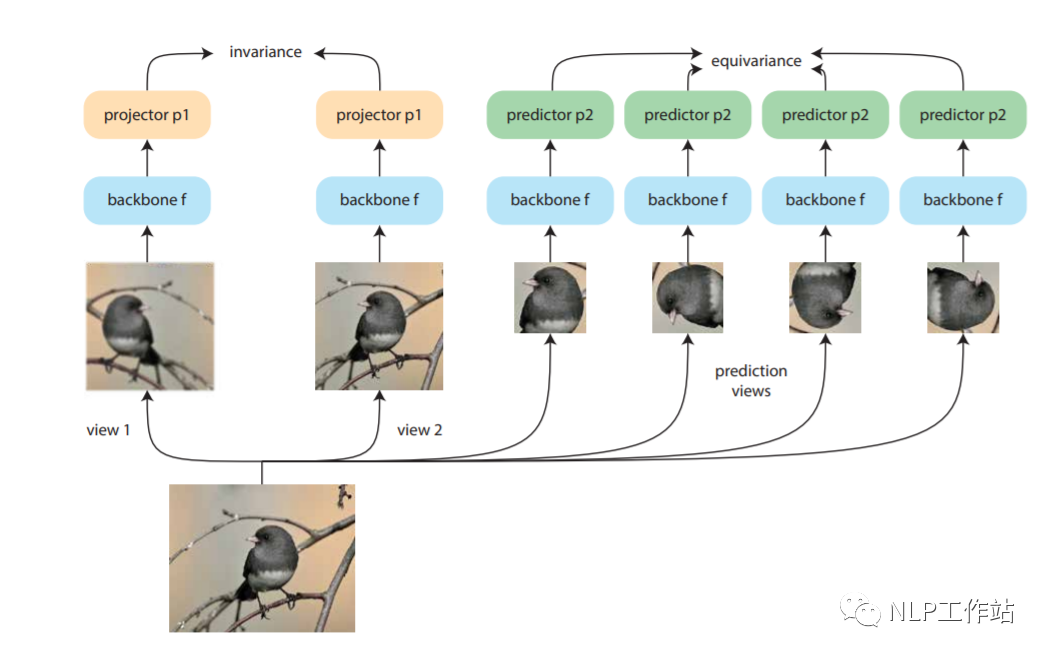
paper:https://arxiv.org/pdf/2111.00899.pdf
作者借鑒Dangovski等人在圖像上的做法,提出來(lái)「DiffCSE方法」,通過(guò)使用基于dropout masks機(jī)制的增強(qiáng)作為不敏感轉(zhuǎn)換學(xué)習(xí)對(duì)比學(xué)習(xí)損失和基于MLM語(yǔ)言模型進(jìn)行詞語(yǔ)替換的方法作為敏感轉(zhuǎn)換學(xué)習(xí)「原始句子與編輯句子」之間的差異,共同優(yōu)化句向量表征。
模型
模型如下圖所示,
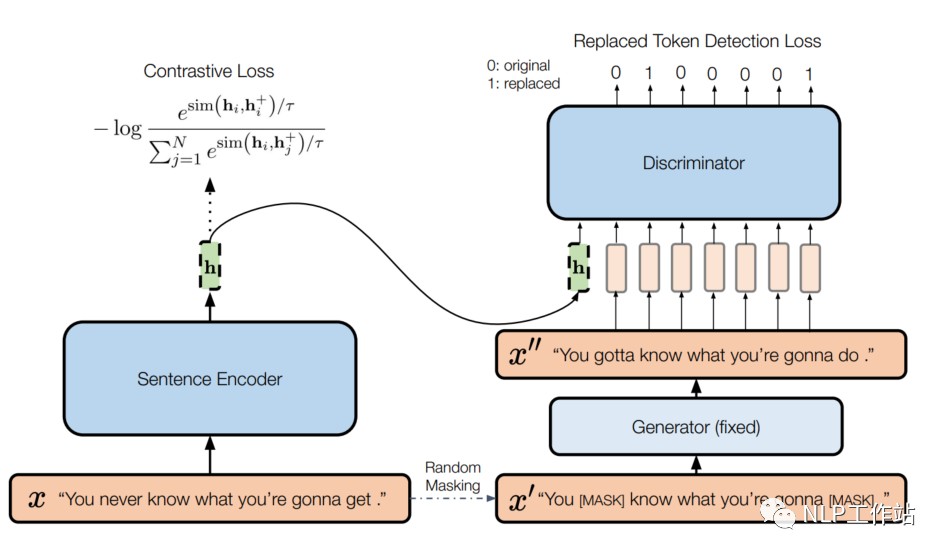
左側(cè)為一個(gè)標(biāo)準(zhǔn)的SimCSE模型,右側(cè)為一個(gè)帶條件的句子差異預(yù)測(cè)模型。給定一個(gè)句子,SimCSE模型通過(guò)dropout機(jī)制構(gòu)造一個(gè)正例,使用BERT編碼器f,獲取句向量,SimCSE模型的訓(xùn)練目標(biāo)為:
其中,為訓(xùn)練輸入batch大小,為余弦相似度,為溫度參數(shù).
右側(cè)實(shí)際上是ELECTRA模型,包含生成器和判別器。給定一個(gè)長(zhǎng)度為T的句子,,生成一個(gè)隨機(jī)掩碼序列,其中。使用MLM預(yù)訓(xùn)練語(yǔ)言模型作為生成器G,通過(guò)掩碼序列來(lái)生成句子中被掩掉的token,獲取生成序列。然后使用判別器D進(jìn)行替換token檢測(cè),也就是預(yù)測(cè)哪些token是被替換的。其訓(xùn)練目標(biāo)為:
針對(duì)一個(gè)batch的訓(xùn)練目標(biāo)為。
最終將兩個(gè)loss通過(guò)動(dòng)態(tài)權(quán)重將其結(jié)合,
為了使判別器D的損失可以傳播的編碼器f中,將句向量拼接到判別器D的輸入中,輔助進(jìn)行RTD任務(wù),這樣做可以鼓勵(lì)編碼器f使信息量足夠大,從而使判別器D能夠區(qū)分和之間的微小差別。
當(dāng)訓(xùn)練DiffCSE模型時(shí),固定生成器G參數(shù),只有句子編碼器f和鑒別器D得到優(yōu)化。訓(xùn)練結(jié)束后,丟棄鑒別器D,只使用句子編碼器f提取句子嵌入對(duì)下游任務(wù)進(jìn)行評(píng)價(jià)。
結(jié)果&分析
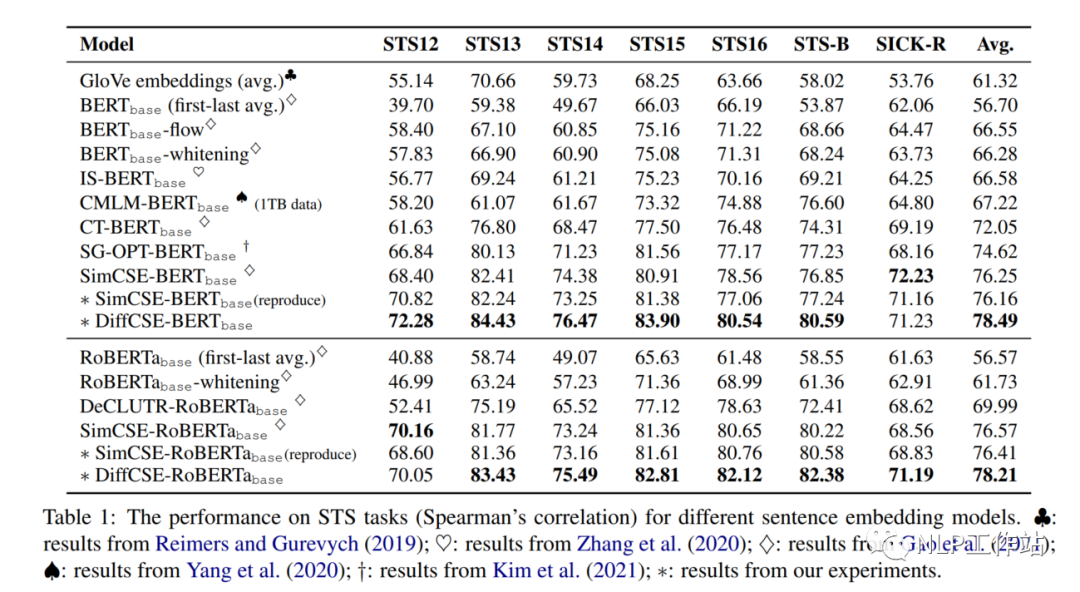
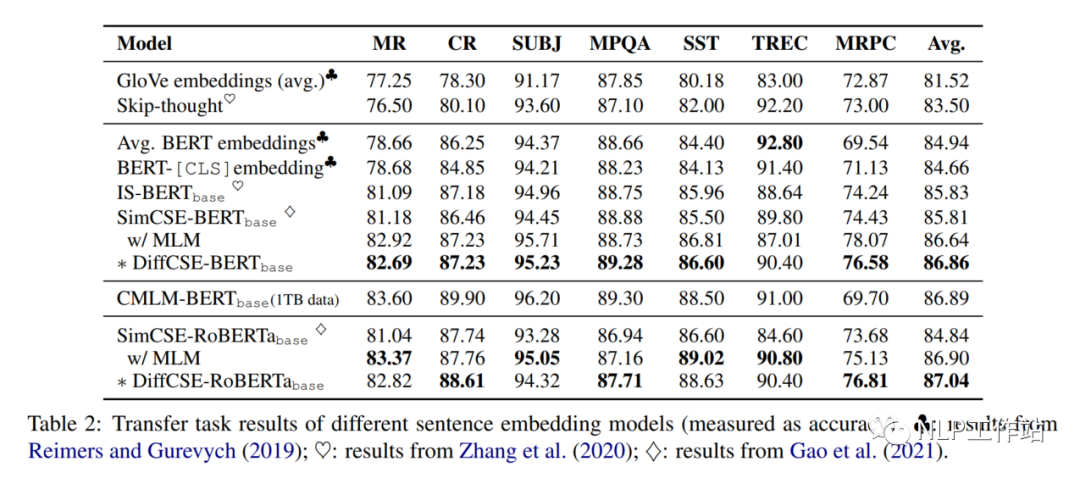
在句子相似度任務(wù)以及分類任務(wù)上的效果,如下表1和表2所示,相比與SimCSE模型均有提高,
為了驗(yàn)證DiffCSE模型具體是哪個(gè)部分有效,進(jìn)行以下消融實(shí)驗(yàn)。
Removing Contrastive Loss
如表3所示,當(dāng)去除對(duì)比學(xué)習(xí)損失,僅采用RTD損失時(shí),在句子相似度任務(wù)上,下降30%,在分類任務(wù)上下降2%。
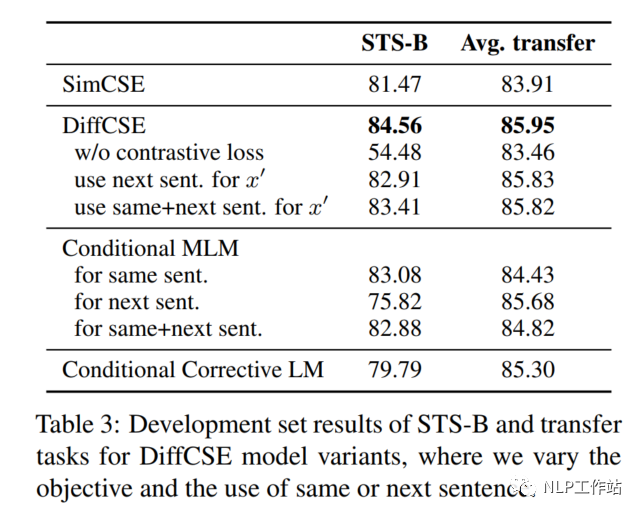
Next Sentence vs. Same Sentence
如表3所示,當(dāng)將同句話預(yù)測(cè)任務(wù),變成預(yù)測(cè)下句話任務(wù)時(shí),在句子相似度任務(wù)和分類任務(wù)上,具有不同程度的下降。
Other Conditional Pretraining Tasks
DiffCSE模型采用MLM模型和LM模型分別作為生成器時(shí),效果如表3所示,在句子相似度任務(wù)和分類任務(wù)上,具有不同程度的下降。句子相似度任務(wù)上下降的較為明顯。
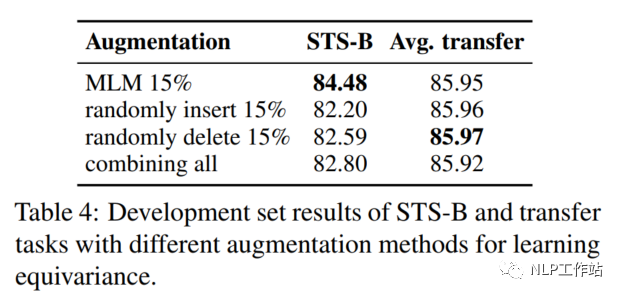
Augmentation Methods: Insert/Delete/Replace
將MLM模型生成偽造句換成隨機(jī)插入、隨機(jī)刪除或隨機(jī)替換的效果,如表示所4,MLM模型的效果綜合來(lái)說(shuō)較為優(yōu)秀。
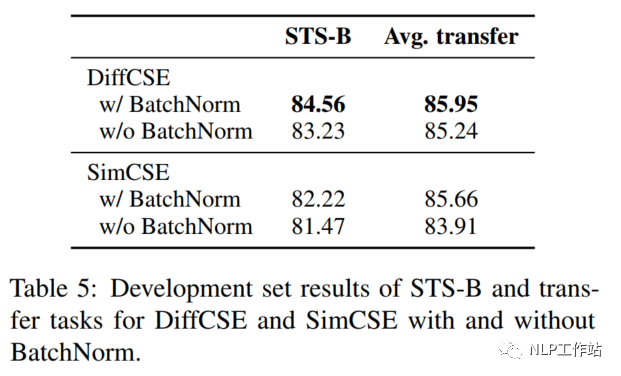
Pooler Choice
在SimCSE模型中,采用pooler層(一個(gè)帶有tanh激活函數(shù)的全連接層)作為句子向量輸出。該論文實(shí)驗(yàn)發(fā)現(xiàn),采用帶有BN的兩層pooler效果更為突出,如表5所示;并發(fā)現(xiàn),BN在SimCSE模型上依然有效。
代碼如下:
classProjectionMLP(nn.Module):
def__init__(self,config):
super().__init__()
in_dim=config.hidden_size
hidden_dim=config.hidden_size*2
out_dim=config.hidden_size
affine=False
list_layers=[nn.Linear(in_dim,hidden_dim,bias=False),
nn.BatchNorm1d(hidden_dim),
nn.ReLU(inplace=True)]
list_layers+=[nn.Linear(hidden_dim,out_dim,bias=False),
nn.BatchNorm1d(out_dim,affine=affine)]
self.net=nn.Sequential(*list_layers)
defforward(self,x):
returnself.net(x)
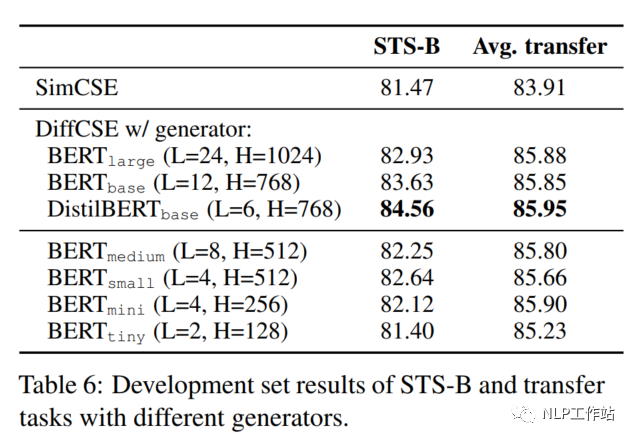
Size of the Generator
在DiffCSE模型中,嘗試了不同大小的生成器G,如下表所示,DistilBERTbase模型效果最優(yōu)。并且發(fā)現(xiàn)與原始ELECTRA模型的結(jié)論不太一致。原始ELECTRA認(rèn)為生成器的大小在判別器的1/4到1/2之間效果是最好的,過(guò)強(qiáng)的生成器會(huì)增大判別器的難度。而DiffCSE模型由于融入了句向量,導(dǎo)致判別器更容易判別出token是否被替換,所以生成器的生成能力需要適當(dāng)提高。
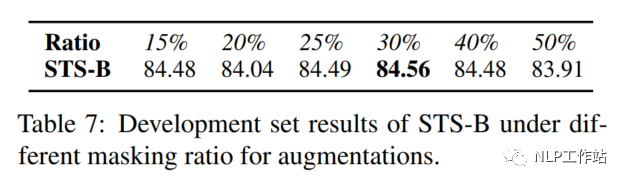
Masking Ratio
對(duì)于掩碼概率,經(jīng)實(shí)驗(yàn)發(fā)現(xiàn),在掩碼概率為30%時(shí),模型效果最優(yōu)。
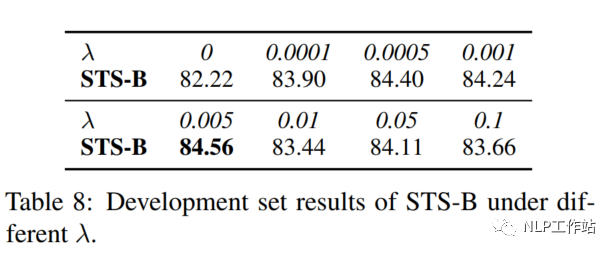
Coefficient λ
針對(duì)兩個(gè)損失之間的權(quán)重值,經(jīng)實(shí)驗(yàn)發(fā)現(xiàn),對(duì)比學(xué)習(xí)損失為RTD損失200倍時(shí),模型效果最優(yōu)。
總結(jié)
個(gè)人覺(jué)得這篇論文的主要思路還是通過(guò)加入其他任務(wù),來(lái)增強(qiáng)句向量表征任務(wù),整體來(lái)說(shuō)挺好的。但是該方法如何使用到監(jiān)督學(xué)習(xí)數(shù)據(jù)上,值得思考,歡迎留言討論。
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
6892瀏覽量
88828 -
生成器
+關(guān)注
關(guān)注
7文章
313瀏覽量
20977 -
向量
+關(guān)注
關(guān)注
0文章
55瀏覽量
11658
原文標(biāo)題:DiffCSE:結(jié)合句子間差異的無(wú)監(jiān)督句子嵌入對(duì)比學(xué)習(xí)方法
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
什么是機(jī)器學(xué)習(xí)?通過(guò)機(jī)器學(xué)習(xí)方法能解決哪些問(wèn)題?

時(shí)空引導(dǎo)下的時(shí)間序列自監(jiān)督學(xué)習(xí)框架

嵌入式學(xué)習(xí)建議
【《大語(yǔ)言模型應(yīng)用指南》閱讀體驗(yàn)】+ 基礎(chǔ)知識(shí)學(xué)習(xí)
【《大語(yǔ)言模型應(yīng)用指南》閱讀體驗(yàn)】+ 基礎(chǔ)篇
神經(jīng)網(wǎng)絡(luò)如何用無(wú)監(jiān)督算法訓(xùn)練
深度學(xué)習(xí)中的無(wú)監(jiān)督學(xué)習(xí)方法綜述
深度學(xué)習(xí)與傳統(tǒng)機(jī)器學(xué)習(xí)的對(duì)比
谷歌提出大規(guī)模ICL方法
QNX與Linux基礎(chǔ)差異對(duì)比
OpenAI推出Sora:AI領(lǐng)域的革命性突破
Meta發(fā)布新型無(wú)監(jiān)督視頻預(yù)測(cè)模型“V-JEPA”
請(qǐng)問(wèn)初學(xué)者要怎么快速掌握FPGA的學(xué)習(xí)方法?
基于transformer和自監(jiān)督學(xué)習(xí)的路面異常檢測(cè)方法分享

無(wú)監(jiān)督域自適應(yīng)場(chǎng)景:基于檢索增強(qiáng)的情境學(xué)習(xí)實(shí)現(xiàn)知識(shí)遷移






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論