 一個“槍槍爆頭”的視覺AI自瞄程序!
一個“槍槍爆頭”的視覺AI自瞄程序!
前言
前段時間在網上看到《警惕AI外掛!我寫了一個槍槍爆頭的視覺AI,又親手“殺死”了它》 這個視頻,引起了我極大的興趣。
視頻中提到,在國外有人給使命召喚做了個AI程序來實現自動瞄準功能。它跟傳統外掛不一樣,該程序不需要用游戲內存數據,也不往服務器發送作弊指令,只是通過計算機視覺來分析游戲畫面,定位敵人,把準星移動過去,跟人類玩家操作一模一樣,因此反外掛程序無法檢測到它。而且更恐怖的是這AI程序全平臺通用,不管是X-box,PS4還是手機,只要能把畫面接出來,把操作送進去,就可以實現“槍槍爆頭”。

外網的那個開發者用的是基于方框的目標檢測,但是像射擊游戲需要定位人體的場景,其實有比方框檢測更好的算法。up主就利用了幾個小時的時間就寫出來了一個效果更好,功能更夸張的AI程序,也就是利用人體關節點檢測技術,通過大量真人圖片訓練出來的視覺AI,可以把視頻和圖片里人物的關節信息提取出來 并給出每個部位中心點的精確像素坐標,而且雖然訓練的是是真人圖片,但是給它游戲里的人物,他也一樣能把人體關節定位出來。
可以說由于這類AI程序的出現,現在fps游戲的形式就是山雨欲來風滿樓,十分嚴峻啊!
下面,我們先開始介紹這個視覺AI自動瞄準的制作思路,然后再談談這個問題帶來的影響以及如何解決這個問題。
一、核心功能設計
總體來說,我們首先需要訓練好一個人體關節點檢測的AI視覺模型,然后將游戲畫面實時送入AI視覺模型中,再反饋出游戲人物各個部位的像素位置,然后確定瞄準點,并將鼠標移動到瞄準點位置。
拆解需求后,整理出核心功能如下:
- 訓練人體關節點檢測模型
- 輸入視頻或圖片到AI視覺模型,并輸出瞄準點位置。
- 自動操作鼠標移動到對應瞄準位置
最終想要實現的效果如下圖所示:

二、核心實現步驟
1.訓練人體關節點檢測模型
在這一部分,我打算使用由微軟亞洲研究院和中科大提出High-Resoultion Net(HRNet)來進行人體關節點檢測,該模型通過在高分辨率特征圖主網絡逐漸并行加入低分辨率特征圖子網絡,不同網絡實現多尺度融合與特征提取實現的,所以在目前的通用數據集上取得了較好的結果。
1.1 HRNet代碼庫安裝
按照官方的install指導命令,安裝十分簡單。我是采用本地源代碼安裝方式。
gitclonehttps://github.com/leoxiaobin/deep-high-resolution-net.pytorch.git
python-mpipinstall-edeep-high-resolution-ne.pytorch
1.2 人體關鍵點數據集下載
首先打開COCO數據集官方下載鏈接。
對于Images一欄的綠色框需要下載三個大的文件,分別對應的是訓練集,驗證集和測試集:
https://images.cocodataset.org/zips/train2017.zip
https://images.cocodataset.org/zips/val2017.zip
https://images.cocodataset.org/zips/test2017.zip
對于Annotations一欄綠色框需要下載一個標注文件:
https://images.cocodataset.org/annotations/annotations_trainval2017.zip
將文件解壓后,可以得到如下目錄結構:
其中的 person_keypoints_train2017.json 和 person_keypoints_val2017.json 分別對應的人體關鍵點檢測對應的訓練集和驗證集標注。
annotations
├──captions_train2017.json
├──captions_val2017.json
├──instances_train2017.json
├──instances_val2017.json
├──person_keypoints_train2017.json人體關鍵點檢測對應的訓練集標注文件
└──person_keypoints_val2017.json人體關鍵點檢測對應的驗證集標注文件
在本地代碼庫datasets目錄下面新建立coco目錄,將上面的訓練集,驗證集以及標注文件放到本地代碼的coco目錄下面
datasets
├──coco
│├──annotations
│├──test2017
│├──train2017
│└──val2017
1.3 環境配置與模型訓練
核心訓練代碼如下:
deftrain(config,train_loader,model,criterion,optimizer,epoch,
output_dir,tb_log_dir,writer_dict):
batch_time=AverageMeter()
data_time=AverageMeter()
losses=AverageMeter()
acc=AverageMeter()
#switchtotrainmode
model.train()
end=time.time()
fori,(input,target,target_weight,meta)inenumerate(train_loader):
data_time.update(time.time()-end)
outputs=model(input)
target=target.cuda(non_blocking=True)
target_weight=target_weight.cuda(non_blocking=True)
ifisinstance(outputs,list):
loss=criterion(outputs[0],target,target_weight)
foroutputinoutputs[1:]:
loss+=criterion(output,target,target_weight)
else:
output=outputs
loss=criterion(output,target,target_weight)
optimizer.zero_grad()
loss.backward()
optimizer.step()
#measureaccuracyandrecordloss
losses.update(loss.item(),input.size(0))
_,avg_acc,cnt,pred=accuracy(output.detach().cpu().numpy(),
target.detach().cpu().numpy())
acc.update(avg_acc,cnt)
batch_time.update(time.time()-end)
end=time.time()
ifi%config.PRINT_FREQ==0:
msg='Epoch:[{0}][{1}/{2}] '
'Time{batch_time.val:.3f}s({batch_time.avg:.3f}s) '
'Speed{speed:.1f}samples/s '
'Data{data_time.val:.3f}s({data_time.avg:.3f}s) '
'Loss{loss.val:.5f}({loss.avg:.5f}) '
'Accuracy{acc.val:.3f}({acc.avg:.3f})'.format(
epoch,i,len(train_loader),batch_time=batch_time,
speed=input.size(0)/batch_time.val,
data_time=data_time,loss=losses,acc=acc)
logger.info(msg)
writer=writer_dict['writer']
global_steps=writer_dict['train_global_steps']
writer.add_scalar('train_loss',losses.val,global_steps)
writer.add_scalar('train_acc',acc.val,global_steps)
writer_dict['train_global_steps']=global_steps+1
prefix='{}_{}'.format(os.path.join(output_dir,'train'),i)
save_debug_images(config,input,meta,target,pred*4,output,
prefix)
訓練結果:

2.輸入視頻或圖片實時反饋瞄準點坐標
2.1 實時讀取屏幕畫面
importpyautogui
img=pyautogui.screenshot()
在一個 1920×1080 的屏幕上,screenshot()函數要消耗100微秒,基本達到實時傳入游戲畫面要求。
如果不需要截取整個屏幕,還有一個可選的region參數。你可以把截取區域的左上角XY坐標值和寬度、高度傳入截取。
im=pyautogui.screenshot(region=(0,0,300,400))
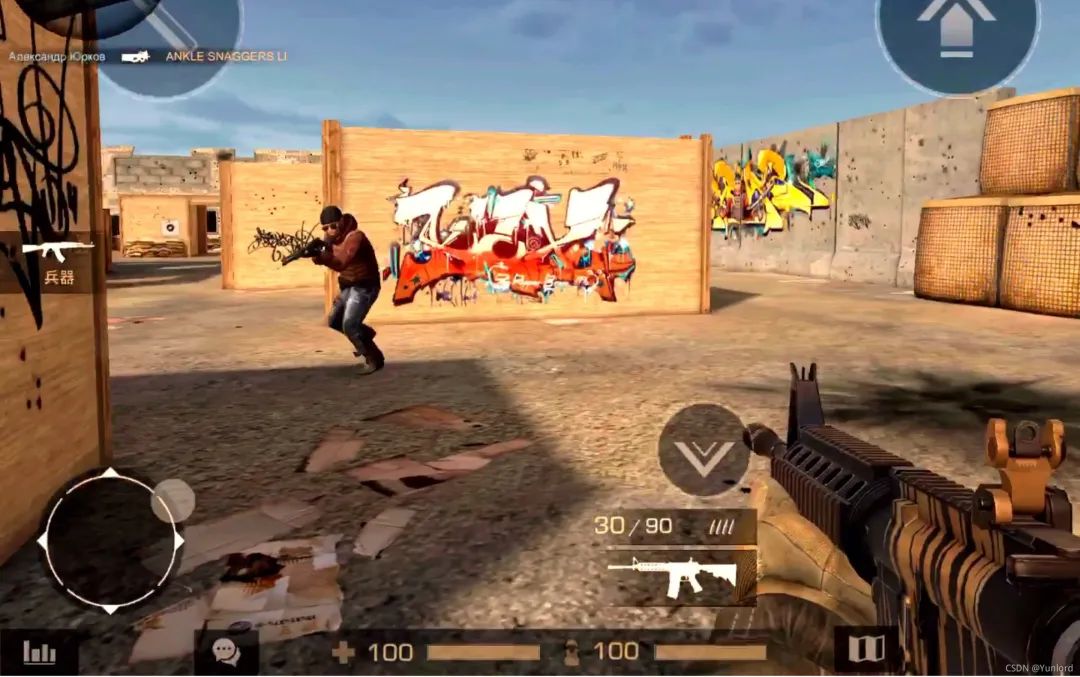
2.2 讀取圖片反饋坐標
parser.add_argument('--keypoints',help='f:fullbody17keypoints,h:halfbody11keypoints,sh:smallhalfbody6keypotins')
hp=PoseEstimation(config=args.keypoints,device="cuda:0")
可以選擇人體關節點檢測數目,包括上半身6個關鍵點、上半身11個關鍵點以及全身17個關鍵點,然后構建探測器。
人體關節點對應序號:
"keypoints":{0:"nose",1:"left_eye",2:"right_eye",3:"left_ear",4:"right_ear",5:"left_shoulder",6:"right_shoulder",7:"left_elbow",8:"right_elbow",9:"left_wrist",10:"right_wrist",11:"left_hip",12:"right_hip",13:"left_knee",14:"right_knee",15:"left_ankle",16:"right_ankle"}
因此如果為了自動瞄準頭部實現“槍槍爆頭”,僅需要反饋 0: "nose"的坐標點就行了。
代碼如下:
location=hp.detect_head(img_path,detect_person=True,waitKey=0)
defdetect_head(self,image_path,detect_person=True,waitKey=0):
bgr_image=cv2.imread(image_path)
kp_points,kp_scores,boxes=self.detect_image(bgr_image,
threshhold=self.threshhold,
detect_person=detect_person)
returnkp_points[0][0]
輸出結果:[701.179 493.55]
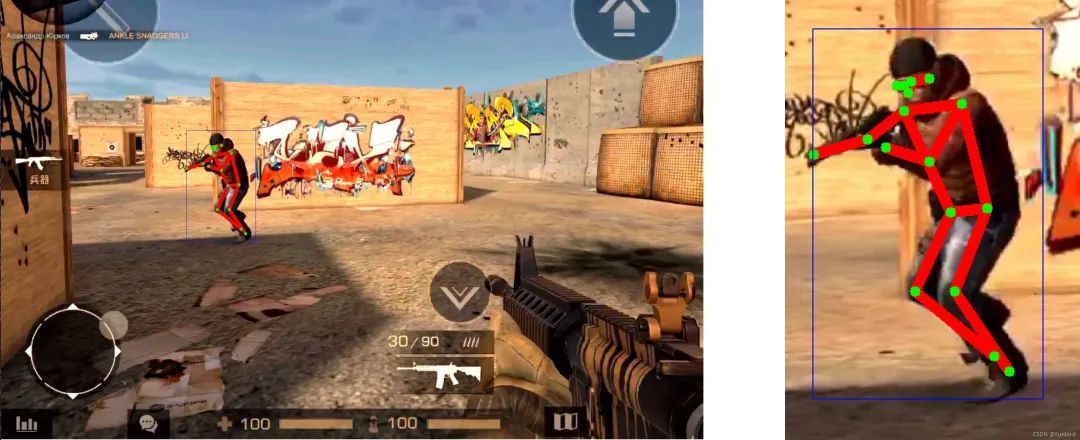
可以看到雖然訓練的是真人圖片,但是給它游戲里的人物,它也一樣能把人體關節定位出來。
深度神經網絡之所以厲害,就是因為它有一定的演繹推廣能力。沒見過的東西,他也能靠著層次線索分析一波,結果往往也挺準。而且游戲場景是現實場景的簡化之后的結果,環境和光影都要簡單的多,能把現實世界分析明白的視覺AI,對付個3D游戲更是小菜一碟了。
3.自動移動鼠標到對應的坐標點
3.1 移動鼠標
移動到指定位置:
pyautogui.moveTo(100,300,duration=1)
將鼠標移動到指定的坐標;duration 的作用是設置移動時間,所有的gui函數都有這個參數,而且都是可選參數。
獲取鼠標位置:
print(pyautogui.position())#得到當前鼠標位置;輸出:Point(x=200, y=800)
3.2 控制鼠標點擊
單擊鼠標:
#點擊鼠標
pyautogui.click(10,10)#鼠標點擊指定位置,默認左鍵
pyautogui.click(10,10,button='left')#單擊左鍵
pyautogui.click(1000,300,button='right')#單擊右鍵
pyautogui.click(1000,300,button='middle')#單擊中間
雙擊鼠標:
pyautogui.doubleClick(10,10)#指定位置,雙擊左鍵
pyautogui.rightClick(10,10)#指定位置,雙擊右鍵
pyautogui.middleClick(10,10)#指定位置,雙擊中鍵
點擊 & 釋放:
pyautogui.mouseDown()#鼠標按下
pyautogui.mouseUp()#鼠標釋放
至此,視覺AI自瞄程序已經基本設計完成。
三、引發的思考
總的來說,視覺AI給FPS游戲帶來了一波危機!
這類視覺AI程序目前存在三個威脅:
- 準確性
- 隱蔽性
- 通用性
第一個威脅就是超越人類的準確性。雖然人腦的高層次演繹歸納能力是遠勝于AI的,但是在低級信息處理速度和精確度上,人類就很難比得過專精某個功能的AI了,比如在人體關節定位這件事上,給出人體每個部位的中心位置只需要幾毫秒,而且精確到像素點,而同樣一張圖片給人類看個幾毫秒,都不一定能夠看清人在哪,更別說定位關節移動鼠標了。
第二個威脅就是無法被外掛程序檢測的隱蔽性。和傳統外掛不一樣,傳統外掛要操作游戲的內存數據或者文件數據,從而獲取游戲世界的信息。讓開掛的人打出一些正常玩家不可能實現的作弊操作。而視覺AI是完全獨立于游戲數據之外的,和人一樣,也是通過實時觀察畫面發送鼠標和鍵盤指令,所以傳統的反外掛程序只能反個寂寞。
第三個威脅就是適用全平臺的通用性。首先這個AI視覺模型是通過大量真人照片訓練出來的,但是能夠識別游戲中的人物,這意味著可以攻陷大部分FPS游戲。AI操作游戲和人操作游戲交互方式是沒區別的,所以衍生出更大的問題,只要能把畫面接入到這個模型中,就可以攻陷任意一種游戲平臺,包括電腦、主機、手機等,無論你做的多封閉,生態維護的多好,在視覺AI面前眾生平等。
那么我們該如何解決這個問題呢?
可以通過算法檢測游戲異常操作,這也是一種思路,但是實現起來還是比較困難,畢竟可以讓AI更像人類的操作。
而我想到之前比較火的deepfake,那么我們是不是可以通過對抗樣本來解決這個問題呢,使得視覺AI識別錯誤?
說了那么多,其實也沒有什么好的結論,只能說技術的發展是在不斷對抗中前進以及規范。
審核編輯 :李倩
-
AI
+關注
關注
87文章
30146瀏覽量
268415 -
計算機視覺
+關注
關注
8文章
1696瀏覽量
45927 -
數據集
+關注
關注
4文章
1205瀏覽量
24644
原文標題:寫了一個“槍槍爆頭”的視覺AI自瞄程序!
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
拆解品勝筋膜槍

語音芯片NV040D兒童玩具槍ic方案

手持pda碼槍大概多少錢 如何挑選pda手持終端

UAV反制槍如何應對國慶假期無人機亂飛?
XBLW/芯伯樂產品在筋膜槍上的應用

電纜雙槍安全刺扎器的試驗方法——每日了解電力知識

如何挑選合適的工業用條碼槍?

手持式掃描槍在醫療行業的應用

STM32F103如何連接讀取掃碼槍數據?
普通筋膜槍與冷熱敷筋膜槍的精妙差異

SIMCO-ION COBRA手持式離子風槍的作用及應用行業

筋膜槍的作用和使用方法
熱熔膠槍損壞檢修方法






 工商網監
工商網監
評論