 如何改進和加速擴散模型采樣的方法1
如何改進和加速擴散模型采樣的方法1
這是一系列關于 NVIDIA 研究人員如何改進和加速擴散模型采樣的方法的一部分,擴散模型是一種新穎而強大的生成模型。 Part 2 介紹了克服擴散模型中緩慢采樣挑戰的三種新技術。
生成模型是一類機器學習方法,它可以學習所訓練數據的表示形式,并對數據本身進行建模。它們通常基于深層神經網絡。相比之下,判別模型通常預測給定數據的單獨數量。
生成模型允許您合成與真實數據不同但看起來同樣真實的新數據。設計師可以在汽車圖像上訓練生成性模型,然后讓生成性人工智能計算出具有不同外觀的新穎汽車,從而加速藝術原型制作過程。
深度生成學習已成為機器學習領域的一個重要研究領域,并有許多相關應用。生成模型廣泛用于圖像合成和各種圖像處理任務,如編輯、修復、著色、去模糊和超分辨率。
生成性模型有可能簡化攝影師和數字藝術家的工作流程,并實現新水平的創造力。類似地,它們可能允許內容創建者高效地為游戲、動畫電影或 metaverse 生成虛擬 3D 內容。
基于深度學習的語音和語言合成已經進入消費品領域。醫學和醫療保健等領域也可能受益于生成性模型,例如生成對抗疾病的分子候選藥物的方法。
當神經網絡被用于不同的生成性學習任務時,尤其是對于不同的生成性學習任務,神經網絡和神經網絡也可以被用于合成。
生成性學習三位一體
為了在實際應用中得到廣泛采用,生成模型在理想情況下應滿足以下關鍵要求:
High-quality sampling :許多應用程序,尤其是那些直接與用戶交互的應用程序,需要高生成質量。例如,在語音生成中,語音質量差是很難理解的。類似地,在圖像建模中,期望的輸出在視覺上與自然圖像無法區分。
模式覆蓋和樣本多樣性 :如果訓練數據包含復雜或大量的多樣性,一個好的生成模型應該在不犧牲生成質量的情況下成功捕獲這種多樣性。
快速且計算成本低廉的采樣 :許多交互式應用程序需要快速生成,例如實時圖像編輯。
雖然目前大多數深層生成性學習方法都注重高質量的生成,但第二和第三個要求也非常重要。
忠實地表示數據的多樣性對于避免數據分布中遺漏少數模式至關重要。這有助于減少學習模型中不希望出現的偏差。
另一方面,在許多應用程序中,數據分布的長尾巴特別有趣。例如,在交通建模中,人們感興趣的正是罕見的場景,即與危險駕駛或事故相對應的場景。
降低計算復雜度和采樣時間不僅可以實現交互式實時應用。它還通過降低發電所需的總功率使用量,減少了運行昂貴的深層神經網絡(發電模型的基礎)所造成的環境足跡。
在本文中,我們將這三個需求帶來的挑戰定義為 生成性學習三位一體 ,因為現有方法通常會做出權衡,無法同時滿足所有需求。
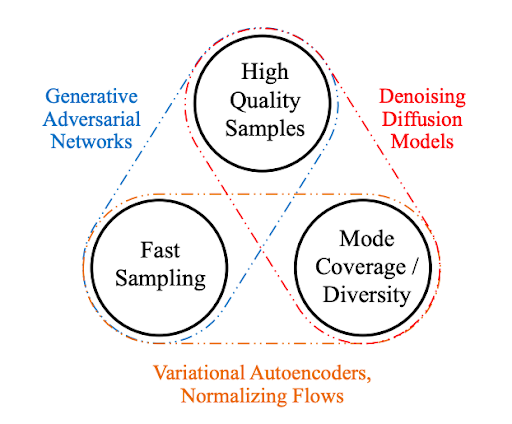
圖 1 生成性學習三位一體
基于擴散模型的生成性學習
最近,擴散模型已經成為一種強大的生成性學習方法。這些模型,也被稱為去噪擴散模型或基于分數的生成模型,表現出驚人的高樣本質量,通常優于生成性對抗網絡。它們還具有強大的模式覆蓋和樣本多樣性。
擴散模型已經應用于各種生成任務,如圖像、語音、三維形狀和圖形合成。
擴散模型包括兩個過程:正向擴散和參數化反向擴散。
前向擴散過程通過逐漸擾動輸入數據將數據映射為噪聲。這是通過一個簡單的隨機過程正式實現的,該過程從數據樣本開始,使用簡單的高斯擴散核迭代生成噪聲較大的樣本。也就是說,在這個過程的每一步,高斯噪聲都會逐漸添加到數據中。
第二個過程是一個參數化的反向過程,取消正向擴散并執行迭代去噪。這個過程代表數據合成,并經過訓練,通過將隨機噪聲轉換為真實數據來生成數據。它也被正式定義為一個隨機過程,使用可訓練的深度神經網絡對輸入圖像進行迭代去噪。
正向和反向過程通常使用數千個步驟來逐步注入噪聲,并在生成過程中進行去噪。

圖 2 擴散模型處理數據和噪聲之間的移動
圖 2 顯示,在擴散模型中,固定前向過程以逐步方式逐漸擾動數據,使其接近完全隨機噪聲。學習一個參數化的反向過程來執行迭代去噪,并從噪聲中生成數據,如圖像。
在形式上,通過x0表示一個數據點,例如圖像,通過xt表示時間步長t的擴散版本,正向過程由以下公式定義:

雖然離散時間擴散模型和連續時間擴散模型看起來可能不同,但它們有一個幾乎相同的生成過程。事實上,很容易證明離散時間擴散模型是連續時間模型的特殊離散化。
在實踐中使用連續時間擴散模型基本上要容易得多:
它們更通用,可以通過簡單的時間離散化轉換為離散時間模型。
它們是用 SDE 描述的, SDE 在各個科學領域都得到了很好的研究。
生成性 SDE 可以使用現成的數值 SDE 解算器進行求解。
它們可以轉換為相關的常微分方程( ODE ),這些方程也得到了很好的研究,并且易于使用。
如前所述,擴散模型通過遵循反向擴散過程生成樣本,該過程將簡單的基本分布(通常為高斯分布)映射到復雜的數據分布。在生成 SDE 表示的連續時間擴散模型中,由于神經網絡逼近分數函數
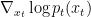
,這種映射通常很復雜。
用數值積分技術解決這個問題需要調用 1000 次深層神經網絡來生成樣本。正因為如此,擴散模型在生成樣本時通常很慢,需要幾分鐘甚至幾小時的計算時間。這與生成性對抗網絡( GANs )等競爭性技術形成了鮮明對比,后者只需對神經網絡進行一次調用即可生成樣本。
總結
盡管擴散模型實現了較高的樣本質量和多樣性,但不幸的是,它們在采樣速度方面存在不足。這限制了擴散模型在實際應用中的廣泛采用,并導致了從這些模型加速采樣的研究領域的活躍。在 Part 2 中,我們回顧了 NVIDIA 為克服擴散模型的主要局限性而開發的三種技術。
關于作者
Arash Vahdat 是 NVIDIA research 的首席研究科學家,專攻計算機視覺和機器學習。在加入 NVIDIA 之前,他是 D-Wave 系統公司的研究科學家,從事深度生成學習和弱監督學習。在 D-Wave 之前,阿拉什是西蒙·弗雷澤大學( Simon Fraser University , SFU )的一名研究人員,他領導了深度視頻分析的研究,并教授大數據機器學習的研究生課程。阿拉什在格雷格·莫里( Greg Mori )的指導下獲得了 SFU 的博士和理學碩士學位,致力于視覺分析的潛變量框架。他目前的研究領域包括深層生成學習、表征學習、高效神經網絡和概率深層學習。
Karsten Kreis 是 NVIDIA 多倫多人工智能實驗室的高級研究科學家。在加入 NVIDIA 之前,他在 D-Wave Systems 從事深度生成建模工作,并與他人共同創立了變分人工智能,這是一家利用生成模型進行藥物發現的初創公司。卡斯滕在馬克斯·普朗克光科學研究所獲得量子信息理論理學碩士學位,并在馬克斯·普朗克聚合物研究所獲得計算和統計物理博士學位。目前,卡斯滕的研究重點是開發新的生成性學習方法,以及將深層生成模型應用于計算機視覺、圖形和數字藝術等領域的問題。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
4940瀏覽量
102817 -
人工智能
+關注
關注
1791文章
46867瀏覽量
237590
發布評論請先 登錄
相關推薦
PyTorch GPU 加速訓練模型方法

FPGA加速深度學習模型的案例
NVIDIA CorrDiff生成式AI模型能夠精準預測臺風
LLM大模型推理加速的關鍵技術
深度學習模型量化方法

python訓練出的模型怎么調用
谷歌推出AI擴散模型Lumiere
加速度傳感器的基本力學模型是什么
基于DiAD擴散模型的多類異常檢測工作

stm32ADXL357能讀取傳感器的ID號,但是讀溫度和加速度寄存器值一直為0如何解決?
SegRefiner:通過擴散模型實現高精度圖像分割






 工商網監
工商網監
評論