") 基于視覺的機(jī)器人抓取系統(tǒng)
基于視覺的機(jī)器人抓取系統(tǒng)
0
導(dǎo)讀
抓取綜合方法是機(jī)器人抓取問題的核心,本文從抓取檢測(cè)、視覺伺服和動(dòng)態(tài)抓取等角度進(jìn)行討論,提出了多種抓取方法。各位對(duì)機(jī)器人識(shí)別抓取感興趣的小伙伴,一定要來看一看!千萬別錯(cuò)過~
目錄/ contents
1. 引言
1.1抓取綜合方法
1.2 基于視覺的機(jī)器人抓取系統(tǒng)
2. 抓取檢測(cè)、視覺伺服和動(dòng)態(tài)抓取
2.1抓取檢測(cè)
2.2 視覺伺服控制
2.3動(dòng)態(tài)抓取
3. 本文實(shí)現(xiàn)的方法
3.1網(wǎng)絡(luò)體系結(jié)構(gòu)
3.2 Cornell 抓取數(shù)據(jù)集
3.3 結(jié)果評(píng)估
3.4視覺伺服網(wǎng)絡(luò)體系結(jié)構(gòu)
3.5VS數(shù)據(jù)集

1
引言
找到理想抓取配置的抓取假設(shè)的子集包括:機(jī)器人將執(zhí)行的任務(wù)類型、目標(biāo)物體的特征、關(guān)于物體的先驗(yàn)知識(shí)類型、機(jī)械爪類型,以及最后的抓取合成。
注:從本文中可以學(xué)習(xí)到視覺伺服的相關(guān)內(nèi)容,用于對(duì)動(dòng)態(tài)目標(biāo)的跟蹤抓取或自動(dòng)調(diào)整觀察姿態(tài)。因?yàn)橛^察的角度不同,預(yù)測(cè)的抓取框位置也不同:抓取物品離相機(jī)位置越近,抓取預(yù)測(cè)越準(zhǔn)。
1.1
抓取綜合方法
抓取綜合方法是機(jī)器人抓取問題的核心,因?yàn)樗婕暗皆谖矬w中尋找最佳抓取點(diǎn)的任務(wù)。這些是夾持器必須與物體接觸的點(diǎn),以確保外力的作用不會(huì)導(dǎo)致物體不穩(wěn)定,并滿足一組抓取任務(wù)的相關(guān)標(biāo)準(zhǔn)。
抓取綜合方法通常可分為分析法和基于數(shù)據(jù)的方法。
分析法是指使用具有特定動(dòng)力學(xué)行為的靈巧且穩(wěn)定的多指手構(gòu)造力閉合
基于數(shù)據(jù)的方法指建立在按某種標(biāo)準(zhǔn)的條件下,對(duì)抓取候選對(duì)象的搜索和對(duì)象分類的基礎(chǔ)上。(這一過程往往需要一些先驗(yàn)經(jīng)驗(yàn))
1.2
基于視覺的機(jī)器人抓取系統(tǒng)
基于視覺的機(jī)器人抓取系統(tǒng)一般由四個(gè)主要步驟組成,即目標(biāo)物體定位、物體姿態(tài)估計(jì)、抓取檢測(cè)(合成)和抓取規(guī)劃。
一個(gè)基于卷積神經(jīng)網(wǎng)絡(luò)的系統(tǒng),一般可以同時(shí)執(zhí)行前三個(gè)步驟,該系統(tǒng)接收對(duì)象的圖像作為輸入,并預(yù)測(cè)抓取矩形作為輸出。
而抓取規(guī)劃階段,即機(jī)械手找到目標(biāo)的最佳路徑。它應(yīng)該能夠適應(yīng)工作空間的變化,并考慮動(dòng)態(tài)對(duì)象,使用視覺反饋。
目前大多數(shù)機(jī)器人抓取任務(wù)的方法執(zhí)行一次性抓取檢測(cè),無法響應(yīng)環(huán)境的變化。因此,在抓取系統(tǒng)中插入視覺反饋是可取的,因?yàn)樗棺ト∠到y(tǒng)對(duì)感知噪聲、物體運(yùn)動(dòng)和運(yùn)動(dòng)學(xué)誤差具有魯棒性。
2
抓取檢測(cè)、視覺伺服和動(dòng)態(tài)抓取
抓取計(jì)劃分兩步執(zhí)行:
首先作為一個(gè)視覺伺服控制器,以反應(yīng)性地適應(yīng)對(duì)象姿勢(shì)的變化。
其次,作為機(jī)器人逆運(yùn)動(dòng)學(xué)的一個(gè)內(nèi)部問題,除了與奇異性相關(guān)的限制外,機(jī)器人對(duì)物體的運(yùn)動(dòng)沒有任何限制。
2.1
抓取檢測(cè)
早期的抓取檢測(cè)方法一般為分析法,依賴于被抓取物體的幾何結(jié)構(gòu),在執(zhí)行時(shí)間和力估計(jì)方面存在許多問題。
此外,它們?cè)谠S多方面都不同于基于數(shù)據(jù)的方法。
基于數(shù)據(jù)的方法:Jiang、Moseson和Saxena等人僅使用圖像,從五個(gè)維度提出了機(jī)器人抓取器閉合前的位置和方向表示。
如下圖,該五維表示足以對(duì)抓取姿勢(shì)的七維表示進(jìn)行編碼[16],因?yàn)榧俣▓D像平面的法線近似。因此,三維方向僅由給出。
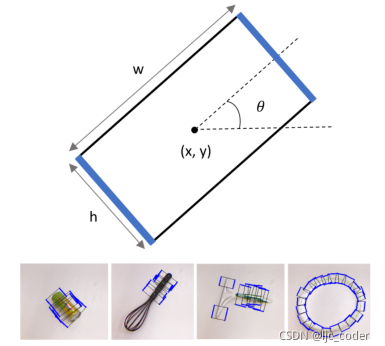
本文的工作重點(diǎn)是開發(fā)一種簡單高效的CNN,用于預(yù)測(cè)抓取矩形。
在訓(xùn)練和測(cè)試步驟中,所提出的網(wǎng)絡(luò)足夠輕,可以聯(lián)合應(yīng)用第二個(gè)CNN,解決視覺伺服控制任務(wù)。因此,整個(gè)系統(tǒng)可以在機(jī)器人應(yīng)用中實(shí)時(shí)執(zhí)行,而不會(huì)降低兩項(xiàng)任務(wù)的精度。
2.2
視覺伺服控制
經(jīng)典的視覺伺服(VS)策略要求提取視覺特征作為控制律的輸入。我們必須正確選擇這些特征,因?yàn)榭刂频聂敯粜耘c此選擇直接相關(guān)。
最新的VS技術(shù)探索了深度學(xué)習(xí)算法,以同時(shí)克服特征提取和跟蹤、泛化、系統(tǒng)的先驗(yàn)知識(shí)以及在某些情況下處理時(shí)間等問題。
Zhang等人開發(fā)了第一項(xiàng)工作,證明了在沒有任何配置先驗(yàn)知識(shí)的情況下,從原始像素圖像生成控制器的可能性。作者使用Deep Q-Network ,通過深度視覺運(yùn)動(dòng)策略控制機(jī)器人的3個(gè)關(guān)節(jié),執(zhí)行到達(dá)目標(biāo)的任務(wù)。訓(xùn)練是在模擬中進(jìn)行的,沒有遇到真實(shí)的圖像。
遵循強(qiáng)化學(xué)習(xí)方法的工作使用確定性策略梯度設(shè)計(jì)新的基于圖像的VS或Fuzzy Q-Learning,依靠特征提取,控制多轉(zhuǎn)子空中機(jī)器人。
在另一種方法中,一些研究視覺伺服深度學(xué)習(xí)的工作是通過卷積神經(jīng)網(wǎng)絡(luò)進(jìn)行的。CNN的泛化能力優(yōu)于RL,因?yàn)镽L學(xué)習(xí)的參數(shù)是特定于環(huán)境和任務(wù)的。
本文設(shè)計(jì)了四種卷積神經(jīng)網(wǎng)絡(luò)模型作為端到端視覺伺服控制器的潛在候選。網(wǎng)絡(luò)不使用參考圖像和當(dāng)前圖像以外的任何類型的附加信息來回歸控制信號(hào)。
因此,所提出的網(wǎng)絡(luò)作為實(shí)際上的控制器工作,預(yù)測(cè)速度信號(hào),而不是相對(duì)姿態(tài)。
2.3
動(dòng)態(tài)抓取
學(xué)習(xí)感知行為的視覺表征,遵循反應(yīng)范式,直接從感覺輸入生成控制信號(hào),無需高級(jí)推理,有助于動(dòng)態(tài)抓取。
強(qiáng)化學(xué)習(xí)方法適用于特定類型的對(duì)象,并且仍然依賴于某種先驗(yàn)知識(shí),因此,最近大量研究探索了將深度學(xué)習(xí)作為解決閉環(huán)抓取問題的方法。
Levine等人提出了一種基于兩個(gè)組件的抓取系統(tǒng)。第一部分是預(yù)測(cè)CNN,其接收?qǐng)D像和運(yùn)動(dòng)命令作為輸入,并輸出通過執(zhí)行這樣的命令,所產(chǎn)生的抓取將是令人滿意的概率。第二個(gè)部分是視覺伺服功能。這將使用預(yù)測(cè)CNN來選擇將持續(xù)控制機(jī)器人成功抓取的命令。這稱為是深度強(qiáng)化學(xué)習(xí),需要很久的訓(xùn)練時(shí)間。
2019年,Morrison, Corke 和 Leitner 開發(fā)了一種閉環(huán)抓取系統(tǒng),在這種系統(tǒng)中,抓取檢測(cè)和視覺伺服不是同時(shí)學(xué)習(xí)的。作者使用完全CNN獲取抓取點(diǎn),并應(yīng)用基于位置的視覺伺服,使抓取器的姿勢(shì)與預(yù)測(cè)的抓取姿勢(shì)相匹配。
3
本文實(shí)現(xiàn)的方法
VS的目的是通過將相機(jī)連續(xù)獲得的圖像與參考圖像進(jìn)行比較,引導(dǎo)操縱器到達(dá)機(jī)器人能夠完全看到物體的位置,從而滿足抓取檢測(cè)條件。因此,該方法的應(yīng)用涵蓋了所有情況,其中機(jī)器人操作器(相機(jī)安裝在手眼模式下)必須跟蹤和抓取對(duì)象。
該系統(tǒng)包括三個(gè)階段:設(shè)計(jì)階段、測(cè)試階段和運(yùn)行階段。第一個(gè)是基于CNN架構(gòu)的設(shè)計(jì)和訓(xùn)練,以及數(shù)據(jù)集的收集和處理。在第二階段,使用驗(yàn)證集獲得離線結(jié)果,并根據(jù)其準(zhǔn)確性、速度和應(yīng)用領(lǐng)域進(jìn)行評(píng)估。第三階段涉及在機(jī)器人上測(cè)試經(jīng)過訓(xùn)練的網(wǎng)絡(luò),以評(píng)估其在實(shí)時(shí)和現(xiàn)實(shí)應(yīng)用中的充分性。
在運(yùn)行階段,系統(tǒng)運(yùn)行的要求是事先獲得目標(biāo)對(duì)象的圖像,該圖像將被VS用作設(shè)定點(diǎn)。只要控制信號(hào)的L1范數(shù)大于某個(gè)閾值,則執(zhí)行控制回路。
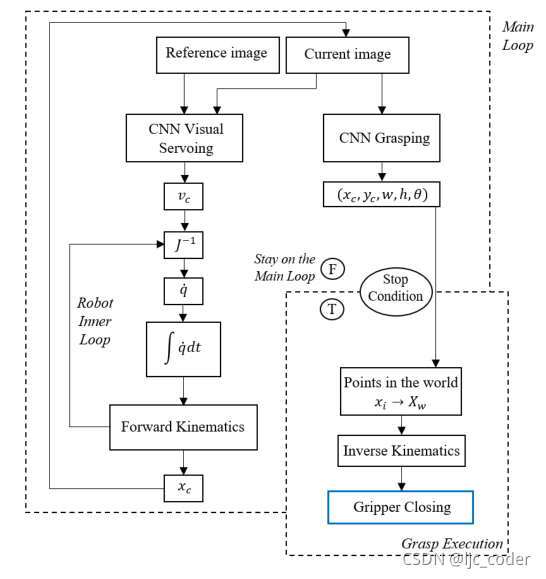
單個(gè)參考圖像作為視覺伺服CNN的輸入之一呈現(xiàn)給系統(tǒng)。相機(jī)當(dāng)前獲取的圖像作為該網(wǎng)絡(luò)的第二個(gè)輸入,并作為抓取CNN的輸入。這兩個(gè)網(wǎng)絡(luò)都連續(xù)運(yùn)行,因?yàn)樽トNN實(shí)時(shí)預(yù)測(cè)矩形以進(jìn)行監(jiān)控,VS網(wǎng)絡(luò)執(zhí)行機(jī)器人姿勢(shì)的實(shí)時(shí)控制。
VS CNN預(yù)測(cè)一個(gè)速度信號(hào),該信號(hào)乘以比例增益,以應(yīng)用于相機(jī)中。機(jī)器人的內(nèi)部控制器尋找保證相機(jī)中預(yù)測(cè)速度的關(guān)節(jié)速度。在每次循環(huán)執(zhí)行時(shí),根據(jù)機(jī)器人的當(dāng)前位置更新當(dāng)前圖像,只要控制信號(hào)不收斂,該循環(huán)就會(huì)重復(fù)。
當(dāng)滿足停止條件時(shí),抓取網(wǎng)絡(luò)的預(yù)測(cè)映射到世界坐標(biāo)系。機(jī)器人通過逆運(yùn)動(dòng)學(xué)得到并到達(dá)預(yù)測(cè)點(diǎn),然后關(guān)閉夾持器。
3.1
網(wǎng)絡(luò)體系結(jié)構(gòu)
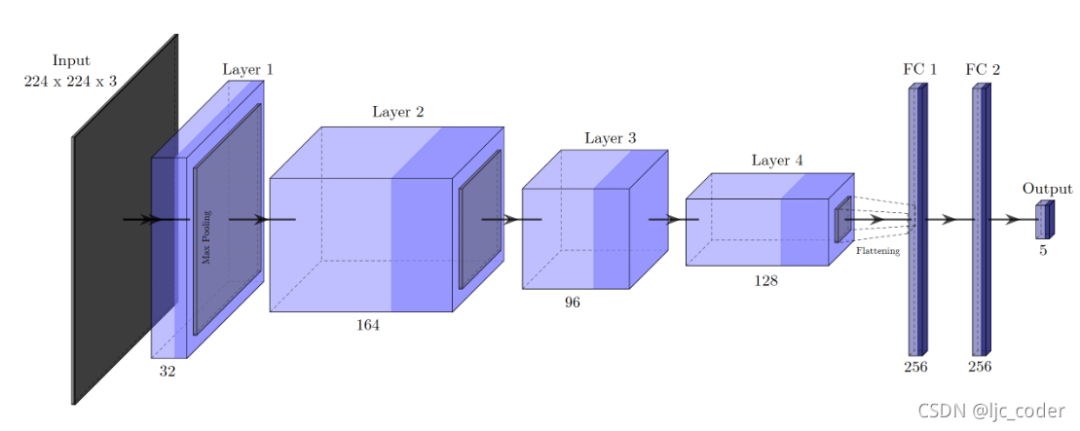
該卷積網(wǎng)絡(luò)架構(gòu)被用于抓取檢測(cè)。網(wǎng)絡(luò)接收224×224×3的RGB圖像作為輸入,無深度信息。
layer 1 由32個(gè)3×3卷積組成,layer 2 包含164個(gè)卷積。在這兩種情況下,卷積運(yùn)算都是通過步長2和零填充(zero-padding)執(zhí)行的,然后是批標(biāo)準(zhǔn)化(batch normalization)和2×2最大池化。layer 3 包含96個(gè)卷積,其中卷積使用步長1和零填充執(zhí)行,然后僅執(zhí)行批標(biāo)準(zhǔn)化。layer 4 ,也是最后一層,卷積層由128個(gè)卷積組成,以步長1執(zhí)行,然后是2×2最大池化。
在最后一層卷積之后,生成的特征映射在包含4608個(gè)元素的一維向量中被展開,進(jìn)一步傳遞到兩個(gè)全連接(FC)層,每個(gè)層有256個(gè)神經(jīng)元。在這些層次之間,訓(xùn)練期間考慮50%的dropout rate。
最后,輸出層由5個(gè)神經(jīng)元組成,對(duì)應(yīng)于編碼抓取矩形的**值。在所有層中,使用的激活函數(shù)都是ReLU**,但在輸出層中使用線性函數(shù)的情況除外。
3.2
Cornell 抓取數(shù)據(jù)集
為了對(duì)數(shù)據(jù)集真值進(jìn)行編碼,使用四個(gè)頂點(diǎn)的和坐標(biāo)編譯抓取矩形。
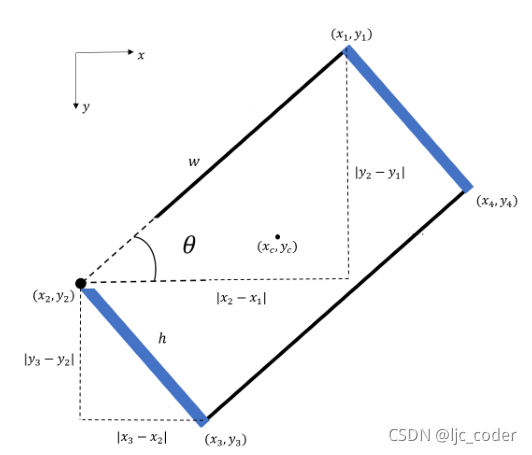
和參數(shù)分別表示矩形中心點(diǎn)的和坐標(biāo),可從以下公式獲得:

計(jì)算夾持器開口和高度,同樣根據(jù)四個(gè)頂點(diǎn)計(jì)算:
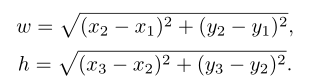
最后,表示夾持器相對(duì)于水平軸方向的由下式給出:
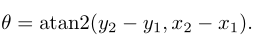
3.3
結(jié)果評(píng)估
預(yù)測(cè)矩形()和真值矩形()之間的角度差必須在30度以內(nèi)。
雅卡爾指數(shù)(交并比)需要大于0.25,而不是像一般那樣“達(dá)到0.25即可”。
3.4
視覺伺服網(wǎng)絡(luò)體系結(jié)構(gòu)
與抓取不同,設(shè)計(jì)用于執(zhí)行機(jī)械手視覺伺服控制的網(wǎng)絡(luò)接收兩個(gè)圖像作為輸入,并且必須回歸六個(gè)值,考慮到線性和角度相機(jī)速度。
這些值也可以分為兩個(gè)輸出,共有四個(gè)模型處理VS任務(wù)。
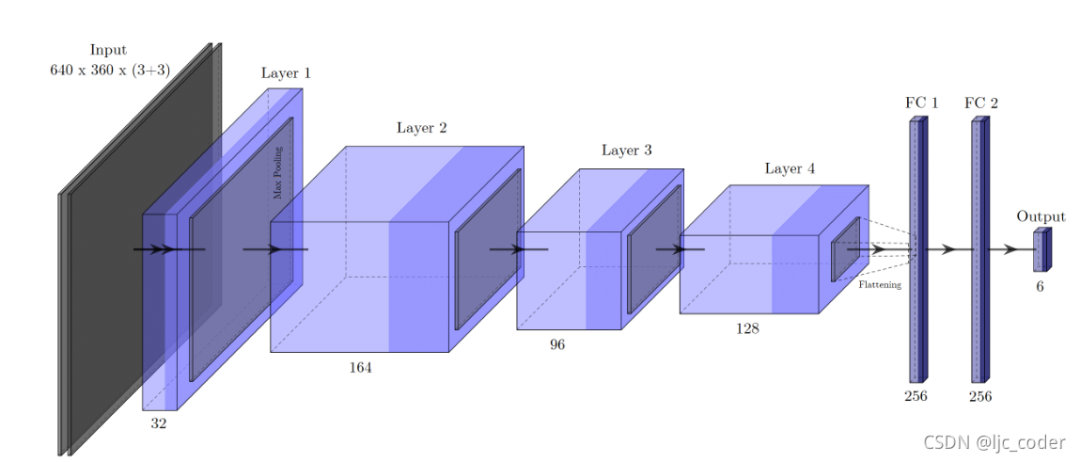
模型1-直接回歸(最終實(shí)驗(yàn)效果最佳)。它基本上與抓取網(wǎng)絡(luò)相同,除了在第三卷積層中包含最大池化和不同的輸入維度,這導(dǎo)致特征圖上的比例差異相同。
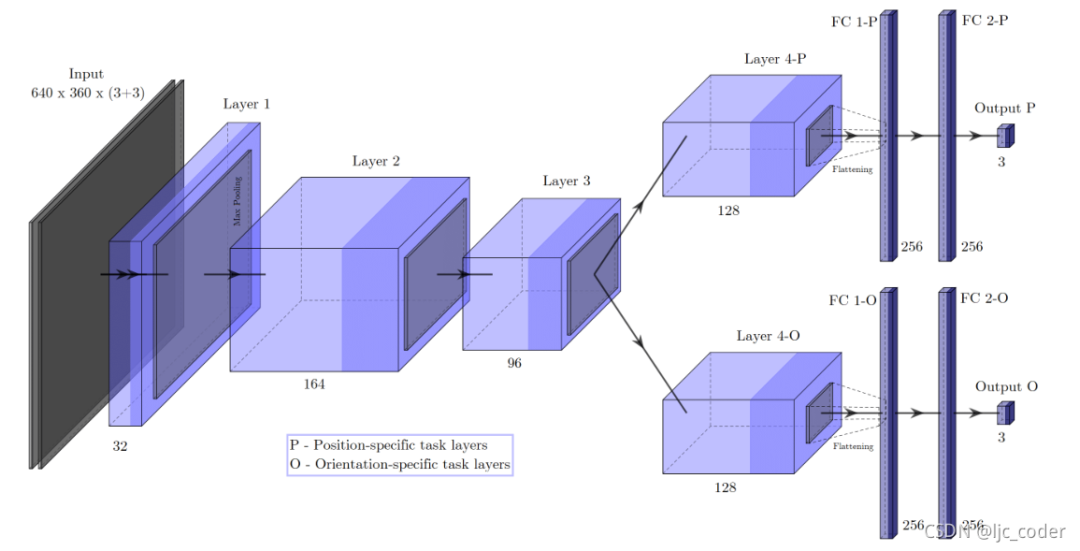
模型2-任務(wù)特定回歸。網(wǎng)絡(luò)輸入被串聯(lián),第三組特征圖由兩個(gè)獨(dú)立的層序列處理(多任務(wù)網(wǎng)絡(luò))。因此,網(wǎng)絡(luò)以兩個(gè)3D矢量的形式預(yù)測(cè)6D速度矢量。具體來說,該結(jié)構(gòu)由一個(gè)共享編碼器和兩個(gè)特定解碼器組成 - 一個(gè)用于線速度,另一個(gè)用于角速度。
模型3-串聯(lián)特征的直接回歸和模型4-相關(guān)特征的直接回歸,兩個(gè)模型的結(jié)構(gòu)類似,通過關(guān)聯(lián)運(yùn)算符()區(qū)分。
模型3簡單連接;模型4使用相關(guān)層。
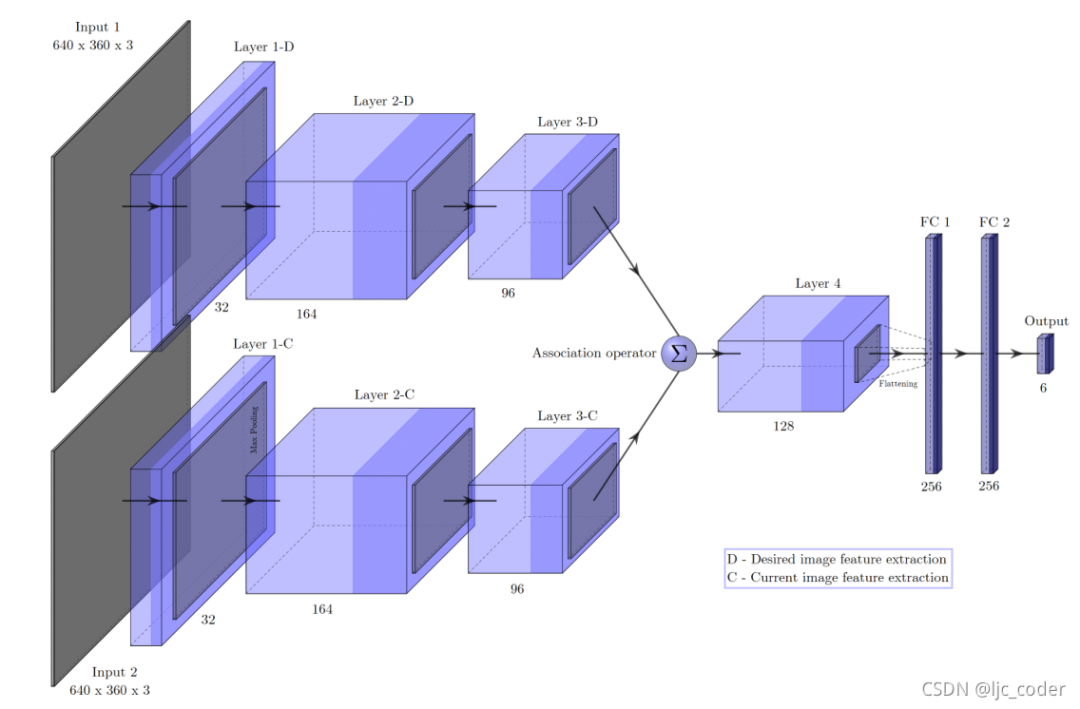
模型3簡單地由第三個(gè)卷積層產(chǎn)生的特征映射連接,因此第四個(gè)層的輸入深度是原來的兩倍。而模型4有一個(gè)相關(guān)層,幫助網(wǎng)絡(luò)找到每個(gè)圖像的特征表示之間的對(duì)應(yīng)關(guān)系。原始相關(guān)層是flow network FlowNet的結(jié)構(gòu)單元。
3.5
VS數(shù)據(jù)集
該數(shù)據(jù)集能夠有效地捕獲機(jī)器人操作環(huán)境的屬性,具有足夠的多樣性,以確保泛化。
機(jī)器人以參考姿態(tài)為中心的高斯分布的不同姿態(tài),具有不同的標(biāo)準(zhǔn)偏差(SD)。
下表為參考姿勢(shì)(分布的平均值)和機(jī)器人假設(shè)的標(biāo)準(zhǔn)偏差集(SD)。
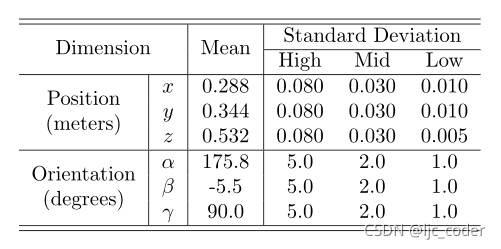
SD選擇考慮了機(jī)器人在VS期間必須執(zhí)行的預(yù)期位移值。
從高SD獲得的圖像有助于網(wǎng)絡(luò)了解機(jī)器人產(chǎn)生大位移時(shí)圖像空間中產(chǎn)生的變化。
當(dāng)參考圖像和當(dāng)前圖像非常接近時(shí),從低SD獲得的實(shí)例能夠減少參考圖像和當(dāng)前圖像之間的誤差,從而在穩(wěn)態(tài)下獲得良好的精度。
平均SD值有助于網(wǎng)絡(luò)在大部分VS執(zhí)行期間進(jìn)行預(yù)測(cè)。
獲得數(shù)據(jù)后,數(shù)據(jù)集以**的形式構(gòu)造,其中圖像為I**,****是拍攝該圖像時(shí)對(duì)應(yīng)的相機(jī)姿態(tài)。
為泰特-布萊恩角內(nèi)旋(按照變換)
已處理數(shù)據(jù)集的每個(gè)實(shí)例都采用()表示。是選擇作為所需圖像的隨機(jī)實(shí)例;選擇另一個(gè)實(shí)例作為當(dāng)前圖像;是二者的變換。
通過齊次變換矩陣形式表示每個(gè)姿勢(shì)(由平移和歐拉角表示)來實(shí)現(xiàn)(和),然后獲得
最后,對(duì)于實(shí)際上是控制器的網(wǎng)絡(luò),其目的是其預(yù)測(cè)相機(jī)的速度信號(hào),即:E控制信號(hào)。 被轉(zhuǎn)化為
是比例相機(jī)速度。由于在確定標(biāo)記比例速度時(shí)不考慮增益,因此使用了周期性項(xiàng),并且在控制執(zhí)行期間必須對(duì)增益進(jìn)行后驗(yàn)調(diào)整。
速度由表示:
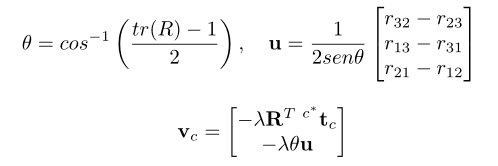
其中,是旋轉(zhuǎn)矩陣;****同一矩陣第i行和第j列的元素;是與當(dāng)前相機(jī)位置到期望相機(jī)位置的平移向量;是比例增益(初始設(shè)置為1)。
審核編輯 :李倩
-
機(jī)器人
+關(guān)注
關(guān)注
210文章
28212瀏覽量
206549 -
圖像
+關(guān)注
關(guān)注
2文章
1083瀏覽量
40418 -
視覺
+關(guān)注
關(guān)注
1文章
146瀏覽量
23893
原文標(biāo)題:【機(jī)器人識(shí)別抓取綜述】基于視覺的機(jī)器人抓取—從物體定位、物體姿態(tài)估計(jì)到平行抓取器抓取估計(jì)
文章出處:【微信號(hào):vision263com,微信公眾號(hào):新機(jī)器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
【書籍評(píng)測(cè)活動(dòng)NO.51】具身智能機(jī)器人系統(tǒng) | 了解AI的下一個(gè)浪潮!
解鎖機(jī)器人視覺與人工智能的潛力,從“盲人機(jī)器”改造成有視覺能力的機(jī)器人(上)

智能移動(dòng)機(jī)器人
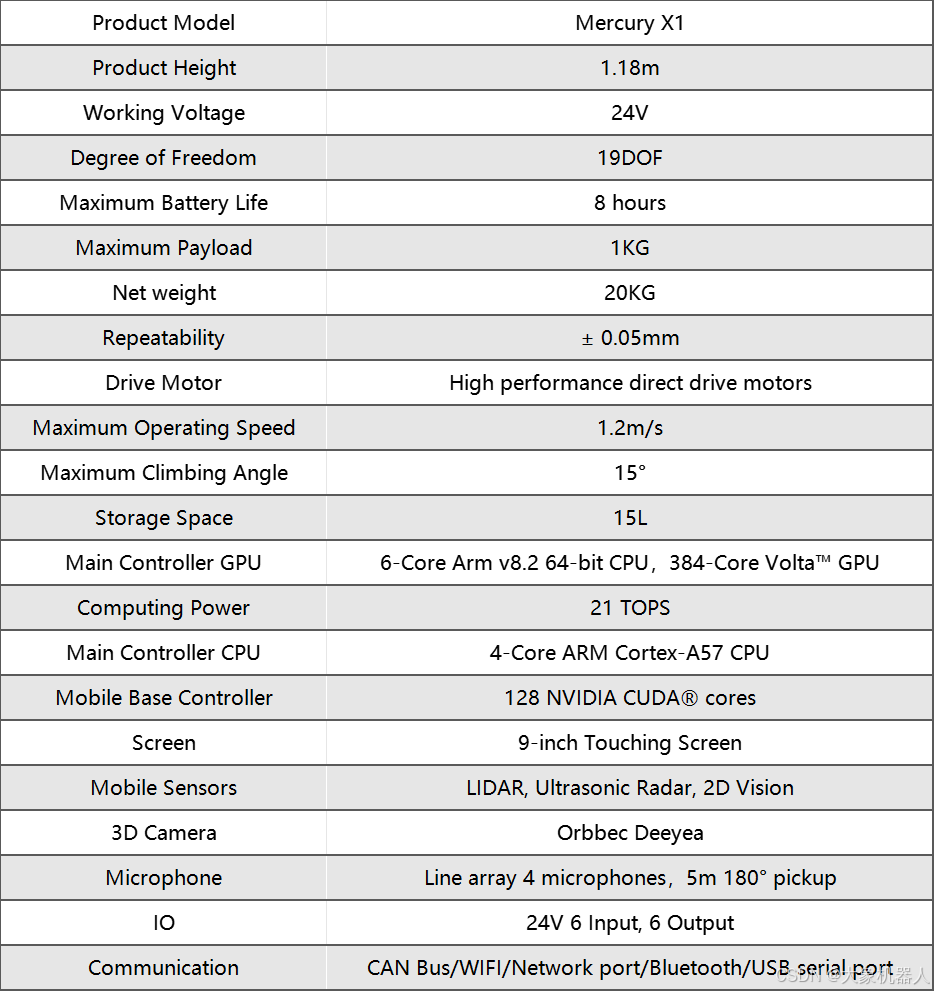
水星Mercury X1輪式人形機(jī)器人結(jié)合openc算法&STag標(biāo)記碼視覺系統(tǒng)實(shí)現(xiàn)精確抓取!
工業(yè)機(jī)器人視覺技術(shù)的應(yīng)用分為哪幾種?
機(jī)器人視覺與計(jì)算機(jī)視覺的區(qū)別與聯(lián)系
機(jī)器人視覺的應(yīng)用范圍
機(jī)器人視覺的作用是什么
簡述機(jī)器人控制系統(tǒng)的組成
基于FPGA EtherCAT的六自由度機(jī)器人視覺伺服控制設(shè)計(jì)
富唯智能案例|3D視覺引導(dǎo)機(jī)器人抓取鞋墊上下料

視覺機(jī)器人焊接的研究現(xiàn)狀

機(jī)器人視覺定位抓取技術(shù)原理總結(jié)
富唯智能機(jī)器人集成了協(xié)作機(jī)器人、移動(dòng)機(jī)器人和視覺引導(dǎo)技術(shù)
基于視覺的自主導(dǎo)航移動(dòng)抓取機(jī)器人搭建方案





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論