") X-CUBE-AI v7.1.0的三大更新內(nèi)容
X-CUBE-AI v7.1.0的三大更新內(nèi)容
X-CUBE-AI是STM32生態(tài)系統(tǒng)中的AI擴展包。可自動轉(zhuǎn)換預(yù)訓(xùn)練的人工智能模型,并在用戶項目中生成STM32優(yōu)化庫。
最新版的X-CUBE-AI v7.1.0在以下方面進行了三大更新:
支持入門級STM32 MCU
支持最新的AI訓(xùn)練框架
改善用戶體驗和性能調(diào)節(jié)。
我們通過提供更多用戶友好的界面,不斷增強STM32 AI生態(tài)系統(tǒng)的功能,并加強了神經(jīng)網(wǎng)絡(luò)計算中的更多操作。最重要的是,該擴展包由我們免費提供。
在介紹X-CUBE-AI v7.1.0的三大更新內(nèi)容之前,我們先回顧一下X-CUBE-AI的主要用途。
什么是X-CUBE-AI擴展包
X-CUBE-AI擴展包,也稱STM32Cube.AI,裝配優(yōu)化模塊,確保從精度、內(nèi)存占用和電源效率方面為目標STM32生成最佳擬合模型。
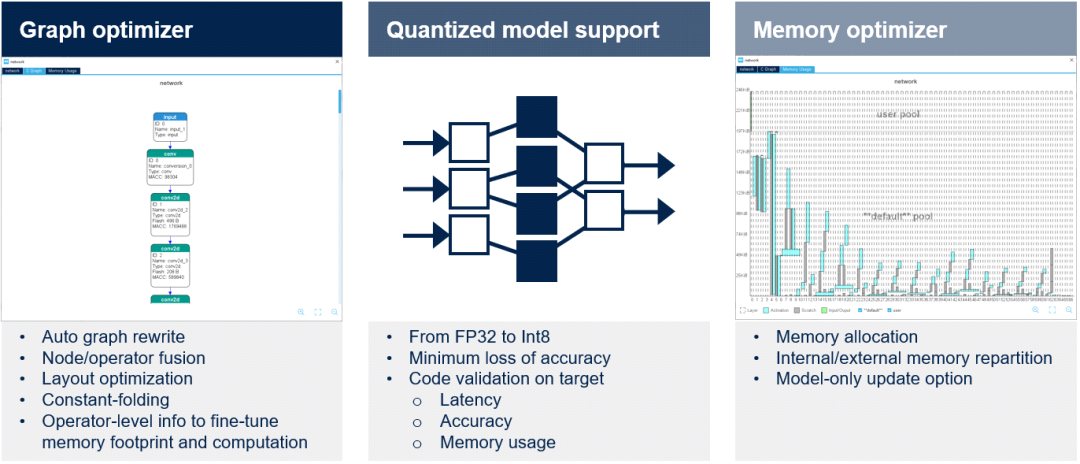
圖形優(yōu)化器通過有利于STM32目標硬件架構(gòu)的圖形簡化和優(yōu)化自動提高性能。使用了幾種優(yōu)化技術(shù),如計算圖重組、算子融合、常數(shù)折疊等。
量化器X-CUBE-AI擴展包支持FP32和Int8預(yù)訓(xùn)練模型。開發(fā)人員可以導(dǎo)入量化神經(jīng)網(wǎng)絡(luò)以兼容STM32嵌入式架構(gòu),同時通過采用文檔中詳述的訓(xùn)練后量化過程來保持性能。在下一個版本中,還將考慮Int1、Int2和Int3。成功導(dǎo)入模型后,可在桌面和目標STM32硬件上驗證代碼。
內(nèi)存優(yōu)化器內(nèi)存優(yōu)化器是一種高級內(nèi)存管理工具。優(yōu)化內(nèi)存分配以獲得最佳性能,同時符合嵌入式設(shè)計的要求。可在內(nèi)部和外部資源之間實現(xiàn)內(nèi)存分配的智能平衡,還可以為模型創(chuàng)建專用內(nèi)存。開發(fā)人員可以輕松地更新模型。
X-CUBE-AI v7.1.0的三大更新
在最新版本的X-CUBE-AI v7.1.0中,我們進行了三大更新。
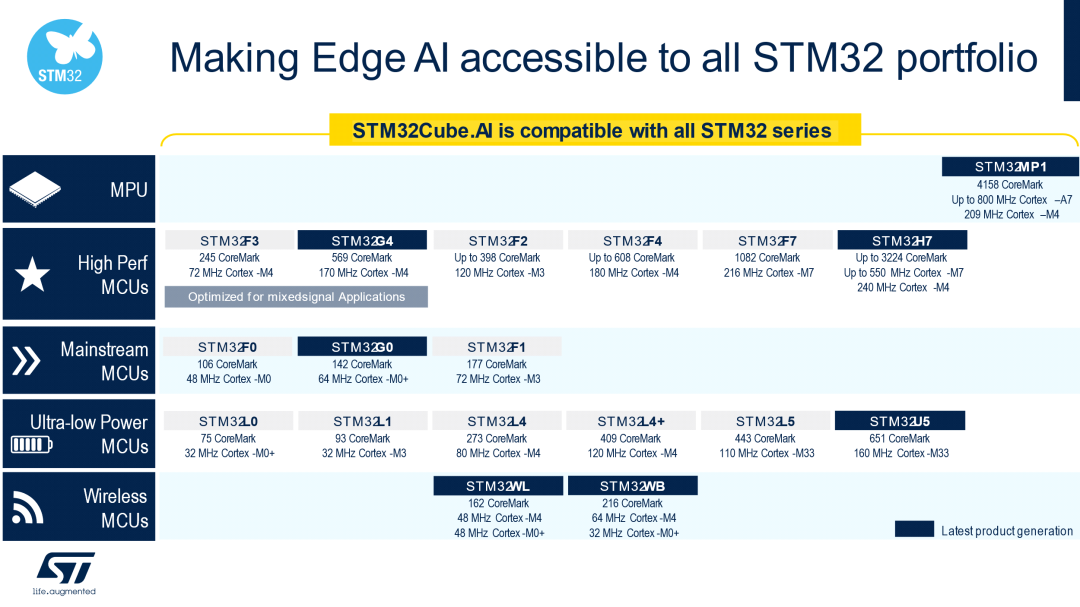
支持入門級STM32 MCU為了讓您的邊緣設(shè)備在各個層面都支持AI,我們使X-CUBE-AI v7.1.0實現(xiàn)了對STM32 Arm Cortex-M0和Arm Cortex-M0+的全面支持。從現(xiàn)在起,用戶可以將神經(jīng)網(wǎng)絡(luò)帶至最小的STM32微控制器上。
開發(fā)人員不僅可以在以下產(chǎn)品組合中找到用于各種用途的匹配芯片,還可以擁有一款具有AI啟發(fā)性的芯片。STM32的頻譜范圍從超低功耗到高性能系列和微處理器,均包含在內(nèi)。無線MCU等不同用途也適合AI應(yīng)用。
支持最新的AI框架最新版本的X-CUBE-AI v7.1.0在Keras和TensorFlow等廣泛使用的深度學(xué)習(xí)框架中添加了多種功能,并將TFLite runtime升級至2.7.0,將ONNX升級至1.9。
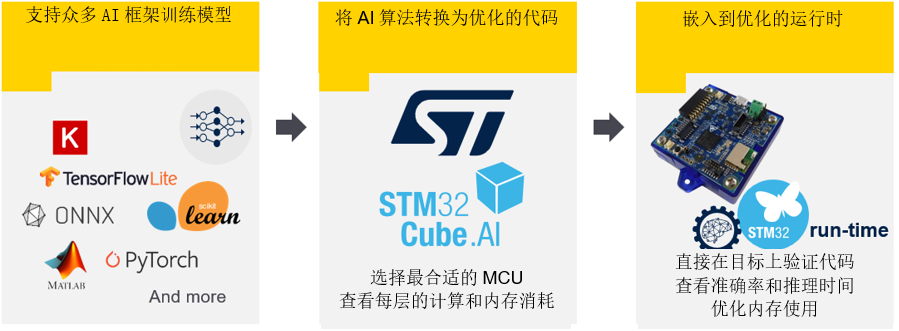
Keras通過Tensorflow得到支持,支持的算子允許處理針對移動或物聯(lián)網(wǎng)資源受限的運行時環(huán)境的大量經(jīng)典拓撲。例如,SqueezeNet、MobileNet V1或V2、Inception、SSD MobileNet V1等。在X-CUBE-AI v7.1.0中最高可支持TF Keras 2.7.0。
Tensorflow Lite是在移動平臺上部署神經(jīng)網(wǎng)絡(luò)模型的格式。X-CUBE-AI導(dǎo)入并轉(zhuǎn)換基于flatbuffer技術(shù)的tflite文件。處理多個算子,包括量化模型和量化感知訓(xùn)練或訓(xùn)練后量化過程生成的算子。
對于其他可以導(dǎo)出為ONNX標準格式的框架,如PyTorch、Microsoft Cognitive Toolkit、MATLAB等,X-CUBE-AI同樣支持。
每個AI框架我們只支持所有可能層和層參數(shù)子集,這取決于網(wǎng)絡(luò)C API的表達能力和特定工具箱的解析器。
我們提供STM32Cube.AI運行時,以便在執(zhí)行AI應(yīng)用程序時獲得最佳性能。但是,開發(fā)人員可以選擇TensorFlow Lite運行時作為一種替代方案,在多個項目中發(fā)揮作用。即使可能會降低性能,因為運行時針對STM32的優(yōu)化程度較低。
除了深度學(xué)習(xí)框架外,X-CUBE-AI還涵蓋了來自著名開源庫scikit-learn的機器學(xué)習(xí)算法,這是一個完整的Python機器學(xué)習(xí)框架,如:隨機森林、支持向量機(SVM)、k-means聚類和k最近鄰(k-NN)。開發(fā)人員可以構(gòu)建大量有監(jiān)督或無監(jiān)督的機器學(xué)習(xí)算法,并利用簡單高效的工具進行數(shù)據(jù)分析。
X-CUBE-AI v7.1.0不直接支持來自scikit-learn框架或XGBoost包的機器學(xué)習(xí)算法。在完成訓(xùn)練步驟后,這些算法應(yīng)轉(zhuǎn)換為ONNX格式,以便部署和導(dǎo)入。skl2onnx實用程序通常用于將模型轉(zhuǎn)換為ONNX格式。可以使用帶有ONNX導(dǎo)出器的其他ML框架,但請注意,X-CUBE-AI中ONNX-ML模型的導(dǎo)入主要使用 scikit-learn v0.23.1、skl2onnx v1.10.3和XGBoost v1.5.1進行測試。
改善用戶體驗和性能調(diào)節(jié)X-CUBE-AI v7.1.0引入了多堆支持,開發(fā)人員只需單擊即可輕松地將不同內(nèi)容分配到碎片化的內(nèi)存段上。
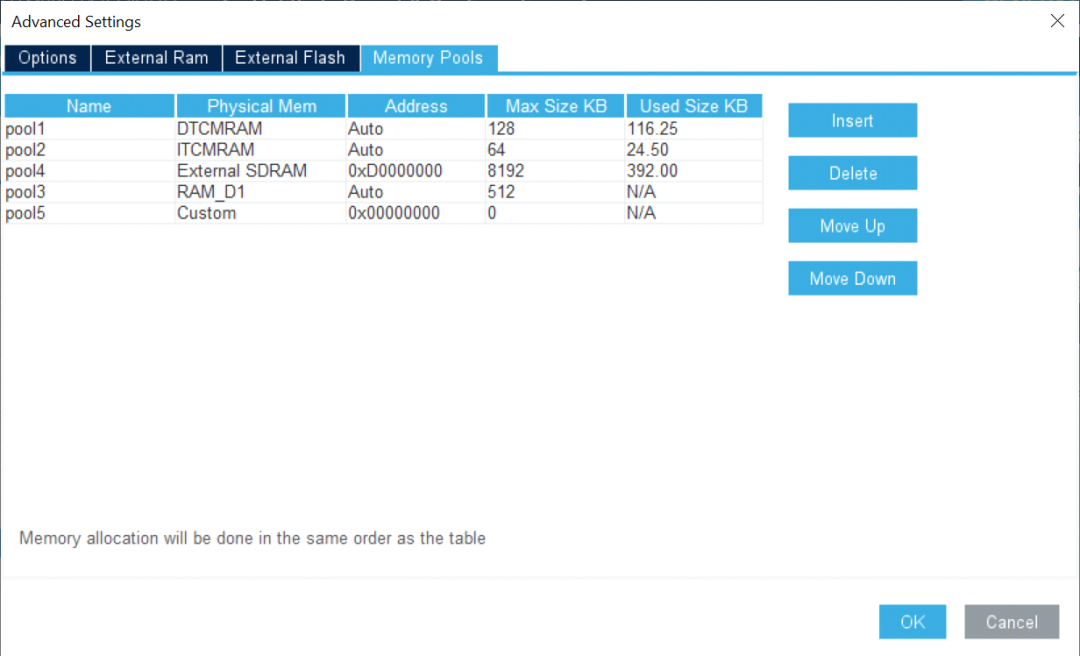
通過使用外部內(nèi)存支持,開發(fā)人員可以輕松地在不同的內(nèi)存區(qū)域分配權(quán)重。一旦模型存儲在多個數(shù)組中,便可將部分權(quán)重映射到內(nèi)部閃存,而其余的則映射到外部閃存。該工具使開發(fā)人員可以根據(jù)模型要求和應(yīng)用程序內(nèi)存占用使用非連續(xù)閃存區(qū)。
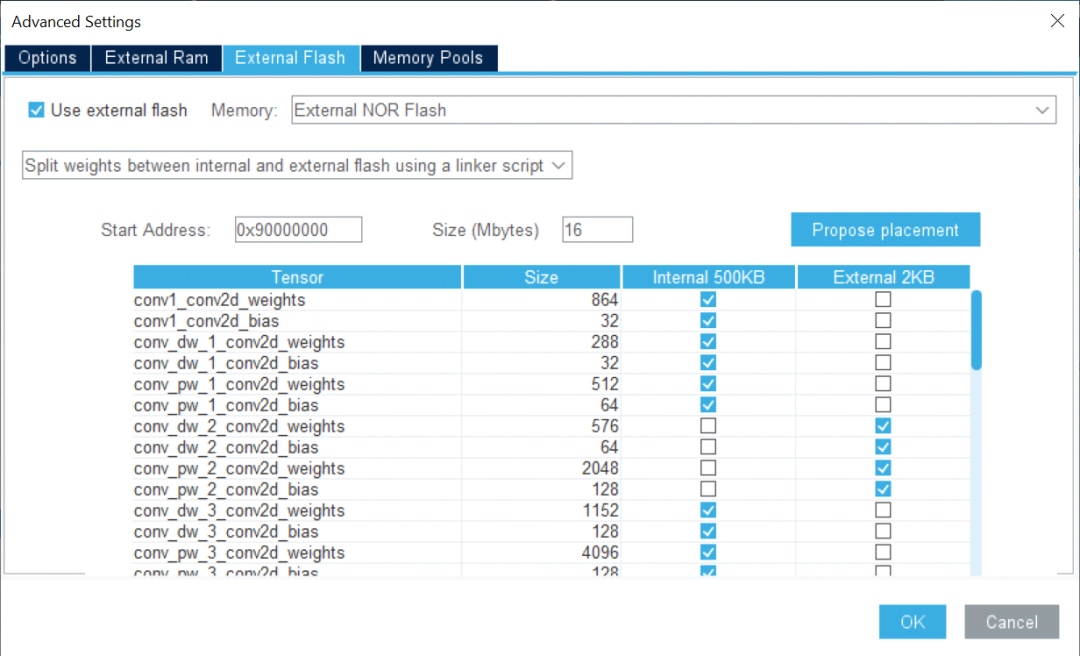
圖形用戶界面還提供了生成代碼中使用的緩沖區(qū)的全面視圖。一旦選擇了模型,開發(fā)人員就可以通過直觀地檢查統(tǒng)計數(shù)據(jù)來評估整體復(fù)雜性和內(nèi)存占用。模型中的每一層都清晰可見,開發(fā)人員可以輕松識別關(guān)鍵層。
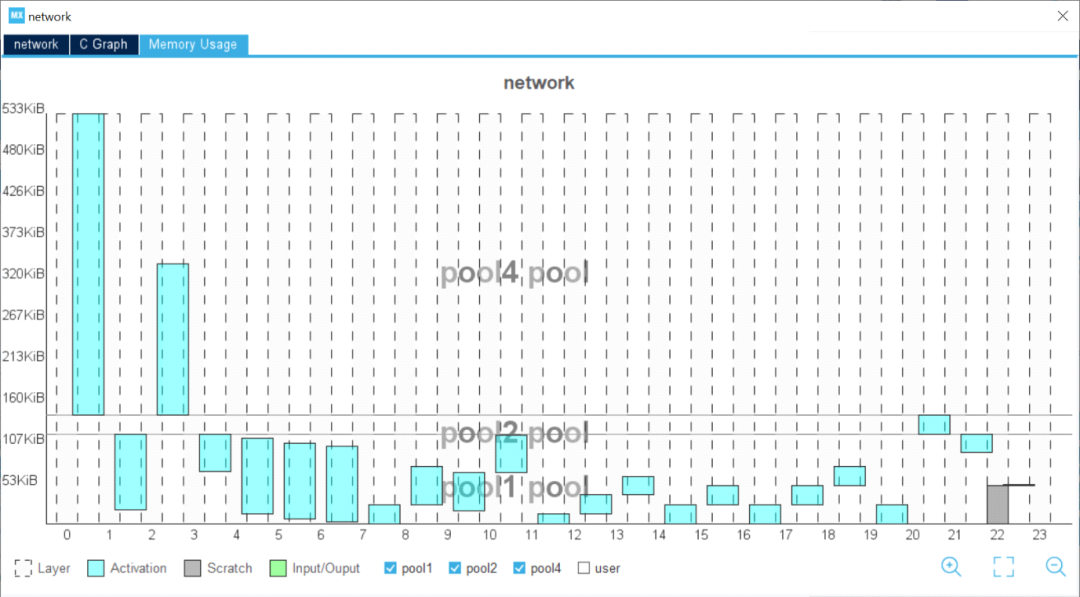
該工具可幫助開發(fā)人員加快速度,使我們能夠在桌面上驗證模型,進行快速基準測試并檢測目標STM32設(shè)備的最終性能。
驗證過程結(jié)束時,對比表總結(jié)了原始模型和STM32模型之間的準確性和誤差。X-CUBE-AI還提供了每層的計算復(fù)雜度報告,以及運行時測量的推斷時間。
X-CUBE-AI只是意法半導(dǎo)體為STM32用戶利用人工智能提供的廣泛生態(tài)系統(tǒng)的一部分。使用X-CUBE-AI可確保高質(zhì)量開發(fā)的長期支持和可靠性。每次推出新的主要版本時,都會有針對性地定期更新,確保兼容最新AI框架。敬請關(guān)注我們?yōu)槟鷰淼母嘤腥ぜ夹g(shù)。
我們將策劃一系列AI主題文章,詳細介紹意法半導(dǎo)體在Deep Edge AI領(lǐng)域的努力成果。
本文是該系列文章中的第十一篇,點擊上方的話題,訂閱我們的AI技術(shù)專題系列 。
歡迎您在文后積極留言,告訴我們想了解意法半導(dǎo)體AI的哪些方面,我們將為您呈現(xiàn)更多精彩內(nèi)容。
原文標題:AI技術(shù)專題之十一:更簡便、更智能的X-CUBE-AI v7.1.0,讓您輕松部署AI模型
文章出處:【微信公眾號:意法半導(dǎo)體中國】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
審核編輯:湯梓紅
-
STM32
+關(guān)注
關(guān)注
2266文章
10871瀏覽量
354806 -
意法半導(dǎo)體
+關(guān)注
關(guān)注
31文章
3106瀏覽量
108525 -
AI
+關(guān)注
關(guān)注
87文章
30146瀏覽量
268414
原文標題:AI技術(shù)專題之十一:更簡便、更智能的X-CUBE-AI v7.1.0,讓您輕松部署AI模型
文章出處:【微信號:STMChina,微信公眾號:意法半導(dǎo)體中國】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論