 如何讓HSPICE仿真效率提升42倍?
如何讓HSPICE仿真效率提升42倍?
作為最早的電子設計自動化軟件,我們的EDA云實證系列從SPICE開始,再合適不過。
在它出現之前,人們分析電路,用的是紙筆或者搭電路板。隨著電路規模增大,手工明顯跟不上。
于是,1971年,SPICE誕生了。全稱“Simulation Program with Integrates Circuit Emphasis"。
H-SPICE是隨著產業環境及電路設計技術的發展與升級,以“SPICE2”為基礎加以改進而成的商業軟件產品,現在屬于Synopsys。
既然有了新的計算機輔助工具,那問題就來了:
怎么才能跑得更快一點?
怎么才能運行更大規模的集成電路?
第一個答案是算法改進。這屬于數學領域,很難。
第二個答案是摩爾定律。從上世紀70年代初到如今,SPICE從只能仿真十幾個元器件到今天可以仿真上千萬個元器件的電路。但已經幾十年沒有太大的變化了。
第三個答案是計算架構升級,從單核到多核,單線程到多線程。
第四個答案是Cloud HPC云端高性能計算。談概念過于抽象,我們今天拿實證說話。
實證背景信息
用戶需求
公司在本地部署了由十多臺機器組成的計算集群,但目前面臨的最大問題依然是算力不足。特別是面對每年十次左右的算力高峰期時,基本上沒有太好的辦法。
對云的認知
C社相關負責人表示:算力不足是目前IC設計行業普遍面臨的問題。對于EDA上云,公司之前沒有嘗試過,對云模式和架構也并不了解,在數據安全性方面也存在一定的顧慮。
不過該負責人對于EDA上云早有耳聞,也頗感興趣,愿意進行一定的嘗試。畢竟上云若真的能夠加快運算速度,就意味著可以更早展開研究,從而提升項目的整體進度。
實證目標
1、HSPICE任務能否在云端運行?
2、云端資源是否能適配HSPICE任務需求?
3、fastone平臺能否有效解決目前業務問題?
4、相比傳統手動模式,云端計算集群的自動化部署,有哪些好處?
實證參數
平臺:
fastone企業版產品
應用:
HSPICE
適用場景:
仿真模擬電路、混合信號電路、精確數字電路、建立SoC的時序及功耗單元庫、分析系統級的信號完整性等
技術架構圖:
用戶登錄VDI,使用fastone算力運營平臺根據實際計算需求自動創建、銷毀集群,完成計算任務。
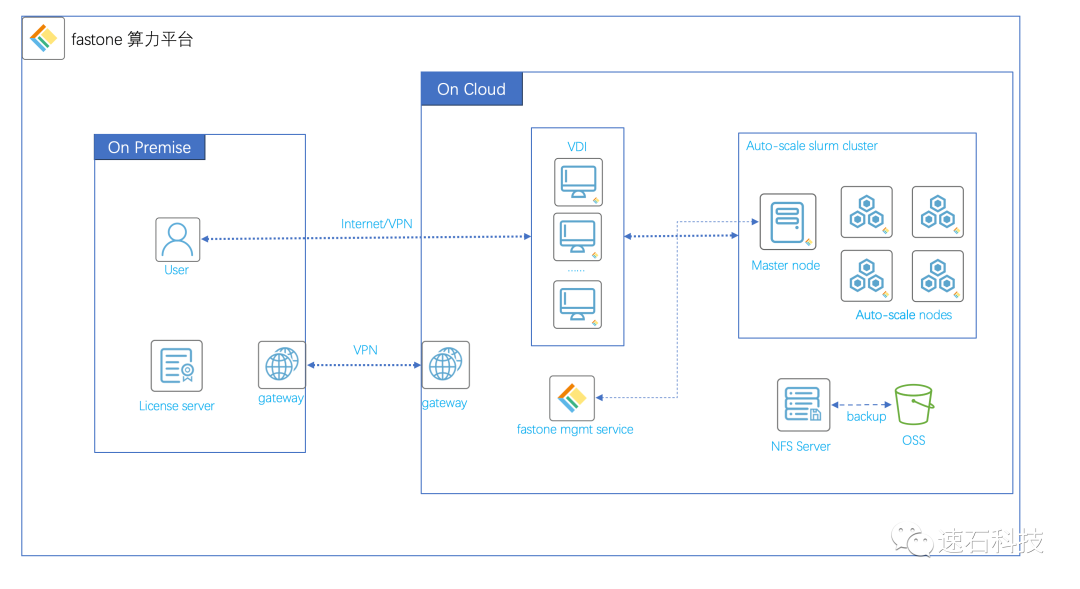
License配置:
EDA License Server設置在本地。
步驟一:硬件選擇
選擇適合HSPICE應用的配置
云端可以選擇的機型有幾百種,配置、價格差異極大。
我們首先需要挑選出既能滿足HSPICE應用需求,又具備性價比的機型。
已知用戶的本地硬件配置:
Xeon(R) Gold 6244 CPU @ 3.60GHz,512GB Memory
本地配置不僅主頻高,內存也相當大。
我們推薦的云端硬件配置:
96 vCPU, 3.6GHz, 2nd Gen Intel Xeon Platinum 8275CL, 192 GiB Memory
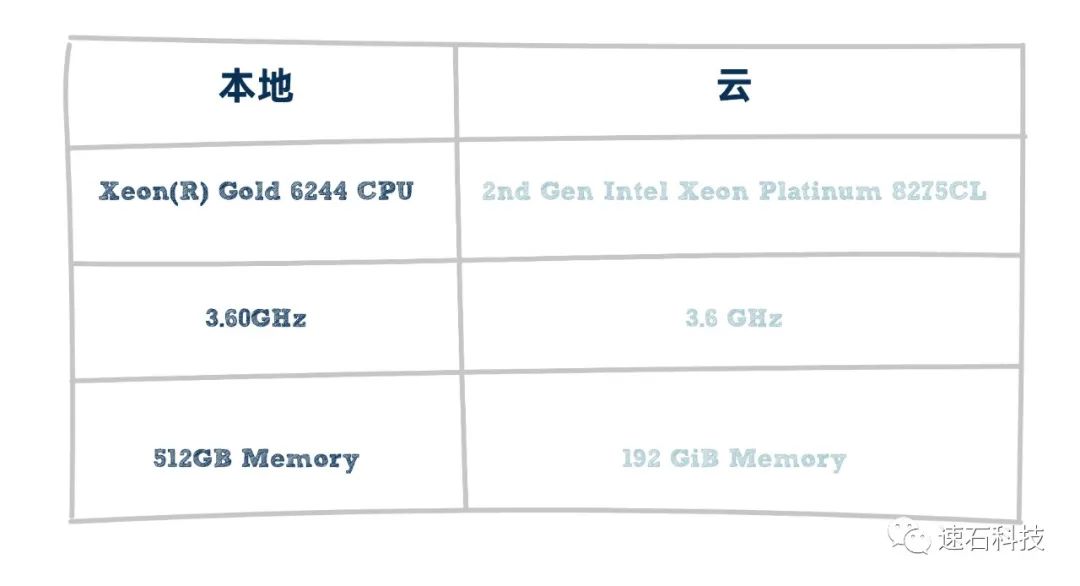
推薦理由:
1、該應用對CPU主頻要求較高,但內存要求并不大;
2、我們選擇了計算優化型云端實例,即具備高性價比的高主頻機器。
C社的本地硬件在HSPICE以外,還需處理一些需要大內存的后端任務,所以需要在配置上兼顧各種資源需求,在當前項目不可避免會造成一定的資源浪費。
步驟二:云端部署
手動模式 VS 自動部署
我們先看手動模式:
第一步:不管你需要用哪朵云,你都得先熟悉那家云的操作界面,掌握正確的使用方法;
第二步:構建大規模算力集群:
配置計算節點,存儲節點,VPC,安全組等等
安裝應用,把HSPICE安裝在集群環境
配置集群調度器,比如slurm
第三步:上傳任務數據,開啟計算;
第四步:任務完成后及時下載結果并關機。
不要笑,這一點很重要。我們在切換七種視角,我們給各位CXO大佬算算上云這筆賬有講到原因。
此外,還有一個需要考慮的點,時間。
第一步,需要多少時間說不好;
第二步,大概需要專業IT人員平均3-5天;
第三步/第四步,如果數據量較大,需要考慮斷點續傳和自動重傳;
第四步,任務完成時間很可能難以預測。
即使是可測的,我們可以想象一個場景——有個任務預計在凌晨跑完,用戶此時有兩個選擇:
1、調一個鬧鐘,半夜起來關機——有人遭罪;
2、睡到自然醒,次日上班關機——成本浪費。

在手動模式下,通常都是先構建一個固定規模的集群,然后提交任務,全部任務結束后,關閉集群。
想一下一個幾千core的集群拉起來之后,第二、三、四步手動配置的時間里,所有機器一直都是開啟狀態,也就是說,燒錢中。
再看看我們的自動化部署:
第一步,不需要;
第二步,只需要點擊幾個按鈕,5-10分鐘即可開啟集群;
第三步,我們有Auto-Scale功能,自動開關機。
另外,我們還自帶資源的管理和監控功能。
fastone的Auto-Scale功能可以自動監控用戶提交的任務數量和資源的需求,動態按需地開啟所需算力資源,在提升效率的同時有效降低成本。
所有操作都是自動化完成,無需用戶干預;
在實際開機過程中,可能遇到云在某個可用區資源不足的情況,fastone會自動嘗試從別的區域開啟資源;
如果需要的資源確實不夠,又急需算力完成任務,用戶還可以從fastone界面選擇配置接近的實例類型來補充。
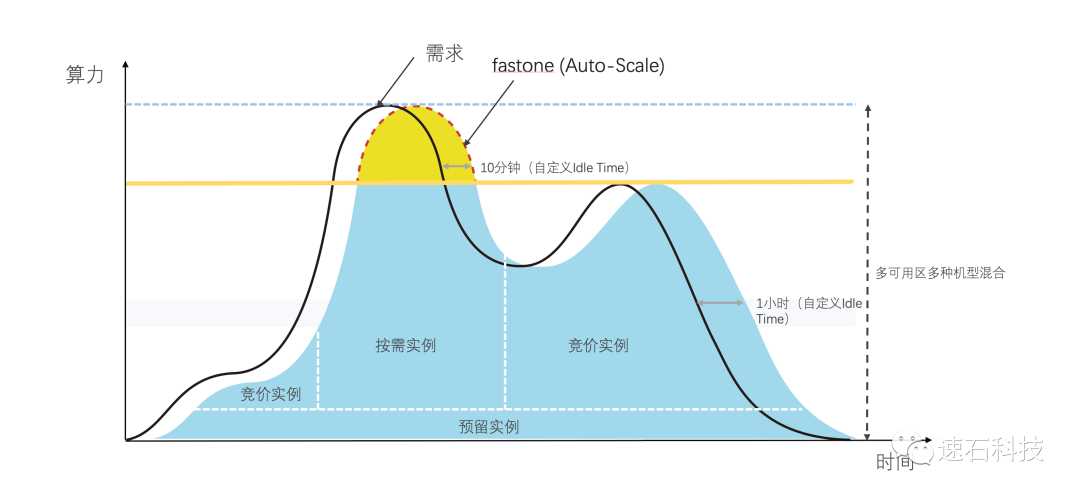
跨區域,跨機型使用,在本次實證場景沒有用到。
我們還可以根據GPU的需求來實現自動伸縮,下次單獨聊。
實證場景一:云端驗證
本地40核 VS 云端40核 VS云端80核
結論:
1、當計算資源與任務拆分方式均為5*8核時,本地和云端的計算周期基本一致;
2、在云端將任務拆分為10*4核后,比5*8核的拆分方式計算周期減少三分之一;
3、當任務拆分方式不變,計算資源從40核增加到80核,計算周期減半;
4、當計算資源翻倍,且任務拆分方式從5*8核變更為10*4核后,計算周期減少三分之二;
5、fastone自動化部署可大幅節省用戶的時間和人力成本。
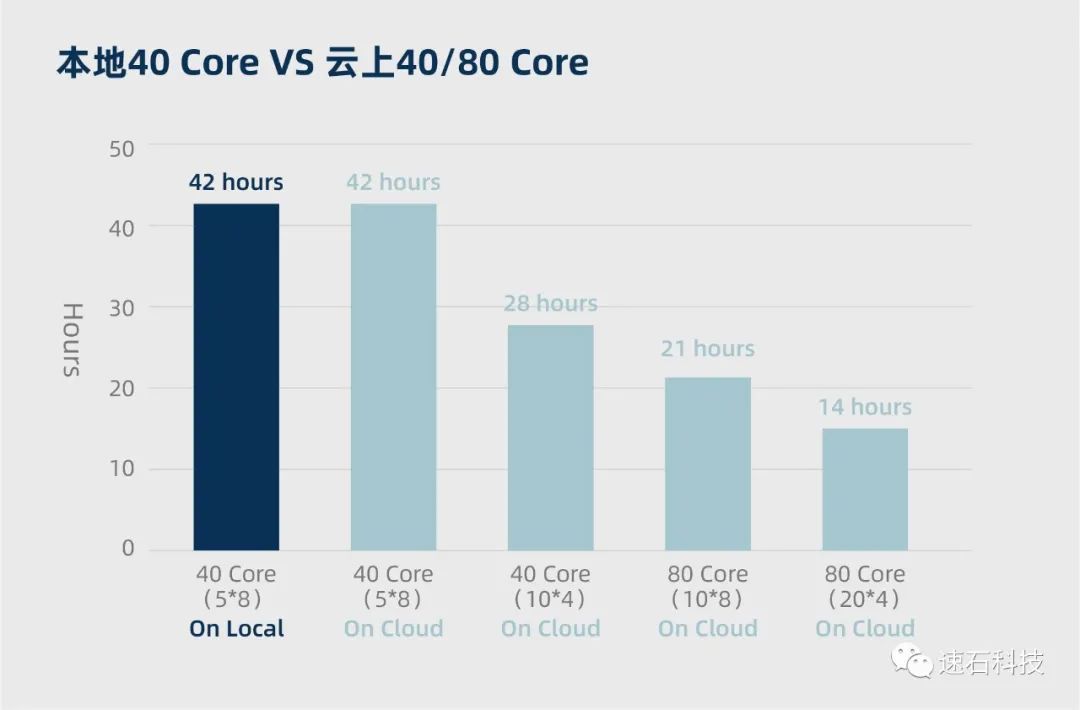
實證過程:
1、本地使用40核計算資源,拆分為5*8核,運行編號為1的HSPICE任務,耗時42小時;
2、云端調度40核計算資源,拆分為5*8核,運行編號為1的HSPICE任務,耗時42小時;
3、云端調度40核計算資源,拆分為10*4核,運行編號為1的HSPICE任務,耗時28小時;
4、云端調度80核計算資源,拆分為10*8核,運行編號為1的HSPICE任務,耗時21小時;
5、云端調度80核計算資源,拆分為20*4核,運行編號為1的HSPICE任務,耗時14小時。
實證場景二:大規模業務驗證
超大規模計算任務
結論:
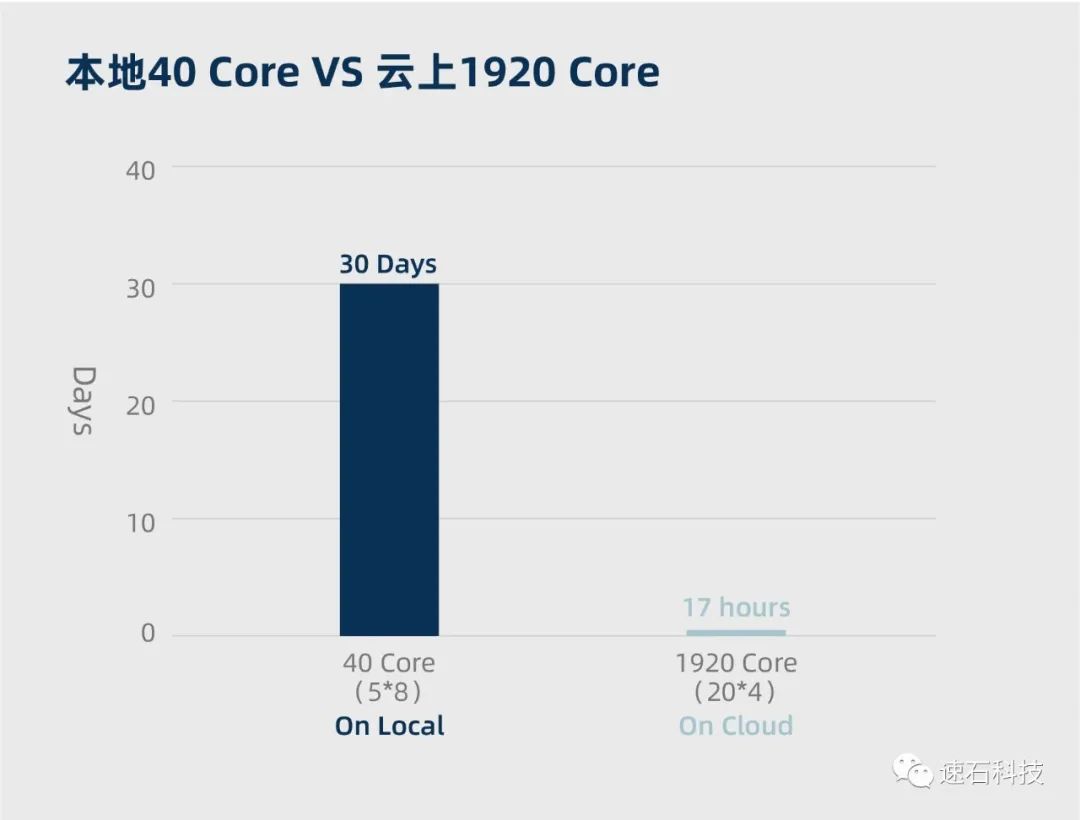
1、增加計算資源并優化任務拆分方式后,云端調度1920核計算資源,將一組超大規模計算任務(共計24個HSPICE任務)的計算周期從原有的30天縮短至17小時即可完成,云端最優計算周期與本地計算周期相比,效率提升42倍;
2、由fastone平臺自研的Auto-Scale功能,使平臺可根據HSPICE任務狀態在云端自動化構建計算集群,并根據實際需求自動伸縮,計算完成后自動銷毀,在提升效率的同時有效降低成本;
3、隨著計算周期的縮短,設備斷電、應用崩潰等風險也相應降低,作業中斷的風險也大大降低。在本實例中未發生作業中斷。
實證過程:
1、本地使用40核計算資源,拆分為5*8核,運行編號從0到23共計24個HSPICE任務,耗時約30天;
2、云端調度1920核計算資源,拆分為24組,每組為20*4核,運行編號從0到23共計24個HSPICE任務,耗時17個小時。
實證小結
我們回顧一下實證目標:
1、HSPICE任務在云端能高效運行;
2、異構的云端資源能更好適配HSPICE任務需求,避免資源浪費;
3、fastone平臺有效解決了算力不足問題,效率提升42倍;
4、相比手動模式,fastone平臺自研的Auto-Scale功能,既能有效提升部署效率,降低部署門檻,又能大大縮短整個計算周期資源占用率,節約成本。
至于本次實證場景沒用到的跨區域,跨機型使用,還有根據GPU的需求來實現自動伸縮,我們下次再聊。
本次半導體行業Cloud HPC實證系列Vol.1就到這里了。
審核編輯 :李倩
-
仿真
+關注
關注
50文章
4044瀏覽量
133423 -
hspice
+關注
關注
6文章
29瀏覽量
24257 -
自動化軟件
+關注
關注
0文章
20瀏覽量
6009
原文標題:從30天到17小時,如何讓HSPICE仿真效率提升42倍?
文章出處:【微信號:FPGA_Study,微信公眾號:FPGA自習室】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
永磁同步電機效率提升方法
如何提升EDA設計效率
如何提升RFID手持終端的讀寫效率
hspice共源放大電路仿真分析
請問如何將HSPICE和 IBIS兩種模型怎么轉換成TINA軟件中用?
請問RC4580的hspice模型如何導入ADS里使用?
騰訊推出自主研發的AI引擎,工作效率提升超40倍
龍芯:自主研發CPU提升性能,單核通用性能提高20倍
潞晨科技Colossal-AI + 浪潮信息AIStation,大模型開發效率提升10倍






 工商網監
工商網監
評論