 NVIDIA TensorRT支持矩陣中的流控制結構層部分
NVIDIA TensorRT支持矩陣中的流控制結構層部分
NVIDIA TensorRT 支持循環結構,這對于循環網絡很有用。 TensorRT 循環支持掃描輸入張量、張量的循環定義以及“掃描輸出”和“最后一個值”輸出。
10.1. Defining A Loop
循環由循環邊界層(loop boundary layers)定義。
ITripLimitLayer指定循環迭代的次數。
IIteratorLayer使循環能夠迭代張量。
IRecurrenceLayer指定一個循環定義。
ILoopOutputLayer指定循環的輸出。
每個邊界層都繼承自類ILoopBoundaryLayer ,該類有一個方法getLoop()用于獲取其關聯的ILoop 。 ILoop對象標識循環。具有相同ILoop的所有循環邊界層都屬于該循環。
下圖描繪了循環的結構和邊界處的數據流。循環不變張量可以直接在循環內部使用,例如 FooLayer 所示。
一個循環可以有多個IIteratorLayer 、 IRecurrenceLayer和ILoopOutputLayer ,并且最多可以有兩個ITripLimitLayer ,如后面所述。沒有ILoopOutputLayer的循環沒有輸出,并由 TensorRT 優化。
NVIDIA TensorRT 支持矩陣中的流控制結構層部分描述了可用于循環內部的 TensorRT 層。
內部層可以自由使用在循環內部或外部定義的張量。內部可以包含其他循環(請參閱嵌套循環)和其他條件構造(請參閱條件嵌套)。
要定義循環,首先,使用INetworkDefinition ::addLoop方法創建一個ILoop對象。然后添加邊界層和內部層。本節的其余部分描述了邊界層的特征,使用loop表示INetworkDefinition ::addLoop返回的ILoop* 。
ITripLimitLayer支持計數循環和 while 循環。
loop -》addTripLimit( t ,TripLimit::kCOUNT)創建一個ITripLimitLayer ,其輸入t是指定循環迭代次數的 0D INT32 張量。
loop -》addTripLimit( t ,TripLimit::kWHILE)創建一個ITripLimitLayer ,其輸入t是一個 0D Bool 張量,用于指定是否應該進行迭代。通常t要么是IRecurrenceLayer的輸出,要么是基于所述輸出的計算。
一個循環最多可以有一種限制。
IIteratorLayer支持在任何軸上向前或向后迭代。
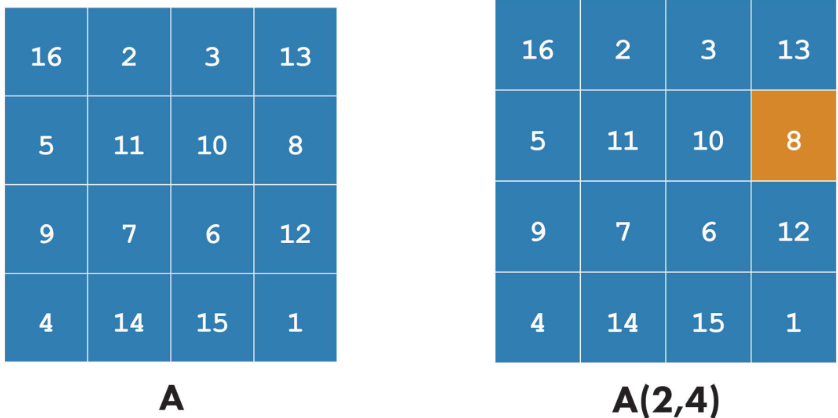
loop -》addIterator( t )添加一個IIteratorLayer ,它在張量t的軸 0 上進行迭代。例如,如果輸入是矩陣:
2 3 5
4 6 8
第一次迭代的一維張量{2, 3, 5}和第二次迭代的{4, 6, 8} 。超出張量范圍的迭代是無效的。
loop -》addIterator( t , axis )類似,但該層在給定的軸上迭代。例如,如果 axis=1 并且輸入是矩陣,則每次迭代都會傳遞矩陣的一列。
loop -》addIterator( t , axis,reverse )類似,但如果reverse =true ,則該層以相反的順序產生其輸出。
ILoopOutputLayer支持三種形式的循環輸出:
loop -》addLoopOutput( t, LoopOutput::kLAST_VALUE)輸出t的最后一個值,其中t必須是IRecurrenceLayer的輸出。
loop-》 addLoopOutput( t ,LoopOutput::kCONCATENATE, axis )將每次迭代的輸入串聯輸出到t 。例如,如果輸入是一維張量,第一次迭代的值為{ a,b,c} ,第二次迭代的值為{d,e,f} , axis =0 ,則輸出為矩陣:
a b c
d e f
如果axis =1 ,則輸出為:
a d
b e
c f
loop-》 addLoopOutput( t ,LoopOutput::kREVERSE, axis )類似,但顛倒了順序。 kCONCATENATE和kREVERSE形式都需要第二個輸入,這是一個 0D INT32 形狀張量,用于指定新輸出維度的長度。當長度大于迭代次數時,額外的元素包含任意值。第二個輸入,例如u ,應使用ILoopOutputLayer::setInput(1, u )設置。
最后,還有IRecurrenceLayer 。它的第一個輸入指定初始輸出值,第二個輸入指定下一個輸出值。第一個輸入必須來自循環外;第二個輸入通常來自循環內部。例如,這個 C++ 片段的 TensorRT 模擬:
for (int32_t i = j; 。..; i += k) 。..
可以通過這些調用創建,其中j和k是ITensor* 。
ILoop* loop = n.addLoop();
IRecurrenceLayer* iRec = loop-》addRecurrence(j);
ITensor* i = iRec-》getOutput(0);
ITensor* iNext = addElementWise(*i, *k,
ElementWiseOperation::kADD)-》getOutput(0);
iRec-》setInput(1, *iNext);
第二個輸入是TensorRT允許后沿的唯一情況。如果刪除了這些輸入,則剩余的網絡必須是非循環的。
10.2. Formal Semantics
TensorRT 具有應用語義,這意味著除了引擎輸入和輸出之外沒有可見的副作用。因為沒有副作用,命令式語言中關于循環的直覺并不總是有效。本節定義了 TensorRT 循環結構的形式語義。
形式語義基于張量的惰性序列(lazy sequences)。循環的每次迭代對應于序列中的一個元素。循環內張量X的序列表示為? X 0, X 1, X 2, 。.. ? 。序列的元素被懶惰地評估,意思是根據需要。
IIteratorLayer(X)的輸出是? X[0], X[1], X[2], 。.. ?其中X[i]表示在IIteratorLayer指定的軸上的下標。
IRecurrenceLayer(X,Y)的輸出是? X, Y0, Y1, Y2, 。.. ? 。 的輸入和輸出取決于LoopOutput的類型。
kLAST_VALUE :輸入是單個張量X ,對于 n-trip 循環,輸出是X n 。
kCONCATENATE :第一個輸入是張量X,第二個輸入是標量形狀張量Y。結果是X0, X1, X2, 。.. Xn-1與后填充(如有必要)連接到Y指定的長度。如果Y 《 n則為運行時錯誤。 Y是構建時間常數。注意與IIteratorLayer的反比關系。 IIteratorLayer將張量映射到一系列子張量;帶有kCONCATENATE的ILoopOutputLayer將一系列子張量映射到一個張量。
kREVERSE :類似于kCONCATENATE ,但輸出方向相反。
ILoopOutputLayer的輸出定義中的n值由循環的ITripLimitLayer確定:
對于計數循環,它是迭代計數,表示ITripLimitLayer的輸入。
對于 while 循環,它是最小的 n 使得$X_n$為假,其中X是ITripLimitLayer的輸入張量的序列。
非循環層的輸出是層功能的順序應用。例如,對于一個二輸入非循環層F(X,Y) = ? f(X 0 , Y 0 ), f(X 1 , Y 1 ), f(X 2 , Y 2 )。.. ? 。如果一個張量來自循環之外,即是循環不變的,那么它的序列是通過復制張量來創建的。
10.3. Nested Loops
TensorRT 從數據流中推斷出循環的嵌套。例如,如果循環 B 使用在循環 A 中定義的值,則 B 被認為嵌套在 A 中。
TensorRT 拒絕循環沒有干凈嵌套的網絡,例如如果循環 A 使用循環 B 內部定義的值,反之亦然。
10.4. Limitations
引用多個動態維度的循環可能會占用意外的內存量。 在一個循環中,內存的分配就像所有動態維度都取任何這些維度的最大值一樣。例如,如果一個循環引用兩個維度為[4,x,y]和[6,y]的張量,則這些張量的內存分配就像它們的維度是[4,max(x,y),max(x ,y)]和[6,max(x,y)] 。
帶有kLAST_VALUE的LoopOutputLayer的輸入必須是IRecurrenceLayer的輸出。 循環 API 僅支持 FP32 和 FP16 精度。
10.5. Replacing IRNNv2Layer With Loops
IRNNv2Layer在 TensorRT 7.2.1 中已棄用,并將在 TensorRT 9.0 中刪除。使用循環 API 合成循環子網絡。例如,請參閱sampleCharRNN方法SampleCharRNNLoop::addLSTMCell 。循環 API 讓您可以表達一般的循環網絡,而不是局限于IRNNLayer和IRNNv2Layer中的預制單元。
關于作者
Ken He 是 NVIDIA 企業級開發者社區經理 & 高級講師,擁有多年的 GPU 和人工智能開發經驗。自 2017 年加入 NVIDIA 開發者社區以來,完成過上百場培訓,幫助上萬個開發者了解人工智能和 GPU 編程開發。在計算機視覺,高性能計算領域完成過多個獨立項目。并且,在機器人和無人機領域,有過豐富的研發經驗。對于圖像識別,目標的檢測與跟蹤完成過多種解決方案。曾經參與 GPU 版氣象模式GRAPES,是其主要研發者。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
4940瀏覽量
102818 -
gpu
+關注
關注
28文章
4702瀏覽量
128709 -
人工智能
+關注
關注
1791文章
46872瀏覽量
237595
發布評論請先 登錄
相關推薦
OSI七層模型中各層的協議 OSI七層模型的優勢與不足
使用NVIDIA TensorRT提升Llama 3.2性能
TensorRT-LLM低精度推理優化

NVIDIA Nemotron-4 340B模型幫助開發者生成合成訓練數據

MATLAB中的矩陣索引
魔搭社區借助NVIDIA TensorRT-LLM提升LLM推理效率
NVIDIA 通過 Holoscan 為 NVIDIA IGX 提供企業軟件支持
NVIDIA加速微軟最新的Phi-3 Mini開源語言模型
利用NVIDIA組件提升GPU推理的吞吐
Torch TensorRT是一個優化PyTorch模型推理性能的工具

半導體芯片結構分析
NVIDIA DOCA 2.5 長期支持版本發布
矩陣式變換器的拓撲結構和工作原理 矩陣式變換器的控制策略和仿真分析
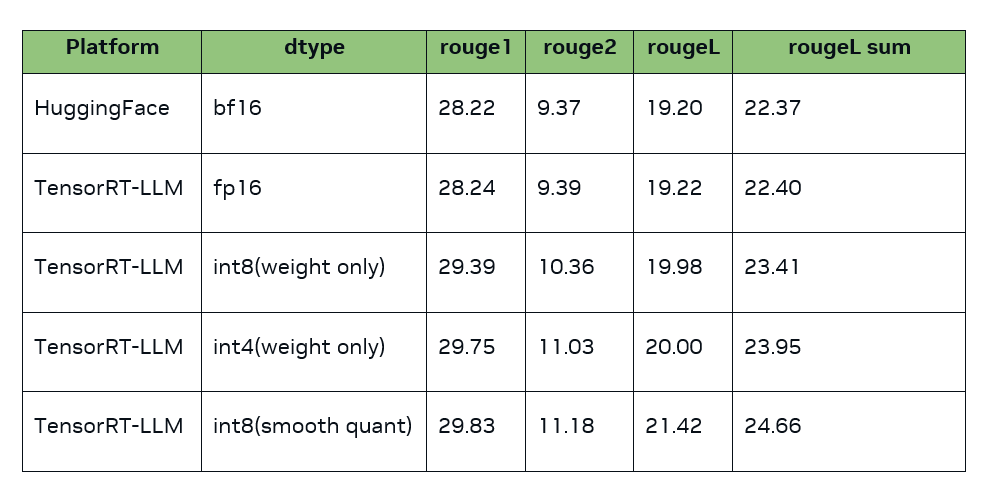
如何在 NVIDIA TensorRT-LLM 中支持 Qwen 模型





 工商網監
工商網監
評論