") Linux塊層架構介紹 塊層IO流程與塊層IO調度器詳解
Linux塊層架構介紹 塊層IO流程與塊層IO調度器詳解
塊存儲沒那么神秘!
之前一直跟大家聊文件系統(tǒng),文件系統(tǒng)提供一層文件到物理塊層的映射轉換。這層邏輯可能非常復雜,依賴于文件系統(tǒng)的實現。今天則跟大家聊聊塊層,塊層位于 fs 層之下,大家可能平時不怎么接觸,看不見摸不著。其實沒有那么神秘,來看下塊設備的使用姿勢, Linux 經常看見的 sda,sdb 這樣的盤符文件其實就是塊設備。
我們來試一下對一個塊設備進行讀寫(注意,千萬找一個不用的塊設備,有寫操作):
funcmain(){
//千萬注意:/dev/sdx1 盤,注意一定是要是不用的新盤哦。這里有寫操作,可千萬不要寫壞數據哦
f,err:=os.OpenFile("/dev/sdx1",os.O_RDWR,0666)
iferr!=nil{
log.Fatalf("err:%v
",err)
}
//寫
content:="helloworld"
_,err=f.WriteAt([]byte(content),0)
iferr!=nil{
log.Fatalf("err:%v
",err)
}
//讀
buffer:=make([]byte,len(content))
n,err:=f.ReadAt(buffer,0)
iferr!=nil{
log.Fatalf("err:%v
",err)
}
fmt.Printf("content=%s,n=%v
",buffer,n)
}
以上就完成了對塊設備的一次讀寫,大家看用戶態(tài)操作一下塊設備是不是非常簡單呀。說白了,就是把它當一個線性的文件來使用即可。用戶態(tài)的文件系統(tǒng)經常喜歡這樣去管理塊設備,來看一下塊層的架構。
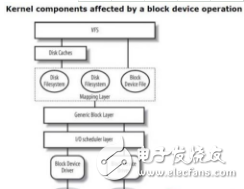
塊層架構
塊設備的邏輯集中在 Linux 的塊層子系統(tǒng)中。由于塊設備有多種的類型,并且內部關于不同的場景可能會有不同的調度需求,所以它的設計也必須滿足一定的抽象,塊層內一般分為三層:
- 通用層 :抽象不同的塊設備,為上層建立統(tǒng)一的塊設備模型;
- IO 調度層 :IO 請求入隊、出隊,并且按照特定的策略去調度(可配置);
- 塊設備驅動層 :針對不同的塊設備類型有著不同驅動程序。比如 SCSI 設備,邏輯設備等;
聊聊這三層:
- 通用層:給上層一個叫做 submit_bio 的函數,并且和上層對齊的 IO 類型叫做 bio ,所有的塊 IO 請求封裝成 bio ,然后通過 submit_bio 遞交即可。這是統(tǒng)一的抽象界面;
- IO 調度層:無非就是上層請求怎么入隊,然后怎么派發(fā)給底層。整體的塊 IO 調度器叫做電梯,它的架子也是電梯算法的架子,調度算法允許配置,常見的就是 cfq,deadline,noop 這三種算法;
- 塊設備驅動層:針對不同塊設備的封裝,比如有順序訪問的塊設備,還有隨機訪問的,還有邏輯棧式設備;
塊層 IO 流程
今天走一小段代碼,省略復雜邏輯,只擼主干邏輯。
1抽象界面 submit_bio下面涉及到代碼,配合 Linux 3.10.1
塊層的入口是 submit_bio 函數,上層填裝 bio 結構之后,調用 submit_bio 遞交到塊層。一切的開始都是從這個函數。bio 就是塊層和上層約定好的參數結構。塊層的核心工作就是對這個結構做處理,做變形,最終做轉發(fā)。
塊設備的讀寫都是通過這個接口和參數來表達。來看一下 submit_bio 的邏輯:
voidsubmit_bio(intrw,structbio*bio)
{
//打上讀寫標記
bio->bi_rw|=rw;
//...
//構造request
generic_make_request(bio);
}
一個小信息:FS 和 塊層交互的是 bio 類型,但是塊層內部用的是 request 結構,由 bio 轉換而來。
2IO 請求入隊 make_request_fn
來看下 generic_make_request 中 實現:
voidgeneric_make_request(structbio*bio)
{
//保證make_requst核心的邏輯在同一個進城內是串行之行的
if(current->bio_list){
bio_list_add(current->bio_list,bio);
return;
}
bio_list_init(&bio_list_on_stack);
current->bio_list=&bio_list_on_stack;
//循環(huán)處理bio_list里的內容
do{
//獲取到該塊設備的隊列
structrequest_queue*q=bdev_get_queue(bio->bi_dev);
//執(zhí)行make_request_fn回調
q->make_request_fn(q,bio);
bio=bio_list_pop(current->bio_list);
}while(bio);
current->bio_list=NULL;
}
塊設備都會有個 request_queue 結構體。隊列這個很容易理解,用來掛請求的。排序、合并之后 IO 請求總得放在一個地方。
上面的核心是 request queue 的 make_request_fn 函數回調。合并和排序就是在該函數中實現。
思考:make_request_fn 又是什么呢?什么時候賦值的呢?
其實是設備創(chuàng)建之初,初始化結構體的時候賦值好的。比如 SCSI 設備,那么 make_request_fn 就是 blk_queue_bio 。
注意:這里我們看到還有一個 request_fn 的回調,SCSI 設備是初始化成 scsi_request_fn ,記住這個,后面會講。
//分配并初始化一個scsi設備
scsi_alloc_sdev
scsi_alloc_queue
//創(chuàng)建、初始化請求隊列,回調request_fn
__scsi_alloc_queue(sdev->host,scsi_request_fn);
blk_init_queue
blk_init_queue_node
blk_init_allocated_queue
//回調make_request_fn
blk_queue_make_request(q,blk_queue_bio);
排序、合并的邏輯則是在 make_request_fn 中完成,也就是 IO 請求入隊的過程就完成了。
思考:合并、排序究竟是什么意思?
- 合并:將磁盤上扇區(qū)連續(xù)的多個請求合并成一個,然后作為一個 SCSI 請求命令下發(fā)
- 排序:將多個 IO 請求按照磁盤扇區(qū)的位置進行排序,以便磁頭能夠盡可能的往一個方向擺動
合并和排序在 make_request_fn 中完成。來看一看調度器的邏輯:
voidblk_queue_bio(structrequest_queue*q,structbio*bio)
{
el_ret=elv_merge(q,&req,bio);
if(el_ret==ELEVATOR_BACK_MERGE){
//往后合并
}elseif(el_ret==ELEVATOR_FRONT_MERGE){
//往前合并
}
get_rq:
//沒合并的新請求走這里
plug=current->plug
if(plug){
list_add_tail(&req->queuelist,&plug->list);
}else{
add_acct_request(q,req,where);
__blk_run_queue(q);
}
}
elv_merge 會返回一個常量來標識向前或者向后合并。如果是向前或者向后合并,那么返回對應的已經存在的 request 結構體。如果是不能合并,那么就創(chuàng)建的一個新的 request 請求。
思考:IO 請求在 make_request_fn 入隊,那什么時候派發(fā)呢?
是通過 request_fn 回調函數(往前看,設備初始化的時候賦值的)來處理。SCSI 設備的 request_fn 回調是 scsi_request_fn 函數。函數中有個 for 循環(huán),會按照策略逐個取出請求,封裝處理一下,然后丟到底層去執(zhí)行 ( 使用 scsi_dispatch_cmd )。
思考:有沒有想過能夠合并和排序的基礎條件是啥?
基礎是:有足夠多的請求。這個依賴于 Linux 的一個叫做蓄流/泄流的機制(Plugging / Unplugging)。蓄流/泄流什么意思?
Linux 塊層為了增加吞吐能力,對于來的請求,并不是立即下發(fā),而是 hold 一段時間,攢一會兒,超時了或者超閾值了,再一次性處理請求下發(fā)。類似于用塞子堵住一下(蓄流)池子,水滿了再拔掉塞子(泄流)。
很容易理解,塊層之所以不將每個請求都立馬下發(fā),就是為了實現 IO 的調度。這種短暫的 hold 請求本質上是優(yōu)化的基礎。如果每一個請求都不聚合,不把大家聚在一起,那么是無法找到優(yōu)化的時機的。
3IO 請求派發(fā) request_fn
request 的派發(fā)邏輯則是在 request_fn 中完成,SCSI 是 scsi_request_fn 函數。Unplug 的時候就會走到這里來。
staticvoidscsi_request_fn(structrequest_queue*q)
{
for(;;){
//按照IO調度策略取請求出來
req=blk_peek_request(q);
//派發(fā)命令到SCSI驅動層
rtn=scsi_dispatch_cmd(cmd);
}
}
這里的邏輯則是集中在 ”怎么取請求出來?“ 。
IO 調度算法的主要發(fā)揮時機就是在這里!(還有一個時機就是入隊的時候)
把 request 選出來之后,封裝成 scsi cmd 命令,通過 scsi_dispatch_cmd 函數下發(fā)到 SCSI 驅動層即可。這樣一個請求的派發(fā)就算完成了。
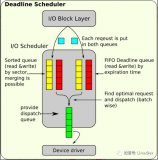
塊層 IO 調度器
接著上面,聊聊塊層 IO 調度器。首先塊層整體的 IO 調度器是一個電梯算法的架子,你會發(fā)現 elevator 的縮寫到處都是。隨著 Linux 系統(tǒng)的持續(xù)發(fā)展還是衍生了不同于真正簡單電梯算法的調度算法。這個就是我們常見的 noop,deadline,cfq 等算法。這部分則是被抽象成一個界面,可以讓用戶來配置選擇。這個統(tǒng)一界面類型叫做 elevator_type :
structelevator_type{
//最重要的是這個
structelevator_opsops;
}
最重要就是 ops 字段,以 noop 算法為例:
staticstructelevator_typeelevator_noop={
.ops={
.elevator_merge_req_fn=noop_merged_requests,
.elevator_dispatch_fn=noop_dispatch,
.elevator_add_req_fn=noop_add_request,
.elevator_former_req_fn=noop_former_request,
.elevator_latter_req_fn=noop_latter_request,
.elevator_init_fn=noop_init_queue,
.elevator_exit_fn=noop_exit_queue,
}
.elevator_name="noop",
.elevator_owner=THIS_MODULE,
}
也就是說,不同的調度算法只要實現了這個 elevator_type ,就可以在"電梯"的大框架里運行了。所以,其實“電梯”已經不是“電梯”了。
調度算法主要做好兩個事情:
- bio 請求入隊:合并、排序?隨你。比如 noop 就沒有合并和排序
- request 請求出隊:電梯不電梯?隨你,目前就看 deadline 是變形的“電梯”。
調度算法的實現在:
- noop 的實現在 block/noop-iosched.c ,及其簡單
- deadline 的實現在 block/deadline-iosched.c ,主要加了一個超時,饑餓的考慮
- cfq 的實現在 block/cfq-iosched.c ,號稱絕對公平算法,考慮到不同進程的性能公平,邏輯是最復雜的
今天先不給大家展開調度策略的實現,只簡要梳理其作用。說白了,無論哪種調度策略,都只是選出一個 request 出來而已。
思考:linux 怎么查看調度策略?
cat/sys/block/{塊設備符}/queue/scheduler
1noop
它自身不帶任何邏輯。沒有合并、排序。請求按照 fifo 的方式入隊出隊。誰先進的誰先出,不區(qū)分請求。
這種簡單的算法,反而適用于超高性能的介質,比如 ssd ,因為 ssd 的性能已經足夠高了,自身提供的并發(fā)能力也是夠的。不需要上層做順序化,批量化,它沒有磁頭擺動的問題。合并和排序等多余的邏輯對它來講就是累贅。
2deadline
最像電梯算法的 IO 調度算法。在電梯算法的基礎上,再加上請求超時的考慮,起到防止饑餓請求的作用。它內部有兩部電梯:讀寫。讀請求優(yōu)先,但也會考慮寫?zhàn)囸I,同一時間只有一部電梯在運行。
3cfq
完全公平隊列,為每個進程單獨創(chuàng)建一個隊列來管理該進程所產生的請求,試圖給不同的進程分配相同的塊設備使用時間片,以此來保證每個進程都能被很好的分配到 IO 帶寬。該算法就屬于萬金油,通用場景用它是最保險的,是最通用的 IO 調度算法。它的邏輯實現也是最復雜的。noop 100 行代碼,deadline 460 行,cfq 4600 行代碼,由此可見。
總結
- submit_bio 是塊層的統(tǒng)一接口函數,bio 是統(tǒng)一 IO 結構體
- request 是塊層內部的 IO 請求的結構體,bio 到 request 有一層轉換,這層轉換就是排序、合并的時候;
- make_request_fn 就是 bio 轉換成 request 的時機,IO 的排序、合并時機就在于此;
- request_fn 是 request 派發(fā)的時機,IO 的調度算法也在此發(fā)揮作用。從 request 隊列中按照策略選一個 req 出來,封裝成底層想要的樣子,下發(fā)下去
- IO 調度器合并、排序,包括按照電梯直上直下派發(fā)請求的目的是減少磁盤尋址時間,從而提高整體性能;
- noop,cfq,deadline 三種派發(fā)請求的算法都有適用自己的場景。noop 是幾乎 bypass 請求,沒有重拍、合并。deadline 是電梯算法衍生了一下。cfq 是全新的一種公平算法,跟電梯沒啥關系;
- 塊層最核心的邏輯是:bio 請求怎么入隊,request 請求怎么出隊而已,它遠比文件系統(tǒng)要簡單;
原文標題:Linux 塊層 IO 子系統(tǒng)|最核心的邏輯是什么?
文章出處:【微信公眾號:Linux愛好者】歡迎添加關注!文章轉載請注明出處。
-
Linux
+關注
關注
87文章
11123瀏覽量
207920 -
文件系統(tǒng)
+關注
關注
0文章
280瀏覽量
19831 -
調度器
+關注
關注
0文章
98瀏覽量
5210
原文標題:Linux 塊層 IO 子系統(tǒng)|最核心的邏輯是什么?
文章出處:【微信號:LinuxHub,微信公眾號:Linux愛好者】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
liunx下文件系統(tǒng),都會與塊設備層交互嗎?
EPA功能塊及用戶層技術研究
三層架構的原理及作用_三層架構怎么用
基于塊層的組成“bio層”的詳細解析
深度剖析基于塊層的組成“request層”
Linux通用塊層之deadline簡介及通用塊層調度器框架
Linux IO系統(tǒng)簡介和調度器的工作流程詳細概述
pcb板各層畫什么?絲印層 機械層 阻焊層 助焊層 信號層 鉆孔數據層作用詳解
邏輯層接口的IO口如何使用

CXL事務層詳解
查看linux系統(tǒng)磁盤io情況的辦法是什么
SCP基本構建塊介紹






 工商網監(jiān)
工商網監(jiān)
評論