 Linux內核虛擬內存管理中的mmu_gather操作
Linux內核虛擬內存管理中的mmu_gather操作
1開場白
環境:
本文講解Linux內核虛擬內存管理中的mmu_gather操作,看看它是如何保證刷tlb和釋放物理頁的順序的,又是如何將更多的頁面聚集起來統一釋放的。
通常在進程退出或者執行munmap的時候,內核會解除相關虛擬內存區域的頁表映射,刷/無效tlb,并釋放/回收相關的物理頁面,這一過程的正確順序如下:
1)解除頁表映射
2)刷相關tlb
3)釋放物理頁面
在刷相關虛擬內存區域tlb之前,絕對不能先釋放物理頁面,否則可能導致不正確的結果,而mmu-gather(mmu 積聚)的作用就是保證這種順序,并將需要釋放的相關的物理頁面聚集起來統一釋放。
2.源代碼解讀
2.1 重要數據結構體
首先我們先介紹一下,與mmu-gather相關的一些重要結構體,對于理解源碼很有幫助。
相關的主要數據結構有三個:
struct mmu_gather
struct mmu_table_batch
struct mmu_gather_batch
1)mmu_gather
來表示一次mmu積聚操作,在每次解除相關虛擬內存區域時使用。
structmmu_gather{
structmm_struct*mm;
#ifdefCONFIG_MMU_GATHER_TABLE_FREE
structmmu_table_batch*batch;
#endif
unsignedlongstart;
unsignedlongend;
/*
|*weareinthemiddleofanoperationtoclear
|*afullmmandcanmakesomeoptimizations
|*/
unsignedintfullmm:1;
/*
|*wehaveperformedanoperationwhich
|*requiresacompleteflushofthetlb
|*/
unsignedintneed_flush_all:1;
/*
|*wehaveremovedpagedirectories
|*/
unsignedintfreed_tables:1;
/*
|*atwhichlevelshaveweclearedentries?
|*/
unsignedintcleared_ptes:1;
unsignedintcleared_pmds:1;
unsignedintcleared_puds:1;
unsignedintcleared_p4ds:1;
/*
|*tracksVM_EXEC|VM_HUGETLBintlb_start_vma
|*/
unsignedintvma_exec:1;
unsignedintvma_huge:1;
unsignedintbatch_count;
#ifndefCONFIG_MMU_GATHER_NO_GATHER
structmmu_gather_batch*active;
structmmu_gather_batchlocal;
struct page *__pages[MMU_GATHER_BUNDLE];
...
#endif
};
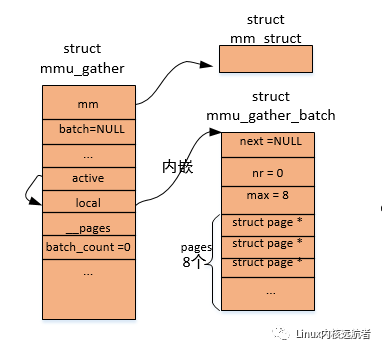
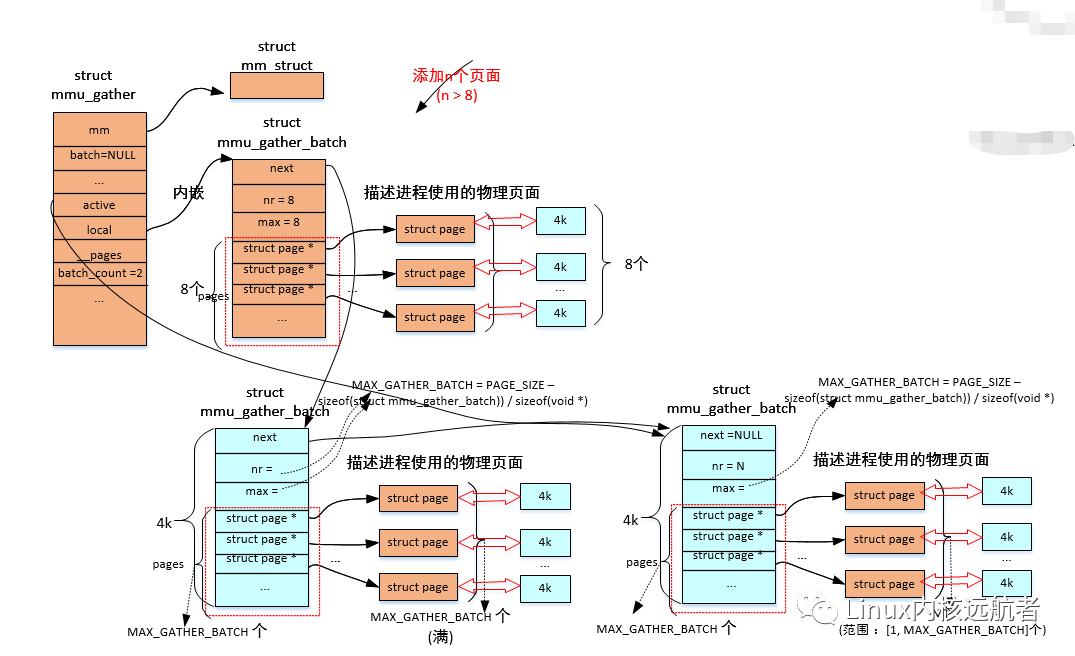
其中,mm 表示操作哪個進程的虛擬內存;batch 用于積聚進程各級頁目錄的物理頁;start和end 表示操作的起始和結束虛擬地址,這兩個地址在處理過程中會被相應的賦值;fullmm 表示是否操作整個用戶地址空間;freed_tables 表示我們已經釋放了相關的頁目錄;cleared_ptes/pmds/puds/p4ds 表示我們在哪個級別上清除了表項;vma_exec 表示操作的是否為可執行的vma;vma_huge 表示操作的是否為hugetlb的vma;batch_count 表示積聚了多少個“批次”,后面會講到 ;active、local和__pages 和多批次釋放物理頁面相關;active表示當前處理的批次,local表示“本地”批次,__pages表示“本地”批次積聚的物理頁面。
這里需要說明一點就是,mmu積聚操作會涉及到local批次和多批次操作,local批次操作的物理頁面相關的struct page數組內嵌到mmu_gather結構的__pages中,且我們發現這個數組大小為8,也就是local批次最大積聚8 * 4k = 32k的內存大小,這因為mmu_gather結構通常在內核棧中分配,不能占用太多的內核棧空間,而多批次由于動態分配批次積聚結構所以每個批次能積聚更多的頁面。
2)mmu_table_batch
用于積聚進程使用的各級頁目錄的物理頁,在釋放進程相關的頁目錄的物理頁時使用(文章中稱為頁表批次的積聚結構)。
structmmu_table_batch{
#ifdefCONFIG_MMU_GATHER_RCU_TABLE_FREE
structrcu_headrcu;
#endif
unsignedintnr;
void*tables[0];
};
rcu 用于rcu延遲釋放頁目錄的物理頁;
nr 表示頁目錄的物理頁的積聚結構的page數組中頁面個數;
tables 表示頁表積聚結構的page數組。
3)mmu_gather_batch
表示物理頁的積聚批次,用于積聚進程映射到用戶空間物理頁(文章中稱為批次的積聚結構)。
structmmu_gather_batch{
structmmu_gather_batch*next;
unsignedintnr;
unsignedintmax;
structpage*pages[0];
};
next 用于多批次積聚物理頁時,連接下一個積聚批次結構 ;
nr 表示本次批次的積聚數組的頁面個數;
max 表示本次批次的積聚數組最大的頁面個數;
pages 表示本次批次積聚結構的page數組。
2.2 總體調用
通常mmu-gather操作由一下幾部分函數組成:
tlb_gather_mmu
unmap_vmas
free_pgtables
tlb_finish_mmu
其中tlb_gather_mmu表示mmu-gather初始化,也就是struct mmu_gather的初始化;
unmap_vmas 表示解除相關虛擬內存區域的頁表映射;
free_pgtables 表示釋放頁表操作 ;
tlb_finish_mmu 表示進行刷tlb和釋放物理頁操作。
2.3 tlb_gather_mmu
這個函數主要是初始化從進程內核棧中傳遞過來的mmu_gather結構。
voidtlb_gather_mmu(structmmu_gather*tlb,structmm_struct*mm,
unsignedlongstart,unsignedlongend)
{
tlb->mm=mm;//賦值進程的內存描述符
/*Isitfrom0to~0?*/
tlb->fullmm=!(start|(end+1));//如果是操作進程整個地址空間,則start=0,end=-1,這個時候fullmm會被賦值1
#ifndefCONFIG_MMU_GATHER_NO_GATHER
tlb->need_flush_all=0;//初始化“本地”積聚相關成員
tlb->local.next=NULL;
tlb->local.nr=0;
tlb->local.max=ARRAY_SIZE(tlb->__pages);
tlb->active=&tlb->local;//active指向本地的積聚結構
tlb->batch_count=0;
#endif
tlb_table_init(tlb);//tlb->batch=NULL,來表示先不使用多批次積聚
#ifdefCONFIG_MMU_GATHER_PAGE_SIZE
tlb->page_size=0;
#endif
__tlb_reset_range(tlb);//tlb->start/end和lb->freed_tables、tlb->cleared_xxx初始化
inc_tlb_flush_pending(tlb->mm);
}
下面給出tlb_gather_mmu時的圖解:
2.4 unmap_vmas
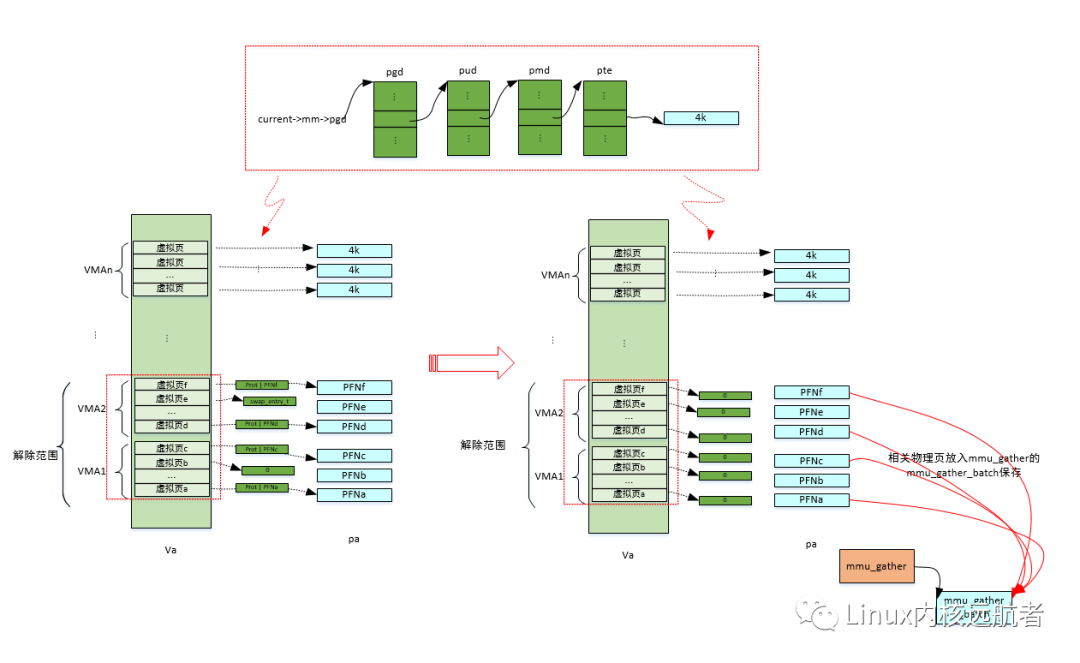
這個函數用于解除相關進程虛擬內存區域的頁表映射,還會將相關的物理頁面放入積聚結構中,后面統一釋放。
下面我們來看下這個函數:
voidunmap_vmas(structmmu_gather*tlb,
structvm_area_struct*vma,unsignedlongstart_addr,
unsignedlongend_addr)
{
...
for(;vma&&vma->vm_startvm_next)
unmap_single_vma(tlb,vma,start_addr,end_addr,NULL);
...
}
函數傳遞進已經初始化好的mmu積聚結構、操作的起始vma、以及虛擬內存范圍[start_addr, end_addr], 然后調用unmap_single_vma來操作這個范圍內的每一個vma。
unmap_single_vma的實現相關代碼比較多,在此不在贅述,我們會分析關鍵代碼,它主要做的工作為:通過遍歷進程的多級頁表,來找到vma中每一個虛擬頁對應的物理頁(存在的話),然后解除虛擬頁到物理頁的映射關系,最后將物理頁放入積聚結構中。
總體調用如下:
//mm/memory.c
unmap_vmas
->unmap_single_vma//處理單個vma
->unmap_page_range
->zap_p4d_range//遍歷pge頁目錄中每一個p4d表項
->zap_pud_range//遍歷p4d頁目錄中每一個pud表項
->zap_pmd_range//遍歷pud頁目錄中每一個pmd表項
->zap_pte_range//遍歷pmd頁目錄中每一個pmd表項
下面我們省略中間各級頁表的遍歷過程,重點看下最后一級頁表的處理(這段代碼相當關鍵):
zap_pte_range
->
staticunsignedlongzap_pte_range(structmmu_gather*tlb,
structvm_area_struct*vma,pmd_t*pmd,
unsignedlongaddr,unsignedlongend,
structzap_details*details)
{
...
again:
init_rss_vec(rss);
start_pte=pte_offset_map_lock(mm,pmd,addr,&ptl);//根據addr從pmd指向的頁表中獲得頁表項指針,并申請頁表的自旋鎖
pte=start_pte;
flush_tlb_batched_pending(mm);
arch_enter_lazy_mmu_mode();
do{
pte_tptent=*pte;//獲得頁表項
if(pte_none(ptent))//頁表項的內容為空表示沒有映射過,繼續下一個虛擬頁
continue;
...
if(pte_present(ptent)){//虛擬頁相關的物理頁在內存中(如沒有被換出到swap)
structpage*page;
page=vm_normal_page(vma,addr,ptent);//獲得虛擬頁相關的物理頁
...
ptent=ptep_get_and_clear_full(mm,addr,pte,
tlb->fullmm);//將頁表項清空(即是解除了映射關系),并返回原來的頁表項的內容
tlb_remove_tlb_entry(tlb,pte,addr);
if(unlikely(!page))
continue;
if(!PageAnon(page)){//如果是文件頁
if(pte_dirty(ptent)){//是臟頁
force_flush=1;//強制刷tlb
set_page_dirty(page);//臟標志傳遞到page結構
}
if(pte_young(ptent)&&
|likely(!(vma->vm_flags&VM_SEQ_READ)))//如果頁表項訪問標志置位,且是隨機訪問的vma,則標記頁面被訪問
mark_page_accessed(page);
}
rss[mm_counter(page)]--;//進程的相關rss做減1記賬
page_remove_rmap(page,false);//page->_mapcount--
if(unlikely(page_mapcount(page)if(unlikely(__tlb_remove_page(tlb,page))){//將物理頁記錄到積聚結構中,如果分配不到mmu_gather_batch結構或不支持返回true
force_flush=1;//強制刷tlb
addr+=PAGE_SIZE;//操作下一個虛擬頁
break;//退出循環
}
continue;//正常情況下,處理下一個虛擬頁
}
//下面處理虛擬頁相關的物理頁“不在”內存中的情況,可能是交換到swap或者是遷移類型等
entry=pte_to_swp_entry(ptent);//頁表項得到swp_entry
if(is_device_private_entry(entry)){//處理設備內存表項
structpage*page=device_private_entry_to_page(entry);
if(unlikely(details&&details->check_mapping)){
/*
|*unmap_shared_mapping_pages()wantsto
|*invalidatecachewithouttruncating:
|*unmapsharedbutkeepprivatepages.
|*/
if(details->check_mapping!=
|page_rmapping(page))
continue;
}
pte_clear_not_present_full(mm,addr,pte,tlb->fullmm);
rss[mm_counter(page)]--;
page_remove_rmap(page,false);
put_page(page);
continue;
}
....
if(!non_swap_entry(entry))//非遷移類型的swap_entry
rss[MM_SWAPENTS]--;//進程相關的交換條目的rss減1
elseif(is_migration_entry(entry)){//遷移類型的表項
structpage*page;
page=migration_entry_to_page(entry);//得到對應的物理頁
rss[mm_counter(page)]--;//進程相關的物理頁類型的rss減1
}
if(unlikely(!free_swap_and_cache(entry)))//釋放swap條目
print_bad_pte(vma,addr,ptent,NULL);
pte_clear_not_present_full(mm,addr,pte,tlb->fullmm);//清除虛擬頁相關的物理頁的頁表映射
}while(pte++,addr+=PAGE_SIZE,addr!=end);//遍歷pmd表項管轄范圍內的每一個虛擬頁
add_mm_rss_vec(mm,rss);//記錄到進程的相關rss結構中
arch_leave_lazy_mmu_mode();
/*DotheactualTLBflushbeforedroppingptl*/
if(force_flush)
tlb_flush_mmu_tlbonly(tlb);//如果是強制刷tlb,則刷tlb
pte_unmap_unlock(start_pte,ptl);//釋放進程的頁表自旋鎖
/*
|*IfweforcedaTLBflush(eitherduetorunningoutof
|*batchbuffersorbecauseweneededtoflushdirtyTLB
|*entriesbeforereleasingtheptl),freethebatched
|*memorytoo.Restartifwedidn'tdoeverything.
|*/
if(force_flush){//如果是強制刷tlb,則釋放掉本次聚集的物理頁
force_flush=0;
tlb_flush_mmu(tlb);//釋放本次聚集的物理頁
}
...
returnaddr;
}
以上函數,遍歷進程相關頁表(一個pmd表項指向一個頁表)所描述的范圍的每一個虛擬頁,如果之前已經建立過映射,就將相關的頁表項清除,對于在內存中物理頁來說,需要調用__tlb_remove_page將其加入到mmu的積聚結構中,下面重點看下這個函數:
__tlb_remove_page
->__tlb_remove_page_size//mm/mmu_gather.c
->
bool__tlb_remove_page_size(structmmu_gather*tlb,structpage*page,intpage_size)
{
structmmu_gather_batch*batch;
...
batch=tlb->active;//獲得當前批次的積聚結構
/*
|*Addthepageandcheckifwearefull.Ifso
|*forceaflush.
|*/
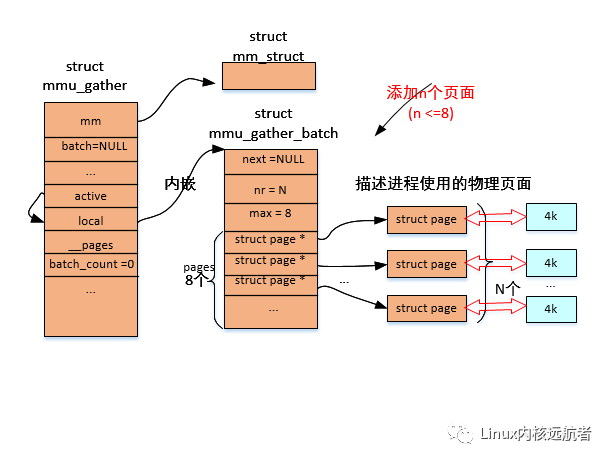
batch->pages[batch->nr++]=page;//將頁面加入到批次的積聚結構的pages數組中,并增加batch->nr計數
if(batch->nr==batch->max){//如果當前批次的積聚結構的pages數組中積聚的頁面個數到達最大個數
if(!tlb_next_batch(tlb))//獲得下一個批次積聚結構
returntrue;//獲得不成功返回true
batch=tlb->active;
}
VM_BUG_ON_PAGE(batch->nr>batch->max,page);
returnfalse;//獲得下一個批次批次積聚結構成功,返回false;
}
我們再來看下tlb_next_batch的實現:
staticbooltlb_next_batch(structmmu_gather*tlb)
{
structmmu_gather_batch*batch;
batch=tlb->active;
if(batch->next){//下一個批次積聚結構存在
tlb->active=batch->next;//當前的批次積聚結構指向這個批次結構
returntrue;
}
if(tlb->batch_count==MAX_GATHER_BATCH_COUNT)//如果批次數量達到最大值則返回false
returnfalse;
//批次還沒有到達最大值,則分配并初始化批次的積聚結構
batch=(void*)__get_free_pages(GFP_NOWAIT|__GFP_NOWARN,0);//申請一個物理頁面由于存放mmu_gather_batch和page數組
if(!batch)
returnfalse;
tlb->batch_count++;//批次計數加1
batch->next=NULL;
batch->nr=0;
batch->max=MAX_GATHER_BATCH;//批次積聚結構的page數組最大個數賦值為MAX_GATHER_BATCH
//插入到mmu積聚結構的批次鏈表中
tlb->active->next=batch;
tlb->active=batch;
returntrue;
}
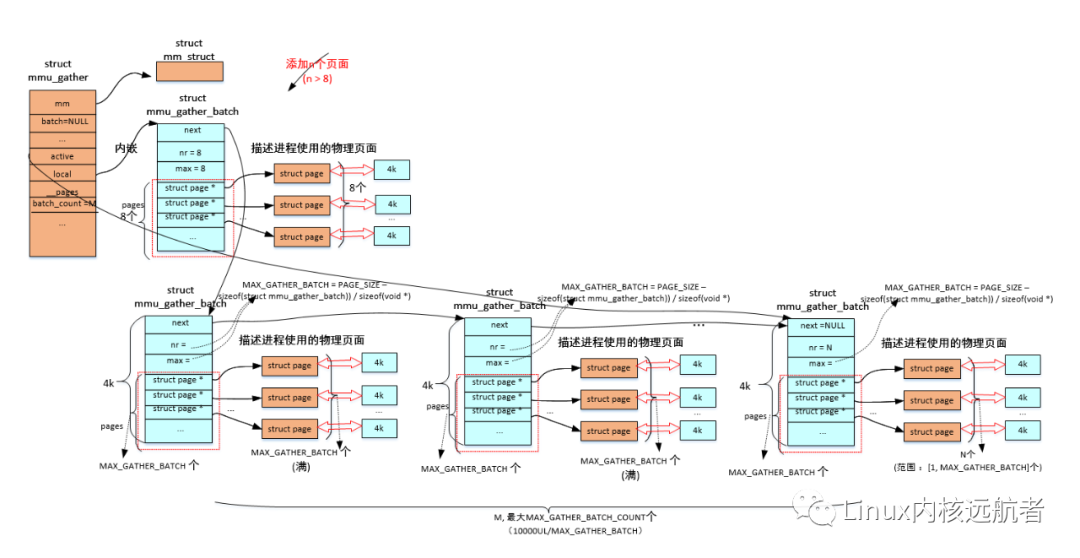
這里有幾個地方需要注意:MAX_GATHER_BATCH_COUNT 表示的是mmu積聚操作最多可以有多少個批次積聚結構,他的值為10000UL/MAX_GATHER_BATCH (考慮到非搶占式內核的soft lockups的影響)。MAX_GATHER_BATCH 表示一個批次的積聚結構的 page數組的最多元素個數,他的值為((PAGE_SIZE - sizeof(struct mmu_gather_batch)) / sizeof(void *)),也就是物理頁面大小去除掉struct mmu_gather_batch結構大小。
下面給出相關圖解:
解除頁表過程:
添加的到積聚結構page數組頁面小于等于8個的情況:
添加的到積聚結構page數組頁面大于8個的情況:
1個批次積聚結構->
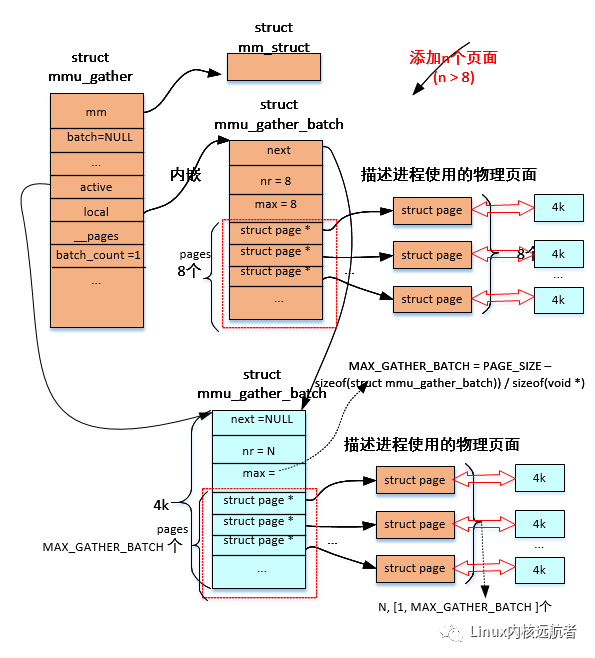
2個批次積聚結構->
更多批次積聚結構加入->
2.5 free_pgtables
unmap_vmas函數主要是積聚了一些相關的虛擬頁面對應的物理頁面,但是我們還需要釋放各級頁表對應的物理頁等。下面看下free_pgtables的實現:
首先看下它的主要脈絡:
//mm/memory.c
voidfree_pgtables(structmmu_gather*tlb,structvm_area_struct*vma,
unsignedlongfloor,unsignedlongceiling)
{
while(vma){//從起始的vma開始遍歷每個vma
structvm_area_struct*next=vma->vm_next;//獲得下一個vma
unsignedlongaddr=vma->vm_start;//獲得vma的起始地址
/*
|*Hidevmafromrmapandtruncate_pagecachebeforefreeing
|*pgtables
|*/
unlink_anon_vmas(vma);//解除匿名vma的反向映射關系
unlink_file_vma(vma);//解除文件vma反向映射關系
if(is_vm_hugetlb_page(vma)){
hugetlb_free_pgd_range(tlb,addr,vma->vm_end,
floor,next?next->vm_start:ceiling);
}else{
/*
|*Optimization:gathernearbyvmasintoonecalldown
|*/
while(next&&next->vm_start<=?vma->vm_end+PMD_SIZE
|&&!is_vm_hugetlb_page(next)){
vma=next;
next=vma->vm_next;
unlink_anon_vmas(vma);
unlink_file_vma(vma);
}
free_pgd_range(tlb,addr,vma->vm_end,
floor,next?next->vm_start:ceiling);//遍歷各級頁表
}
vma=next;
}
}
我們主要看free_pgd_range的實現:
free_pgd_range
->free_p4d_range
->free_pud_range
->free_pmd_range
->free_pte_range
->....
->pud_clear(pud);////清除pud頁目錄中的對應的pud表項
pmd_free_tlb(tlb,pmd,start);//pmd頁目錄的物理頁放入頁表的積聚結構中
mm_dec_nr_pmds(tlb->mm)//進程使用的頁表的物理頁統計減1
->p4d_clear(p4d);//清除p4d頁目錄中的對應的p4d表項
pud_free_tlb(tlb,pud,start)//pud頁目錄的物理頁放入頁表的積聚結構中
->pgd_clear(pgd);//清除pgd頁目錄中的對應的pgd表項
p4d_free_tlb(tlb,p4d,start);//p4d頁目錄的物理頁放入頁表的積聚結構中(存在p4d頁目錄的話)
我們以最后一級頁表(pmd表項指向)為例說明:
staticvoidfree_pte_range(structmmu_gather*tlb,pmd_t*pmd,
|unsignedlongaddr)
{
pgtable_ttoken=pmd_pgtable(*pmd);//從相關的pmd表項指針中獲得頁表
pmd_clear(pmd);//清除pmd頁目錄中的對應的pmd表項,即是頁表指針
pte_free_tlb(tlb,token,addr);//存放頁表的物理頁放入頁表的積聚結構中
mm_dec_nr_ptes(tlb->mm);//進程使用的頁表的物理頁統計減1
}
看下pte_free_tlb函數:
//include/asm-generic/tlb.h
#ifndefpte_free_tlb
#definepte_free_tlb(tlb,ptep,address)
do{
tlb_flush_pmd_range(tlb,address,PAGE_SIZE);//更新tlb->start和tlb->end,tlb->cleared_pmds=1
tlb->freed_tables=1;
__pte_free_tlb(tlb,ptep,address);//存放頁表的物理頁放入頁表的積聚結構中
}while(0)
#endif
再看看__pte_free_tlb:
//arch/arm64/include/asm/tlb.h
__pte_free_tlb
->pgtable_pte_page_dtor(pte);//執行釋放頁表的時候的構造函數,如釋放ptlock內存,zone的頁表頁面統計減1等
tlb_remove_table(tlb,pte);//mm/mmu_gather.c
->structmmu_table_batch**batch=&tlb->batch;//獲得頁表的積聚結構
if(*batch==NULL){//如何為空,則分配一個物理頁,存放積聚結構和積聚數組
*batch=(structmmu_table_batch*)__get_free_page(GFP_NOWAIT|__GFP_NOWARN);
if(*batch==NULL){
tlb_table_invalidate(tlb);
tlb_remove_table_one(table);
return;
}
(*batch)->nr=0;
}
(*batch)->tables[(*batch)->nr++]=table;//相關的頁目錄對應的物理頁放入積聚數組中
if((*batch)->nr==MAX_TABLE_BATCH)//加入的物理頁達到最大值
tlb_table_flush(tlb);//做一次刷tlb和釋放當前已經積聚的頁目錄的物理頁
需要說明的是:對于存放各級頁目錄的物理頁的釋放,每當一個頁表積聚結構填滿了就會釋放,不會構建批次鏈表。
2.6 tlb_finish_mmu
通過上面的unmap_vmas和free_pgtables之后,我們積聚了大量的物理頁以及存放各級頁目錄的物理頁,現在需要將這些頁面進行釋放。
下面我們來看下tlb_finish_mmu做的mmu-gather的收尾動作:
voidtlb_finish_mmu(structmmu_gather*tlb,
unsignedlongstart,unsignedlongend)
{
...
tlb_flush_mmu(tlb);//刷tlb和釋放所有積聚的物理頁
#ifndefCONFIG_MMU_GATHER_NO_GATHER
tlb_batch_list_free(tlb);//釋放各批次結構對應的物理頁
#endif
...
}
首先看下tlb_flush_mmu:
mm/mmu_gather.c
voidtlb_flush_mmu(structmmu_gather*tlb)
{
tlb_flush_mmu_tlbonly(tlb);//刷tlb
tlb_flush_mmu_free(tlb);//釋放各個批次積聚結構的物理頁
}
tlb_flush_mmu_tlbonly的實現:
staticinlinevoidtlb_flush_mmu_tlbonly(structmmu_gather*tlb)
{
/*
|*Anythingcalling__tlb_adjust_range()alsosetsatleastoneof
|*thesebits.
|*/
if(!(tlb->freed_tables||tlb->cleared_ptes||tlb->cleared_pmds||
|tlb->cleared_puds||tlb->cleared_p4ds))//有一個為0即返回
return;
tlb_flush(tlb);//刷tlb,和處理器架構相關
...
__tlb_reset_range(tlb);//將tlb->start和tlb->end以及tlb->freed_tables,tlb->cleared_xxx復位
}
我們來看下tlb_flush:
arch/arm64/include/asm/tlb.h
staticinlinevoidtlb_flush(structmmu_gather*tlb)
{
structvm_area_structvma=TLB_FLUSH_VMA(tlb->mm,0);
boollast_level=!tlb->freed_tables;
unsignedlongstride=tlb_get_unmap_size(tlb);
inttlb_level=tlb_get_level(tlb);//得到刷tlb的級別,如只刷pte級別
/*
|*Ifwe'retearingdowntheaddressspacethenweonlycareabout
|*invalidatingthewalk-cache,sincetheASIDallocatorwon't
|*reallocateourASIDwithoutinvalidatingtheentireTLB.
|*/
if(tlb->fullmm){//刷整個mm的tlb
if(!last_level)
flush_tlb_mm(tlb->mm);
return;
}
//刷一個虛擬內存范圍的tlb
__flush_tlb_range(&vma,tlb->start,tlb->end,stride,
|last_level,tlb_level);
}
最后我們看tlb_flush_mmu_free:
staticvoidtlb_flush_mmu_free(structmmu_gather*tlb)
{
tlb_table_flush(tlb);//釋放之前積聚的存放各級頁目錄的物理頁
#ifndefCONFIG_MMU_GATHER_NO_GATHER
tlb_batch_pages_flush(tlb);//釋放各個批次積聚結構積聚的物理頁
#endif
}
tlb_table_flush的實現:
staticvoidtlb_table_flush(structmmu_gather*tlb)
{
structmmu_table_batch**batch=&tlb->batch;//獲得當前的頁表批次積聚結構
if(*batch){
tlb_table_invalidate(tlb);//刷tlb
tlb_remove_table_free(*batch);//釋放頁目錄物理頁
*batch=NULL;
}
}
staticvoidtlb_remove_table_free(structmmu_table_batch*batch)
{
call_rcu(&batch->rcu,tlb_remove_table_rcu);//rsu延遲調用
->__tlb_remove_table_free(container_of(head,structmmu_table_batch,rcu));
->staticvoid__tlb_remove_table_free(structmmu_table_batch*batch)
{
inti;
for(i=0;inr;i++)//釋放頁表批次積聚結構中的page數組中每一個物理頁
__tlb_remove_table(batch->tables[i]);
free_page((unsignedlong)batch);//釋放這個表批次積聚結構對應的物理頁
}
}
tlb_batch_pages_flush的實現:
staticvoidtlb_batch_pages_flush(structmmu_gather*tlb)
{
structmmu_gather_batch*batch;
for(batch=&tlb->local;batch&&batch->nr;batch=batch->next){//遍歷積聚批次鏈表的每一個批次積聚結構
free_pages_and_swap_cache(batch->pages,batch->nr);//釋放積聚結構的page數組的每一個物理頁
batch->nr=0;
}
tlb->active=&tlb->local;
}
最終是:調用free_pages_and_swap_cache將物理頁的引用計數減1 ,引用計數為0時就將這個物理頁釋放,還給伙伴系統。
雖然上面已經釋放了相關的各級頁表的物理頁和映射到進程地址空間的物理頁,但是存放積聚結構和page數組的物理頁還沒有釋放,所以調用tlb_batch_list_free來做這個事情:
tlb_batch_list_free
->staticvoidtlb_batch_list_free(structmmu_gather*tlb)
{
structmmu_gather_batch*batch,*next;
for(batch=tlb->local.next;batch;batch=next){//釋放積聚結構的物理頁從tlb->local.next開始的,遍歷所有批次的積聚結構
next=batch->next;
free_pages((unsignedlong)batch,0);//釋放這個批次積聚結構的物理頁
}
tlb->local.next=NULL;
}
于是相關的所有物理頁面都被釋放了(包括相關地址范圍內進程各級頁目錄對應的物理頁,映射到進程地址空間的物理頁,和各個積聚結構所在的物理頁)。
最后給出整體的圖解:
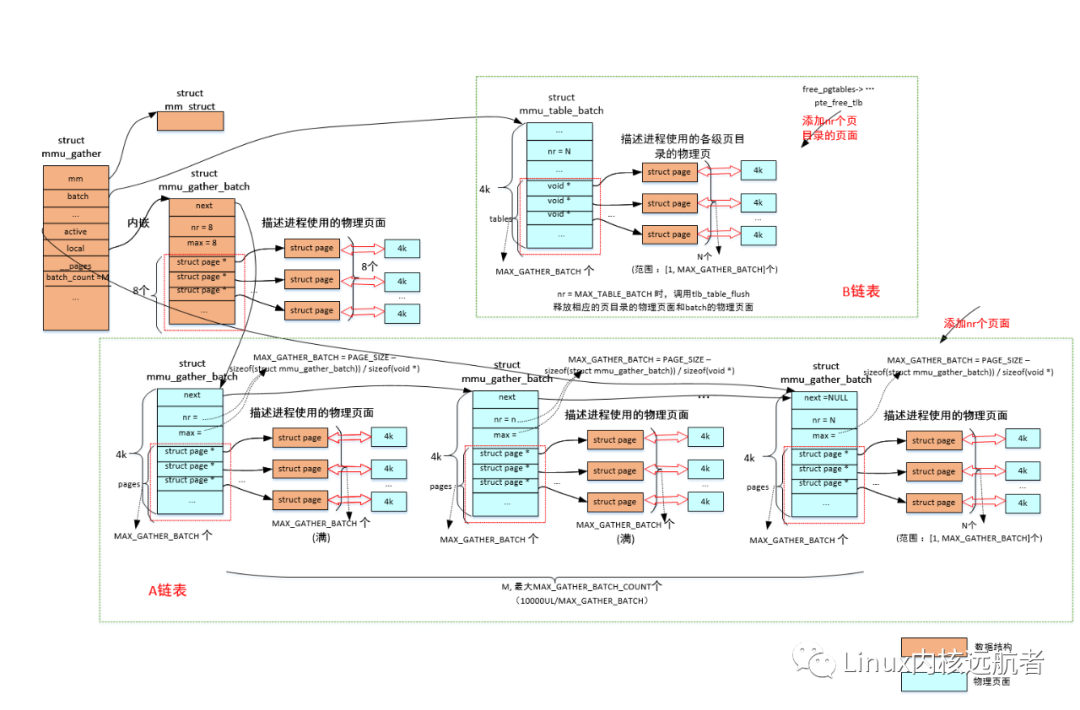
tlb_flush_mmu函數的tlb_table_flush會將B鏈表中的相關物理頁面釋放(包括之前保存的各級頁表的頁面和mmu_table_batch結構所在頁面),tlb_batch_pages_flush會將A鏈表的所有除了積聚結構以外的所有物理頁面釋放,而tlb_batch_list_free會將A鏈表的所有批次積聚結構(mmu_gather_batch)的物理頁面釋放。
3.應用場景
使用mmu-gather的應用場景主要是進程退出,執行execv和調用munmap等。
下面我們主要來看下他們的調用鏈:
3.1 進程退出時
進程退出時會釋放它的所有的相關聯的系統資源,其中就包括內存資源:
kernel/exit.c
do_exit
->exit_mm
->mmput//kernel/fork.c
->if(atomic_dec_and_test(&mm->mm_users))//如果mm->mm_users減1為0時,也就是當前進程是最后一個mm的使用者
__mmput(mm);//釋放mm
->exit_mmap//mm/mmap.c
->tlb_gather_mmu(&tlb,mm,0,-1);//初始化mmu_gather結構,start=0,end=-1表示釋放整個mm
->unmap_vmas(&tlb,vma,0,-1);//解除頁表映射,相關的物理頁放入積聚結構中
>free_pgtables(&tlb,vma,FIRST_USER_ADDRESS,USER_PGTABLES_CEILING);//釋放各級頁表,頁表相關物理頁放入頁表積聚結構,滿則釋放
>tlb_finish_mmu(&tlb,0,-1);//刷mm的tlb,釋放所有積聚物理頁,釋放所有積聚結構相關物理頁
3.2 執行execv時
執行execv時進程會將所有的mm釋放掉:
fs/exec.c
...
do_execveat_common
->bprm_execve
->exec_binprm
->search_binary_handler
...
->load_elf_binary//fs/binfmt_elf.c
->begin_new_exec
->exec_mmap
->mmput(old_mm)
->if(atomic_dec_and_test(&mm->mm_users))//如果mm->mm_users減1為0時,也就是當前進程是最后一個mm的使用者
__mmput(mm);//釋放mm
->exit_mmap//mm/mmap.c
->tlb_gather_mmu(&tlb,mm,0,-1);//初始化mmu_gather結構,start=0,end=-1標識釋放整個mm
->unmap_vmas(&tlb,vma,0,-1);//解除頁表映射,相關的物理頁放入積聚結構中
->free_pgtables(&tlb,vma,FIRST_USER_ADDRESS,USER_PGTABLES_CEILING);//釋放各級頁表,頁表相關物理頁放入頁表積聚結構,滿則釋放
->tlb_finish_mmu(&tlb,0,-1);//刷mm的tlb,釋放所有積聚物理頁,釋放所有積聚結構相關物理頁
3.3 調用munmap時
執行munmap時,會將一個地址范圍的頁表解除并釋放相關的物理頁面:
mm/mmap.c
...
__do_munmap
->unmap_region(mm,vma,prev,start,end);
->tlb_gather_mmu(&tlb,mm,start,end);//初始化mmu_gather結構
unmap_vmas(&tlb,vma,start,end);//解除頁表映射,相關的物理頁放入積聚結構中
free_pgtables(&tlb,vma,prev?prev->vm_end:FIRST_USER_ADDRESS,
|next?next->vm_start:USER_PGTABLES_CEILING);//釋放各級頁表,頁表相關物理頁放入頁表積聚結構,滿則釋放
tlb_finish_mmu(&tlb,start,end);//刷mm的tlb,釋放所有積聚物理頁,釋放所有積聚結構相關物理頁
4.總結
Linux內核mmu-gather用于積聚解除映射的相關物理頁面,并保證了刷tlb和釋放物理頁面的順序。首先解除掉相關虛擬頁面對應物理頁面(如果有的話)的頁表映射關系,然后將相關的物理頁面保存在積聚結構的數組中,接著將相關的各級頁目錄表項清除,并放入頁表相關的積聚結構的數組中,最后刷對應內存范圍的tlb,釋放掉所有放在積聚結構數組中的物理頁面。
原文標題:4.總結
文章出處:【微信公眾號:一口Linux】歡迎添加關注!文章轉載請注明出處。
-
內核
+關注
關注
3文章
1366瀏覽量
40236 -
Linux
+關注
關注
87文章
11232瀏覽量
208950 -
內存管理
+關注
關注
0文章
168瀏覽量
14128
原文標題:4.總結
文章出處:【微信號:yikoulinux,微信公眾號:一口Linux】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何優化RAM內存使用
Windows管理內存的三種主要方式
linux驅動程序如何加載進內核
Linux內核中的頁面分配機制

Linux內核內存管理之內核非連續物理內存分配
拆解mmap內存映射的本質!
Linux內核內存管理架構解析

Windows服務器虛擬內存的設置建議
獲取Linux內核源碼的方法






 工商網監
工商網監
評論