 DASK適用于Python中的并行和分布式計算
DASK適用于Python中的并行和分布式計算
Dask 是一個靈活的開源庫,適用于 Python 中的并行和分布式計算。
什么是 DASK ?
Dask 是一個開源庫,旨在為現有 Python 堆棧提供并行性。Dask 與 Python 庫(如 NumPy 數組、Pandas DataFrame 和 scikit-learn)集成,無需學習新的庫或語言,即可跨多個核心、處理器和計算機實現并行執行。
Dask 由兩部分組成:
用于并行列表、數組和 DataFrame 的 API 集合,可原生擴展 Numpy 、NumPy 、Pandas 和 scikit-learn ,以在大于內存環境或分布式環境中運行。Dask 集合是底層庫的并行集合(例如,Dask 數組由 Numpy 數組組成)并運行在任務調度程序之上。
一個任務調度程序,用于構建任務圖形,協調、調度和監控針對跨 CPU 核心和計算機的交互式工作負載優化的任務。
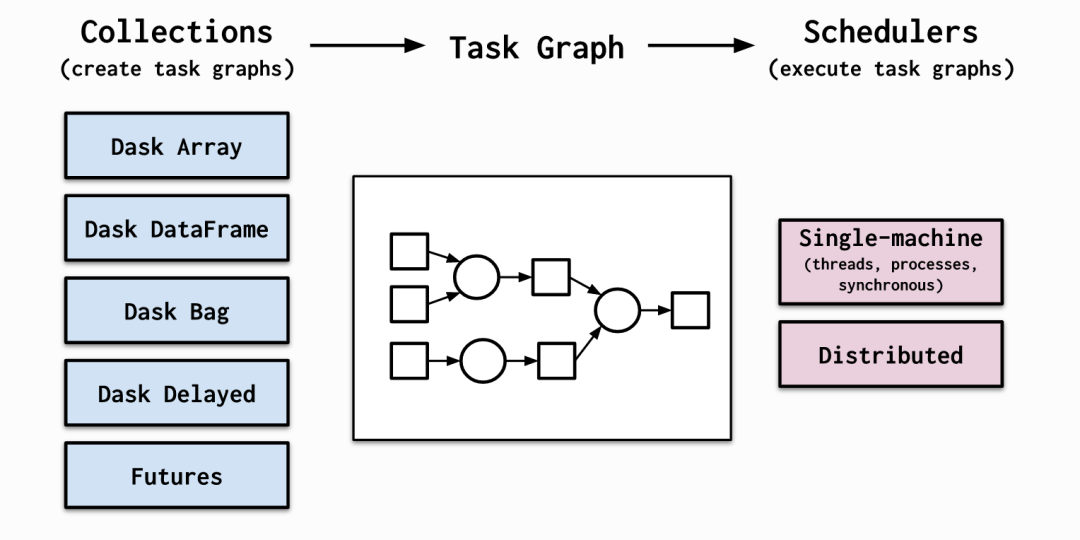
Dask 包含三個并行集合,即 DataFrame 、Bag 和數組,每個均可自動使用在 RAM 和磁盤之間分區的數據,以及根據資源可用性分布在集群中多個節點之間的數據。對于可并行但不適合 Dask 數組或 DataFrame 等高級抽象的問題,有一個“延遲”函數使用 Python 裝飾器修改函數,以便它們延遲運行。這意味著執行被延遲,并且函數及其參數被放置到任務圖形中。
Dask 的任務調度程序可以擴展至擁有數千個節點的集群,其算法已在一些全球最大的超級計算機上進行測試。其任務調度界面可針對特定作業進行定制。Dask 可提供低用度、低延遲和極簡的序列化,從而加快速度。
在分布式場景中,一個調度程序負責協調許多工作人員,將計算移動到正確的工作人員,以保持連續、無阻塞的對話。多個用戶可能共享同一系統。此方法適用于 Hadoop HDFS 文件系統以及云對象存儲(例如 Amazon 的 S3 存儲)。
該單機調度程序針對大于內存的使用量進行了優化,并跨多個線程和處理器劃分任務。它采用低用度方法,每個任務大約占用 50 微秒。
為何選擇 DASK?
Python 的用戶友好型高級編程語言和 Python 庫(如 NumPy 、Pandas 和 scikit-learn)已經得到數據科學家的廣泛采用。
這些庫是在大數據用例變得如此普遍之前開發的,沒有強大的并行解決方案。Python 是單核計算的首選,但用戶不得不為多核心或多計算機并行尋找其他解決方案。這會中斷用戶體驗,還會讓用戶感到非常沮喪。
過去五年里,對 Python 工作負載擴展的需求不斷增加,這導致了 Dask 的自然增長。Dask 是一種易于安裝、快速配置的方法,可以加速 Python 中的數據分析,無需開發者升級其硬件基礎設施或切換到其他編程語言。啟動 Dask 作業所使用的語法與其他 Python 操作相同,因此可將其集成,幾乎不需要重新寫代碼。
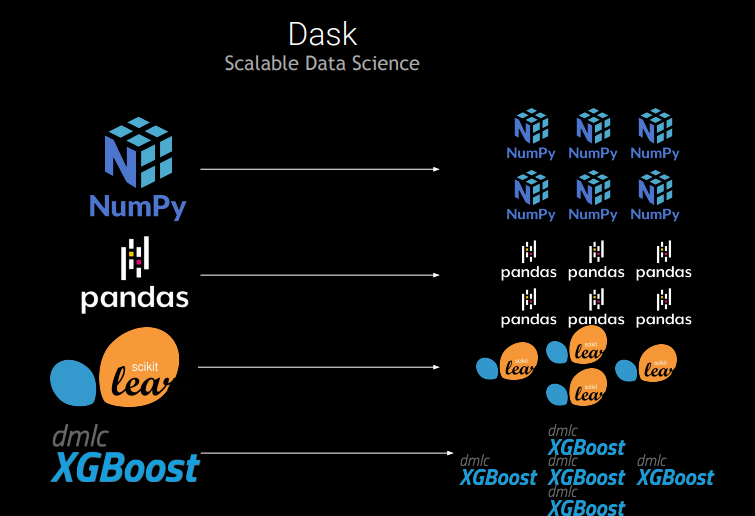
此外,由于擁有強大的網絡建設堆棧,Python 受到網絡開發者的青睞,Dask 可利用該堆棧構建一個靈活、功能強大的分布式計算系統,能夠擴展各種工作負載。Dask 的靈活性使其能夠從其他大數據解決方案(如 Hadoop 或 Apache Spark)中脫穎而出,而且它對本機代碼的支持使得 Python 用戶和 C/C++/CUDA 開發者能夠輕松使用。
Dask 已被 Python 開發者社區迅速采用,并且隨著 Numpy 和 Pandas 的普及而增長,這為 Python 提供了重要的擴展,可以解決特殊分析和數學計算問題。
Dask 的擴展性遠優于 Pandas,尤其適用于易于并行的任務,例如跨越數千個電子表格對數據進行排序。加速器可以將數百個 Pandas DataFrame 加載到內存中,并通過單個抽象進行協調。
如今, Dask 由一個開發者社區管理,該社區涵蓋數十家機構和 PyData 項目,例如 Pandas 、Jupyter 和 Scikit-Learn 。Dask 與這些熱門工具的集成促使采用率迅速提高,在需要 Pythonic 大數據工具的開發者中采用率約達 20%。
為何 DASK 在應用 GPU 后表現更出色
在架構方面,CPU 僅由幾個具有大緩存內存的核心組成,一次只可以處理幾個軟件線程。相比之下,GPU 由數百個核心組成,可以同時處理數千個線程。
GPU 可提供曾經深奧難測的并行計算技術。
| Dask + NVIDIA:推動可訪問的加速分析
NVIDIA 了解 GPU 為數據分析提供的強大性能。因此,NVIDIA 致力于幫助數據科學、機器學習和人工智能從業者從數據中獲得更大價值。鑒于 Dask 的性能和可訪問性,NVIDIA 開始將其用于 RAPIDS 項目,目標是將加速數據分析工作負載橫向擴展到多個 GPU 和基于 GPU 的系統。
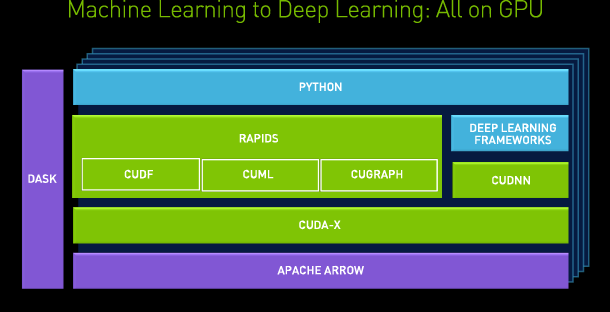
得益于可訪問的 Python 界面和超越數據科學的通用性,Dask 發展到整個 NVIDIA 的其他項目,成為從解析 JSON 到管理端到端深度學習工作流程等新應用程序的不二選擇。以下是 NVIDIA 使用 Dask 正在進行的許多項目和協作中的幾個:
| RAPIDS
RAPIDS 是一套開源軟件庫和 API,用于完全在 GPU 上執行數據科學流程,通常可以將訓練時間從幾天縮短至幾分鐘。RAPIDS 基于 NVIDIA CUDA-X AI 構建,并結合了圖形、機器學習、高性能計算 (HPC)等方面的多年開發經驗。
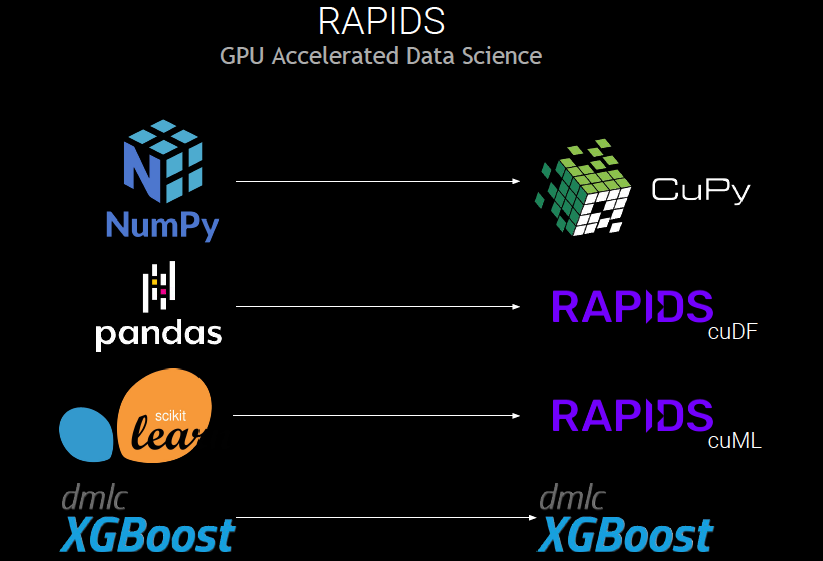
雖然 CUDA-X 功能強大,但大多數數據分析從業者更喜歡使用 Python 工具集(例如前面提到的 NumPy、Pandas 和 Scikit-learn)來試驗、構建和訓練模型。Dask 是 RAPIDS 生態系統的關鍵組件,使數據從業者能夠更輕松地通過基于 Python 的舒適用戶體驗利用加速計算。
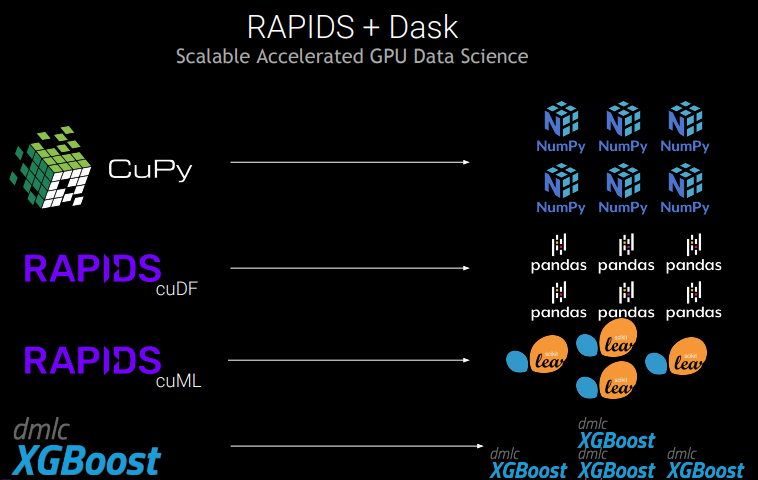
| NVTabular
NVTabular 是一個特征工程和預處理庫,旨在快速輕松地處理 TB 級表格數據集。它基于 Dask-cuDF 庫構建,可提供高級抽象層,從而簡化大規模高性能 ETL 運算的創建。NVTabular 能夠利用 RAPIDS 和 Dask 擴展至數千個 GPU ,消除等待 ETL 進程完成這一瓶頸。
| BlazingSQL
BlazingSQL 是一個在 GPU 上運行的速度超快的分布式 SQL 引擎,也是基于 Dask-cuDF 構建的。它使數據科學家能夠輕松將大規模數據湖與 GPU 加速的分析連接在一起。借助幾行代碼,從業者可以直接查詢原始文件格式(例如 HDFS 和 AWS S3 等數據湖中的 CSV 和 Apache Parquet),并直接將結果傳輸至 GPU 顯存。
BlazingSQL 背后的公司 BlazingDB Inc 是 RAPIDS 的核心貢獻者,并與 NVIDIA 進行了大量合作。
| cuStreamz
在 NVIDIA 內部,我們正在使用 Dask 為我們的部分產品和業務運營提供動力。我們使用 Streamz、Dask 和 RAPIDS 構建了 cuStreamz ,這是一個 100% 使用原生 Python 的加速流數據平臺。借助 cuStreamz,我們能夠針對某些要求嚴苛的應用程序(例如 GeForce NOW、NVIDIA GPU Cloud 和 NVIDIA Drive SIM)進行實時分析。雖然這是一個新興項目,但與使用支持 Dask 的 cuStreamz 的其他流數據平臺相比,TCO 已顯著降低。
DASK 用例
Dask 能夠高效處理數百 TB 的數據,因此成為將并行性添加到 ML 處理、實現大型多維數據集分析的更快執行以及加速和擴展數據科學制作流程或工作流程的強大工具。因此,它可以用于 HPC 、金融服務、網絡安全和零售行業的各種用例。例如,Dask 與 Numpy 工作流程一起使用,在地球科學、衛星圖像、基因組學、生物醫學應用程序和機器學習算法中實現多維數據分析。
借助 Pandas DataFrame ,Dask 可以在時間序列分析、商業智能和數據準備方面啟用應用程序。Dask-ML 是一個用于分布式和并行機器學習的庫,可與 Scikit-Learn 和 XGBoost 一起使用,以針對大型模型和數據集創建可擴展的訓練和預測。開發者可以使用標準的 Dask 工作流程準備和設置數據,然后將數據交給 XGBoost 或 Tensorflow 。
DASK + RAPIDS:在企業中實現創新
許多公司正在同時采用 Dask 和 RAPIDS 來擴展某些重要的業務。NVIDIA 的一些大型合作伙伴都是各自行業的領導者,他們正在使用 Dask 和 RAPIDS 來為數據分析提供支持。以下是最近一些令人興奮的例子:
| Capital One
Capital One 的使命是“變革銀行業務”,投入巨資進行大規模數據分析,為客戶提供更好的產品和服務,并提高整個企業的運營效率。憑借一大群對 Python 情有獨鐘的數據科學家,Capital One 使用 Dask 和 RAPIDS 來擴展和加速傳統上難以并行化的 Python 工作負載,并顯著減少大數據分析的學習曲線。
NERSC 致力于為基礎科學研究提供計算資源和專業知識,是通過計算加速科學發現的世界領導者。該使命的一部分是讓研究人員能夠使用超級計算來推動科學探索。借助 Dask 和 RAPIDS ,超級計算背景有限的研究人員和科學家可以輕松訪問其新的超級計算機“Perlmutter”的驚人功能。他們利用 Dask 創建一個熟悉的界面,讓科學家掌握超級計算能力,推動各領域取得潛在突破。
| 沃爾瑪實驗室
作為零售領域巨頭,沃爾瑪利用海量數據集更好地服務客戶、預測產品需求并提高內部效率。借助大規模數據分析來實現這些目標,沃爾瑪實驗室轉而使用 Dask 、XGBoost 和 RAPIDS,將訓練時間縮短 100 倍,實現快速模型迭代和準確性提升,從而進一步發展業務。借助 Dask ,數據科學家可以利用 NVIDIA GPU 的能力解決他們最棘手的問題。
DASK 在企業中的應用:日益壯大的市場
隨著其在大型機構中不斷取得成功,越來越多的公司開始滿足企業對 Dask 產品和服務的需求。以下是一些正在滿足企業 Dask 需求的公司,它們表明市場已進入成熟期:
| Anaconda
像 SciPy 生態系統的大部分內容一樣,Dask 從 Anaconda Inc 開始,在那里受到關注并發展為更大的開源社區。隨著社區的發展和企業開始采用 Dask ,Anaconda 開始提供咨詢服務、培訓和開源支持,以簡化企業的使用。作為開源軟件的主要支持者,Anaconda 還聘請了許多 Dask 維護人員,為企業客戶提供對該軟件的深入理解。
| Coiled
由 Dask 維護人員(例如 Dask 項目主管和前 NVIDIA 員工 Matthew Rocklin)創立的 Coiled 提供圍繞 Dask 的托管解決方案,以在云和企業環境中輕松運行,還提供幫助優化機構內 Python 分析的企業支持。他們公開托管的托管部署產品為同時使用 Dask 和 RAPIDS 提供了一種強大而直觀的方式。
| Quansight
Quansight 致力于幫助企業從數據中創造價值,提供各種服務,推動各行各業的數據分析。與 Anaconda 類似,Quansight 為使用 Dask 的企業提供咨詢服務和培訓。借助 PyData 和 NumFOCUS 生態系統,Quansight 還為需要在開源軟件中增強功能或修復問題的企業提供支持。
為何 DASK 對數據科學團隊很重要
這一切都與加速和效率有關。開發交互式算法的開發者希望快速執行,以便對輸入和變量進行修補。在運行大型數據集時,內存有限的臺式機和筆記本電腦可能會讓人感到沮喪。Dask 功能開箱即用,即使在單個 CPU 上也可以提高處理效率。當應用于集群時,通常可以通過單一命令在多個 CPU 和 GPU 之間執行運算,將處理時間縮短 90% 。Dask 可以啟用非常龐大的訓練數據集,這些數據集通常用于機器學習,可在無法支持這些數據集的環境中運行。
Dask 擁有低代碼結構、低用度執行模型,并且可輕松集成到 Python、Pandas 和 Numpy 工作流程中,因此 Dask 正迅速成為每個 Python 開發者的必備工具。
原文標題:NVIDIA 大講堂 | 什么是 DASK ?
文章出處:【微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
審核編輯:湯梓紅
-
NVIDIA
+關注
關注
14文章
4949瀏覽量
102826 -
python
+關注
關注
56文章
4783瀏覽量
84473 -
分布式計算
+關注
關注
0文章
28瀏覽量
4458
原文標題:NVIDIA 大講堂 | 什么是 DASK ?
文章出處:【微信號:NVIDIA_China,微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
適用于筆記本計算應用中Raptor Lake處理器的非隔離式直流/直流設計

適用于筆記本計算應用中Alder Lake的非隔離式直流/直流解決方案
適用于筆記本計算應用中Alder Lake處理器的非隔離式直流/直流解決方案
基于分布式計算的AR光波導中測試圖像的仿真
遠程IO與分布式IO的區別
OpenHarmony開發案例:【分布式計算器】
NVIDIA cuPQC幫助開發適用于量子計算時代的加密技術
分布式存儲與計算:大數據時代的解決方案
分布式無紙化交互系統的應用場景:企業、教育、政府
什么是分布式架構?





 工商網監
工商網監
評論