") 由合成數(shù)據(jù)支持的可解釋人工智能
由合成數(shù)據(jù)支持的可解釋人工智能
數(shù)據(jù)是模型可解釋性的核心。可解釋人工智能( XAI )是一個(gè)快速發(fā)展的領(lǐng)域,旨在深入了解人工智能算法的復(fù)雜決策過程。
在人工智能對(duì)個(gè)人生活有重大影響的領(lǐng)域,如信用風(fēng)險(xiǎn)評(píng)分,管理者和消費(fèi)者都有權(quán)要求深入了解這些決策。領(lǐng)先的金融機(jī)構(gòu)已經(jīng)在利用 XAI 驗(yàn)證其模型。同樣,監(jiān)管機(jī)構(gòu)也要求深入了解金融機(jī)構(gòu)的算法環(huán)境。但在實(shí)踐中如何做到這一點(diǎn)呢?
潘多拉的封閉盒子
人工智能越先進(jìn),對(duì)可解釋性來(lái)說(shuō),數(shù)據(jù)就越重要。
現(xiàn)代的 ML 算法有集成方法和深度學(xué)習(xí),即使沒有數(shù)百萬(wàn)個(gè)模型參數(shù),也會(huì)產(chǎn)生數(shù)千個(gè)。當(dāng)應(yīng)用于實(shí)際數(shù)據(jù)時(shí),如果不看到它們的實(shí)際作用,就不可能掌握它們。
甚至在培訓(xùn)數(shù)據(jù)敏感的情況下,廣泛訪問數(shù)據(jù)的必要性也是顯而易見的。用于信用評(píng)分和保險(xiǎn)定價(jià)的金融和醫(yī)療數(shù)據(jù)是人工智能中使用最頻繁、但也是最敏感的數(shù)據(jù)類型。
這是一個(gè)相互矛盾的難題:你想要數(shù)據(jù)得到保護(hù),你想要一個(gè)透明的決策。
可解釋的 AI 需要數(shù)據(jù)
那么,這些算法如何變得透明呢?你如何判斷機(jī)器做出的模型決策?考慮到它們的復(fù)雜性,披露數(shù)學(xué)模型、實(shí)現(xiàn)或完整的訓(xùn)練數(shù)據(jù)并不能達(dá)到目的。
相反,您必須通過觀察各種實(shí)際案例中的決策來(lái)探索系統(tǒng)的行為,并探索其對(duì)修改的敏感性。這些基于示例的假設(shè)探索有助于我們理解是什么驅(qū)動(dòng)了模型的決策。
這種簡(jiǎn)單而強(qiáng)大的概念,即在給定輸入數(shù)據(jù)變化的情況下,系統(tǒng)地探索模型輸出的變化,也稱為 local interpretability ,可以在域和 model-agnostic 按比例 中執(zhí)行。因此,同樣的原則可以應(yīng)用于幫助解釋信用評(píng)分系統(tǒng)、銷售需求預(yù)測(cè)、欺詐檢測(cè)系統(tǒng)、文本分類器、推薦系統(tǒng)等。
然而,像 SHAP 這樣的局部可解釋性方法不僅需要訪問模型,還需要訪問大量具有代表性和相關(guān)的數(shù)據(jù)樣本。
圖 1 顯示了一個(gè)在模型上進(jìn)行的基本演示,該演示預(yù)測(cè)了客戶對(duì)金融行業(yè)內(nèi)營(yíng)銷活動(dòng)的反應(yīng)。查看相應(yīng)的 Python 調(diào)用可以發(fā)現(xiàn)需要經(jīng)過訓(xùn)練的模型,以及執(zhí)行這些類型分析的代表性數(shù)據(jù)集。然而,如果該數(shù)據(jù)實(shí)際上是敏感的,并且無(wú)法被 AI 模型驗(yàn)證器 訪問,該怎么辦?
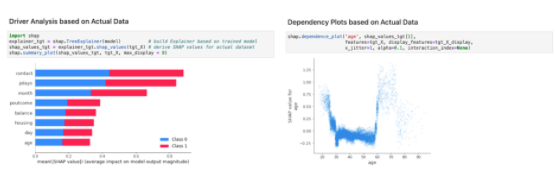
圖 1 :。使用實(shí)際數(shù)據(jù)通過 SHAP 解釋模型的示例
用于跨團(tuán)隊(duì)擴(kuò)展 XAI 的合成數(shù)據(jù)
在人工智能采用的早期,通常是同一組工程師開發(fā)模型并對(duì)其進(jìn)行驗(yàn)證。在這兩種情況下,他們都使用了真實(shí)的生產(chǎn)數(shù)據(jù)。
考慮到算法對(duì)個(gè)人的現(xiàn)實(shí)影響,現(xiàn)在越來(lái)越多的人認(rèn)識(shí)到,獨(dú)立小組應(yīng)該檢查和評(píng)估模型及其影響。理想情況下,這些人會(huì)從工程和非工程背景中提出不同的觀點(diǎn)。
與外部審計(jì)師和認(rèn)證機(jī)構(gòu)簽訂合同,以建立額外的信心,確保算法是公平、公正和無(wú)歧視的。然而,隱私問題和現(xiàn)代數(shù)據(jù)保護(hù)法規(guī)(如 GDPR )限制了對(duì)代表性驗(yàn)證數(shù)據(jù)的訪問。這嚴(yán)重阻礙了模型驗(yàn)證的廣泛開展。
幸運(yùn)的是,模型驗(yàn)證可以使用高質(zhì)量的人工智能生成的 synthetic data 來(lái)執(zhí)行,它可以作為敏感數(shù)據(jù)的高度準(zhǔn)確、匿名的替代品。例如, AI 的 綜合數(shù)據(jù)平臺(tái) 主要使組織能夠以完全自助、自動(dòng)化的方式生成合成數(shù)據(jù)集。
圖 2 顯示了使用合成數(shù)據(jù)對(duì)模型執(zhí)行的 XAI 分析。比較圖 1 和圖 2 時(shí),結(jié)果幾乎沒有任何明顯的差異。同樣的見解和檢查也可以通過利用 AI 的隱私安全合成數(shù)據(jù)來(lái)實(shí)現(xiàn),這最終使真正的協(xié)作能夠在規(guī)模和連續(xù)的基礎(chǔ)上執(zhí)行 XAI 。
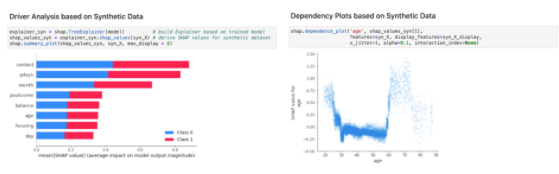
圖 2 :。使用合成數(shù)據(jù)通過 SHAP 解釋模型的示例
圖 3 顯示了跨團(tuán)隊(duì)擴(kuò)展模型驗(yàn)證的過程。組織在其受控的計(jì)算環(huán)境中運(yùn)行最先進(jìn)的合成數(shù)據(jù)解決方案。它不斷生成其數(shù)據(jù)資產(chǎn)的合成副本,可以與內(nèi)部和外部 AI 驗(yàn)證器的不同團(tuán)隊(duì)共享。
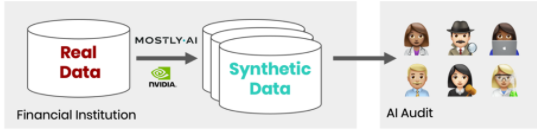
圖 3 :。通過合成數(shù)據(jù)進(jìn)行模型驗(yàn)證的流程
使用 GPU 擴(kuò)展到真實(shí)數(shù)據(jù)量
GPU 加速的庫(kù),如 RAPIDS 和 Plotly ,能夠以實(shí)際遇到的實(shí)際用例所需的規(guī)模進(jìn)行模型驗(yàn)證。這同樣適用于生成合成數(shù)據(jù),其中以 AI 為動(dòng)力的合成解決方案(主要是 AI )可以通過在全棧加速計(jì)算平臺(tái)上運(yùn)行而受益匪淺。有關(guān)更多信息,請(qǐng)參閱 加速信用風(fēng)險(xiǎn)管理的可信 AI 。
為了證明這一點(diǎn),我們參考了房利美(Fannie Mae,F(xiàn)NMA)發(fā)布的抵押貸款數(shù)據(jù)集,目的是【VZX19】。我們首先生成一個(gè)具有統(tǒng)計(jì)代表性的訓(xùn)練數(shù)據(jù)合成副本,由數(shù)千萬(wàn)個(gè)合成貸款組成,由幾十個(gè)合成屬性組成(圖4)。
所有數(shù)據(jù)都是人工創(chuàng)建的,沒有一條記錄可以鏈接回原始數(shù)據(jù)集中的任何實(shí)際記錄。然而,數(shù)據(jù)的結(jié)構(gòu)、模式和相關(guān)性被忠實(shí)地保留在合成數(shù)據(jù)集中。
這種捕獲數(shù)據(jù)多樣性和豐富性的能力對(duì)于模型驗(yàn)證至關(guān)重要。該過程旨在驗(yàn)證模型行為,不僅針對(duì)占主導(dǎo)地位的多數(shù)階級(jí),還針對(duì)人口中代表性不足和最脆弱的少數(shù)群體。
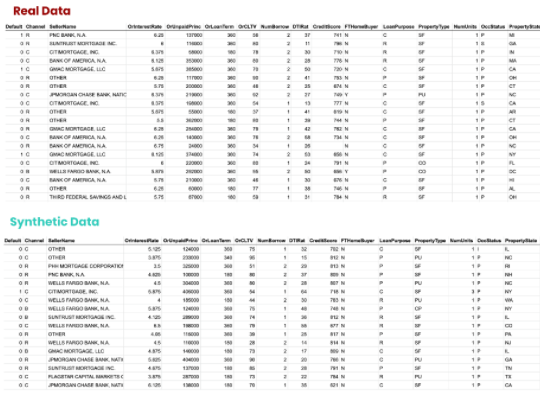
圖 4 :。真實(shí)和合成數(shù)據(jù)樣本的快照
給定生成的合成數(shù)據(jù),然后可以使用 GPU 加速的 XAI 庫(kù)來(lái)計(jì)算感興趣的統(tǒng)計(jì)信息,以評(píng)估模型行為。
例如,圖 5 顯示了 SHAP 值的并列比較:貸款拖欠模型在真實(shí)數(shù)據(jù)上解釋,在合成數(shù)據(jù)上解釋之后。通過使用高質(zhì)量的合成數(shù)據(jù)作為敏感原始數(shù)據(jù)的替代品,可以可靠地得出關(guān)于該模型的相同結(jié)論。
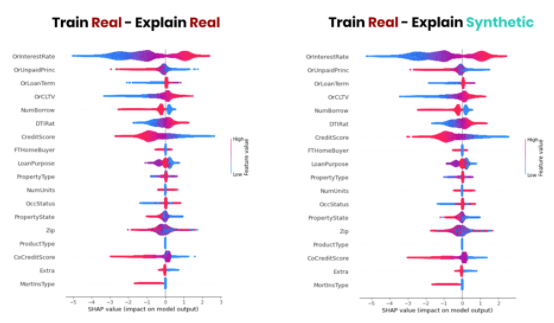
圖 5 :。貸款拖欠 ML 模型的 SHAP 值
圖 5 顯示,合成數(shù)據(jù)可以作為解釋模型行為的實(shí)際數(shù)據(jù)的安全替代品。
此外,合成數(shù)據(jù)生成器生成任意數(shù)量新數(shù)據(jù)的能力使您能夠顯著改進(jìn)較小組的模型驗(yàn)證。
圖 6 顯示了數(shù)據(jù)集中特定郵政編碼的 SHAP 值的并排比較。雖然原始數(shù)據(jù)在給定地理位置的貸款不到 100 筆,但我們利用 10 倍的數(shù)據(jù)量來(lái)檢查該區(qū)域的模型行為,從而實(shí)現(xiàn)更詳細(xì)和更豐富的見解。
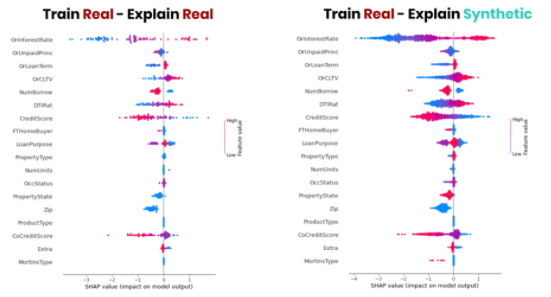
圖 6 :。通過使用合成過采樣進(jìn)行模型驗(yàn)證,獲得更豐富的見解
使用合成樣品進(jìn)行單獨(dú)水平檢驗(yàn)
雖然匯總統(tǒng)計(jì)和可視化是分析一般模型行為的關(guān)鍵,但我們對(duì)模型的理解還可以通過逐個(gè)檢查單個(gè)樣本獲得更多好處。
XAI 工具揭示了多個(gè)信號(hào)對(duì)最終模型決策的影響。只要合成數(shù)據(jù)真實(shí)且具有代表性,這些案例不一定是實(shí)際案例。
圖 7 顯示了四個(gè)隨機(jī)生成的合成案例,以及它們的最終模型預(yù)測(cè)和每個(gè)輸入變量的相應(yīng)分解。這使您能夠在不暴露任何個(gè)人隱私的情況下,深入了解對(duì)無(wú)限潛在案例的模型決策有多大影響的因素和方向。
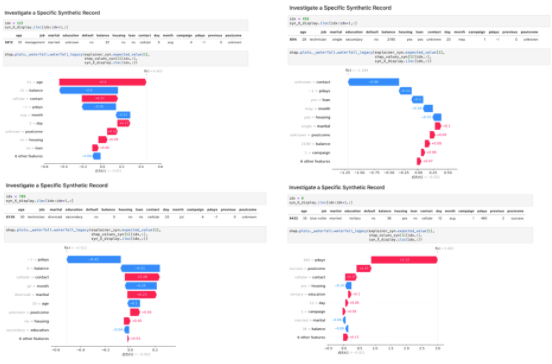
圖 7 :。檢驗(yàn)四個(gè)隨機(jī)抽樣合成記錄的模型預(yù)測(cè)
利用合成數(shù)據(jù)進(jìn)行有效的 AI 治理
人工智能驅(qū)動(dòng)的服務(wù)越來(lái)越多地出現(xiàn)在私營(yíng)和公共部門,在我們的日常生活中發(fā)揮著越來(lái)越大的作用。然而,我們只是在人工智能治理的黎明。
雖然像歐洲提議的人工智能法案這樣的法規(guī)需要時(shí)間才能體現(xiàn)出來(lái),但開發(fā)人員和決策者今天必須負(fù)責(zé)任地采取行動(dòng),并采用 XAI 最佳實(shí)踐。合成數(shù)據(jù)支持廣泛的協(xié)作環(huán)境,而不會(huì)危及客戶的隱私。它是一個(gè)強(qiáng)大、新穎的工具,可以支持開發(fā)和治理公平、健壯的人工智能。
關(guān)于作者
Jochen Papenbrock 位于德國(guó)法蘭克福,在過去的15年中,Jochen一直在金融服務(wù)業(yè)人工智能領(lǐng)域擔(dān)任各種角色,擔(dān)任思想領(lǐng)袖、實(shí)施者、研究者和生態(tài)系統(tǒng)塑造者。
Alexandra 是金融服務(wù)業(yè)的綜合數(shù)據(jù)專家,在隱私、公平和負(fù)責(zé)任的人工智能方面擁有深厚的專業(yè)知識(shí)。作為主要人工智能的首席信托官,她參與了有關(guān)隱私、道德人工智能和新興合成數(shù)據(jù)領(lǐng)域的公共政策討論,并定期在國(guó)際人工智能和銀行會(huì)議上發(fā)言,討論如何協(xié)調(diào)個(gè)性化與隱私,確保算法的公平性,以及如何克服數(shù)字轉(zhuǎn)型帶來(lái)的數(shù)據(jù)挑戰(zhàn)。除此之外, Alexandra 還是數(shù)據(jù)民主化播客的主持人,她邀請(qǐng)一些最大銀行的高管討論隱私和道德 AI 最佳實(shí)踐。
審核編輯:郭婷
-
gpu
+關(guān)注
關(guān)注
28文章
4701瀏覽量
128705 -
AI
+關(guān)注
關(guān)注
87文章
30146瀏覽量
268411 -
人工智能
+關(guān)注
關(guān)注
1791文章
46858瀏覽量
237553
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論