 使用NVIDIA DGX SuperPOD訓練SOTA大規模視覺模型
使用NVIDIA DGX SuperPOD訓練SOTA大規模視覺模型
最近的研究表明,在語義分割和目標檢測等計算機視覺任務中,大型 transformer 模型可以實現或提高 SOTA 。然而,與只能使用標準公共數據集的卷積網絡模型不同,它需要一個更大的專有數據集。
VOLO 模型體系結構
新加坡 SEA AI 實驗室最近的項目 VOLO ( Vision Outlooker )展示了一種高效且可擴展的 Vision transformer 模式體系結構,該體系結構僅使用 ImageNet-1K 數據集就大大縮小了差距。
VOLO 引入了一種新穎的 outlook attention ,并提出了一種簡單而通用的架構,稱為 Vision Outlooker 。與自我關注不同,自我關注側重于粗略級別的全局依賴關系建模, outlook 關注有效地將更精細級別的功能和上下文編碼為標記。這對識別性能極為有利,但在很大程度上被自我注意所忽視。
實驗表明, VOLO 在 ImageNet-1K 分類上達到了 87.1% 的 top-1 精度,這是第一個在這個競爭基準上超過 87% 精度的模型,無需使用任何額外的訓練數據。
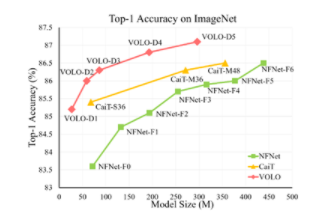
圖 1 :不同尺寸級別的 VOLO 模型的 Top-1 精度
此外,經過預訓練的 VOLO 可以很好地轉移到下游任務,例如語義切分。
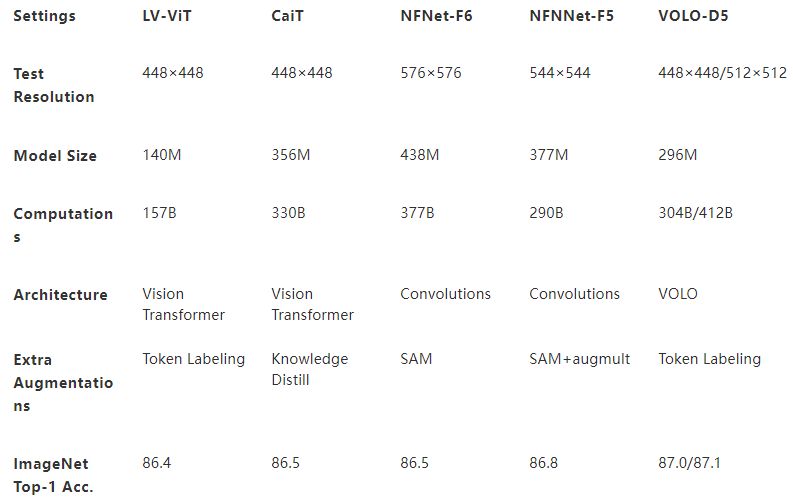
表 1 :對比 ViT 、 CNN 基線模型概述
盡管 VOLO 模型顯示出了出色的計算效率,但訓練 SOTA 性能模型并非易事。
在這篇文章中,我們將介紹我們在 NVIDIA DGX SuperPOD 上基于 NVIDIA ML 軟件堆棧和 Infiniband 群集技術培訓 VOLO 模型所獲得的技術和經驗。
培訓方法
培訓 VOLO 模型需要考慮培訓策略、基礎設施和配置規劃。在本節中,我們將討論此解決方案中應用的一些技術。
培訓策略
始終使用原始 ImageNet 樣本質量數據訓練模型,并在細粒度上執行神經網絡( NN )架構搜索,使理論上的研究更加鞏固。然而,這需要計算資源預算的很大一部分。
在這個項目的范圍內,我們采用了一種粗粒度的訓練方法,它不像細粒度的方法那樣能夠訪問盡可能多的神經網絡體系結構。然而,它能夠以更少的時間和更低的資源預算顯示 EIOF 。在這種替代策略中,我們首先使用分辨率較低的圖像樣本訓練潛在的神經網絡候選,然后使用高分辨率圖像進行微調。
在早期的工作中,這種方法在降低邊際模型性能損失的計算成本方面被證明是有效的。
基礎設施
實際上,我們在本次培訓中使用了兩種類型的集群:
一個用于基礎模型預訓練,它是一個基于 NVIDIA DGX A100 的 DGX 吊艙,由使用 NVIDIA Mellanox HDR Infiniband 網絡集群的 5 個 NVIDIA DGX A100 系統組成。
一個用于微調,即 NVIDIA DGX SuperPOD ,由 DGX A100 系統和 NVIDIA Mellanox HDR Infiniband 網絡組成。

圖 2 :本項目使用的基于 NVIDIA 技術的軟件棧
軟件基礎設施在這一過程中也發揮了重要作用。圖 2 顯示,除了基礎的標準深度學習優化 CUDA 庫(如 cuDNN 和 cuBLAS )外,我們還廣泛利用 NCCL 、 enroot 、 PyXis 、 APEX 和 DALI 來實現培訓性能的亞線性可擴展性。
DGX A100 POD 集群主要用于使用較小尺寸圖像樣本的基礎模型預訓練。這是因為基本模型預訓練的內存限制較少,可以利用 NVIDIA A100 GPU 的計算能力優勢。
相比之下,微調是在 NVIDIA DGX-2 的 NVIDIA DGX SuperPOD 上執行的,因為微調過程使用更大的圖像,每臺計算能力需要更多的內存。
培訓配置
需要引入句子
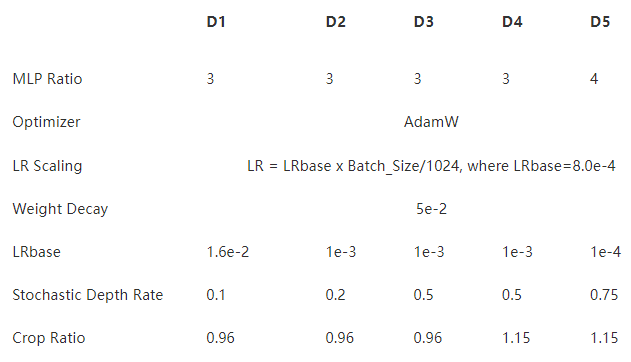
表 2 :模型設置(對于所有模型,批大小設置為 1024 )
我們在 ImageNet 數據集上評估了我們提出的 VOLO 模型。在培訓期間,沒有使用額外的培訓數據。我們的代碼基于 PyTorch 、令牌標記工具箱和 PyTorch 圖像模型( timm )。我們使用帶有標記的 LV-ViT-S 模型作為基線。
安裝說明
我們使用了 AdamW 優化器和線性學習率縮放策略 LR = LR基礎x Batch \ u 大小/ 1024 和 5 × 10 ? 2 先前工作建議的重量衰減率,表 3 中給出了所有 VOLO 模型的 LRbase 。
使用隨機深度。
我們在 ImageNet 數據集上訓練了 300 個時代的模型。
對于數據擴充方法,我們使用 CutOut 、 RandAug 和 MixToken 的標記目標。
我們沒有使用 MixUp 或 CutMix ,因為它們與 MixToken 沖突。
訓練前
在本節中,我們以 VOLO-D5 為例來演示如何訓練模型。
圖 3 顯示,使用單個 DGX A100 的 VOLO-D5 的訓練吞吐量約為 500 圖像/秒。據估計,完成一個完整的預訓練周期大約需要 170 個小時,這需要使用 ImageNet-1K 進行 300 個階段。這相當于 100 萬張圖片的一周。
為了加快速度,基于一個由五個 DGX A100 節點組成的簡單參數服務器架構集群,我們大致實現了 2100 個圖像/秒的吞吐量,這可以將預訓練時間減少到約 52 小時。
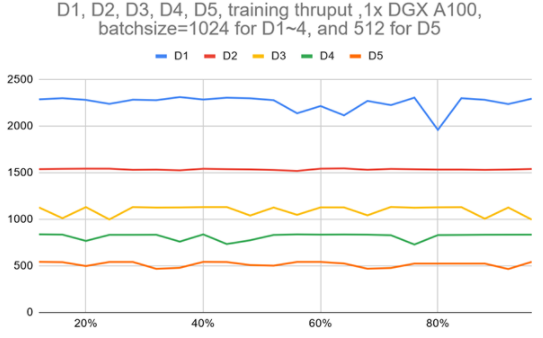
圖 3 :D1 ~ D5 模型在一個 DGX A100 上跨一個完整歷元的訓練吞吐量
VOLO-D5 模型預訓練可以使用以下代碼示例在單個節點上啟動:
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 ./distributed_train.sh 8 /path/to/imagenet \ --model volo_d5 --img-size 224 \ -b 44 --lr 1.0e-4 --drop-path 0.75 --apex-amp \ --token-label --token-label-size 14 --token-label-data /path/to/token_label_data
對于 MNMG 培訓案例,它需要將培訓集群詳細信息作為命令行輸入的一部分。首先,我們根據節點和集群架構設置 CPU 、 MEM 、 IB 綁定。預訓練階段的集群是 DGX A100 POD ,每個 CPU 插槽有四個 NUMA 域,每個 A100 GPU 有一個 IB 端口,因此我們將每個列組綁定到 NUMA 節點中距離其 GPU 最近的所有 CPU 核。
對于內存綁定,我們將每個列組綁定到最近的 NUMA 節點。
對于 IB 綁定,我們為每個 GPU 綁定一個 IB 卡,或者盡可能接近這樣的設置。
由于 VOLO 模型培訓基于 PyTorch ,并且簡單地利用了默認的 PyTorch 分布式培訓方法,因此我們的多節點多 GPU 培訓基于一個簡單的參數服務器架構,該架構適合 NVIDIA DGX SuperPOD 的 fat 樹網絡拓撲。
為了簡化調度,分配節點列表中的第一個節點始終用作參數服務器和工作節點,而所有其他節點都是工作節點。為了避免潛在的存儲 I / O 開銷,數據集、所有代碼、中間/里程碑檢查點和結果都保存在一個基于 DDN 的高性能分布式存儲后端。它們通過 100G NVIDIA Mellanox EDR Infiniband 網絡裝載到所有工作節點。
為了加速數據預處理和流水線數據加載, NVIDIA DALI 配置為每個 GPU 進程使用一個專用數據加載程序。
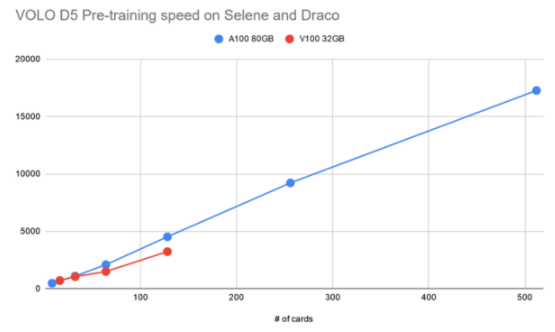
圖 4 :訓練前階段訓練吞吐量相對于 A100 和 V100 的速度提高 GPU
微調
使用以下代碼示例,在單個節點上運行 VOLO-D5 模型微調非常簡單:
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 ./distributed_train.sh 8 /path/to/imagenet \ --model volo_d5 --img-size 512 \ -b 4 --lr 2.3e-5 --drop-path 0.5 --apex-amp --epochs 30 \ --weight-decay 1.0e-8 --warmup-epochs 5 --ground-truth \ --token-label --token-label-size 24 --token-label-data /path/to/token_label_data \ --finetune /path/to/pretrained_224_volo_d5/
如前所述,由于用于微調的圖像大小遠遠大于預訓練階段使用的圖像大小,因此必須相應地減小批量大小。將工作負載放入 GPU 內存中,這使得進一步擴展訓練到更大數量的 GPU 并行任務是必須的。
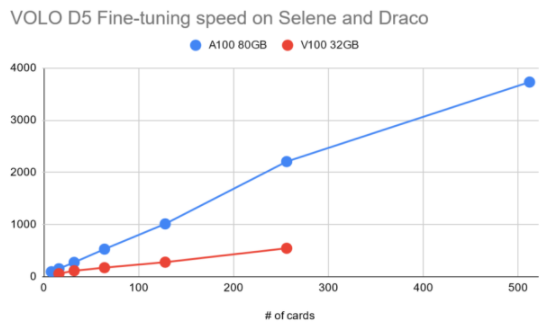
圖 5 :針對 A100 和 V100 的數量提高微調階段訓練吞吐量 GPU
大多數微調配置類似于預訓練階段。
結論
在這篇文章中,我們展示了在大規模人工智能超級計算機上訓練 SOTA 大規模視覺 transformer 模型(如 VOLO \ u D5 )的主要技術和程序,如基于 NVIDIA DGX A100 的 DGX SuperPOD 。經過訓練的 VOLO \ u D5 模型在圖像分類模型排名中取得了最佳的 Top-1 精度,無需使用 ImageNet-1k 數據集以外的任何其他數據。
這項工作的代碼資源(包括用于運行實驗的 Docker 映像和 Slurm 調度程序腳本)在 sail-sg/volo GitHub repo 中是開源的,以便將來可以在 VOLO \ u D5 上進行更廣泛的研究。
未來,我們希望進一步擴展這項工作,以培訓更智能、自我監督、更大規模的模型,使用更大的公共數據集和更現代化的基礎設施,例如, NVIDIA DGX SuperPOD 和 NVIDIA H100 GPU。
關于作者
Terry Yin 目前是 NVIDIA AI 技術中心的高級深度學習解決方案架構師。他分別于 2009 年和 2012 年在中國華南理工大學和韓國延世大學獲得學士和碩士學位。 2012 年至 2016 年,他是南洋理工大學新加坡分校的研究員,期間他獲得了東盟 ICT 金獎、數據中心動態獎、 ACM SIGCOMM 2013 年旅游獎和 GTC 2015 年演講者獎。他的研究興趣包括云計算系統、深度學習系統、高性能計算系統等。
Yuan Lin 是 NVIDIA 編譯團隊的首席工程師。他對所有使程序更高效、編程更高效的技術感興趣。在加入 NVIDIA 之前,他是 Sun Microsystems 的一名高級職員工程師。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
4940瀏覽量
102815 -
gpu
+關注
關注
28文章
4701瀏覽量
128705 -
人工智能
+關注
關注
1791文章
46859瀏覽量
237577
發布評論請先 登錄
相關推薦
使用EMBark進行大規模推薦系統訓練Embedding加速

NVIDIA助力丹麥發布首臺AI超級計算機
NVIDIA Nemotron-4 340B模型幫助開發者生成合成訓練數據

【大規模語言模型:從理論到實踐】- 閱讀體驗
【大規模語言模型:從理論到實踐】- 每日進步一點點
進一步解讀英偉達 Blackwell 架構、NVlink及GB200 超級芯片
【大語言模型:原理與工程實踐】大語言模型的預訓練
Edge Impulse發布新工具,助 NVIDIA 模型大規模部署
NVIDIA Blackwell DGX SuperPOD助力萬億級生成式AI計算
NVIDIA推出搭載GB200 Grace Blackwell超級芯片的NVIDIA DGX SuperPOD?
英偉達推出百億參數AI模型處理方案——DGX SuperPOD
NVIDIA 推出 Blackwell 架構 DGX SuperPOD,適用于萬億參數級的生成式 AI 超級計算

名單公布!【書籍評測活動NO.30】大規模語言模型:從理論到實踐
NVIDIA 為部分大型亞馬遜 Titan 基礎模型提供訓練支持






 工商網監
工商網監
評論