 小馬智行車載傳感器數據處理系統的發展歷程
小馬智行車載傳感器數據處理系統的發展歷程
就像人類用眼睛看東西一樣,自動駕駛汽車使用傳感器收集信息。這些傳感器收集了大量數據,因此需要高效率的車載數據處理,以便車輛對道路情況做出快速反應。這種能力對自動駕駛汽車的安全以及虛擬駕駛員的智能化水平至關重要。
由于需要冗余和多樣化的傳感器和計算系統,因此處理流水線的設計和優化存在一定的難度。本文將介紹小馬智行(Pony.ai)車載傳感器數據處理流水線的發展歷程。
小馬智行的傳感器配置包含多個攝像頭、激光雷達和雷達。上游模塊負責同步傳感器,將數據封裝成消息并發送到下游模塊,后者根據這些數據消息完成物體分割、分類和檢測等。
每種類型的傳感器數據可能被多個模塊使用,并且用戶的算法可能是傳統的或基于神經網絡的。
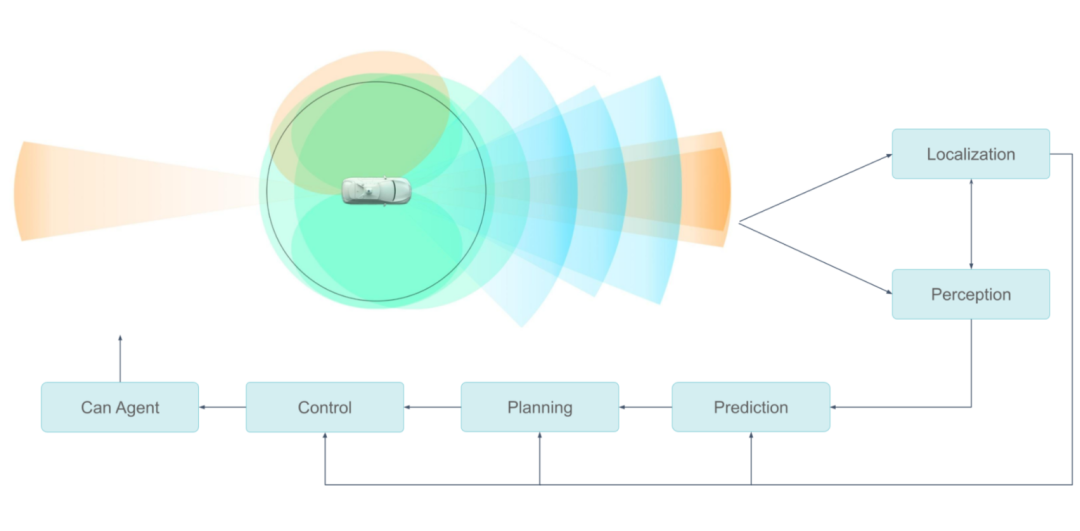
小馬智行自動駕駛傳感系統功能
乘員安全是第一要務,因此整個流水線必須以最高效率運行。而傳感器數據處理系統對安全的影響主要體現在兩個方面。
第一,自動駕駛系統處理傳感器數據的速度是安全的決定性因素之一。如果感知和定位算法收到的傳感器數據出現數百毫秒的延遲,那么車輛就無法及時做出決策。
第二,整個硬件/軟件系統必須是可靠的,才能實現長期保障。消費者絕不會愿意購買或乘坐在制造幾個月后就出現問題的自動駕駛汽車,這一點在量產階段至關重要。
高效處理傳感器數據
考慮到傳感器、 GPU 架構和 GPU 內存,需要采取較為全面的方法應對傳感器處理流水線中的瓶頸。
從傳感器到 GPU
在小馬智行成立之初,傳感器配置由現成組件構成。小馬智行使用基于 USB 和以太網的攝像頭,并將其直接連接到車載電腦上, CPU 負責從 USB /以太網接口讀取數據。
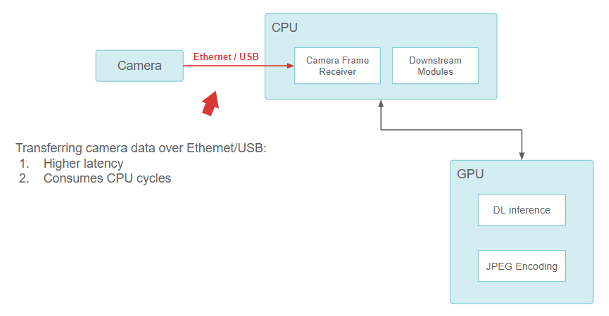
從攝像頭到 CPU 再到 GPU 的流水線功能
雖然這種方法有效,但在設計上存在一個基本問題。USB 和以太網攝像頭接口(GigE-camera)會消耗 CPU。隨著越來越多高分辨率攝像頭的加入, CPU 很快就會不堪重負,無法執行所有輸入輸出(I/O)操作。這種設計很難在保持足夠低的延遲的情況下進行擴展。
為了解決這個問題,小馬智行為攝像頭和激光雷達增加了基于 FPGA 的傳感器網關。
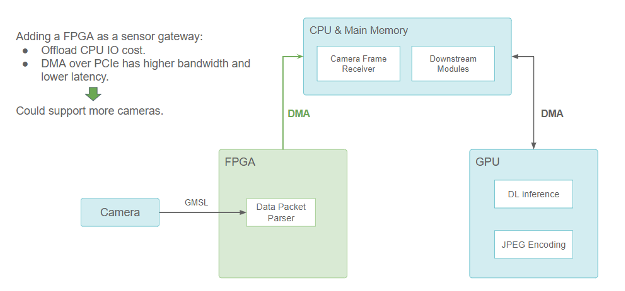
擔任傳感器網關的 FPGA (傳感器部分使用攝像頭示范)
FPGA 通過處理攝像頭觸發和同步邏輯來實現更好的傳感器融合。當攝像頭數據包準備就緒時,就會觸發 DMA 傳輸,通過 PCIe 總線將數據從 FPGA 復制到主存儲器。DMA 引擎在 FPGA 上執行此操作,不會占用 CPU。它不僅解放了 CPU 的 I/O 資源,而且還減少了數據傳輸延遲,使傳感器的配置更具有可擴展性。
由于許多在 GPU 上運行的神經網絡模型都需要使用攝像頭數據,在通過 DMA 將數據從 FPGA 傳輸到 CPU 之后,仍須將其復制到 GPU 內存。因此在某處需要進行 CUDA HostToDevice內存拷貝, FHD 分辨率的圖像每幀的用時需要約 1.5ms。
但小馬智行想進一步減少延遲。理想情況下,應直接將攝像頭數據傳輸到 GPU 內存,而不需要通過 CPU。
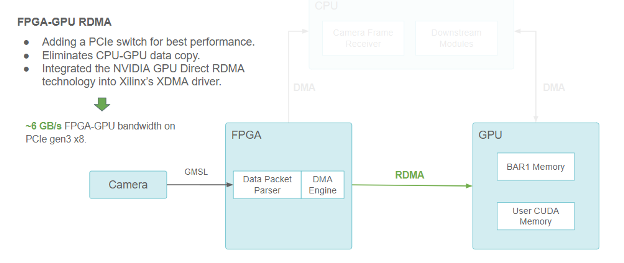
攝像頭/FPGA/CPU/GPU流水線功能塊圖,使用 RDMA 在 FPGA 和 GPU 之間進行通信
GPU Direct RDMA 使小馬智行能夠通過 PCIe BAR (定義 PCIe 地址空間線性窗口的基地址寄存器)預分配 CUDA 內存供 PCIe peers 訪問。
它還為第三方設備驅動程序提供了一系列內核空間 API 以獲得 GPU 內存物理地址。這些 API 方便了第三方設備的 DMA 引擎直接向 GPU 內存發送和讀取數據,就像是在向主內存發送和讀取數據一樣。
GPU Direct RDMA 通過消除 CPU 到 GPU 的復制來減少延遲,并在 PCIe Gen3 x8 下實現約 6 GB/s 的最高帶寬(理論極限值為 8 GB/s)。
跨 GPU 擴展
由于計算工作負載的增加,小馬智行需要不止一個 GPU。隨著越來越多的 GPU 加入到系統中,GPU之間的通信也可能成為瓶頸。經中轉緩沖區通過 CPU 會增加 CPU 成本,并限制整體帶寬。
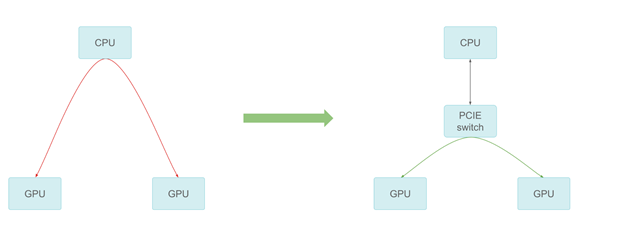
通過 PCIe 交換機進行 GPU-GPU 通信
小馬智行添加了 PCIe 開關提供最好的對等傳輸性能。在測量中,對等通信可以達到 PCIe 速度上限,提高了跨多個 GPU 的擴展性。
將計算轉移到專用硬件
小馬智行還將以前在 CUDA 核上運行的任務轉移到專用硬件上,以加速傳感器數據處理。
例如,當把 FHD 攝像頭圖像編碼成 JPEG 字符串時, NvJPEG 庫在 RTX5000 GPU 的單個 CPU 線程上需要約 4 毫秒。NvJPEG 可能會消耗 CPU 和 GPU 資源,這是因為它的一些階段(比如 Huffman 編碼)可能完全是在 CPU 上運行的。
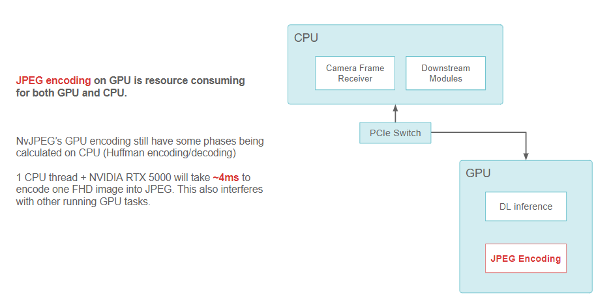
使用 GPU 上的 NvJPEG 庫進行 JPEG 編碼的數據流功能塊圖
小馬智行在車輛上采用了 NVIDIA 視頻編解碼器,以減輕 CPU 和 GPU ( CUDA 部分)進行圖像編碼和解碼的負擔。此編解碼器在 GPU 的專用部分使用編碼器。它屬于 GPU 的一部分,但不會與用于運行內核和深度學習模型的其他 CUDA 資源相沖突。
小馬智行也一直在使用 NVIDIA GPU 上的專用硬件視頻編碼器將圖像壓縮格式從 JPEG 遷移到 HEVC(H.265)。這實現了編碼速度的提高,并為其他任務釋放了 CPU 和 GPU 資源。
在不影響 CUDA 性能的情況下,在 GPU 上對 FHD 圖像進行完全編碼需要 3 毫秒。該性能在純 I 幀模式下測量,可確保各幀之間質量和壓縮偽影的一致性。

避免消耗 CUDA 核或 CPU 的 HEVC 編碼數據流功能塊圖
NVIDIA 視頻編解碼器在 GPU 芯片的專用分區中使用編碼器,不會消耗 CUDA 核或 CPU。NVENC 支持 H264/H265。將 FHD 圖像編碼為 HEVC 需要約 3ms,因此可以釋放 GPU 和 CPU 去處理其他任務。小馬智行使用純 I 幀模式,確保每幀都有相同的質量和相同類型的偽影。
GPU 上的數據流
另一個關鍵是將攝像頭幀作為信息發送到下游模塊的效率。
小馬智行使用谷歌的 ProtoBuf 來定義消息。以CameraFrame信息為例,攝像頭規格和屬性是該消息中的基本數據類型。由于 ProtoBuf 的限制,真正的有效載荷——攝像頭數據必須被定義為主系統內存中的字節。
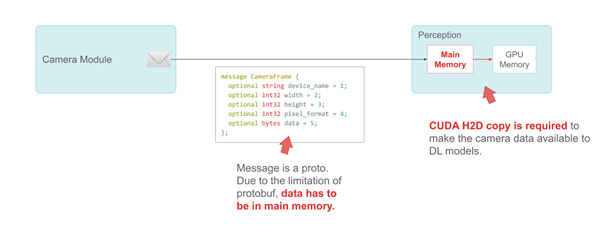
CameraFrame 消息示例
以下代碼示例中的消息是一個原型。由于 protobuf 的限制, data 這一成員必須在主內存中。
message CameraFrame {
optional string device_name = 1;
optional int32 width = 2;
optional int32 height = 3;
optional int32 pixel_format = 4;
optional bytes data = 5;
};
小馬智行使用發布-訂閱模式,通過模塊間的零拷貝消息傳遞來共享信息。CameraFrame 信息的許多用戶模塊使用攝像頭數據進行深度學習推理。
在最初的設計中,當此類模塊收到信息時,它不得不調用 CUDA 的HostToDevice拷貝,在推理前將攝像頭數據傳輸到 GPU 上。
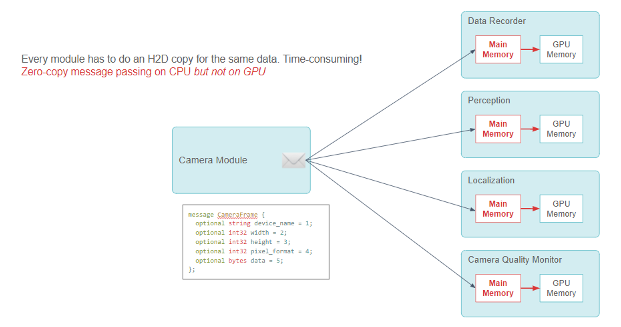
發布-訂閱模型功能:攝像頭模塊向多個用戶模塊發送 CameraFrame 信息。每個用戶模塊需要進行 CPU 到 GPU 的內存拷貝。
每個模塊都必須進行 CUDAHostToDevice拷貝,這項工作既多余又消耗資源。雖然零拷貝消息傳遞框架在 CPU 上運行良好,但它需要進行大量 CPU-GPU 數據拷貝。
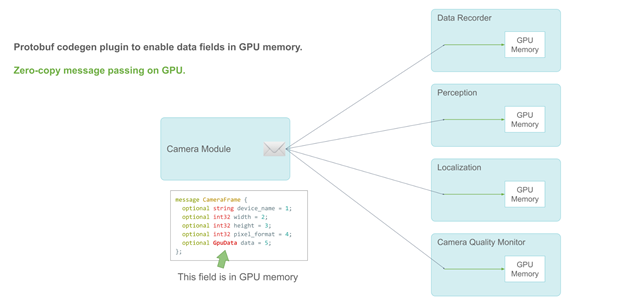
支持 GPU 的零拷貝發布-訂閱信息傳遞
小馬智行通過 protobuf 的插件 API 將新的數據類型——GpuData字段添加到 protobuf 代碼生成器中,從而解決了這個問題。如同 CPU 內存bytes字段,GpuData支持標準resize操作。但它的物理數據存儲在 GPU 上。
當用戶模塊收到消息時,他們可以檢索能夠直接使用的 GPU 數據指針。因此,小馬智行在整個流水線上實現了完全的零拷貝。
改進 GPU 內存分配
當我們調用GpuDataproto 的resize操作時,它會調用 CUDA 中的cudaMalloc參數。當GpuDataproto 信息被銷毀時,它會調用cudaFree。
這兩個 API 操作的成本并不低,因為它們必須修改 GPU 的內存映射。每次調用可能需要約 0.1ms。
由于該 proto 消息被廣泛使用,而攝像頭在不停地產生數據,所以小馬智行應該優化 GPU proto 消息的分配與釋放(alloc/free)成本。
小馬智行采用了固定片段大小的 GPU 內存池來解決這個問題。這個想法很簡單:維護一個預先分配的 GPU 內存池,內存池的每個片段大小匹配攝像頭數據幀的大小。每次alloc時,就從堆棧中取出一片 GPU 內存。每次free時,該 GPU 內存片段就會返回到池中。通過重新使用 GPU 內存,alloc/free時間接近于零。

僅支持固定分配大小的 GPU 內存池
如果想支持不同分辨率的攝像頭該怎么辦?使用這種固定大小的內存池,就必須始終分配盡量多的大小,或者初始化插槽大小不同的多個內存池。這兩種情況都會降低效率。
CUDA 11.2 的新功能解決了這個問題。它正式支持cudaMemPool,該內存池可以被預先分配并在之后用于cudaMalloc和free。與之前的方法相比,這種方法適用于任何分配大小,以極小性能代價極大地提高了靈活性(每次分配約 2us)。

支持動態分配大小的 GPU 內存池
在這兩種方法中,當內存池溢出時,resize的調用會退回到傳統的cudaMalloc和free。
YUV 顏色空間中更干凈的數據流
通過上述所有的硬件設計和系統軟件架構優化,小馬智行實現了高效的數據流。下一步是優化數據格式本身。
小馬智行的系統曾經在 RGB 顏色空間中處理攝像頭數據。但攝像頭的圖像信號處理(ISP)輸出是在 YUV 顏色空間,在 GPU 上進行 YUV 到 RGB 的轉換需要約 0.3ms。此外,一些感知組件不需要顏色信息。向它們提供 RGB 顏色像素是一種浪費。
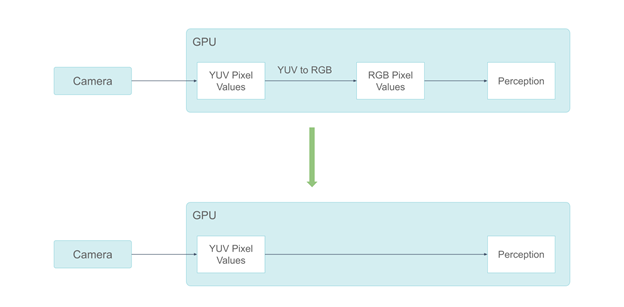
使用 YUV 格式避免顏色空間轉換
鑒于這些原因,小馬智行從 RGB 攝像頭格式遷移到 YUV 格式。由于人類視覺對色度信息不如對亮度信息那么敏感,因此小馬智行選擇使用 YUV420 像素格式。
通過采用 YUV420 像素格式,小馬智行減少了一半的 GPU 內存消耗。這也使小馬智行能夠只將 Y 通道發送到不需要色度信息的感知組件。與 RGB 相比,這減少了三分之二的 GPU 內存消耗。
在 GPU 上處理激光雷達數據
除了攝像頭數據,小馬智行還在 GPU 上處理激光雷達數據,而且這些數據更加稀疏。不同類型的激光雷達增加了這項處理工作的難度。在處理激光雷達數據時,小馬智行采取了一些優化措施。
-
由于激光雷達掃描數據包含大量物理信息,小馬智行使用對 GPU 友好的數組結構代替結構數組來描述點云,使 GPU 的內存訪問模式變得更加凝聚而不是分散。
-
當必須在 CPU 和 GPU 之間交換時,將數據保存在鎖定內存中以加速傳輸。
-
NVIDIA CUB 庫在小馬智行的的處理流水線中被廣泛使用,尤其是 Scan/Select 操作。
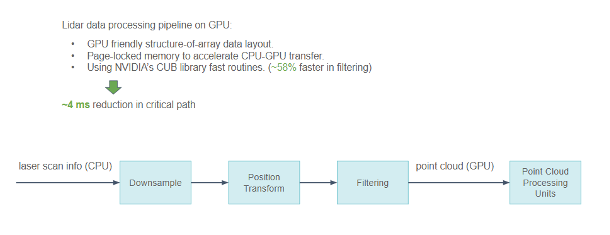
從激光雷達傳感器到 GPU 上點云處理的流水線功能
通過所有這些優化,小馬智行在關鍵路徑上將整個流水線的延遲減少了約 4ms。
總時間線
憑借所有這些優化,小馬智行可以使用內部的時間線可視化工具查看系統追蹤。

從傳感器數據到深度學習推理的總時間線
總時間線顯示了小馬智行目前對 GPU 的總體依賴程度。盡管這兩個 GPU 在 80% 的時間內被使用,但 GPU0 和 GPU1 的工作負載并不平衡。GPU 0 在整個感知模塊迭代過程中被大量使用,而 GPU1 在迭代的中間階段有更多的空閑時間。
未來小馬智行將專注于進一步提高 GPU 的效率。
生產就緒
在開發初期,小馬智行通過 FPGA 輕松試驗在基于硬件的傳感器數據處理方面的想法。隨著傳感器數據處理單元變得越來越成熟,小馬智行開始研究如何使用系統級芯片(SoC)提供緊湊、可靠的生產級傳感器數據處理器。
經發現,車規級 NVIDIA DRIVE Orin 系統級芯片完全滿足小馬智行的要求。它符合 ASIL 認證,因此非常適合在量產車輛上運行。
從 FPGA 遷移到 NVIDIA DRIVE Orin
在開發初期,小馬智行通過 FPGA 輕松試驗在基于硬件的傳感器數據處理方面的想法。
隨著傳感器數據處理單元變得越來越成熟,小馬智行開始研究如何使用系統級芯片(SoC)提供緊湊、可靠的生產級傳感器數據處理器。
小馬智行發現,車規級 NVIDIA DRIVE Orin 系統級芯片完全滿足要求。它符合 ASIL 認證,因此非常適合在量產車輛上運行。
小馬智行將使用 NVIDIA DRIVE Orin 來處理所有傳感器信號處理、同步、數據包收集以及攝像頭幀編碼。小馬智行估計這種設計與其他架構優化結合后,將節省約 70% 的總硬件成本。
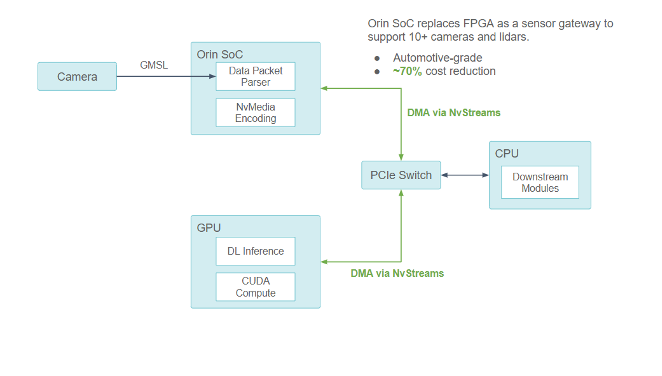
使用 NVIDIA DRIVE Orin 系統級芯片作為新的傳感器網關
通過與 NVIDIA 合作,小馬智行確保 Orin-CPU-GPU 組件之間的所有通信均通過 PCIe 總線進行,并通過 NvStreams 支持 DMA。
-
對于計算密集型深度學習工作, NVIDIA Orin 系統級芯片使用 NvStream 將傳感器數據傳輸到獨立的 GPU 上進行處理。
-
對于非 GPU 工作, NVIDIA Orin 系統級芯片使用 NvStream 將數據傳輸到主機 CPU 進行處理。
Orin 提供每秒 254 萬億次計算性能,可以處理與目前 L4 級自動駕駛汽車計算平臺上所使用的 RTX5000 獨立 GPU 類似的工作負載。但它需要通過多項優化,才能充分釋放 NVIDIA DRIVE Orin 系統級芯片的潛力,例如:
-
結構性稀疏網絡
-
DLA(深度學習加速器)核
-
跨多個 NVIDIA DRIVE Orin 系統級芯片的擴展
結論
小馬智行傳感器數據處理流水線的發展歷程顯示了小馬智行采用系統化方法來實現高效率的數據處理流水線和更高的系統可靠性,這有助于實現更高的安全目標。這種方法背后的簡單理念是:
-
使數據流簡單而流暢。數據應該以最小化轉化開銷的格式被直接傳輸到它將被使用的地方。
-
專用硬件用于計算密集型任務,通用計算資源用于其他任務。
這種方法無法僅靠軟件或硬件來實現,而是依靠在軟件和硬件協同設計方面的共同努力。這對于滿足快速增長的計算需求與生產期望至關重要。
原文標題:加速小馬智行自動駕駛汽車傳感器數據處理流水線
文章出處:【微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
-
NVIDIA
+關注
關注
14文章
4949瀏覽量
102826 -
自動駕駛
+關注
關注
783文章
13694瀏覽量
166166 -
車載傳感器
+關注
關注
0文章
44瀏覽量
4347 -
小馬智行
+關注
關注
0文章
101瀏覽量
3677
原文標題:加速小馬智行自動駕駛汽車傳感器數據處理流水線
文章出處:【微信號:NVIDIA_China,微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Microchip PolarFire? FPGA以太網傳感器橋與NVIDIA Holoscan傳感器處理平臺兼容的人工智能(AI)驅動的傳感器處理系統
霍爾傳感器的發展歷史與技術革新
FPGA在數據處理中的應用實例
如何構建一個基于Imap4郵件通信協議與放射性物質監測數據處理系統
車載傳感器網絡是什么意思啊
車載傳感器主要有哪些傳感器
信號采集與處理系統通常由哪些模塊組成
XV4001系列陀螺儀傳感器廣泛用于車載導航系統
振弦采集儀在巖土工程監測中的數據處理與結果展示

土壤墑情監測站系統是一種集成了多種監測設備和數據處理技術的系統
工業物聯網如何選擇數據采集網關

從數據到決策:車載中控系統在空中交通指揮車中的應用探索
虹科方案 | 車內智慧大腦:基于車載網絡捕獲的全景數據處理





 工商網監
工商網監
評論