 機器學習算法的介紹
機器學習算法的介紹

哲學要回答的基本問題是從哪里來、我是誰、到哪里去,尋找答案的過程或許可以借鑒機器學習的套路:組織數據->挖掘知識->預測未來。組織數據即為設計特征,生成滿足特定格式要求的樣本,挖掘知識即建模,而預測未來就是對模型的應用。

特征設計依賴于對業務場景的理解,可分為連續特征、離散特征和組合高階特征。本篇重點是機器學習算法的介紹,可以分為監督學習和無監督學習兩大類。
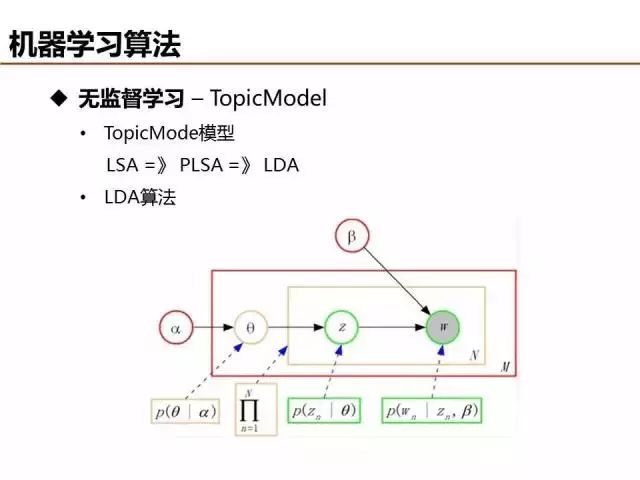
無監督學習算法很多,最近幾年業界比較關注主題模型,LSA->PLSA->LDA為主題模型三個發展階段的典型算法,它們主要是建模假設條件上存在差異。LSA假設文檔只有一個主題,PLSA假設各個主題的概率分布不變(theta都是固定的),LDA假設每個文檔和詞的主題概率是可變的。
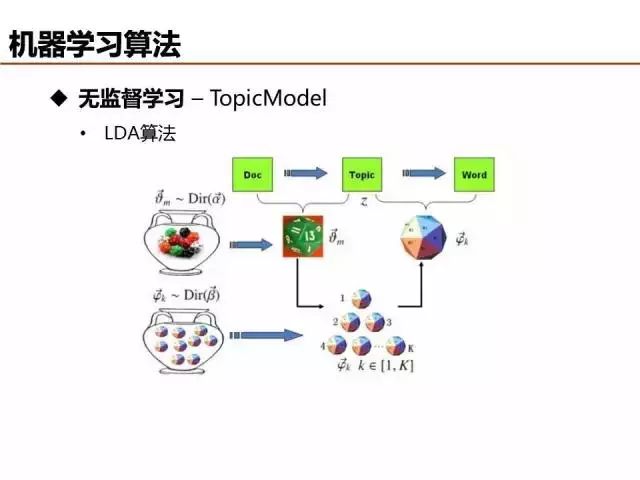
LDA算法本質可以借助上帝擲骰子幫助理解,詳細內容可參加Rickjin寫的《LDA數據八卦》文章,淺顯易懂,順便也科普了很多數學知識,非常推薦。
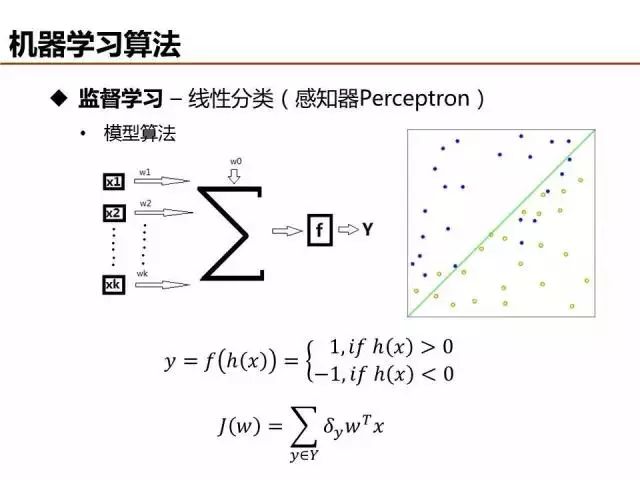
監督學習可分為分類和回歸,感知器是最簡單的線性分類器,現在實際應用比較少,但它是神經網絡、深度學習的基本單元。
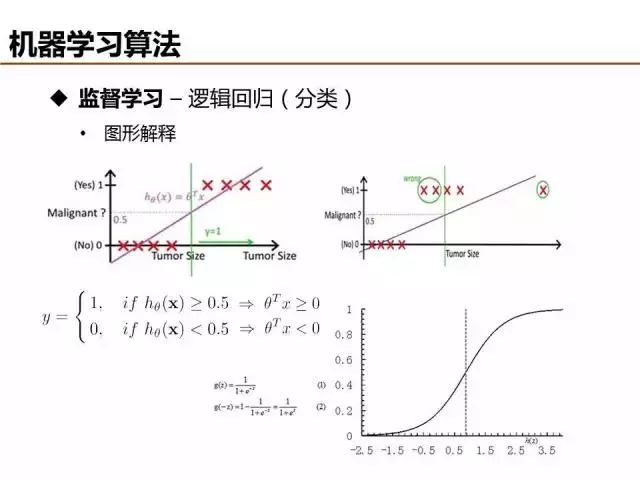
線性函數擬合數據并基于閾值分類時,很容易受噪聲樣本的干擾,影響分類的準確性。邏輯回歸(Logistic Regression)利用sigmoid函數將模型輸出約束在0到1之間,能夠有效弱化噪聲數據的負面影響,被廣泛應用于互聯網廣告點擊率預估。


邏輯回歸模型參數可以通過最大似然求解,首先定義目標函數L(theta),然后log處理將目標函數的乘法邏輯轉化為求和邏輯(最大化似然概率 -> 最小化損失函數),最后采用梯度下降求解。
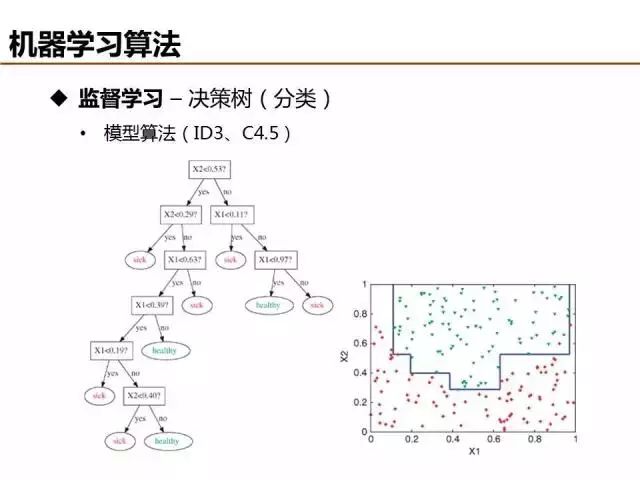

相比于線性分類去,決策樹等非線性分類器具有更強的分類能力,ID3和C4.5是典型的決策樹算法,建模流程基本相似,兩者主要在增益函數(目標函數)的定義不同。
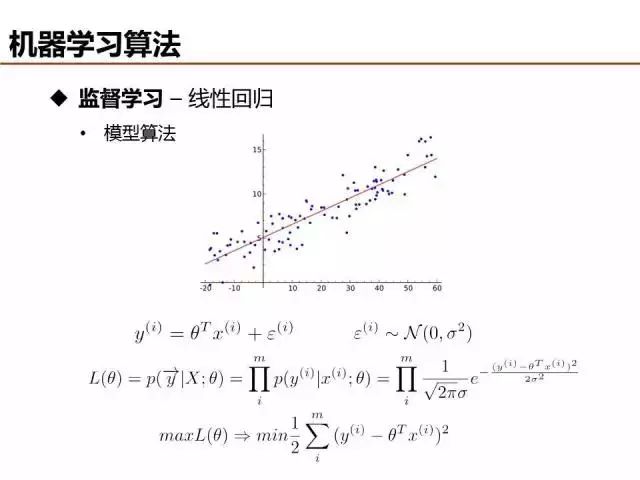
線性回歸和線性分類在表達形式上是類似的,本質區別是分類的目標函數是離散值,而回歸的目標函數是連續值。目標函數的不同導致回歸通常基于最小二乘定義目標函數,當然,在觀測誤差滿足高斯分布的假設情況下,最小二乘和最大似然可以等價。

當梯度下降求解模型參數時,可以采用Batch模式或者Stochastic模式,通常而言,Batch模式準確性更高,Stochastic模式復雜度更低。
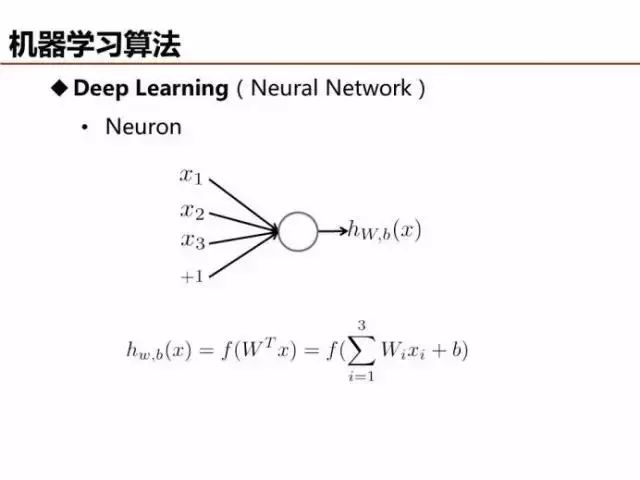
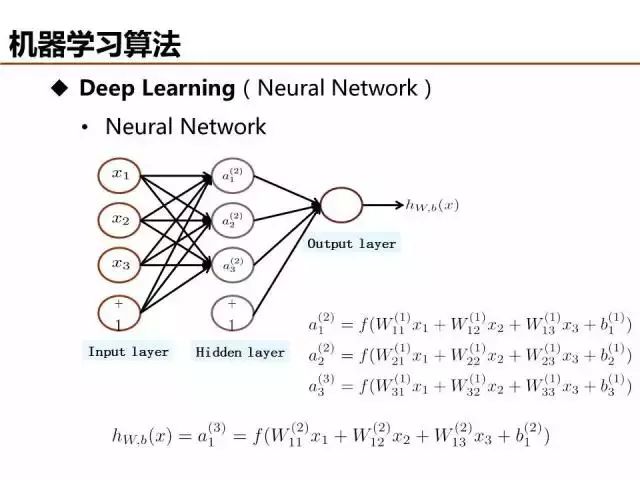
上文已經提到,感知器雖然是最簡單的線性分類器,但是可以視為深度學習的基本單元,模型參數可以由自動編碼(Auto Encoder)等方法求解。

深度學習的優勢之一可以理解為特征抽象,從底層特征學習獲得高階特征,描述更為復雜的信息結構。例如,從像素層特征學習抽象出描述紋理結構的邊緣輪廓特征,更進一步學習獲得表征物體局部的更高階特征。 俗話說三個臭皮匠賽過諸葛亮,無論是線性分類還是深度學習,都是單個模型算法單打獨斗,有沒有一種集百家之長的方法,將模型處理數據的精度更進一步提升呢?當然,Model Ensembel就是解決這個問題。Bagging為方法之一,對于給定數據處理任務,采用不同模型/參數/特征訓練多組模型參數,最后采用投票或者加權平均的方式輸出最終結果。 Boosting為Model Ensemble的另外一種方法,其思想為模型每次迭代時通過調整錯誤樣本的損失權重提升對數據樣本整體的處理精度,典型算法包括AdaBoost、GBDT等。

不同的數據任務場景,可以選擇不同的Model Ensemble方法,對于深度學習,可以對隱層節點采用DropOut的方法實現類似的效果。
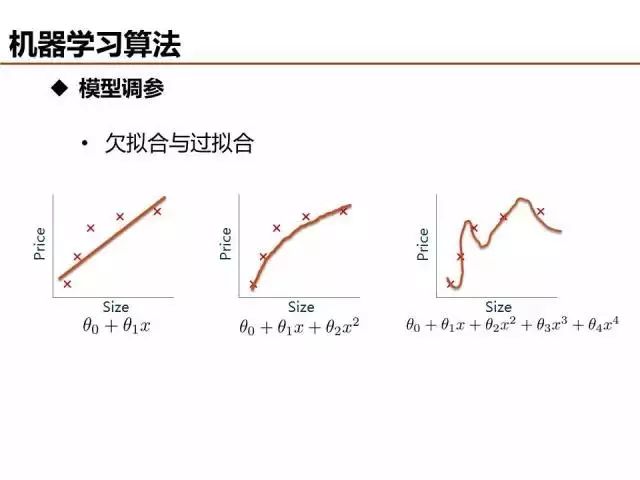
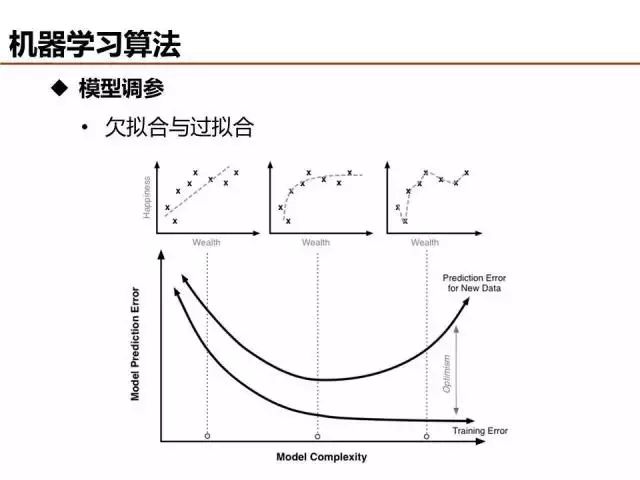
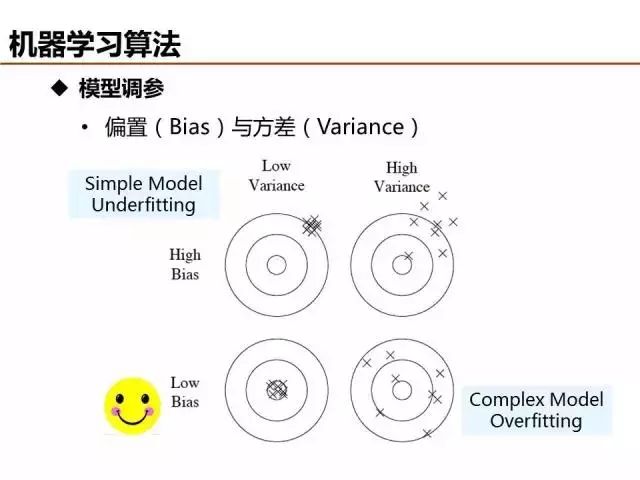
介紹了這么多機器學習基礎算法,說一說評價模型優劣的基本準則。欠擬合和過擬合是經常出現的兩種情況,簡單的判定方法是比較訓練誤差和測試誤差的關系,當欠擬合時,可以設計更多特征來提升模型訓練精度,當過擬合時,可以優化特征量降低模型復雜度來提升模型測試精度。
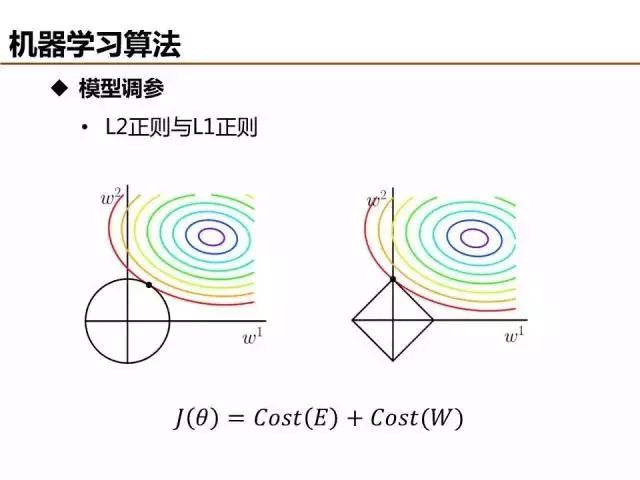
特征量是模型復雜度的直觀反映,模型訓練之前設定輸入的特征量是一種方法,另外一種比較常用的方法是在模型訓練過程中,將特征參數的正則約束項引入目標函數/損失函數,基于訓練過程篩選優質特征。
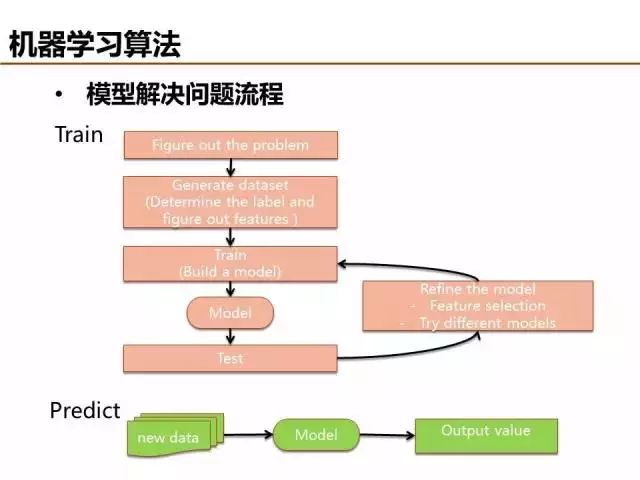
模型調優是一個細致活,最終還是需要能夠對實際場景給出可靠的預測結果,解決實際問題。期待學以致用!
審核編輯 :李倩
-
算法
+關注
關注
23文章
4600瀏覽量
92647 -
機器學習
+關注
關注
66文章
8378瀏覽量
132415
原文標題:零基礎入門機器學習算法(附圖)
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
NPU與機器學習算法的關系
人工智能、機器學習和深度學習存在什么區別

LIBS結合機器學習算法的江西名優春茶采收期鑒別

【「時間序列與機器學習」閱讀體驗】全書概覽與時間序列概述
機器學習算法原理詳解
機器學習在數據分析中的應用
深度學習與傳統機器學習的對比
名單公布!【書籍評測活動NO.35】如何用「時間序列與機器學習」解鎖未來?
圖機器學習入門:基本概念介紹

深入探討機器學習的可視化技術

機器學習怎么進入人工智能
機器學習8大調參技巧
AI算法的本質是模擬人類智能,讓機器實現智能化
目前主流的深度學習算法模型和應用案例






 工商網監
工商網監
評論