") Linux內(nèi)存的分配管理與內(nèi)存回收基本框架
Linux內(nèi)存的分配管理與內(nèi)存回收基本框架
1.序言
內(nèi)存對(duì)計(jì)算機(jī)系統(tǒng)來(lái)說(shuō)是一項(xiàng)非常重要的資源,直接影響著系統(tǒng)運(yùn)行的性能。最初的時(shí)候,系統(tǒng)是直接運(yùn)行在物理內(nèi)存上的,這存在著很多的問(wèn)題,尤其是安全問(wèn)題。后來(lái)出現(xiàn)了虛擬內(nèi)存,內(nèi)核和進(jìn)程都運(yùn)行在虛擬內(nèi)存上,進(jìn)程與進(jìn)程之間有了空間隔離,增加了安全性。進(jìn)程與內(nèi)核之間有特權(quán)級(jí)的區(qū)別,進(jìn)程運(yùn)行在非特權(quán)級(jí),內(nèi)核運(yùn)行在特權(quán)級(jí),進(jìn)程不能訪問(wèn)內(nèi)核空間,只能通過(guò)系統(tǒng)調(diào)用和內(nèi)核進(jìn)行交互,內(nèi)核會(huì)對(duì)進(jìn)程進(jìn)行嚴(yán)格的權(quán)限檢查和參數(shù)檢查,使得系統(tǒng)更加安全。通過(guò)虛擬內(nèi)存訪問(wèn)物理內(nèi)存,每次都需要解析頁(yè)表,這大大降低了內(nèi)存訪問(wèn)的性能,為此CPU的MMU里面加入了TLB用來(lái)緩存頁(yè)表解析的結(jié)果,這樣由于程序的時(shí)間局部性和空間局部性,能極大的提高內(nèi)存訪問(wèn)的速度。雖然和直接訪問(wèn)物理內(nèi)存相比,仍然存在著一些性能損耗,但是損耗已經(jīng)降到很低了。因此虛擬內(nèi)存機(jī)制在系統(tǒng)安全和性能之間達(dá)到了最大的平衡。雖然如此,但是虛擬內(nèi)存機(jī)制也使得計(jì)算機(jī)的內(nèi)存系統(tǒng)變得異常復(fù)雜,給我們的編程帶來(lái)了巨大的挑戰(zhàn)。內(nèi)存問(wèn)題,在很多軟件公司里面,都是一個(gè)非常重要非常讓人頭疼的問(wèn)題,今天我們從OOM的角度來(lái)幫大家提高一點(diǎn)內(nèi)存方面的知識(shí),雖然不能說(shuō)幫助人們來(lái)完全解決內(nèi)存問(wèn)題,但是也能從一個(gè)側(cè)面來(lái)提高大家分析內(nèi)存問(wèn)題相關(guān)的能力。2.內(nèi)存的分配管理
我們已經(jīng)知道了物理內(nèi)存、虛擬內(nèi)存、用戶空間、內(nèi)核空間之間的區(qū)別,下面我們?cè)賮?lái)深入的了解一下這方面的知識(shí)。系統(tǒng)剛啟動(dòng)的時(shí)候是運(yùn)行在物理內(nèi)存之上的,然后系統(tǒng)建立了一段足夠自己繼續(xù)運(yùn)行的恒等映射的頁(yè)表,也就是把物理地址映射到相同地址的虛擬地址上。等到系統(tǒng)再進(jìn)一步初始化之后,就會(huì)建立完整的頁(yè)表來(lái)映射物理內(nèi)存,并把內(nèi)核映射在虛擬地址空間的高部位,對(duì)于32位系統(tǒng)來(lái)說(shuō)是3G之上的內(nèi)存空間,對(duì)于64系統(tǒng)來(lái)說(shuō),是映射到比較接近虛擬地址頂端的地方。內(nèi)核初始化之后就會(huì)啟動(dòng)init進(jìn)程,從而啟動(dòng)整個(gè)用戶空間的所有進(jìn)程。內(nèi)核空間和用戶空間的內(nèi)存管理方式的差別是非常大的,首先內(nèi)核是不會(huì)缺頁(yè)也不會(huì)換頁(yè)的,不會(huì)缺頁(yè)是指內(nèi)核的物理內(nèi)存在啟動(dòng)時(shí)就直接映射好了,使用時(shí)直接分配就行了,分配好虛擬內(nèi)存的同時(shí)物理內(nèi)存也分配好了。不會(huì)換頁(yè)是指,當(dāng)系統(tǒng)內(nèi)存不足時(shí)內(nèi)核自身使用的物理內(nèi)存不會(huì)被swap出去。與此相反,用戶空間的內(nèi)存分配是先分配虛擬內(nèi)存,此時(shí)并不會(huì)直接分配物理內(nèi)存,而是延遲到程序運(yùn)行時(shí)訪問(wèn)到哪里的內(nèi)存,如果這個(gè)內(nèi)存還沒(méi)有對(duì)應(yīng)的物理內(nèi)存,MMU就會(huì)報(bào)缺頁(yè)異常從而陷入內(nèi)核,執(zhí)行內(nèi)核的缺頁(yè)異常handler給分配物理內(nèi)存,并建立頁(yè)表映射,然后再回到用戶空間剛才的那個(gè)指令處繼續(xù)執(zhí)行。當(dāng)系統(tǒng)內(nèi)存不足時(shí),用戶空間使用的物理內(nèi)存會(huì)被swap到磁盤,從而回收物理內(nèi)存。之后如果進(jìn)程再訪問(wèn)這段內(nèi)存又會(huì)再發(fā)生缺頁(yè)異常從swap處把內(nèi)存內(nèi)容加載回來(lái)。3.進(jìn)程的內(nèi)存空間布局
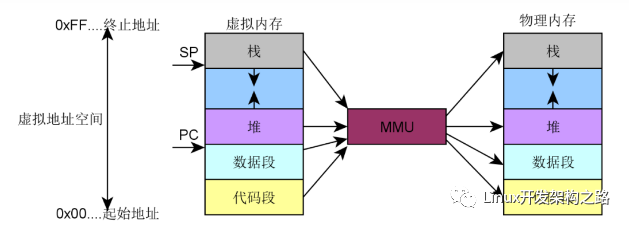
明白了上面這些,我們?cè)賮?lái)看看進(jìn)程的用戶空間內(nèi)存布局。我們都知道進(jìn)程的內(nèi)存空間是由代碼區(qū)、數(shù)據(jù)區(qū)、堆區(qū)、棧區(qū)組成。我們先來(lái)看下面的圖,我們以32位進(jìn)程為例進(jìn)行講解,64位的數(shù)值太大不好畫的,但是原理都是一樣的。
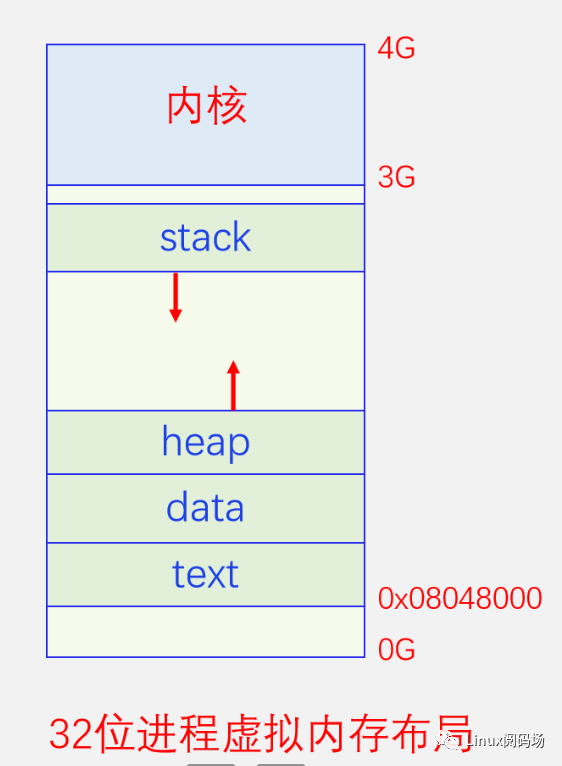
4.內(nèi)存回收基本框架
在講OOM之前,我們先來(lái)了解一下內(nèi)核內(nèi)存回收的總體框架。內(nèi)存作為系統(tǒng)最寶貴的資源,總是不夠用的,經(jīng)常需要進(jìn)行回收。內(nèi)存回收可分為兩種方式,同步回收和異步回收,同步回收是在分配內(nèi)存時(shí)發(fā)現(xiàn)內(nèi)存不足直接調(diào)用函數(shù)進(jìn)行回收,異步回收是喚醒專門的回收線程kswapd進(jìn)行回收。我們先看一下它們的總體架構(gòu)圖,然后再一一說(shuō)明。
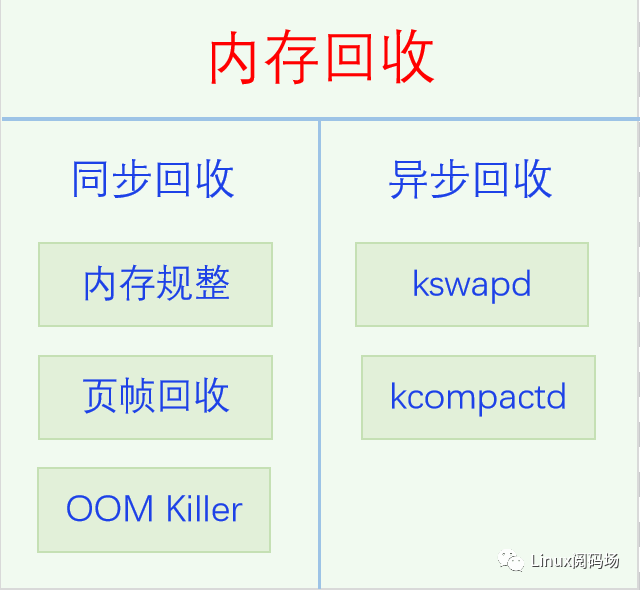
同步回收的話是在alloc_pages時(shí)發(fā)現(xiàn)內(nèi)存不足就直接進(jìn)行回收,首先嘗試的是內(nèi)存規(guī)整,也就是內(nèi)存碎片整理,比如說(shuō)系統(tǒng)當(dāng)前有10個(gè)不連續(xù)的空閑page,但是你要分配兩個(gè)連續(xù)的page,顯然是無(wú)法分配的,此時(shí)就要進(jìn)行內(nèi)存規(guī)整,通過(guò)移動(dòng)movable page,使空閑page盡量連在一起,這樣能有可能分配出多個(gè)連續(xù)的page了。如果內(nèi)存規(guī)整之后還是無(wú)法分配到內(nèi)存,此時(shí)就會(huì)進(jìn)行頁(yè)幀回收了。用戶空間的物理內(nèi)存可以分為兩種類型,文件頁(yè)和匿名頁(yè),文件頁(yè)是text data段對(duì)應(yīng)的頁(yè)幀,它們都有文件做后備存儲(chǔ),匿名是棧和堆對(duì)應(yīng)的內(nèi)存頁(yè),它們沒(méi)有對(duì)應(yīng)的文件,一般用swap分區(qū)或者swap文件做它們的后備存儲(chǔ)。系統(tǒng)會(huì)首先考慮干凈的文件頁(yè)進(jìn)行回收,因?yàn)榛厥账鼈冎灰苯觼G棄內(nèi)容就可以了,需要的時(shí)候再直接從文件里讀取回來(lái),這樣不會(huì)有數(shù)據(jù)丟失。如果沒(méi)有干凈的文件頁(yè)或者干凈的文件頁(yè)不太多,此時(shí)就要從dirty 文件頁(yè)和匿名頁(yè)進(jìn)行回收了,因?yàn)樗鼈兌家M(jìn)行IO操作,所以會(huì)非常的慢。如果頁(yè)幀回收也回收不到內(nèi)存的話,內(nèi)核只能使出最后一招了,OOM Killer,直接殺進(jìn)程進(jìn)行內(nèi)存回收,雖然這招好像不太文雅,但是也是沒(méi)有辦法,因?yàn)椴贿@樣做的話,系統(tǒng)沒(méi)有多余的內(nèi)存就沒(méi)法繼續(xù)運(yùn)行,系統(tǒng)就會(huì)卡死,用戶就會(huì)重啟系統(tǒng),結(jié)果更糟,所以殺進(jìn)程也是最后的無(wú)奈之舉。一般能走到這一步都是因?yàn)檫M(jìn)程有長(zhǎng)期或者嚴(yán)重的內(nèi)存泄漏導(dǎo)致的。 異步回收線程kswapd是被周期性的喚醒來(lái)執(zhí)行回收任務(wù)的,當(dāng)然同步回收的時(shí)候也會(huì)順便喚醒它來(lái)一起回收內(nèi)存。有一點(diǎn)需要注意的是kswapd線程不是per CPU的,而是per node的,是一個(gè)NUMA節(jié)點(diǎn)一個(gè)線程,這是因?yàn)閮?nèi)存的分配是per node不是 per CPU的,大部分內(nèi)存分配都是優(yōu)先從本node分配或者只能從本node分配,因此哪個(gè)node的內(nèi)存不足了就喚醒哪個(gè)node的kswapd線程就行內(nèi)存回收工作。對(duì)于家庭電腦和手機(jī)來(lái)說(shuō)都是一個(gè)node,所以一般就只有一個(gè)kswapd線程。Kswapd完成回收工作之后,它會(huì)喚醒kcompactd線程進(jìn)行內(nèi)存規(guī)整,對(duì)的,內(nèi)存規(guī)整也可以異步執(zhí)行。
5.OOM基本原理
在講內(nèi)核的OOM Killer之前,我們先來(lái)說(shuō)一下OOM基本概念。OOM,out of memory,就是內(nèi)存用完了耗盡了的意思。OOM分為虛擬內(nèi)存OOM和物理內(nèi)存OOM,兩者是不一樣的。虛擬內(nèi)存OOM發(fā)生在用戶空間,因?yàn)橛脩艨臻g分配的就是虛擬內(nèi)存,不能分配物理內(nèi)存,程序在運(yùn)行的時(shí)候觸發(fā)缺頁(yè)異常從而需要分配物理內(nèi)存,內(nèi)核自身在運(yùn)行的時(shí)候也需要分配物理內(nèi)存,如果此時(shí)物理內(nèi)存不足了,就會(huì)發(fā)生物理內(nèi)存OOM。用戶空間虛擬內(nèi)存OOM表現(xiàn)為malloc、mmap等內(nèi)存分配接口返回失敗,錯(cuò)誤碼為ENOMEM。大家也許會(huì)想,虛擬內(nèi)存會(huì)OOM嗎,虛擬內(nèi)存那么大,對(duì)于32位進(jìn)程來(lái)說(shuō)就有3G,對(duì)于64位進(jìn)程來(lái)說(shuō)至少也得有上百G,應(yīng)有盡有,而且很多教科書上都說(shuō)的是虛擬內(nèi)存可以隨意分配,不受物理內(nèi)存的限制,事實(shí)上真的是這樣嗎,讓我們來(lái)看一看。
5.1、虛擬內(nèi)存OOM
虛擬內(nèi)存我們是不是可以隨意分配,虛擬空間有多大我們就能分配多少?事實(shí)不是這樣的。UNIX世界有個(gè)著名的哲學(xué)原理,提供機(jī)制而不是策略,對(duì)于這個(gè)問(wèn)題,Linux也提供了機(jī)制,我們可以通過(guò) /proc/sys/vm/overcommit_memory文件來(lái)選擇策略。我們有三種選擇,我們可以往這個(gè)文件里面寫入0、1、2來(lái)選擇不同的策略,這三個(gè)值對(duì)應(yīng)的宏是:
-
#define OVERCOMMIT_GUESS 0
-
#define OVERCOMMIT_ALWAYS 1
-
#define OVERCOMMIT_NEVER 2
通過(guò)宏名我們也可以大概猜出來(lái)是啥意思,下面我們一一解析一下,先從最簡(jiǎn)單的開(kāi)始,OVERCOMMIT_ALWAYS,從名字就可以看出來(lái),只要虛擬內(nèi)存空間還有富余,你malloc多少內(nèi)存就給你多少虛擬內(nèi)存,不管它物理內(nèi)存到底還夠不夠用。OVERCOMMIT_GUESS,名為GUESS,實(shí)在不好guess的,通過(guò)看代碼發(fā)現(xiàn),這個(gè)模式允許你最多分配的虛擬內(nèi)存不能超過(guò)系統(tǒng)總的物理內(nèi)存(這里說(shuō)的總物理內(nèi)存是物理內(nèi)存加swap的總和,因?yàn)?/span>swap在一定意義上也相當(dāng)于是增加了物理內(nèi)存),也就是說(shuō)一個(gè)進(jìn)程分配的總虛擬內(nèi)存可以和系統(tǒng)的總物理內(nèi)存相同,還是夠可以的。OVERCOMMIT_NEVER,這個(gè)就比較苛刻了,它像一位勤儉持家的媽媽,總是只給你勉強(qiáng)夠用的零花錢,從來(lái)不多給一分。我們來(lái)看一下它的計(jì)算過(guò)程,它先計(jì)算一個(gè)基準(zhǔn)值,默認(rèn)等于50%的物理內(nèi)存加上swap大小,然后再減去系統(tǒng)管理保留的內(nèi)存,再減去用戶管理保留的內(nèi)存,如果系統(tǒng)所有已分配的虛擬內(nèi)存大于這個(gè)值,就返回分配失敗。具體情況大家可以去看代碼:
linux-src/mm/util.c:__vm_enough_memory。
我們?cè)賮?lái)看一個(gè)這個(gè)三個(gè)宏的公共部分OVERCOMMIT,過(guò)度承諾,這個(gè)詞想表達(dá)什么含義呢,過(guò)程承諾always never guess,我們可以看出來(lái),過(guò)程承諾指的是,系統(tǒng)允許分配給你的虛擬內(nèi)存是對(duì)你的承諾,后面當(dāng)你具體用訪問(wèn)內(nèi)存的時(shí)候,是要給你分配物理內(nèi)存來(lái)實(shí)現(xiàn)對(duì)你的承諾的,那么這個(gè)承諾到底能不能實(shí)現(xiàn)呢,如果不能實(shí)現(xiàn)會(huì)怎么樣呢?
5.2、物理內(nèi)存OOM
出來(lái)混遲早是要還的,分配出去的虛擬內(nèi)存遲早是要兌現(xiàn)物理內(nèi)存的。內(nèi)核運(yùn)行時(shí)會(huì)分配物理內(nèi)存,程序運(yùn)行時(shí)也會(huì)通過(guò)缺頁(yè)異常去分配物理。如果此時(shí)沒(méi)有足夠的物理內(nèi)存,內(nèi)核會(huì)通過(guò)各種手段來(lái)收集物理內(nèi)存,比如內(nèi)存規(guī)整、回收緩存、swap等,如果這些手段都用盡了,還是沒(méi)有收集到足夠的物理內(nèi)存,那么就只能使出最后一招了,OOM Killer,通過(guò)殺死進(jìn)程來(lái)回收內(nèi)存。代碼實(shí)現(xiàn)在linux-src/mm/oom_kill.c:out_of_memory,觸發(fā)點(diǎn)在linux-src/mm/page_alloc.c:__alloc_pages_may_oom,當(dāng)使用各種方法都回收不到不到內(nèi)存時(shí)會(huì)調(diào)用out_of_memory函數(shù)。
out_of_memory函數(shù)的實(shí)現(xiàn)還是有點(diǎn)復(fù)雜,我們把各種檢測(cè)代碼和輔助代碼都去除之后,高度簡(jiǎn)化之后的函數(shù)如下:
這樣就看邏輯就很簡(jiǎn)單了,bool out_of_memory(struct oom_control *oc){select_bad_process(oc);oom_kill_process(oc, "Out of memory");}
-
1先選擇一個(gè)要?dú)⑺赖倪M(jìn)程
-
2殺死它,就是這么簡(jiǎn)單。
下面我們來(lái)分析一下select_bad_process函數(shù)的實(shí)現(xiàn):
static void select_bad_process(struct oom_control *oc){oc->chosen_points = LONG_MIN;struct task_struct *p;rcu_read_lock();for_each_process(p)if (oom_evaluate_task(p, oc))break;rcu_read_unlock();}
函數(shù)首先把chosen_points初始化為最小的Long值,這個(gè)值是用來(lái)比較所有的oom_score值,最后誰(shuí)的值最大就選中哪個(gè)進(jìn)程。然后函數(shù)已經(jīng)遍歷所有進(jìn)程,計(jì)算其oom_score,并更新chosen_points和被選中的task,有點(diǎn)類似于選擇排序。我們繼續(xù)看oom_evaluate_task函數(shù)是如何評(píng)估每個(gè)進(jìn)程的函數(shù)。
static int oom_evaluate_task(struct task_struct *task, void *arg){struct oom_control *oc = arg;long points;if (oom_unkillable_task(task))goto next;/* p may not have freeable memory in nodemask */if (!is_memcg_oom(oc) && !oom_cpuset_eligible(task, oc))goto next;if (oom_task_origin(task)) {points = LONG_MAX;goto select;}points = oom_badness(task, oc->totalpages);if (points == LONG_MIN || points < oc->chosen_points)goto next;select:if (oc->chosen)put_task_struct(oc->chosen);get_task_struct(task);oc->chosen = task;oc->chosen_points = points;next:return 0;abort:if (oc->chosen)put_task_struct(oc->chosen);oc->chosen = (void *)-1UL;return 1;}
此函數(shù)首先會(huì)跳軌所有不適合kill的進(jìn)程,如init進(jìn)程、內(nèi)核線程、OOM_DISABLE進(jìn)程等。然后通過(guò)select_bad_process算出此進(jìn)程的得分points 也就是oom_score,并和上一次的勝出進(jìn)程進(jìn)行比較,如果小的會(huì)話就會(huì)goto next 返回,如果大的話就會(huì)更新oc->chosen的task 和 chosen_points也就是目前最高的oom_score。那么oom_badness是如何計(jì)算的呢?
long oom_badness(struct task_struct *p, unsigned long totalpages){long points;long adj;if (oom_unkillable_task(p))return LONG_MIN;p = find_lock_task_mm(p);if (!p)return LONG_MIN;adj = (long)p->signal->oom_score_adj;if (adj == OOM_SCORE_ADJ_MIN ||&p->mm->flags) ||{task_unlock(p);return LONG_MIN;}points = get_mm_rss(p->mm) + get_mm_counter(p->mm, MM_SWAPENTS) +/ PAGE_SIZE;task_unlock(p);adj *= totalpages / 1000;points += adj;return points;}
oom_badness首先把unkiller的進(jìn)程也就是init進(jìn)程內(nèi)核線程直接返回LONG_MIN,這樣他們就不會(huì)被選中而殺死了,這里看好像和前面的檢測(cè)冗余了,但是實(shí)際上這個(gè)函數(shù)還被/proc/
可能很多會(huì)覺(jué)得這里講的不對(duì),和自己在網(wǎng)上的看到的邏輯不一樣,那是因?yàn)榫W(wǎng)上有很多講oom_score算法的文章都是基于2.6版本的內(nèi)核講的,那個(gè)算法比較復(fù)雜,會(huì)考慮進(jìn)程的nice值,nice值小的,oom_score會(huì)相應(yīng)的降低,也會(huì)考慮進(jìn)程的運(yùn)行時(shí)間,運(yùn)行時(shí)間越長(zhǎng),oom_score值也會(huì)相應(yīng)的降低,因?yàn)楫?dāng)時(shí)認(rèn)為進(jìn)程運(yùn)行的時(shí)間長(zhǎng)消耗內(nèi)存多是合理的。但是這個(gè)算法會(huì)讓那些緩慢內(nèi)存泄漏的進(jìn)程逃脫制裁。因此后來(lái)這個(gè)算法就改成現(xiàn)在這樣的了,只考慮誰(shuí)用的內(nèi)存多就殺誰(shuí),簡(jiǎn)潔高效。
5.3、安卓LMK簡(jiǎn)介
除了OOM Killer,Android上還開(kāi)發(fā)了low memory killer機(jī)制,我們?cè)诖艘埠?jiǎn)單介紹一下。LMK是在系統(tǒng)內(nèi)存較低時(shí)就開(kāi)始?xì)⑦M(jìn)程,而不是等到內(nèi)存不足時(shí)再殺。LMK復(fù)用了OOMKiller 的 /proc/
6.總結(jié)
Linux內(nèi)存管理是一門龐大的學(xué)問(wèn),內(nèi)存回收作為其中的一部分也是十分復(fù)雜的,我們今天給大家大概介紹了內(nèi)核的內(nèi)存回收概覽,并詳細(xì)的介紹了OOM Killer機(jī)制,也算是拋磚引玉讓大家對(duì)內(nèi)存回收有個(gè)初步的認(rèn)識(shí)。另外如果你在工作中遇到你的進(jìn)程莫名其妙掛掉了,如果你能在內(nèi)核log中找到OOM Killer的log的話(搜索 out of memory 關(guān)鍵字并過(guò)濾你的進(jìn)程名),那么你就可以快速的斷定你的是因?yàn)橄到y(tǒng)內(nèi)存不足了,而且你的進(jìn)程占用物理內(nèi)存最多,所以被殺了,此時(shí)你就有很大的理由懷疑自己的進(jìn)程內(nèi)存泄漏了,就可以開(kāi)始進(jìn)行內(nèi)存相關(guān)問(wèn)題的排查了。
原文標(biāo)題:Linux OOM 基本原理解析
文章出處:【微信公眾號(hào):Linux閱碼場(chǎng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
審核編輯:湯梓紅
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點(diǎn)僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場(chǎng)。文章及其配圖僅供工程師學(xué)習(xí)之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問(wèn)題,請(qǐng)聯(lián)系本站處理。
舉報(bào)投訴
-
Linux
+關(guān)注
關(guān)注
87文章
11226瀏覽量
208920 -
計(jì)算機(jī)
+關(guān)注
關(guān)注
19文章
7419瀏覽量
87712 -
內(nèi)存
+關(guān)注
關(guān)注
8文章
2999瀏覽量
73882
原文標(biāo)題:Linux OOM 基本原理解析
文章出處:【微信號(hào):LinuxDev,微信公眾號(hào):Linux閱碼場(chǎng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
Linux的內(nèi)存管理是什么,Linux的內(nèi)存管理詳解
Linux的內(nèi)存管理 Linux的內(nèi)存管理是一個(gè)非常復(fù)雜的過(guò)程,主要分成兩個(gè)大的部分:內(nèi)核的
Linux內(nèi)存管理之頁(yè)面回收
請(qǐng)求調(diào)頁(yè)機(jī)制,只要用戶態(tài)進(jìn)程繼續(xù)執(zhí)行,他們就能獲得頁(yè)框,然而,請(qǐng)求調(diào)頁(yè)沒(méi)有辦法強(qiáng)制進(jìn)程釋放不再使用的頁(yè)框。因此,遲早所有空閑內(nèi)存將被分配給進(jìn)程和高速緩存,Linux內(nèi)核的頁(yè)面回收算法(
發(fā)表于 05-19 14:09
?1063次閱讀
關(guān)于Linux內(nèi)存管理的詳細(xì)介紹
Linux內(nèi)存管理是指對(duì)系統(tǒng)內(nèi)存的分配、釋放、映射、管理、交換、壓縮等一系列操作的
發(fā)表于 03-06 09:28
?1060次閱讀
Linux內(nèi)核的內(nèi)存管理詳解
內(nèi)存管理的主要工作就是對(duì)物理內(nèi)存進(jìn)行組織,然后對(duì)物理內(nèi)存的分配和回收。但是
發(fā)表于 08-31 14:46
?740次閱讀
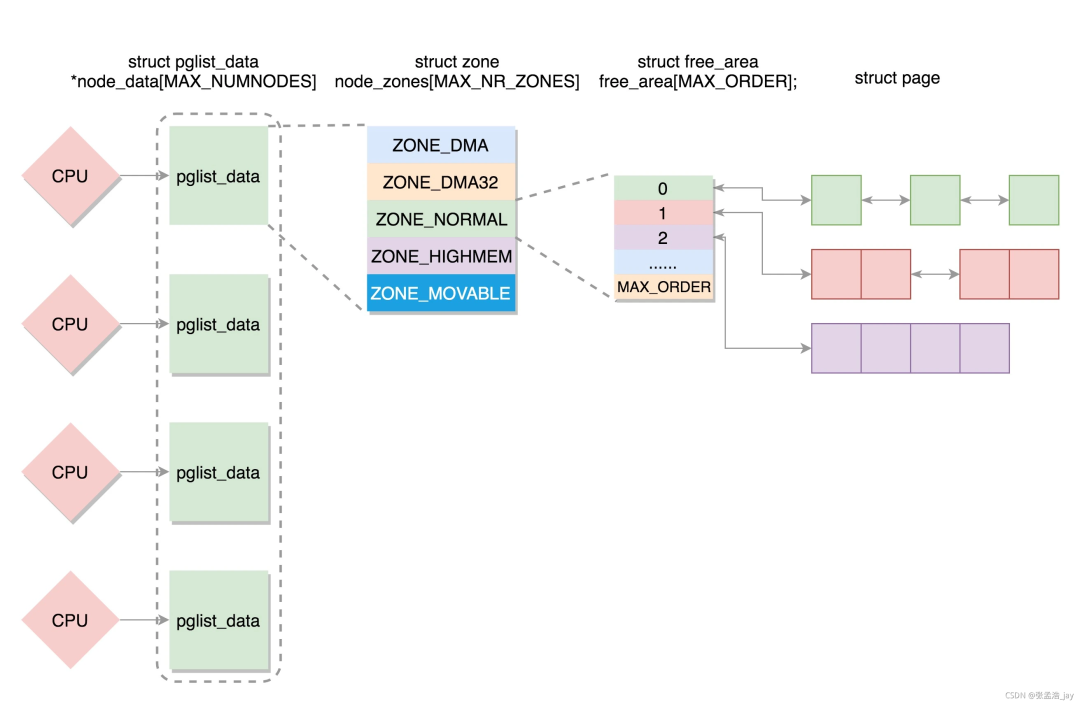
Linux內(nèi)核內(nèi)存管理架構(gòu)解析
內(nèi)存管理子系統(tǒng)可能是linux內(nèi)核中最為復(fù)雜的一個(gè)子系統(tǒng),其支持的功能需求眾多,如頁(yè)面映射、頁(yè)面分配、頁(yè)面回收、頁(yè)面交換、冷熱頁(yè)面、緊急頁(yè)面

Linux內(nèi)核內(nèi)存管理之ZONE內(nèi)存分配器
內(nèi)核中使用ZONE分配器滿足內(nèi)存分配請(qǐng)求。該分配器必須具有足夠的空閑頁(yè)幀,以便滿足各種內(nèi)存大小請(qǐng)求。
Linux內(nèi)存系統(tǒng): Linux 內(nèi)存分配算法
內(nèi)存管理算法:對(duì)討厭自己管理內(nèi)存的人來(lái)說(shuō)是天賜的禮物。1、內(nèi)存碎片1) 基本原理· 產(chǎn)生原因:內(nèi)存
發(fā)表于 08-24 07:44
Linux內(nèi)存管理中的Slab分配機(jī)制
早期Linux 的內(nèi)存分配機(jī)制采用伙伴算法, 當(dāng)請(qǐng)求分配的內(nèi)存大小為幾十個(gè)字節(jié)或幾百個(gè)字節(jié)時(shí)會(huì)產(chǎn)生內(nèi)存
發(fā)表于 04-24 10:49
?11次下載
linux內(nèi)存管理機(jī)制淺析
本內(nèi)容介紹了arm linux內(nèi)存管理機(jī)制,詳細(xì)說(shuō)明了linux內(nèi)核內(nèi)存管理,
發(fā)表于 12-19 14:09
?73次下載
LINUX源代碼分析-內(nèi)存管理
操作系統(tǒng)管理系統(tǒng)所有的物理空間, 現(xiàn)代大多數(shù)操作系統(tǒng)都采取多級(jí)管理, 即頁(yè)面級(jí)分配與內(nèi)核內(nèi)存分配。就LI
發(fā)表于 12-19 16:38
?102次下載
基于Linux內(nèi)存管理與Android內(nèi)存分配機(jī)制
Android采取了一種有別于Linux的進(jìn)程管理策略,有別于Linux的在進(jìn)程活動(dòng)停止后就結(jié)束該進(jìn)程,Android把這些進(jìn)程都保留在內(nèi)存中,直到系統(tǒng)需要更多
STM32內(nèi)存管理
內(nèi)存管理詳解1、介紹內(nèi)存管理,是指軟件運(yùn)行時(shí)對(duì)計(jì)算機(jī)內(nèi)存資源的分配和使用的技術(shù)。其最主要的目的是
發(fā)表于 12-24 19:37
?13次下載

Linux內(nèi)核引導(dǎo)內(nèi)存分配器的原理
Linux內(nèi)核引導(dǎo)內(nèi)存分配器使用的是伙伴系統(tǒng)算法。這種算法是一種用于動(dòng)態(tài)內(nèi)存分配的高效算法,它將內(nèi)存
發(fā)表于 04-03 14:52
?393次閱讀
Linux 內(nèi)存管理總結(jié)
一、Linux內(nèi)存管理概述 Linux內(nèi)存管理是指對(duì)系統(tǒng)內(nèi)存





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論