 事件模式歸納的歷史以及相關概念
事件模式歸納的歷史以及相關概念
事件模式歸納(event schema induction)是從未標記的文本中學習復雜的事件以及其論元的高級表示的一項任務[1]。事件模式歸納最早可以起源于1992年,當時是由美國DARPA資助的MUC-4會議中提出的MUC-4 scenario template task任務中提出了事件模板提取任務(event template task),該任務主要是以管道模型的方式將事件模板提取分解為字段分割和基于事件的文本分割任務[2]。
最早的事件模式自動歸納方法(automatic event schema induction)源自于Chambers and Jurafsky在2009年發布的一篇對于敘事事件模式和其論元的無監督學習的研究[3],在這篇研究中首次提出了利用文本中的類型敘事鏈來對事件模式進行自動歸納的研究方法。
由于事件模式并沒有一個統一的定義,因此存在著眾多的事件模式定義方法以及其相關的歸納方法。但是從大體上來說可以將事件模式歸納分為兩類:一種是原子事件模式歸納(Atomic Event Schema Induction),另外一種是敘事事件模式歸納(Narrative Event Schema Induction)[4]。
下面將分別按照兩種不同的事件模式歸納方法分別對其典型的研究進行介紹,最后介紹一種事件模式歸納的新思路——事件圖模式歸納。
1.原子事件模式歸納
1.1 原子事件模式歸納簡介
原子事件模式歸納重點關注于單一原子事件的事件類型以及論元。一般的原子事件模式是多個相似事件的一個模板:其中包括一個事件類型(如Elections)以及一組論元(如Date/Winner.....)。這里需要注意不同的論文中對于事件類型與論元有著不同的描述,在本文中將其統稱為事件類型和論元。一個原子事件模式的示例如圖1[5]所示。

圖1:一個選舉(Elections)的事件模式。可以看到對于多個相似的事件(圖1中的nominate、vote等),他們對應的均為事件類型為elections的事件模式,并且這些相似的事件都具有事件模式所有的五個論元(Date、Winner、Loser、Position和Vote)以及論元對應的類型。
在介紹下面的典型研究之前首先要明確幾個關鍵的語義學名詞的概念:句法功能(Syntactic Functions):句法功能是指一種語言形式和同一句型中的其他部分之間的關系,常見的句法功能有主語、謂語和賓語等.
語義角色(semantic role):謂語和論元之間不同的語義關系可以把論元分為若干個類型,這些類型一般稱之為"語義角色",如施事、受事等。
句法關系(Syntactic Relations):指句法結構的組成成分間產生的關系意義,如主謂關系、偏正關系等。
1.2典型研究
一個典型的原子事件類型歸納的研究是Nathanael Chambers和Dan Jurafsky在2013年發表的一篇關于如何在沒有預設模板的情況下進行基于模板的事件模式歸納的方法[1]。這篇文章的開創性部分在于文章著重于在無監督的情況下學習一個事件類型的事件模式結構。
對于無監督的事件模式歸納來說主要存在兩個問題:第一個是不知道語料庫中有多少個事件,第二個問題是不知道語料庫中哪些文檔描述了什么事件。作者采用了如下的三個步驟來解決這兩個關鍵問題:
首先是通過計算事件單詞之間的接近度來聚類訓練集中的事件;
其次是針對第一步生成的每一個聚類從一個不相關的語料庫中抽取文章來建立一個新的語料庫;
最后采用第二步生成的新的語料庫來歸納每一個事件模式的論元。
文章采用了MUC-4的恐怖主義語料庫(terrorism corpus of MUC-4),選擇該語料庫的原因是語料庫注釋了包含事件與相關論元的模板,在最后的性能測試中可以將生成的事件模式的結構與語料庫本身的模板結構進行比較。下面介紹作者的方法。
1.2.1 聚類訓練集中的事件
首先需要對事件進行聚類。這里采用了兩種聚類方法:LDA(隱含狄利克雷分布)和基于單詞距離的層次聚類算法(agglomerative clustering based on word distance)。
LDA我們非常熟悉的聚類方法,該算法基于事件的離散分布來學習事件的類型,基于文檔中的共現(co-occurrence)來聚類事件。 對于基于單詞距離的層次聚類算法而言,采用余弦相似性的方法來計算距離這一方法并不適用。舉例來說:引爆和摧毀屬于代表爆炸的同一聚類,但是通過余弦相似性來學習到的聚類的同義詞(clusters of synonymous words)經常不包括引爆和摧毀。因此作者假設單詞之間的接近中心性(closeness)是由單詞所在句子之間的距離來定義的,即不采用兩個事件單詞的出現頻率而考慮兩個事件單詞的出現距離。 在這里作者定義為事件單詞的出現距離(如1代表兩個單詞在同一個句子,2代表兩個單詞在相鄰的句子),下式表現基于距離的兩個單詞的頻率:
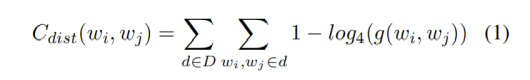
作者使用PMI分數(pointwise mutual information)對所有事件模式進行層次聚類。聚類合并的策略為兩個事件聚類間所有新鏈接間的平均鏈接得分(average link score)。當聚類中事件個數超過40個以后停止聚類。
1.2.2 構建新的語料庫
針對MUC-4沒有提供足夠的動詞以及相關語義角色的情況,作者在一個更大的不相關語料庫(美聯社和《紐約時報》上的胃腸道語料庫的一部分)上通過搜尋相關文章的方式針對每一個聚類分別來構建一個新的語料庫。
具體搜尋方法如下:第一步中對每個聚類具有多個對應的事件詞,在這里可以根據這些事件詞在這個不相關語料庫進行檢索。通過聚類的事件詞出現在文檔中的次數以及文檔中出現了幾種聚類中的事件詞進行篩選,最終得到了每一個聚類對應的語料庫(IR-corpus)。
1.2.3論元歸納
(1)聚類事件聚類對應的句法關系來表示論元:
在成功地聚類了事件詞并檢索了每個聚類的IR-corpus(指在第二步中生成的語料庫)后,我們現在需要解決論元歸納的問題。
文章考慮一種基于向量的共指相似性的方法。首先考慮聚類C,代表著事件聚類C的句法關系,具體示例如下所示:
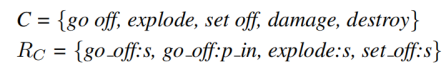
其中中的示例有如下的含義verb:s代表word是verb的主語,verb:o代表的是word賓語,p_word代表word是verb的介詞。作者希望聚類句法關系(如 set_off:s)如下所示:
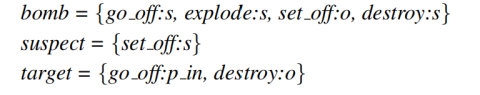
作者希望用句法關系來聚類主語、賓語和介詞,注意在語料中所有的被動語態均被轉化為主動語態。這里作者采用了關系相似性的兩種觀點:共指論元和選擇偏好(coreferring arguments and selectional preferences)。共指論元表示了兩個謂詞之間的語義聯系。
例如“他跑步和跳躍”,在這個例子中跑步和跳躍的主語均是“他”。所以“跑步”和“跳躍”很可能屬于同一特定場景的語義角色。
在這里作者將一個句法關系表示為與該句法關系具有相同論元的所有句法關系的表示。
比如go_off:s這個句法關系和plant:o, set off:o and injure:s具有相同的論元,則將go_off:s表示為這三個句法關系的向量,稱其為共指向量表示(coref vector representation)。
選擇偏好技術(SPs)在測量相似性方面也很有用[5]:一個關系可以被表示為它在訓練過程中觀察到的論元的向量。
比如對于go_off:s的選擇偏好來說包含{bomb, device, charge, explosion}。
在計算成對句法關系的相似性的時候,作者分別對成對句法關系的共指向量和成對句法關系的選擇偏好的向量計算余弦相似性分數從而進行度量。由于共指論元和選擇偏好的性質有所不同,為了更好的度量相似性,可以取兩個句法關系向量的共指向量和選擇偏好向量的余弦相似性分數的最大值(當最大值>0.7)作為其相似性度量;如果最大值小于0.7,則取兩個向量的余弦相似性分數平均值作為訓練懲罰。 (2)聚類事件的句法功能 作者同樣采用了層次聚類的方法來對上邊的成對的句法關系的相似性度量進行聚類。聚類相似性是跨越兩個聚類的所有新鏈接的平均鏈接得分score(ca,cb),對于兩個聚類和來說,如果兩個聚類之間的連接過少,則需要施加懲罰函數r(ca,cb)。懲罰函數r(ca,cb)的作用是:當兩個聚類只共享幾個評分較高的邊時將懲罰兩個聚類進行合并;當合并的聚類分數低于對訓練集性能優化的閾值時,聚類停止。
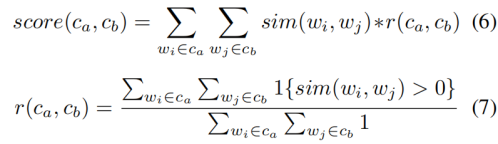
對于事件的句法功能(句法功能:如主語、賓語)和事件的語義角色來說有如下的兩個假設:第一個是對于一個動詞的主語和賓語來說承擔著不同的語義角色。
比如sell的主語是seller,而賓語是good,二者的語義角色是不同的;
第二個假設是每一個語義角色都有一個更高級別的實體類別。
比如seller的實體類別是Person/Organization,good的實體類別是Physical Object。
句法功能的聚類算法首先采用第一個假設進行約束,如果兩個聚類的并集包含同一個動詞的主語和賓語的話則防止其聚類(因為同一個動詞的主語和賓語具有不同的語義角色,那么假設聚類后含有同一個動詞的主語和賓語的話說明這兩個聚類不能進行聚類,否則合并后的聚類就會代表兩個語義角色,而不是應該的一個語義角色)。 第二個假設的實現則是對于聚類中每一個句法功能對應論元的類型對這個句法功能進行標注,這里論元的類型被簡單的分為:Person/Org, Physical Object,或Other。如果一個事件的句法功能對應的20%的論元出現在相應的同義詞集,則將這個句法功能標注為對應的論元類型。一旦標記,模型將分別為句法功能的每個論元類型分別進行聚類。
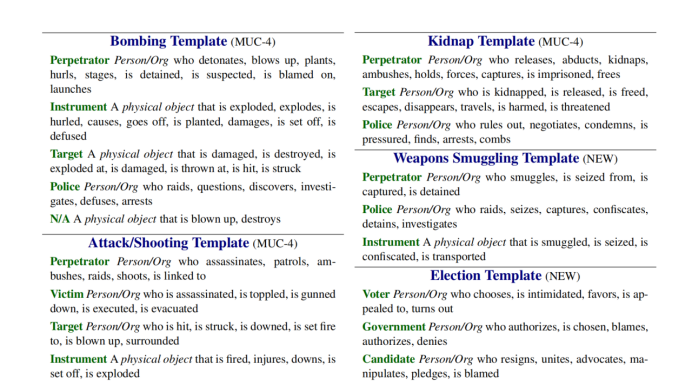
圖2:根據算法生成的MUC-4恐怖主義語料庫的部分事件模式,其中事件類型為藍色,如Election Template,事件的論元為綠色,如Voter。
1.2.4論元歸納對于事件模式歸納的測試
現在將我們學習到的模板與那些為MUC-4恐怖主義語料庫手工創建的模板進行比較。MUC-4恐怖主義語料庫共有6種事件模式,作者對于其中4種主要的事件模式進行了測評。圖3是原先的MUC-4恐怖主義語料庫包含的事件模式和論元,可以看到圖3中包含了13種相關論元,本文的事件模式歸納算法尋找出了原先13種中的12種,并且尋找出了在Bombing/Kidnap/Arson中的一種新的論元Police or Authorities。對于論元的召回率92%,準確度是14/16。

圖3:原先的MUC-4恐怖主義語料庫包含的事件模式以及論元
2.敘事事件模式歸納
2.1 敘事事件模式歸納簡介
敘事事件模式主要關注歸納敘事事件模式。一個敘事事件模式主要由一組相關事件(search/arrest/plead)、事件的時間順序(search before arrest)以及特定的語義角色(Roles:Police/Suspect......)所構成[6]。圖4是一個典型的敘事事件模式的示例[3]:

圖4:一個典型的敘事事件模式。其中在左邊的事件一列由一系列特定的語義角色(Police/Suspect/Plea/Jury)通過一系列相關的事件構成一個敘述(narrative)
最早的敘事事件模式自動歸納方法就是本文第一章中介紹的Chambers and Jurafsky在2009年發布的一篇對于敘事事件模式和其論元的無監督學習的論文[3]。下文將介紹這篇文章講述的研究方法。
2.2典型研究2.2.1先導概念——敘事事件鏈本文借鑒了Chambers and Jurafsky在2008年提出的敘事事件鏈(Narrative Event Chains)這一概念[5]。敘事事件鏈由一個元組(L,O)所構成:其中L由一系列的event slot所構成,event slot的結構是一個由v和d組成的對
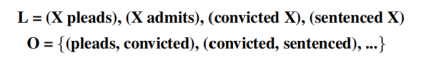
圖5:敘事事件鏈的表示
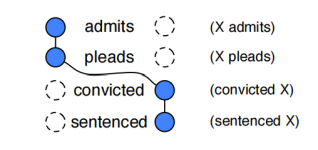
圖6:敘事事件鏈的圖示化表示
對于敘事事件鏈的生成來說,作者首先對文本進行分析和共指消解(parsing and resolving coreference in the text),隨后對進行無監督的學習來生成敘事事件鏈:首先計算在文章中有多少個成對的動詞具有共同的論元(即為圖5中的X),隨后計算這些動詞-論元對之間的PMI分數,算法通過PMI分數進行聚類從而生成敘事事件鏈。這里的敘事事件鏈僅針對于事件鏈中事件共同的論元,這里的論元指的是參與者,即主角(protagonist,如圖5中的X),而不是一種類型。
2.2.2類型敘事鏈
在Chambers and Jurafsky 2009年的研究中擴展了敘事事件鏈并提出了類型敘事鏈(Typed Narrative Chains)這一概念,相較于原先的敘事事件鏈來說,類型敘事鏈中共同的論元被替換為一種類型(如person/government)。一個典型的類型敘事鏈由一個三元組(L,P,O)所構成,其中L和O的概念與敘事事件鏈的概念一致,而新增加的P是一組表示單個角色的論元類型,類型敘事鏈的示例圖7所示:

圖7:類型敘事鏈的一般表示
如上文所述,敘事事件鏈的生成需要分析文本(parsing the text),共指消解(resolving coreference),提取具有共同參與者的事件生成敘事事件鏈。作者通過觀察event slot的數量來計算論元的數量,對共指鏈中的每一個詞建立引用集,然后用引用集中最頻繁的中心詞表示每一個論元。具體的示例如圖8所示:

圖8:一個具體的示例
對于圖8的示例來說,算法通過共指來鑒別出四個粗體的短語,并選取短語中的中心詞,隨后選取頻度最大的中心詞作為最突出的描述。
比如在圖8的示例中最突出的描述為workers,在這里這四個中心詞則成為了共指集。在示例中如果任意成對的event slot具有相同的來自共指集的論元的話,則將其計算為workers。 在圖8的示例中(X find),(X apply)具有相同類型的論元(workers,they)。因此在敘事事件鏈的歸納中((X find),(X apply))被計算,在論元歸納中((X find),(X apply),workers)被計算。
圖9是一個犯罪場景的敘事事件鏈,其中P中為犯罪場景的類型敘事鏈中所有event slot對中4個頻度最大的單詞:

圖9一個犯罪場景的類型敘事鏈,這里沒有O(事件的部分時序關系) 在敘事事件鏈中,需要計算新的event slot與原有的敘事事件鏈C中的所有的event slot的相似性,相似性的計算公式如下,其中sim
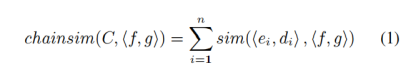
敘事事件鏈對于每一個待選的event slot進行相似性計算,選取相似性最高的event slot來加入敘事事件鏈中,對于類型敘事鏈來說也有類似的操作,只不過需要加入論元這一變量,具體方法是在特定論元a的上下文定義相似性,如下公式所示,其中freq是代表著兩個event slot中對應論元為a的數量:
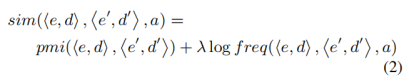
隨后采用如下的公式對整個類型敘事鏈進行評分:
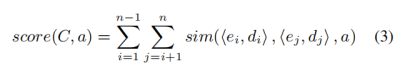
最后采用如下的公式來擴充類型敘事鏈:
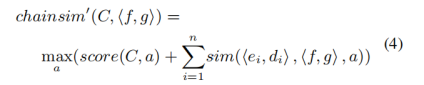
2.2.3敘事事件模式
在完成類型敘事鏈的定義與構建后,下面來定義具體的敘事事件模式。如果說敘事事件鏈是由一系列的event slot構成,那么敘事事件模式則由一系列的類型敘事鏈所表示。敘事事件模式N由一個二元組N=(E,C)所組成,其中E是一系列事件(動詞)的序列,C是一系列類型敘事鏈。一個典型的敘事事件模式如圖10所示。
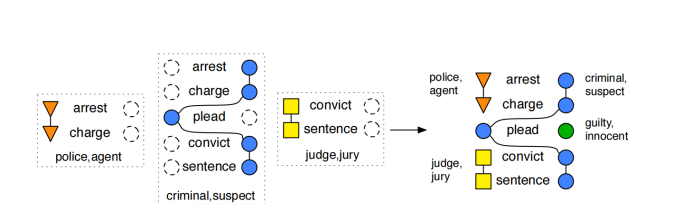
圖10:一個典型的敘事事件模式,左側是類型敘事鏈,第一個是警察的類型敘事鏈,第二個是罪犯的,第三個是法官的;右側是生成的敘事事件模式。
雖然敘事事件模式的表示為一組類型敘事鏈,但是實際上等價于如何將一個模式表示為event slot之間的約束滿足問題(constraint satisfaction problem,簡稱CSP)。敘事事件模式使用了所有動詞以及其相關論元的概括,如果一個動詞的主語和賓語都以一個較高的置信度被分配給了敘事事件模式中的敘事鏈的話,那么這個動詞就可以被分配到敘事事件模式中。
比如對于圖11中的例子來說,有可能(警察,pull over)的得分較高,但是(pull over,A)這個event slot并沒有出現在其他的敘事鏈中;假設有一個(警察,search)的event slot,同時也出現了(search,defendant)這個event slot,那么相較于pull over來說的話,search則更應該加入到敘事事件模式中。

圖11:另一個敘事事件模式的示例
這種直覺引導作者找到了構建敘事事件模式的事件關聯函數(event relatedness function)。不像構建敘事事件鏈那樣需要考慮每一個event slot是否是最合適的,在敘事事件模式中我們要考慮事件v是否在敘事事件模式的所有event slot中是合適的,事件關聯函數如下,其中CN是敘事事件模式中敘事鏈的集合:
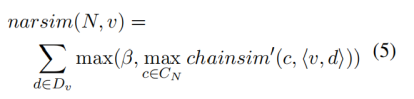
對于事件關聯函數來說,如果待選的event slot對于每一個敘事鏈的都沒有足夠的相似性的話,則為其構建一個新的敘事鏈,這個敘事鏈具有一個基礎的參數β,也就是說參數β是平衡將event slot加入已有的事件鏈或者新構建一個事件鏈的一個分水嶺。 最后對于敘事事件模式的構建來說是不斷的加入事件v,并且最大化事件關聯函數:
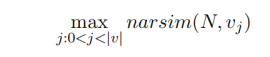
這樣就完成了整個敘事事件模式的構建。2.2.4實驗作者采用了兩種方式來對敘事事件模式進行測試:第一種是與FrameNet進行比較,作者采用了算法生成的top 20個敘事事件模式來和FrameNet在動詞分組、鏈接結構(每個論元角色與語法主語或賓語的映射)以及論元角色(構成模式角色的實體集),圖12是20個生成的敘事事件模式。

圖12:算法生成的top 20個事件模式的其中幾個實例,其中斜體字代表在FrameNet中被判別為錯誤,*號代表動詞不在FrameNet中,而-號代表動詞的詞義不在FrameNet中
在動詞分組評估中,作者首先將20個模式映射到與每個模式的六個動詞重疊最大的FrameNet框架。我們能夠將20個中的13個映射到FrameNet。13個事件模式每一個事件模式6個動詞,一共78個動詞,但是26個動詞沒有出現在FrameNet中。在剩下的52個動詞中,有35個出現在最近的FrameNet frame或在距離最近的frame有一個鏈接(one link)的frame中,剩下的17個動詞出現在不同的frame中(相較于敘事事件模式映射的frame)。 在鏈接結構評估中,主要來看為每個動詞選擇的語法關系。對于敘事事件模式中的每一個鏈,我們可以看到frame元素可以被鏈接到大多數的事件論元中。對于13個敘事事件模式中的78個動詞來說,有156個對應的主語或賓語,其中對應正確的有151個,達到了96.8%的準確率。 在論元角色的評估中,我們首先為每個論元確定最佳的frame元素。隨后我們評估(frame)論元集中top 10的論元是否適合填充角色。對于該評測來說有400個可能的論元(20個模式,每個模式2個鏈),289個被判斷正確,精度為72%。 隨后作者還進行了完形填空測試。對于敘事的完形填空測試來說,是從一個已知的敘事鏈中刪除了一個event slot。這項任務的性能排序方法是來看缺失的event slot在排好序的猜測列表中的位置。 訓練集選用Gigaword語料庫,1994-2004年的紐約時報部分的動詞和共同的論元,大約有100萬篇文章。測試集選用在Gigaword語料庫隨機抽取的100篇紐約時報的文章。實驗的結果如圖13所示。
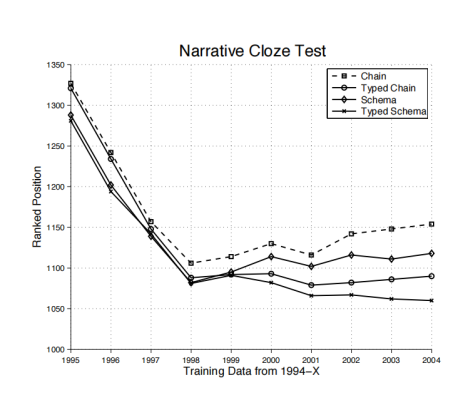
圖13:敘事完型填空的實驗結果
首先對于敘事事件鏈和類型敘事鏈進行比較,二者為圖中的”chain”和”typed chain”。可以看到隨著訓練語料的增加,敘事事件鏈的結果開始惡化(排名順序開始上升),而類型敘事鏈的結果得到了改進。 第二個是對于敘事事件鏈和敘事事件模式(采用不添加事件類型的敘事事件鏈,即采用公式1而不是采用公式5),可以看到敘事事件模式在所有的數據中都有更好的表現。最后對于敘事事件模式(采用類型敘事鏈)的進行了測試,結果顯示敘事事件模式的效果由于其余的三個,相較于效果最差的敘事事件鏈(“chain”)來說,在訓練完所有數據之后得到了10.1%的增益。 在后來的敘事事件模式的研究中,Mostafazadeh等人[7]在事件模式的事件順序上引入了因果關系,此外像時序腳本模式(temporal script graph)這樣的新思路[8]也被引入[4]。隨著相關研究的不斷創新,一些創新的事件模歸納方法也得到了研究,如下面將要介紹的事件圖模式歸納。
3.事件模式歸納的新思路——事件圖模式歸納事件模式的定義也在隨著研究不斷的進行擴展,最近的研究提出了事件實例圖和事件圖模式的概念[4],事件實例圖的基礎是假定如果出現在同一片文章中的兩個事件實例的論元是共指的或者語義相關的話,那么兩個事件實例是互相連接的。通過許多具有相同類型的事件實例對可以誘導出多條從一個事件類型到另外一個事件類型的路徑,從而形成了一種新的事件模式——事件圖模式。下面將簡要介紹一下事件圖模式歸納這一研究。圖14介紹了事件圖模式歸納的整體框架。
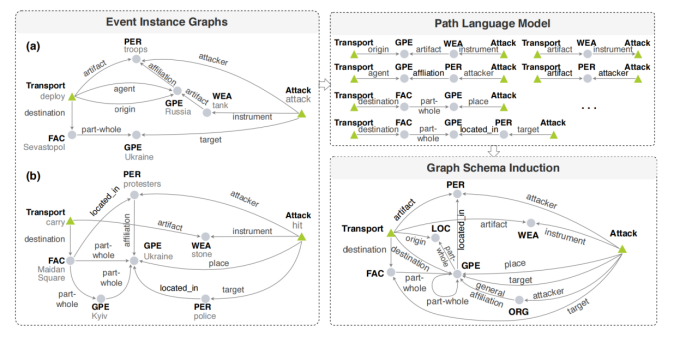
圖14:事件圖模式歸納的整體框架
對于事件圖模式的構建來說的話首先需要構建事件實例圖,首先采用OneIE工具[9]抽取文本中句子的事件以及其相關的論元。對于一個篇章中的兩個事件實例v和v’來說,構建二者之間的路徑如下所示,其中的定義是事件或者論元的類型: 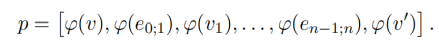 對于一個事件實例圖來說只需要將兩個事件實例生成的所有路徑進行組合即可生成事件實例圖,對于圖14中的事件實例圖(a)和(b)來說,二者均具有相同類型的事件1和事件2(事件1的類型是Transport,事件2的類型是Attack)。要想將這兩個(或者更多)的事件實例圖歸納成一個事件圖模式的話,我們需要選取兩個事件實例圖中路徑具有顯著的和語義連貫的路徑作為新的事件模式圖的路徑,因此作者提出了自回歸路徑語言模型和鄰居路徑分類的任務來解決這個問題: 對于前面生成的事件實例圖的路徑實例來說,自回歸路徑語言模型估計路徑實例中邊和節點的概率分布,模型使用Transformer來學習概率分布,通過排列操作[10]來捕捉雙向上下文,自回歸路徑語言模型的示例如圖15所示。 在路徑語言模型之上作者提出了新的任務——鄰居路徑分類:鄰居路徑是指在一個事件實例圖中的兩條路徑,如果兩條路徑不在相同的事件實例圖中的話,那么二者不是鄰居路徑。在實際的應用中作者分別創建了正采樣(鄰居路徑)和負采樣的數據(非鄰居路徑)的數據,并且采取了路徑對互相交換來提升路徑分類的一致性,從而更好的進行分類。鄰居路徑分類的示例如圖15所示。作者同時訓練這兩個方法(自回歸路徑語言模型和鄰居路徑分類)。?
對于一個事件實例圖來說只需要將兩個事件實例生成的所有路徑進行組合即可生成事件實例圖,對于圖14中的事件實例圖(a)和(b)來說,二者均具有相同類型的事件1和事件2(事件1的類型是Transport,事件2的類型是Attack)。要想將這兩個(或者更多)的事件實例圖歸納成一個事件圖模式的話,我們需要選取兩個事件實例圖中路徑具有顯著的和語義連貫的路徑作為新的事件模式圖的路徑,因此作者提出了自回歸路徑語言模型和鄰居路徑分類的任務來解決這個問題: 對于前面生成的事件實例圖的路徑實例來說,自回歸路徑語言模型估計路徑實例中邊和節點的概率分布,模型使用Transformer來學習概率分布,通過排列操作[10]來捕捉雙向上下文,自回歸路徑語言模型的示例如圖15所示。 在路徑語言模型之上作者提出了新的任務——鄰居路徑分類:鄰居路徑是指在一個事件實例圖中的兩條路徑,如果兩條路徑不在相同的事件實例圖中的話,那么二者不是鄰居路徑。在實際的應用中作者分別創建了正采樣(鄰居路徑)和負采樣的數據(非鄰居路徑)的數據,并且采取了路徑對互相交換來提升路徑分類的一致性,從而更好的進行分類。鄰居路徑分類的示例如圖15所示。作者同時訓練這兩個方法(自回歸路徑語言模型和鄰居路徑分類)。?
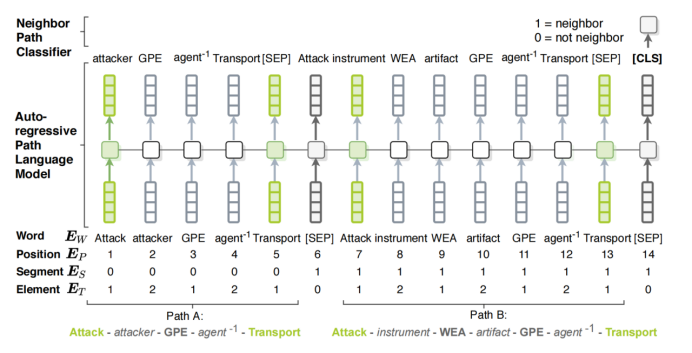
圖15:自回歸路徑語言模型和鄰居路徑分類。其中是類型嵌入,1代表節點,2代表邊,0代表其他字符,如[CLS];鄰居路徑分類中如果兩個路徑是鄰居的話則為1,不是的話則為0
在完成訓練之后,事件圖模式的生成則是對兩個事件類型之間的所有路徑進行排序,選取top k%的路徑進行融合從而生成新的事件圖模式。后續關于事件圖模式這個概念還有加入了時序關系以及多個事件類型的相關工作[11]。 4.總結
本文首先介紹了事件模式歸納的歷史以及相關概念,介紹了原子事件模式歸納以及敘事事件模式歸納的典型研究,最后介紹了事件模式歸納的新思路——事件圖模式歸納。隨著深度學習技術的不斷發展,相信事件模式歸納這一研究能夠取得更大的創新與突破。
審核編輯 :李倩
-
模板
+關注
關注
0文章
108瀏覽量
20554 -
模式
+關注
關注
0文章
65瀏覽量
13376 -
事件
+關注
關注
0文章
12瀏覽量
9919
原文標題:事件模式歸納相關研究簡述
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
SPI通信協議的基本概念和工作模式
閃測儀的精度概念解析

簡述微處理器的發展歷史
與白光干涉儀相關的精度概念都有哪些

Cortex R52內核Cache的相關概念(1)

開關模式電源基礎知識(開關模式電源術語)
計算機原碼、反碼、補碼的概念





 工商網監
工商網監
評論