") 推動處理車輛傳感器數據
推動處理車輛傳感器數據
現在還有許多其他人正在競相處理所有這些車輛傳感器數據。其中,東芝一直在發(fā)展其 Visconti 圖像識別處理器系列,以滿足日益苛刻的歐洲新車評估計劃 (Euro NCAP) 要求。
從 2014 年開始,Euro NCAP 開始根據主動安全技術對車輛進行評級,例如車道偏離警告 (LDW)、車道保持輔助 (LKA) 和自動緊急制動 (AEB)。這些要求在 2016 年擴展到日間行人 AEB 和速度輔助系統 (SAS)。2018 年,這些要求將進一步擴大,包括夜間行人 AEB,以及日間和夜間騎車人 AEB(圖 1)。

圖 1.歐洲新車評估計劃 (Euro NCAP) 的要求近年來有所擴展,包括許多高級駕駛員輔助系統 (ADAS) 功能。
為了滿足能夠在白天和夜間環(huán)境中準確識別移動和靜止物體的視覺系統的需求,東芝的 TMPV7608XBG Visconti4 處理器等圖像識別處理器采用了一套計算技術(圖 2)。除了 CPU 和 DSP 之外,8 個硬件加速模塊使設備能夠高效地執(zhí)行高度專業(yè)化的汽車計算機視覺 (CV) 工作負載,例如仿射變換(線性映射)、過濾、直方圖、匹配和金字塔圖像生成。
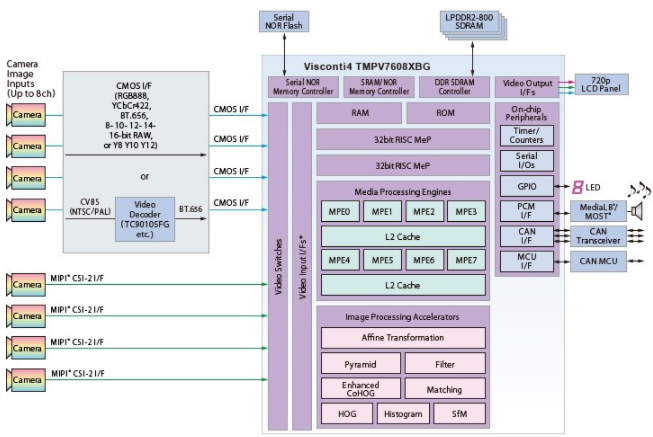
圖 2. Toshiba TMPV7608XBG Visconti4 圖像識別處理器利用 CPU、圖像處理引擎 (DSP) 和圖像處理加速器(硬件加速器)來計算一系列汽車計算機視覺 (CV) 工作負載。
TMPV7608XBG 上的兩個新硬件加速模塊專門解決了夜間和移動/靜止物體檢測的挑戰(zhàn):增強的定向梯度共現直方圖 (CoHOG) 和運動結構 (SfM) 加速器。
對于夜間 ADAS 應用,增強型 CoHOG 加速器通過結合基于亮度和顏色的特征描述符來抵消物體與其周圍環(huán)境之間的低對比度,從而超越了傳統的模式識別。據東芝稱,增強型 CoHOG 加速器不僅可以減少物體識別所需的時間,而且可以在夜間實現與白天一樣可靠的行人檢測。
同時,SfM 加速器使用來自單目相機的連續(xù)圖像來開發(fā)高度、寬度和到對象距離的三維估計(圖 3)。因此可以在沒有任何學習曲線的情況下檢測靜止物體,并且可以應用運動分析和模式識別來檢測運動物體,例如行人或車輛。由于 3D 信息減少了圖像中的感興趣區(qū)域,ADAS 系統能夠更快地識別障礙物并做出反應。
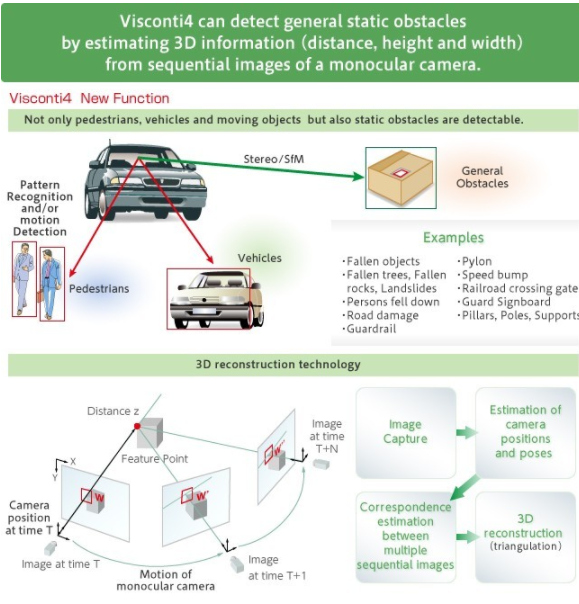
圖 3. TMPV7608XBG 的運動結構 (SfM) 加速器使用三維映射來檢測靜止和移動物體。
這些加速器與 TMPV7608XBG 的 DSP 子系統中的八個媒體處理引擎 (MPE) 一起運行,每個都配備雙精度浮點單元 (FPU)。因此,該設備可以同時并行執(zhí)行 8 個圖像識別應用程序,響應時間為 50 毫秒。以 266.7 MHz 的時鐘頻率運行,與之前的 Visconti 處理器相比,這意味著處理時間減少了 50%(圖 5)。
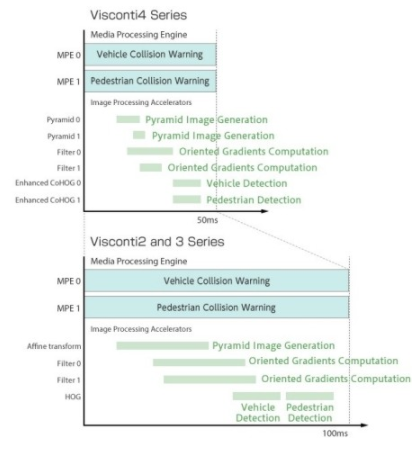
圖 5. TMPV7608XBG Visconti4 處理器的性能與上一代 Visconti 處理器相比,處理時間減少了 50%。
東芝公開的 Visconti4 圖像識別處理器設計中標包括 DENSO Corporation 的基于前置攝像頭的主動安全系統。
但圖像處理只是當今汽車安全系統中的一塊拼圖。除了攝像頭之外,現代 ADAS 應用和半自動車輛還依賴于雷達、激光雷達、接近傳感器、GPS、車聯網 (V2X) 連接和其他有源組件的輸入。來自所有這些輸入的數據必須實時處理、分析和融合,以便在危險情況下迅速采取糾正措施。
人工智能 (AI) 似乎是在自動和半自動車輛用例中執(zhí)行駕駛策略和做出實時決策的理想技術。然而,傳統的基于云的 AI 實現不適合汽車安全應用,這主要是因為與數據傳輸相關的延遲,還因為隱私、安全、成本和網絡覆蓋問題。
作為替代方案,能夠運行片上人工或深度神經網絡 (ANN/DNN) 的超級計算機級處理器正在被設計到特斯拉等汽車安全系統的電子控制單元 (ECU) 中。例如,NVIDIA 聲稱其 Drive PX Pegasus 平臺的變體將提供高達每秒 320 萬億次深度學習操作 (TOPS),這對于 5 級自動駕駛汽車來說已經足夠了。
不幸的是,這些處理器也有其自身的挑戰(zhàn)。除了相當大的功耗和單位成本外,這些芯片的裸片尺寸也很大(圖 7)。如果將每年生產的大約 1 億輛汽車中的每輛都考慮到一個這樣的處理器,那么汽車市場的需求量將是目前為智能手機生產的芯片的三倍。這遠遠超過了當前的硅晶片制造能力。
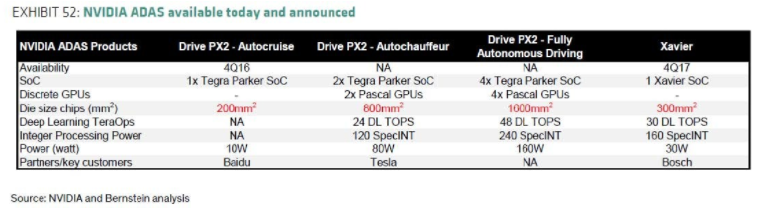
圖 7.雖然高性能處理器提供了運行片上神經網絡以實現完全自動駕駛的計算能力,但目前生產它們所需的芯片尺寸超過了硅晶圓的制造能力。資料來源:英偉達和伯恩斯坦研究。
同樣,DSP IP 模塊提供的解決方案更適合嵌入式汽車用例,CEVA 深度神經網絡 (CDNN) 就是一個例子。CDNN 包括神經網絡生成器、軟件框架和硬件加速器,專為與 CEVA-XM 成像和視覺 DSP 內核配合使用(圖 8)。這里的價值主張是降低功耗、降低成本以及在整個系統設計中分配智能的能力。
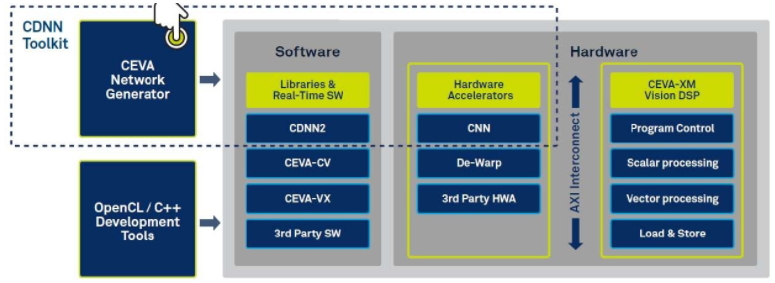
圖 8. CEVA 深度神經網絡 (CDNN) 是一個用于在嵌入式 DSP 上開發(fā)、生成和部署神經網絡的工具包。
CDNN 的核心是像 CEVA-XM6 這樣的 DSP,它包括矢量和標量處理單元以及 3D 數據處理模式。矢量和標量處理單元使 -XM6 非常適合傳感器數據融合,而其 3D 數據處理方案有助于加速神經網絡性能(圖 9)。在 CDNN 環(huán)境中,這些 DSP 配備一個或多個硬件加速器,在卷積神經網絡 (CNN) 處理中每個周期提供 512 次乘法累加 (MAC) 操作。所有其他神經網絡層——任何類型或數量——都由 DSP 本身運行。
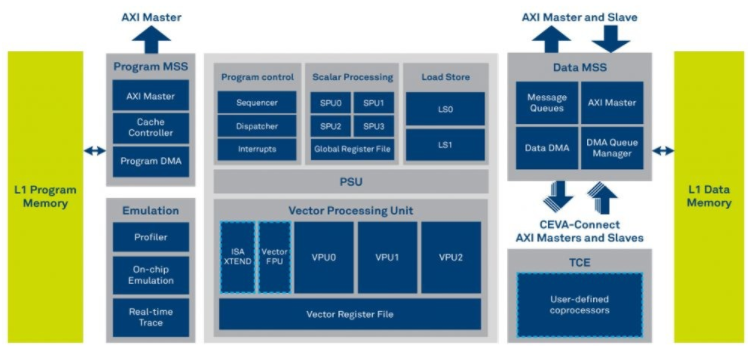
圖 9.矢量和標量處理單元與 3D 數據處理方案相結合,使 CEVA-XM6 DSP 非常適合汽車安全和人工智能工作負載。
但 CDNN 工具包的獨特之處在于 CEVA 網絡生成器。網絡生成器將在 Caffe 和 TensorFlow 等框架中開發(fā)的預訓練神經網絡轉換為可以在嵌入式系統中運行的實時神經網絡模型。從那里,第二代 CDNN 軟件框架可用于應用程序調整。
據 CEVA, Inc. 稱,CDNN 工具包處理 CNN 的速度比基于 GPU 的替代方案快四倍,能效提高 25 倍。該公司負責市場情報、投資者和公共關系的副總裁 Richard Kingston 表示,該技術目前在汽車領域獲得了超過五項設計勝利,著名的合作伙伴是安森美半導體、NEXTCHIP 以及正在使用的一級汽車 OEM它在完全自主的車輛設計中。
審核編輯:郭婷
-
傳感器
+關注
關注
2548文章
50740瀏覽量
752148 -
處理器
+關注
關注
68文章
19178瀏覽量
229202 -
半導體
+關注
關注
334文章
27063瀏覽量
216504
發(fā)布評論請先 登錄
相關推薦
工業(yè)傳感器如何實現數據采集?
汽車傳感器的功能與種類
傳感器的數據怎么傳到云平臺
車載傳感器網絡是什么意思啊
車載傳感器主要有哪些傳感器
汽車橫擺率傳感器的功能重要性
溫度傳感器的常見故障及處理方法
傳感器數據采集平臺是什么
為堅固耐用型車輛的控制機構選擇和應用線性位置傳感器

CMOS圖像傳感器的制造工藝





 工商網監(jiān)
工商網監(jiān)
評論