 Transformer模型結構,訓練過程
Transformer模型結構,訓練過程
導讀
本文分享一篇來自哈佛大學關于Transformer的文章,作者為此文章寫了篇注解文檔,詳細介紹了模型結構,訓練過程并給出了可實現的Transformer的代碼。本文僅作為研究人員和開發者的入門版教程。
下面分享一篇實驗室翻譯的來自哈佛大學一篇關于Transformer的詳細博文。

"Attention is All You Need"[1] 一文中提出的Transformer網絡結構最近引起了很多人的關注。Transformer不僅能夠明顯地提升翻譯質量,還為許多NLP任務提供了新的結構。雖然原文寫得很清楚,但實際上大家普遍反映很難正確地實現。
所以我們為此文章寫了篇注解文檔,并給出了一行行實現的Transformer的代碼。本文檔刪除了原文的一些章節并進行了重新排序,并在整個文章中加入了相應的注解。此外,本文檔以Jupyter notebook的形式完成,本身就是直接可以運行的代碼實現,總共有400行庫代碼,在4個GPU上每秒可以處理27,000個tokens。
想要運行此工作,首先需要安裝PyTorch[2]。這篇文檔完整的notebook文件及依賴可在github[3] 或 Google Colab[4]上找到。
需要注意的是,此注解文檔和代碼僅作為研究人員和開發者的入門版教程。這里提供的代碼主要依賴OpenNMT[5]實現,想了解更多關于此模型的其他實現版本可以查看Tensor2Tensor[6] (tensorflow版本) 和 Sockeye[7](mxnet版本)
- Alexander Rush (@harvardnlp[8] or srush@seas.harvard.edu)
0.準備工作
# !pip install http://download.pytorch.org/whl/cu80/torch-0.3.0.post4-cp36-cp36m-linux_x86_64.whl numpy matplotlib spacy torchtext seaborn
內容目錄
準備工作
背景
模型結構
- Encoder和Decoder
- Encoder
- Decoder
- Attention
- Attention在模型中的應用
- Position-wise前饋網絡
- Embedding和Softmax
- 位置編碼
- 完整模型
(由于原文篇幅過長,其余部分在下篇)
訓練
- 批和掩碼
- 訓練循環
- 訓練數據和批處理
- 硬件和訓練進度
- 優化器
- 正則化
- 標簽平滑
第一個例子
- 數據生成
- 損失計算
- 貪心解碼
真實示例
- 數據加載
- 迭代器
- 多GPU訓練
- 訓練系統附加組件:BPE,搜索,平均
結果
- 注意力可視化
結論
本文注解部分都是以引用的形式給出的,主要內容都是來自原文。
1.背景
減少序列處理任務的計算量是一個很重要的問題,也是Extended Neural GPU、ByteNet和ConvS2S等網絡的動機。上面提到的這些網絡都以CNN為基礎,并行計算所有輸入和輸出位置的隱藏表示。
在這些模型中,關聯來自兩個任意輸入或輸出位置的信號所需的操作數隨位置間的距離增長而增長,比如ConvS2S呈線性增長,ByteNet呈現以對數形式增長,這會使學習較遠距離的兩個位置之間的依賴關系變得更加困難。而在Transformer中,操作次數則被減少到了常數級別。
Self-attention有時候也被稱為Intra-attention,是在單個句子不同位置上做的Attention,并得到序列的一個表示。它能夠很好地應用到很多任務中,包括閱讀理解、摘要、文本蘊涵,以及獨立于任務的句子表示。端到端的網絡一般都是基于循環注意力機制而不是序列對齊循環,并且已經有證據表明在簡單語言問答和語言建模任務上表現很好。
據我們所知,Transformer是第一個完全依靠Self-attention而不使用序列對齊的RNN或卷積的方式來計算輸入輸出表示的轉換模型。
2.模型結構
目前大部分比較熱門的神經序列轉換模型都有Encoder-Decoder結構[9]。Encoder將輸入序列映射到一個連續表示序列。
對于編碼得到的z,Decoder每次解碼生成一個符號,直到生成完整的輸出序列:。對于每一步解碼,模型都是自回歸的[10],即在生成下一個符號時將先前生成的符號作為附加輸入。
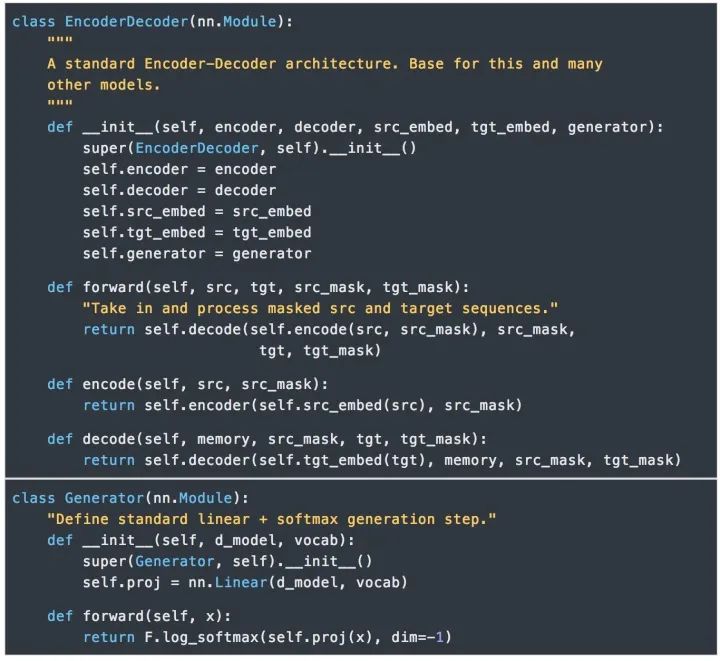
Transformer的整體結構如下圖所示,在Encoder和Decoder中都使用了Self-attention, Point-wise和全連接層。Encoder和decoder的大致結構分別如下圖的左半部分和右半部分所示。
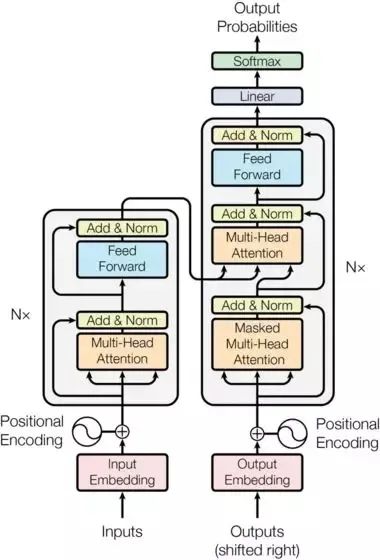
2.Encoder和Decoder
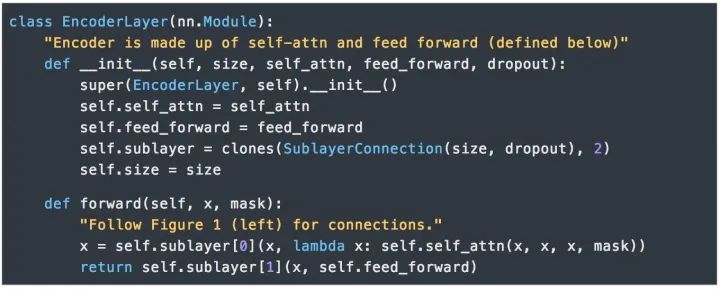
Encoder
Encoder由N=6個相同的層組成。
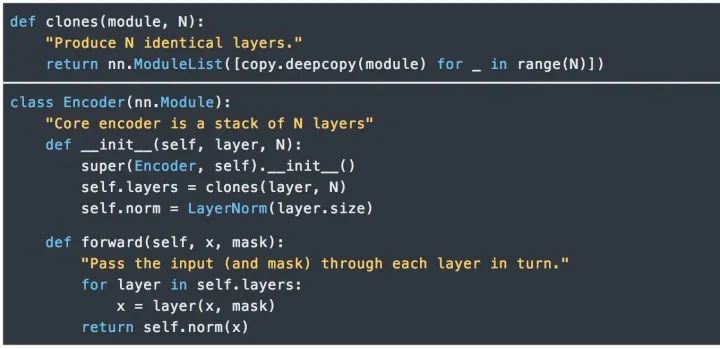
我們在每兩個子層之間都使用了殘差連接(Residual Connection) [11]和歸一化 [12]。
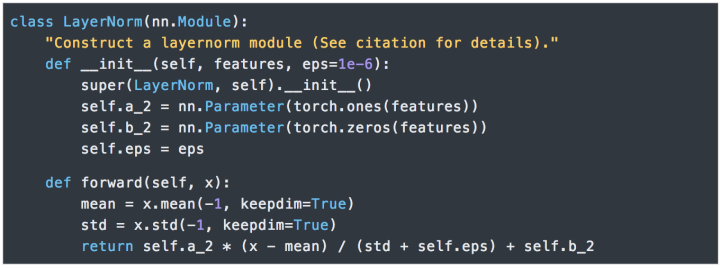

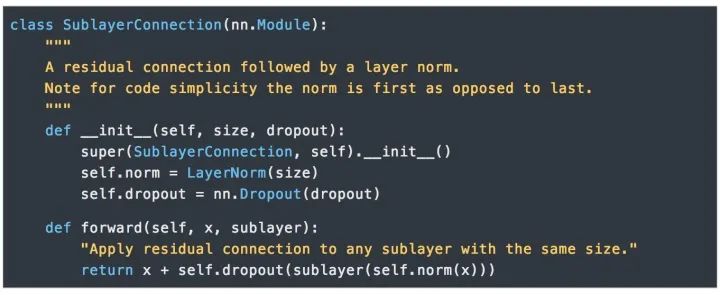
每層都有兩個子層組成。第一個子層實現了“多頭”的 Self-attention,第二個子層則是一個簡單的Position-wise的全連接前饋網絡。
Dncoder
Decoder也是由N=6個相同層組成。
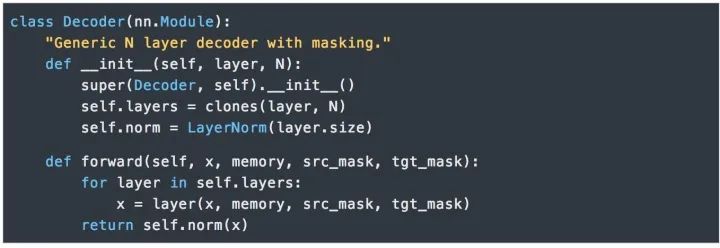
除了每個編碼器層中的兩個子層之外,解碼器還插入了第三種子層對編碼器棧的輸出實行“多頭”的Attention。與編碼器類似,我們在每個子層兩端使用殘差連接進行短路,然后進行層的規范化處理。
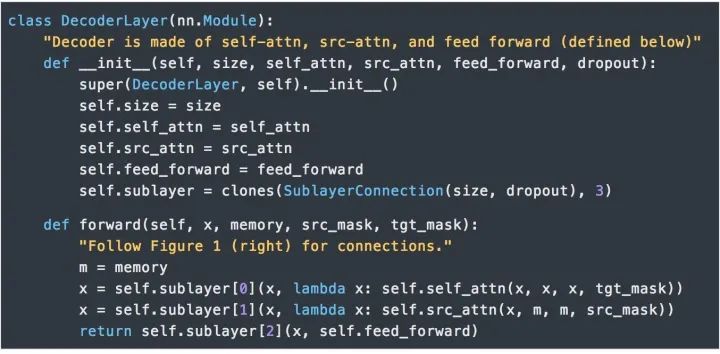
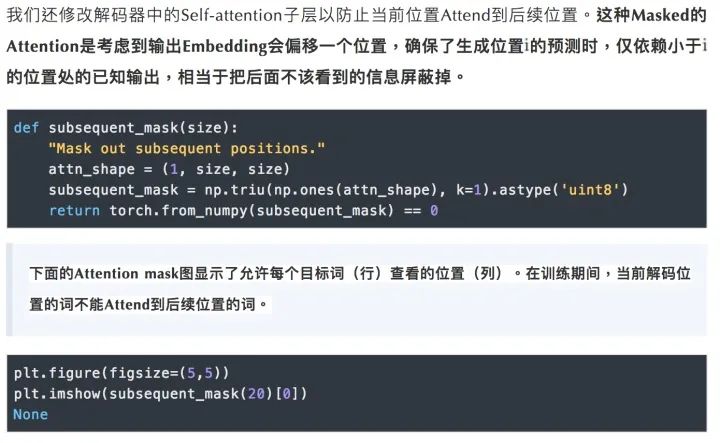
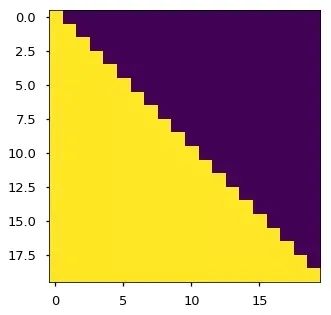
3.Attention
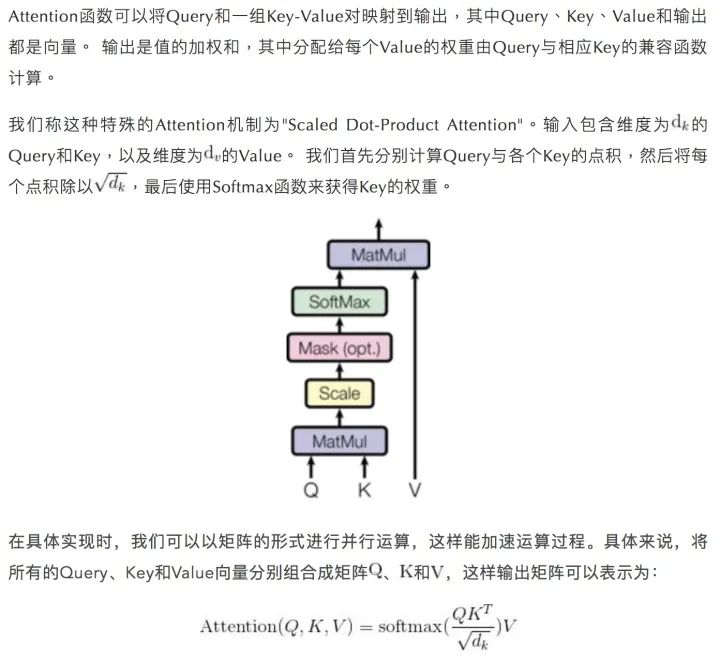

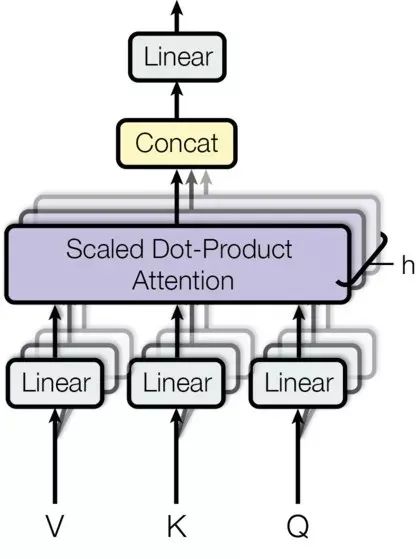
“多頭”機制能讓模型考慮到不同位置的Attention,另外“多頭”Attention可以在不同的子空間表示不一樣的關聯關系,使用單個Head的Attention一般達不到這種效果。
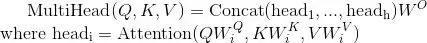

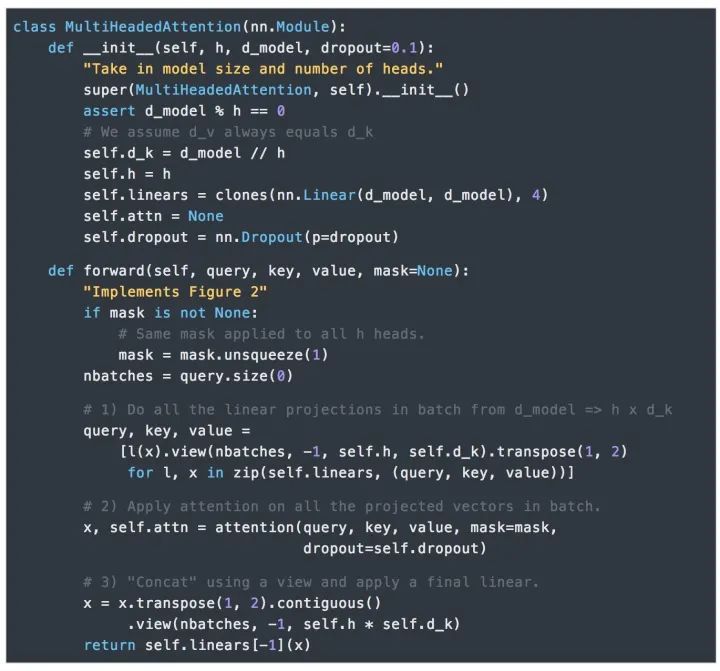
4.Attention在模型中的應用
Transformer中以三種不同的方式使用了“多頭”Attention:
1) 在"Encoder-Decoder Attention"層,Query來自先前的解碼器層,并且Key和Value來自Encoder的輸出。Decoder中的每個位置Attend輸入序列中的所有位置,這與Seq2Seq模型中的經典的Encoder-Decoder Attention機制[15]一致。
2) Encoder中的Self-attention層。在Self-attention層中,所有的Key、Value和Query都來同一個地方,這里都是來自Encoder中前一層的輸出。Encoder中當前層的每個位置都能Attend到前一層的所有位置。
3) 類似的,解碼器中的Self-attention層允許解碼器中的每個位置Attend當前解碼位置和它前面的所有位置。這里需要屏蔽解碼器中向左的信息流以保持自回歸屬性。具體的實現方式是在縮放后的點積Attention中,屏蔽(設為負無窮)Softmax的輸入中所有對應著非法連接的Value。
5.Position-wise前饋網絡

6.Embedding和Softmax

7.位置編碼

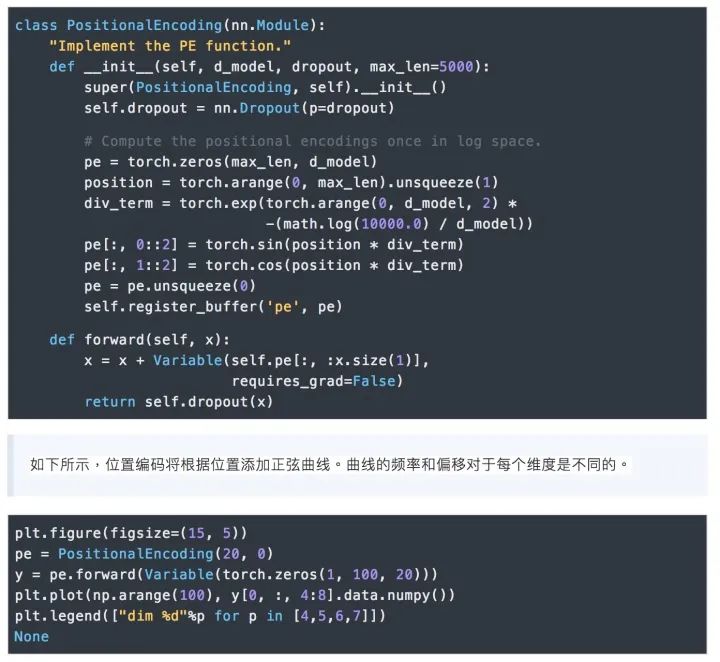
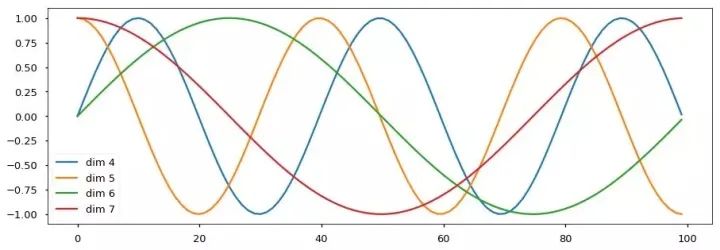
我們也嘗試了使用預學習的位置Embedding,但是發現這兩個版本的結果基本是一樣的。我們選擇正弦曲線版本的實現,因為使用此版本能讓模型能夠處理大于訓練語料中最大序了使用列長度的序列。
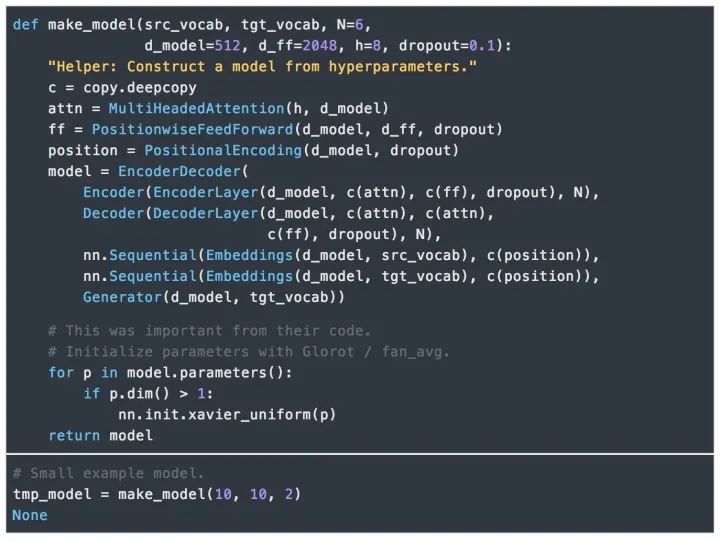
8.完整模型
下面定義了連接完整模型并設置超參的函數。
審核編輯 :李倩
-
代碼
+關注
關注
30文章
4748瀏覽量
68356 -
Transformer
+關注
關注
0文章
141瀏覽量
5982 -
pytorch
+關注
關注
2文章
803瀏覽量
13148
原文標題:搞懂Transformer結構,看這篇PyTorch實現就夠了
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何訓練ai大模型
FP8模型訓練中Debug優化思路
【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
BP神經網絡的基本結構和訓練過程





 工商網監
工商網監
評論