 基于傳統算法的OCR技術
基于傳統算法的OCR技術
文本是人類最重要的信息來源之一,自然場景中充滿了形形色色的文字符號。光學字符識別(OCR)相信大家都不陌生,就是指電子設備(例如掃描儀或數碼相機)檢查紙上打印的字符,通過檢測暗、亮的模式確定其形狀,然后用字符識別方法將形狀翻譯成計算機文字的過程。
工業場景的圖像文字識別更加復雜,出現在很多不同的場合。例如醫藥品包裝上的文字、各種鋼制部件上的文字、容器表面的噴涂文字、商店標志上的個性文字等。在這樣的圖像中,字符部分可能出現在彎曲陣列、曲面異形、斜率分布、皺紋變形、不完整等各種形式中,并且與標準字符的特征大不相同,因此難以檢測和識別圖像字符。
對于文字識別,實際中一般首先需要通過文字檢測定位文字在圖像中的區域,然后提取區域的序列特征,在此基礎上進行專門的字符識別。但是隨著CV發展,也出現很多端到端的End2End OCR。
01 基于傳統算法的OCR技術
傳統的OCR技術通常使用opencv算法庫,通過圖像處理和統計機器學習方法從圖像中提取文本信息,包括二值化、噪聲濾波、相關域分析、AdaBoost等。傳統的OCR技術根據處理方法可分為三個階段:圖像準備、文本識別和后處理。
一、圖像準備預處理:
文字區域定位:連通區域分析、MSER
文字矯正:旋轉、仿射變換
文字分割:二值化、過濾噪聲
二、文字識別:
分類器識別:邏輯回歸、SVM、Adaboost
三、后處理:規則、語言模型(HMM等)
針對簡單場景下的圖片,傳統OCR已經取得了很好的識別效果。傳統方法是針對特定場景的圖像進行建模的,一旦跳出當前場景,模型就會失效。隨著近些年深度學習技術的迅速發展,基于深度學習的OCR技術也已逐漸成熟,能夠靈活應對不同場景。
02 基于深度學習的OCR技術
目前,基于深度學習的場景文字識別主要包括兩種方法,第一種是分為文字檢測和文字識別兩個階段;第二種則是通過端對端的模型一次性完成文字的檢測和識別。
2.1 階段一:文字檢測
文字檢測定位圖片中的文本區域,而Detection定位精度直接影響后續Recognition結果。

圖1.1
如圖1.1中,紅框代表“LAN”字符ground truth(GT),綠色框代表detection box。在GT與detection box有相同IoU的情況下,識別結果差異巨大。所以Detection對后續Recognition影響非常大!
目前已經有很多文字檢測方法,包括:EAST/CTPN/SegLink/PixelLink/TextBoxes/TextBoxes++/TextSnake/MSR/...,具體來說:
2.1.1 CTPN [1]
CTPN是ECCV 2016提出的一種文字檢測算法,由Faster RCNN改進而來,結合了CNN與LSTM深度網絡,其支持任意尺寸的圖像輸入,并能夠直接在卷積層中定位文本行。
CTPN由檢測小尺度文本框、循環連接文本框、文本行邊細化三個部分組成,具體實現流程為:
1、使用VGG16網絡提取特征,得到conv5_3的特征圖;
2、在所得特征圖上使用3*3滑動窗口進行滑動,得到相應的特征向量;
3、將所得特征向量輸入BLSTM,學習序列特征,然后連接一個全連接FC層;
最后輸出層輸出結果。
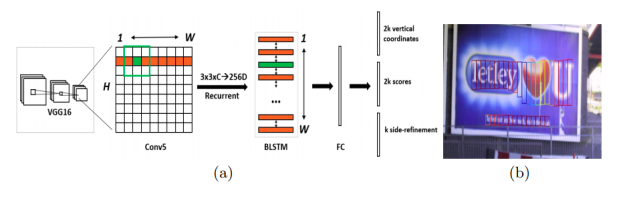
CTPN是基于Anchor的算法,在檢測橫向分布的文字時能得到較好的效果。此外,BLSTM的加入也進一步提高了其檢測能力。
2.1.2 TextBoxes/TextBoxes++ [2,3]
TextBoxes和TextBoxes++模型都來自華中科技大學的白翔老師團隊,其中TextBoxes是改進版的SSD,而TextBoxes++則是在前者的基礎上繼續擴展。
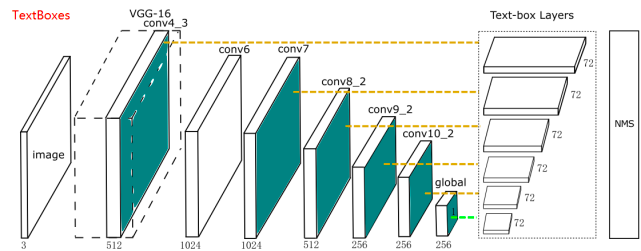
TextBoxes共有28層卷積,前13層來自于VGG-16(conv_1到conv4_3),后接9個額外的卷積層,最后是包含6個卷積層的多重輸出層,被稱為text-box layers,分別和前面的9個卷積層相連。由于這些default box都是細長型的,使得box在水平方向密集在垂直方向上稀疏,從而導致該模型對水平方向上的文字檢測結果較好。
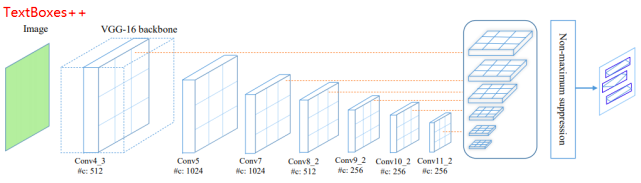
TextBoxes++保留了TextBoxes的基本框架,只是對卷積層的組成進行了略微調整,同時調整了default box的縱橫比和輸出階段的卷積核大小,使得模型能夠檢測任意方向的文字。
2.1.3 EAST [4]
EAST算法是一個高效且準確的文字檢測算法,僅包括全卷積網絡檢測文本行候選框和NMS算法過濾冗余候選框兩個步驟。
其網絡結構結合了HyperNet和U-shape思想,由三部分組成:
特征提取:使用PVANet/VGG16提取四個級別的特征圖;
特征合并:使用上采樣、串聯、卷積等操作得到合并的特征圖;
輸出層:輸出單通道的分數特征圖和多通道的幾何特征圖。
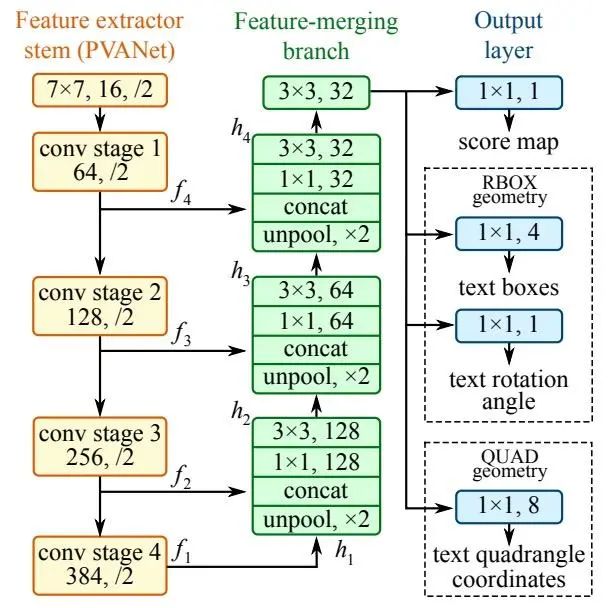
EAST算法借助其獨特的結構和簡練的pipline,可以檢測不同方向、不同尺寸的文字且運行速度快,效率高。
2.2 階段二:文字識別
通過文字檢測對圖片中的文字區域進行定位后,還需要對區域內的文字進行識別。針對文字識別部分目前存在幾種架構,下面將分別展開介紹。
3.2.1 CNN + softmax [5]
此方法主要用于街牌號識別,對每個字符識別的架構為:先使用卷積網絡提取特征,然后使用N+1個softmax分類器對每個字符進行分類。具體流程如下圖所示:
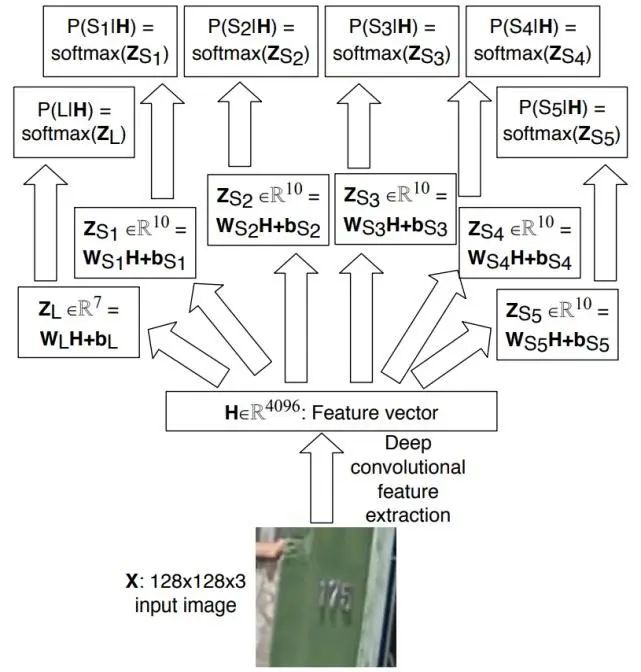
使用此方法可以處理不定長的簡單文字序列(如字符和字母),但是對較長的字符序列識別效果不佳。
3.2.2 CNN + RNN + attention [6]
本方法是基于視覺注意力的文字識別算法。主要分為以下三步:
模型首先在輸入圖片上運行滑動CNN以提取特征;
將所得特征序列輸入到推疊在CNN頂部的LSTM進行特征序列的編碼;
使用注意力模型進行解碼,并輸出標簽序列。
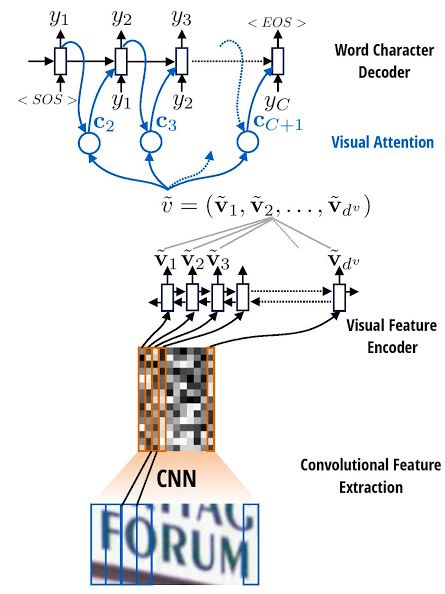
本方法采用的attention模型允許解碼器在每一步的解碼過程中,將編碼器的隱藏狀態通過加權平均,計算可變的上下文向量,因此可以時刻讀取最相關的信息,而不必完全依賴于上一時刻的隱藏狀態。
3.2.3 CNN + stacked CNN + CTC [7]
上一節中提到的CNN + RNN + attention方法不可避免的使用到RNN架構,RNN可以有效的學習上下文信息并捕獲長期依賴關系,但其龐大的遞歸網絡計算量和梯度消失/爆炸的問題導致RNN很難訓練。基于此,有研究人員提出使用CNN與CTC結合的卷積網絡生成標簽序列,沒有任何重復連接。
這種方法的整個網絡架構如下圖所示,分為三個部分:
注意特征編碼器:提取圖片中文字區域的特征向量,并生成特征序列;
卷積序列建模:將特征序列轉換為二維特征圖輸入CNN,獲取序列中的上下文關系;
CTC:獲得最后的標簽序列。
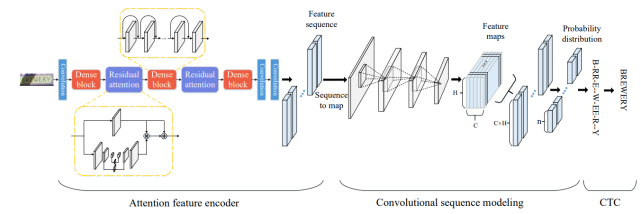
本方法基于CNN算法,相比RNN節省了內存空間,且通過卷積的并行運算提高了運算速度。
3.2.4 特定的彎曲文本行識別
對于特定的彎曲文本行識別,早在CVPR2016就已經有了相關paper:
Robust Scene Text Recognition with Automatic Rectification. CVPR2016.
論文地址:arxiv.org/abs/1603.03915
對于彎曲不規則文本,如果按照之前的識別方法,直接將整個文本區域圖像強行送入CNN+RNN,由于有大量的無效區域會導致識別效果很差。所以這篇文章提出一種通過STN網絡學習變換參數,將Rectified Image對應的特征送入后續RNN中識別。
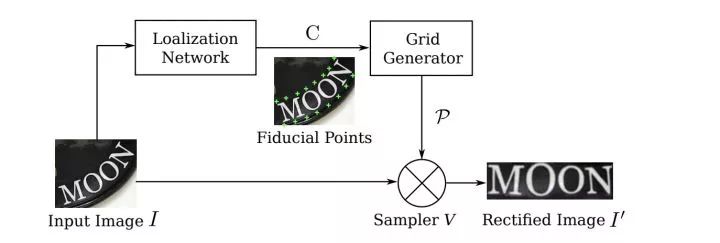
其中Spatial Transformer Network(STN)核心就是將傳統二維圖像變換(如旋轉/縮放/仿射等)End2End融入到網絡中。具體二維圖像變換知識請翻閱:Homograph單應性從傳統算法到深度學習:https://zhuanlan.zhihu.com/p/74597564
Scene Text Recognition from Two-Dimensional Perspective. AAAI2018.
該篇文章于MEGVII 2019年提出。首先在文字識別網絡中加入語義分割分支,獲取每個字符的相對位置。
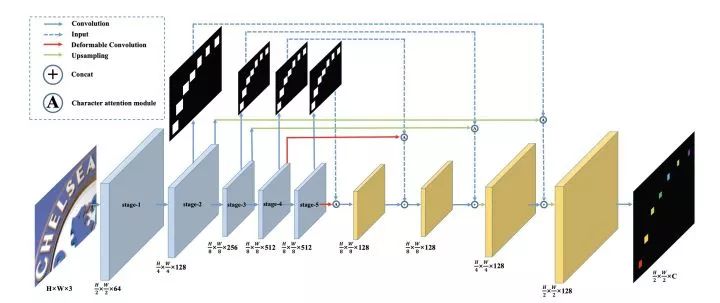
其次,在獲取每個字符位置后對字符進行分類,獲得文字識別信息。該方法采用分類解決識別問題,并沒有像傳統方法那樣使用RNN。

除此之外,在文章中還是使用了Deformable Convolution可變形卷積。相比傳統3x3卷積,可變形卷積可以提取文字區域不同形狀的特征。

3.3 端對端文字識別
使用文字檢測加文字識別兩步法雖然可以實現場景文字的識別,但融合兩個步驟的結果時仍需使用大量的手工知識,且會增加時間的消耗,而端對端文字識別能夠同時完成檢測和識別任務,極大的提高了文字識別的實時性。
3.3.1 STN-ORC [8]
STN-OCR使用單個深度神經網絡,以半監督學習方式從自然圖像中檢測和識別文本。網絡實現流程如下圖所示,總體分為兩個部分:
定位網絡:針對輸入圖像預測N個變換矩陣,相應的輸出N個文本區域,最后借助雙線性差值提取相應區域;
識別網絡:使用N個提取的文本圖像進行文本識別。
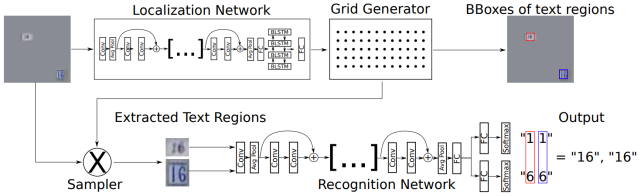
本方法的訓練集不需要bbox標注,使用友好性較高;但目前此模型還不能完全檢測出圖像中任意位置的文本,需要在后期繼續調整。
3.3.2 FOTS [9]
FOTS是一個快速的端對端的文字檢測與識別框架,通過共享訓練特征、互補監督的方法減少了特征提取所需的時間,從而加快了整體的速度。其整體結構如圖所示:

卷積共享:從輸入圖象中提取特征,并將底層和高層的特征進行融合;
文本檢測:通過轉化共享特征,輸出每像素的文本預測;
ROIRotate:將有角度的文本塊,通過仿射變換轉化為正常的軸對齊的本文塊;
文本識別:使用ROIRotate轉換的區域特征來得到文本標簽。
FOTS是一個將檢測和識別集成化的框架,具有速度快、精度高、支持多角度等優點,減少了其他模型帶來的文本遺漏、誤識別等問題。
03 中文OCR開源項目推薦 目前比較常用的中文OCR開源項目是 chineseocr,最近又有一個新開源的中文OCR項目,登上Github Trending榜單第二——chineseocr_lite
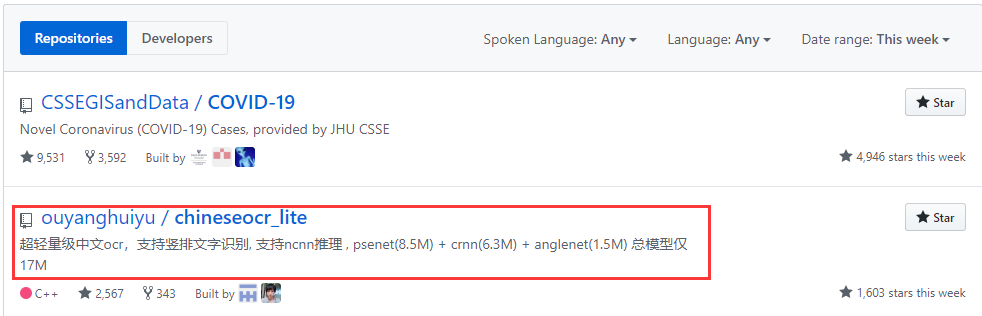
這是一個超輕量級中文 ocr,支持豎排文字識別,支持 ncnn 推理,psenet (8.5M) + crnn (6.3M) + anglenet (1.5M) 總模型僅17M。目前已經在Github上標星2.6K,累積343個Fork(Github地址:https://github.com/ouyanghuiyu/chineseocr_lite) chineseocr_lite實現的功能如下:
提供輕量的backone檢測模型psenet(8.5M),crnn_lstm_lite(9.5M) 和行文本方向分類網絡(1.5M)
任意方向文字檢測,識別時判斷行文本方向
crnncrnn_lite lstmdense識別(ocr-dense和ocr-lstm是搬運chineseocr的)
支持豎排文本識別
ncnn 實現 (支持lstm)
mnn 實現
接下來,我們再說一下chineseocr_lite的運行環境:
Ubuntu 18.04
Python 3.6.9
Pytorch 1.5.0.dev20200227+cpu
此外,最近項目作者對更新了可實現的功能。
nihui 大佬實現的 crnn_lstm 推理
升級 crnn_lite_lstm_dw.pth 模型 crnn_lite_lstm_dw_v2.pth , 精度更高
提供豎排文字樣例以及字體庫(旋轉 90 度的字體)
如果你也對這個項目感興趣就趕緊嘗試下吧。
審核編輯 :李倩
-
算法
+關注
關注
23文章
4601瀏覽量
92671 -
OpenCV
+關注
關注
30文章
628瀏覽量
41273 -
OCR
+關注
關注
0文章
144瀏覽量
16330
原文標題:OCR光學字符識別方法匯總(附開源代碼)
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
ASR與傳統語音識別的區別
ipc與傳統監控技術的比較
基于AOI視覺技術的OCR檢測方案,解鎖產品精準高效入庫新體驗!
明治案例 | 【OCR識別+條碼讀取】一步到位,印刷品質的智能守護者

光學字符識別是什么的一種技術
光學識別技術的工作原理是什么?
光學識別字符是自動識別技術嗎
明治案例 | PE編織袋【大視野】【OCR識別】

圖像識別算法都有哪些方法
神經網絡芯片與傳統芯片的區別和聯系
智能手機充電頭OCR精準識別

Zebra Aurora深度學習OCR算法榮獲CAIMRS頒發的自動化創新獎
觸摸屏用有機硅OCR的性能測試方法

EVS深度學習智能相機OCR工具性能大揭秘






 工商網監
工商網監
評論