 t770芯片怎么樣 AI Benchmark跑分看展銳5G芯片T770性能特性
t770芯片怎么樣 AI Benchmark跑分看展銳5G芯片T770性能特性
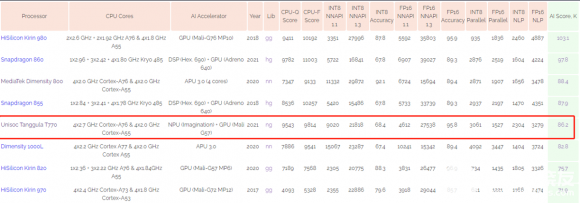
近日,AI Benchmark發布了最新Mobile SoCs推理測試結果。在這份備受AI圈關注的“戰報”中,紫光展銳5G芯片T770取得了86.2K的不俗成績。
AI Benchmark是全球權威AI性能評測平臺,由蘇黎世聯邦理工學院計算機視覺實驗室出品。這個實驗室由計算機視覺領域著名學者Luc Van Gool, 醫療影像教授Ender Konukoglu,以及計算機視覺及系統教授Fisher Yu的研究組組成,是整個歐洲乃至世界最頂尖的CV/ML研究機構之一。
AI Benchmark涵蓋了26組測試,共計78個測試子項,包括了目標識別、目標分類、人臉識別、光學字符識別、圖像超分,圖像增強、語義分割、語義增強等AI場景,從CPU、AI加速器對INT8和FP16模型的推理速度、準確性、初始化時間等數據全方位衡量平臺/設備的AI能力。因此,AI Benchmark可以從比較客觀的角度評估芯片的AI 性能。
在12個維度的測試里,共計102個測試數據,T770有超過59.8%的數據超過競品。

具體表現在圖片分類、并發場景 (量化模型)、目標檢測、文字識別、語義分割、圖像超分、圖像分割、深度估計、圖像增強、視頻超分、自動文本生成等場景 。
接下來,讓我們從幾個關鍵的測試維度看下T770 AI性能的具體表現:
|
逐項拆解之MobileNet 首先來看較為經典的MobileNet神經網絡維度。這里稍微提一下MobileNet的由來:谷歌在2017年提出了專注于移動端或者嵌入式設備中的輕量級CNN網絡,其最大的創新點是提出了深度可分離卷積。mobileNet-V2是對mobileNet-V1的改進,是一種輕量級的神經網絡。mobileNet-V2保留了V1版本的深度可分離卷積,增加了線性瓶頸(Linear Bottleneck)和倒殘差(Inverted Residual),而MobileNet-V3是谷歌基于MobileNet-V2之后的又一項力作,在精度和時間上均有提高。MobileNet-V3做了哪些修改呢?它引入了SE結構、修改了尾部結構和channel的數量,做了非線性變換的改變。MobileNet-V3提供了兩個版本,一個是mobileNet-V3 Large,也就是AI Benchmark這次測試用的版本,另一個是MobileNet-V3 Small版本,分別對應了對計算和存儲要求高與低的版本。 AI-Benchmark主要選取了V2和V3 Large兩個版本進行測試。下圖這個數據柱狀圖表達的是什么意思呢?這里包含了CPU、AI加速器分別對于量化和浮點模型的處理表現,主要從推理速度和準確性兩個維度去評估平臺/設備的AI能力,時間單位是毫秒。 灰色的柱形圖代表競品,紫色的代表T770。可以看到,在mobileNet-V2維度,T770在CPU量化、CPU浮點、加速器量化的處理上基本是優于競品的。加速器浮點上略有差距,在mobileNet-V3 Large維度,T770在CPU量化、CPU浮點、加速器浮點的處理上是優于競品的,加速器量化上略有差距,兩者數據各有千秋,從MobileNet神經網絡整體維度,T770優于競品。 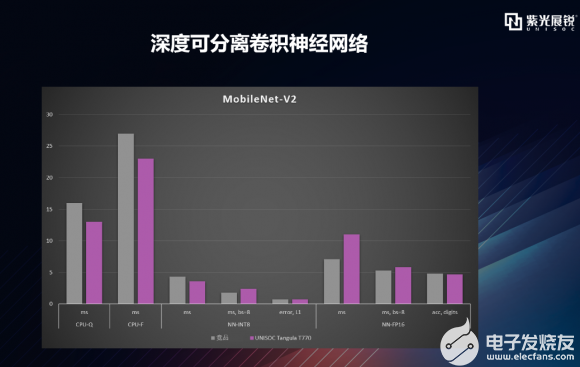 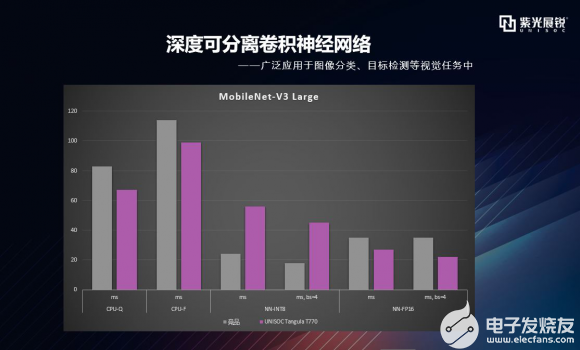 |
|
逐項拆解之Inception-V3 Inception-V3 架構的主要思想是 factorized convolutions (分解卷積) 和 aggressive regularization (激進的正則化)。可以看到,在精度基本一致的情況下,在CPU浮點、加速器量化這兩個關鍵維度上,T770運行Inception-V3的運行速度更快,加速器浮點模型數據的運行速度上略有差距,但精度略優于競品,如下圖所示: 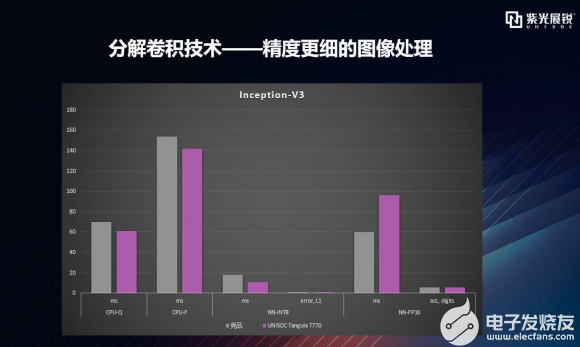 |
|
逐項拆解之EfficientNet EfficientNet是谷歌研究人員在一篇 ICML 2019 論文《EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks》中提出的一種新型模型縮放方法。可以看到,T770運行EfficientNet的表現與競品相當,在CPU浮點、加速器量化、加速器浮點模型數據的運行速度上均有優勢。 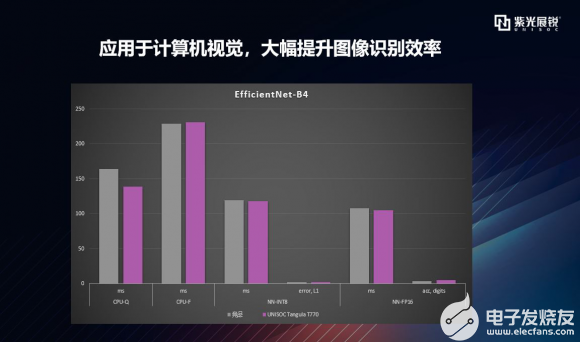 剛才提到的MobileNet、Inception-V3、EfficientNet網絡結構常用于圖像分類、目標檢測、語義分割等技術開發中。這些神經網絡結構可應用的常見場景有手機相冊中的相冊分類,手勢識別等,工業上可用于快遞分揀、頭盔檢測、頭盔識別等場景,在醫學領域會用于皮膚真菌識別等應用。當然這些神經網絡所能支撐的場景,不限于剛剛介紹到的,可利用這些AI能力開發出更多的基于對物體/事物的分類場景。 T770在這些神經網絡結構上的不俗表現表明:T770有更全面、更強大的能力去支撐這些場景的開發。 |
|
逐項拆解之Inception-V3 Parallel 接下來再看Inception-V3 Parallel (NN-INT8),你肯定會想,怎么又來一個Inception-V3,剛才不是show過了?是重復了嗎?搞錯了嗎?當然沒有!這里介紹的是Inception-V3 Parallel的能力,即同時處理多個Inception-V3,對應的是平臺/設備對于AI并發處理的能力,怎么去理解這個并發處理呢?舉個栗子吧,哦,今天忘記帶栗子了,不好意思(╯▽╰)。 簡單來講,就是應用程序同時下發多個任務處理,再簡單點講就是,同時在做兩件事情或多件事情,比如圖片分類和手勢識別同時進行。還不明白?再簡單點,就好比人在吃飯的同時刷抖音短視頻。 OK,我們來看下具體數據,下圖顯示的是AI加速器對1/2/4/8個量化模型同時處理的能力,可以明顯看到,T770在AI多任務處理能力上占有明顯優勢。 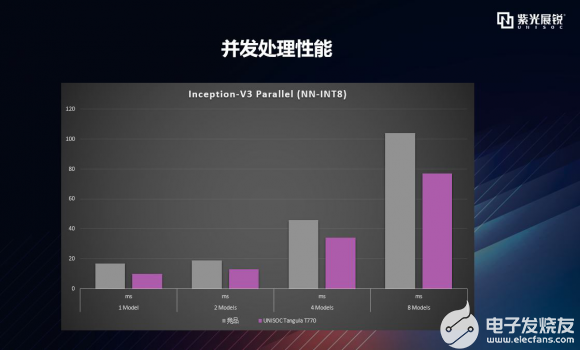 |
|
逐項拆解之Yolo-v4 Tiny 我們再看Yolo-V4 Tiny結構,它是Yolo-V4的精簡版,屬于輕量化模型,參數只有600萬,相當于原來的十分之一,這使檢測速度有了很大提升,非常有利于在端側進行部署,在智能安防領域中已有大量應用,比如車輛識別、人員識別、路徑預測和跟蹤、行為分析、安全帽識別等。 先看下具體數據,如下圖,除加速器量化模型部分略有不足之外,其他均有優勢,如CPU量化、浮點,加速器浮點等。 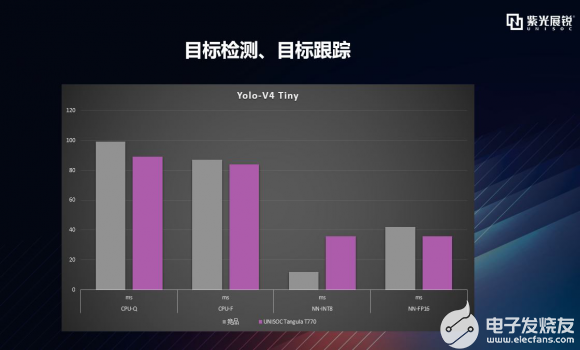 |
|
逐項拆解之DPED – ResNet 再看一下T770在DPED - ResNet處理維度的表現,解釋一下,DPED是DSLR Photo Enhancement Dataset,而DSLR指的是Digital Single Lens Reflex Camera,即數碼單反相機。講到這一點,不得不提到一篇論文《DSLR-Quality Photos on Mobile Devices with Deep Convolutional Networks》,這是一篇發布于2017年關于圖像增強的神經網絡論文,大概成果就是將手機照片作為輸入,將DSLR相機拍出的照片作為target,通過網絡使其學習到一個映射函數,目的是讓手機拍出單反相機照片的效果。 基于DPED,我們可以將老舊或低質量的照片轉化為高質量的照片,而且轉化效果很好,可用于照片美化等應用場景。如下圖,可以看到T770在對DPED - ResNet處理的錯誤率一致的情況下,錯誤率都很低,處理速度上有明顯優勢。 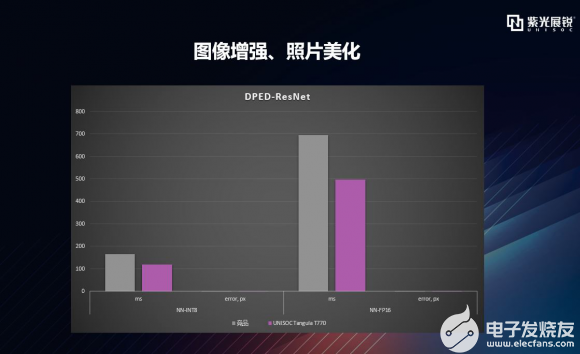 |
|
逐項拆解之LSTM 接下來,我們再看一下T770在長短期記憶網絡(Long-Short Term Memory,LSTM)方面的性能。由于獨特的設計結構,LSTM適合處理和預測時間序列中間隔和延遲非常長的重要事件。LSTM的表現通常比時間遞歸神經網絡及隱馬爾科夫模型(HMM)更好,比如用在不分段連續手寫識別上。 2009年,用LSTM構建的人工神經網絡模型贏得ICDAR手寫識別比賽冠軍。LSTM還普遍應用在自主語音識別,2013年,運用TIMIT自然演講數據庫實現了17.7%錯誤率紀錄。作為非線性模型,LSTM可作為復雜的非線性單元,用于構造更大型深度神經網絡。 下圖可以看到,T770在對LSTM處理的錯誤率一致的情況下,處理速度上有著明顯優勢。 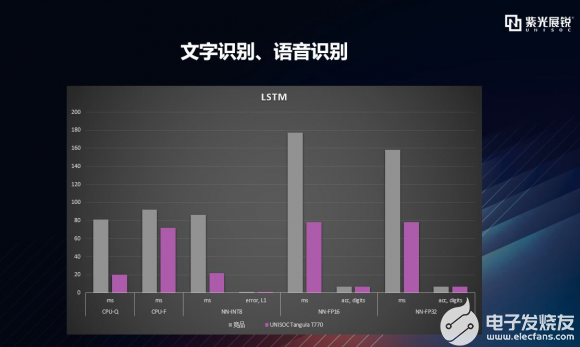 |
|
逐項拆解之U-Net U-Net是比較早的使用全卷積網絡進行語義分割的算法之一,因網絡形狀酷似U而得名。圖像語義分割(Semantic Segmentation)是圖像處理和機器視覺技術中,關于圖像理解的重要一環,也是 AI 領域中一個重要的分支。語義分割對圖像中每一個像素點進行分類,確定每個點的類別(如屬于背景、人或車等),從而進行區域劃分。目前,語義分割已經被廣泛應用于自動駕駛、無人機落點判定等場景中。U-Net在醫學領域也得到了應用,比如醫學圖像解析,也就是從一副醫療圖像中,識別出特定的人體部位,比方說“前列腺”、“肝臟”等等。 下圖可以看到,T770和競品對U-net處理的錯誤率都極低,而T770在擁有極低錯誤率的同時,處理速度明顯占優。 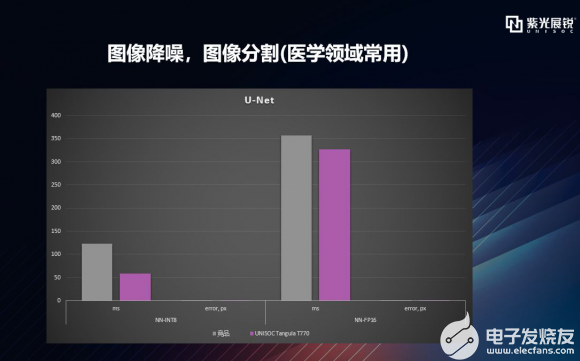 |
好了,數據對比分析先講這么多,大家如果對T770在其他AI場景下的性能數據感興趣,可前往AI Benchmark官網自行查看。
以上可以看到,T770有著不俗的AI性能,可以助力用戶在相冊分類、物體分類、智能美圖、背景虛化、渲染、語音助手、智能家居、車牌識別,人臉識別、視頻超分辨率應用場景中的落地實施,并且在滿足常見CV/NLP應用場景下,可以同時滿足實時、高并發的AI場景需求,如車牌識別、人臉識別等。
看罷T770的AI性能精彩展現,你是否會有疑問,T770是如何做到在AI上大放異彩的呢?下面我們來簡單介紹下。
T770擁有多個可用于AI加速的設備,當然,有時候你擁有的資源越多,并不是一件好事,因為對資源的識別、管理和調度,會是一件極其困難的事情。所以,如何使T770上多個AI加速設備協同合作,并發揮出最大效能成為我們技術研發最主要的挑戰。
大家都知道三個和尚挑水喝的故事:一個和尚挑水喝,兩個和尚抬水喝,三個和尚沒水喝。
故事很簡單,道理也很簡單,借這個故事,這里想表達的是三個核心問題:
一、任務來了,誰能干?
二、任務來了,誰來干更合適?
三、安排好活了,干活的是否積極?
為了解決上述問題,紫光展銳開發了兩大核心技術:
1)Smart Schedule :采用智能算法,精準識別每個AI任務最適合在哪個加速器里進行處理,然后進行分配,使其隨才器使;
2)Device Boost:采用智能調節算法,根據推理任務大小,智能調節加速器負載,使其張弛有度。
得益于紫光展銳開發的這兩大核心技術,T770在AI性能上大放異彩,AI多變場景下,可以助力用戶實現豐富的AI場景化落地。
而且,紫光展銳將持續針對多種AI場景進行優化,屆時,T770的AI性能將得到更大提升,創新不止,敬請期待!
注:本文測試數據來源于AI Benchmark官網發布
-
AI
+關注
關注
87文章
28818瀏覽量
266157 -
5G芯片
+關注
關注
5文章
498瀏覽量
43206 -
紫光展銳
+關注
關注
15文章
834瀏覽量
40199 -
T770
+關注
關注
0文章
1瀏覽量
362
發布評論請先 登錄
相關推薦
紫光展銳全面擁抱Android 15,多款芯片平臺實現同步升級
紫光展銳5G系列移動通信芯片順利通過Telcel技術測試
紫光展銳5G芯片通過墨西哥運營商Telcel測試
平板電腦定制_紫光展銳T610|T618|T770國產平板方案定制開發


搭載紫光展銳5G芯片T760的中興云電腦逍遙系列正式發布
紫光展銳發布業界首款全面支持5G R16寬帶物聯網特性的芯片平臺V620



內置紫光展銳T820 5G芯 天翼鉑頓S9 5G衛星雙模手機上市


紫光展銳攜手中國聯通5G物聯網OPENLAB實驗室,完成RedCap芯片V517聯合孵化測試






 工商網監
工商網監
評論