 一種新方法GSConv來減輕模型的復雜度并保持準確性
一種新方法GSConv來減輕模型的復雜度并保持準確性
目標檢測是計算機視覺中一項艱巨的下游任務。對于車載邊緣計算平臺,大模型很難達到實時檢測的要求。而且,由大量深度可分離卷積層構建的輕量級模型無法達到足夠的準確性。因此本文引入了一種新方法 GSConv 來減輕模型的復雜度并保持準確性。GSConv 可以更好地平衡模型的準確性和速度。并且,提供了一種設計范式,Slim-Neck,以實現檢測器更高的計算成本效益。在實驗中,與原始網絡相比,本文方法獲得了最先進的結果(例如,SODA10M 在 Tesla T4 上以 ~100FPS 的速度獲得了 70.9% mAP0.5)。
1簡介
目標檢測是無人駕駛汽車所需的基本感知能力。目前,基于深度學習的目標檢測算法在該領域占據主導地位。這些算法在檢測階段有兩種類型:單階階段和兩階段。兩階段檢測器在檢測小物體方面表現更好,通過稀疏檢測的原理可以獲得更高的平均精度(mAP),但這些檢測器都是以速度為代價的。單階段檢測器在小物體的檢測和定位方面不如兩階段檢測器有效,但在工作上比后者更快,這對工業來說非常重要。
類腦研究的直觀理解是,神經元越多的模型獲得的非線性表達能力越強。但不可忽視的是,生物大腦處理信息的強大能力和低能耗遠遠超出了計算機。無法通過簡單地無休止地增加模型參數的數量來構建強大的模型。輕量級設計可以有效緩解現階段的高計算成本。這個目的主要是通過使用 Depth-wise Separable Convolution (DSC)操作來減少參數和FLOPs的數量來實現的,效果很明顯。
但是,DSC 的缺點也很明顯:輸入圖像的通道信息在計算過程中是分離的。
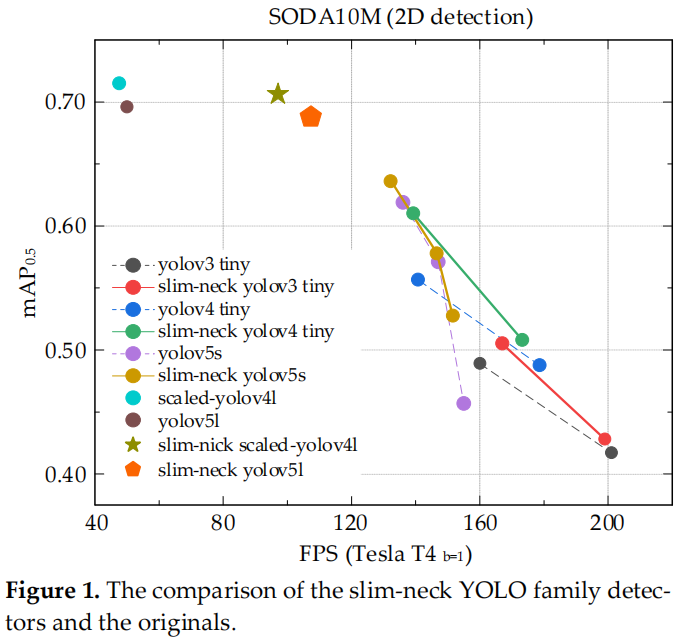
圖 1
對于自動駕駛汽車,速度與準確性同樣重要。通過 GSConv 引入了 Slim-Neck 方法,以減輕模型的復雜度同時可以保持精度。GSConv 更好地平衡了模型的準確性和速度。在圖 1 中,在 SODA10M 的無人駕駛數據集上比較了最先進的 Slim-Neck 檢測器和原始檢測器的速度和準確度。結果證實了該方法的有效性。
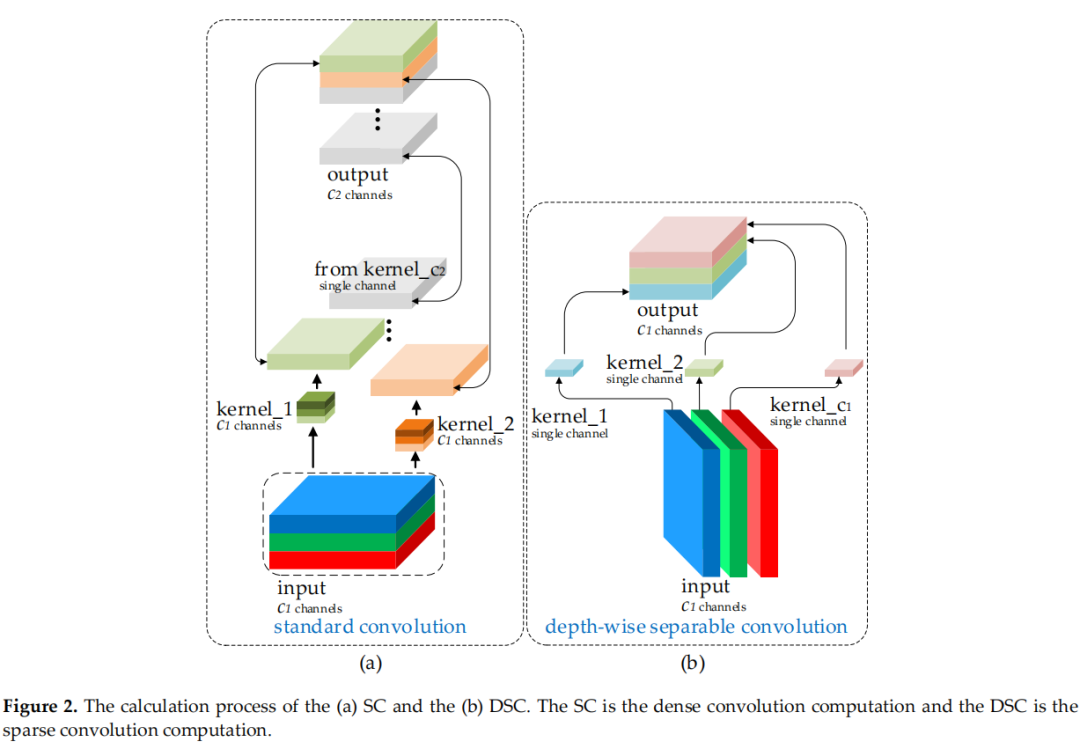
圖2
圖2(a)和(b)顯示了 DSC 和標準卷積(SC)的計算過程。這種缺陷導致 DSC 的特征提取和融合能力比 SC 低得多。優秀的輕量級作品,如 Xception、MobileNets 和 ShuffleNets,通過 DSC 操作大大提高了檢測器的速度。但是當這些模型應用于自動駕駛汽車時,這些模型的較低準確性令人擔憂。事實上,這些工作提出了一些方法來緩解 DSC 的這個固有缺陷(這也是一個特性):MobileNets 使用大量的 1×1 密集卷積來融合獨立計算的通道信息;ShuffleNets 使用channel shuffle來實現通道信息的交互,而 GhostNet 使用 halved SC 操作來保留通道之間的交互信息。但是,1×1的密集卷積反而占用了更多的計算資源,使用channel shuffle效果仍然沒有觸及 SC 的結果,而 GhostNet 或多或少又回到了 SC 的路上,影響可能會來從很多方面。
許多輕量級模型使用類似的思維來設計基本架構:從深度神經網絡的開始到結束只使用 DSC。但 DSC 的缺陷直接在主干中放大,無論是用于圖像分類還是檢測。作者相信 SC 和 DSC 可以結合在一起使用。僅通過channel shuffle DSC 的輸出通道生成的特征圖仍然是“深度分離的”。
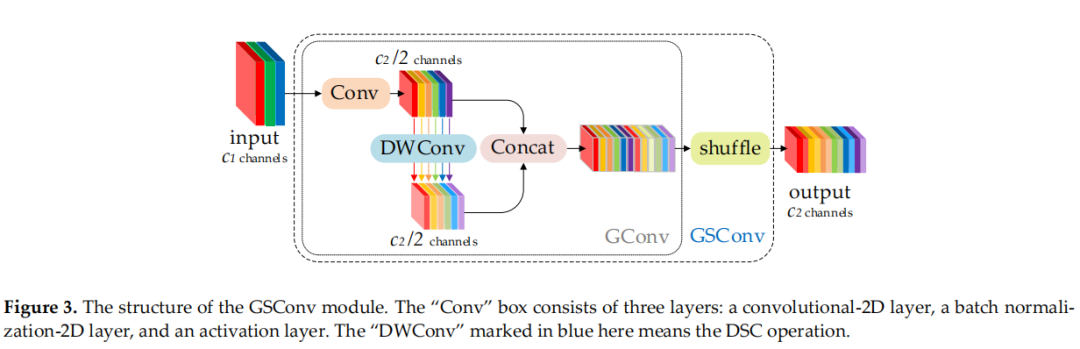
圖 3
為了使 DSC 的輸出盡可能接近 SC,引入了一種新方法——GSConv。如圖 3 所示,使用 shuffle 將 SC 生成的信息(密集卷積操作)滲透到 DSC 生成的信息的每個部分。這種方法允許來自 SC 的信息完全混合到 DSC 的輸出中,沒有花里胡哨的東西。

圖 4
圖 4 顯示了 SC、DSC 和 GSConv 的可視化結果。GSConv 的特征圖與 SC 的相似性明顯高于 DSC 與 SC 的相似。當在 Backbone 使用 SC,在Neck使用 GSConv(slim-neck)時,模型的準確率非常接近原始;如果添加一些技巧,模型的準確性和速度就會超過原始模型。采用 GSConv 方法的Slim-Neck可最大限度地減少 DSC 缺陷對模型的負面影響,并有效利用 DSC 的優勢。
主要貢獻可以總結如下:
引入了一種新方法 GSConv 來代替 SC 操作。該方法使卷積計算的輸出盡可能接近 SC,同時降低計算成本;
為自動駕駛汽車的檢測器架構提供了一種新的設計范式,即帶有標準 Backbone 的 Slim-Neck 設計;
驗證了不同 Trick 的有效性,可以作為該領域研究的參考。
2本文方法
2.1 為什么要在Neck中使用GSConv
為了加速預測的計算,CNN 中的饋送圖像幾乎必須在 Backbone 中經歷類似的轉換過程:空間信息逐步向通道傳輸。并且每次特征圖的空間(寬度和高度)壓縮和通道擴展都會導致語義信息的部分丟失。密集卷積計算最大限度地保留了每個通道之間的隱藏連接,而稀疏卷積則完全切斷了這些連接。
GSConv 盡可能地保留這些連接。但是如果在模型的所有階段都使用它,模型的網絡層會更深,深層會加劇對數據流的阻力,顯著增加推理時間。當這些特征圖走到 Neck 時,它們已經變得細長(通道維度達到最大,寬高維度達到最小),不再需要進行變換。因此,更好的選擇是僅在 Neck 使用 GSConv(Slim-Neck + 標準Backbone)。在這個階段,使用 GSConv 處理 concatenated feature maps 剛剛好:冗余重復信息少,不需要壓縮,注意力模塊效果更好,例如 SPP 和 CA。
2.2 Slim-Neck
作者研究了增強 CNN 學習能力的通用方法,例如 DensNet、VoVNet 和 CSPNet,然后根據這些方法的理論設計了 Slim-Neck 結構。
1、Slim-Neck中的模塊
首先,使用輕量級卷積方法 GSConv 來代替 SC。其計算成本約為 SC 的60%~70%,但其對模型學習能力的貢獻與后者不相上下。然后,在 GSConv 的基礎上繼續引入 GSbottleneck,圖5(a)展示了 GSbottleneck 模塊的結構。
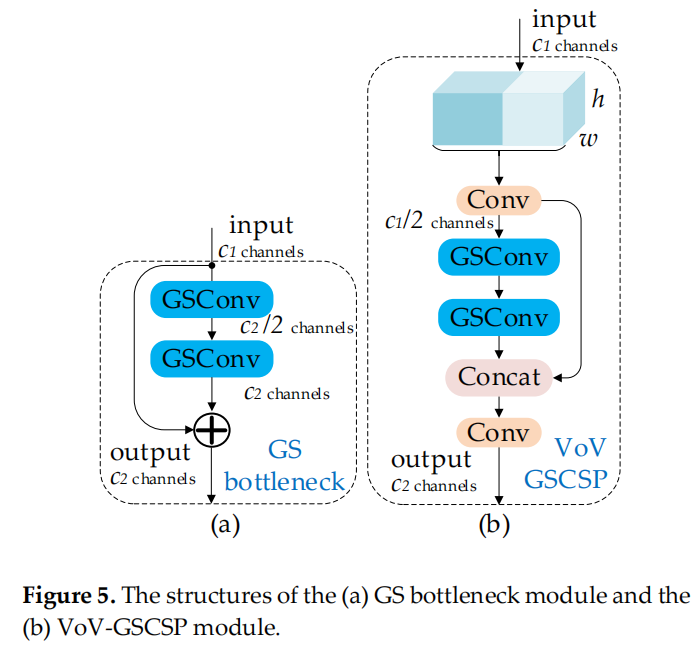
圖5
同樣,使用一次性聚合方法來設計跨級部分網絡 (GSCSP) 模塊 VoV-GSCSP。VoV-GSCSP 模塊降低了計算和網絡結構的復雜性,但保持了足夠的精度。圖 5 (b) 顯示了 VoV-GSCSP 的結構。值得注意的是,如果我們使用 VoV-GSCSP 代替 Neck 的 CSP,其中 CSP 層由標準卷積組成,FLOPs 將平均比后者減少 15.72%。
最后,需要靈活地使用3個模塊,GSConv、GSbottleneck 和 VoV-GSCSP。
2、Slim-Neck針對YOLO系列的設計
YOLO 系列檢測器由于檢測效率高,在行業中應用更為廣泛。這里使用 slim-neck 的模塊來改造 Scaled-YOLOv4 和 YOLOv5 的 Neck 層。圖 6 和圖 7 顯示了2種 slim-neck 架構。
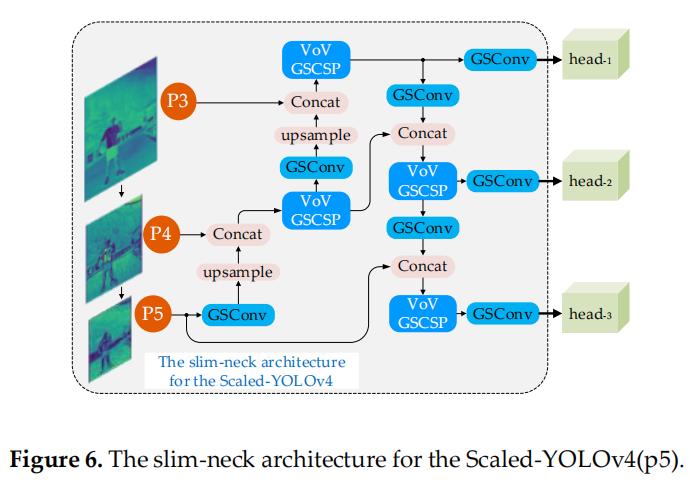
圖 6
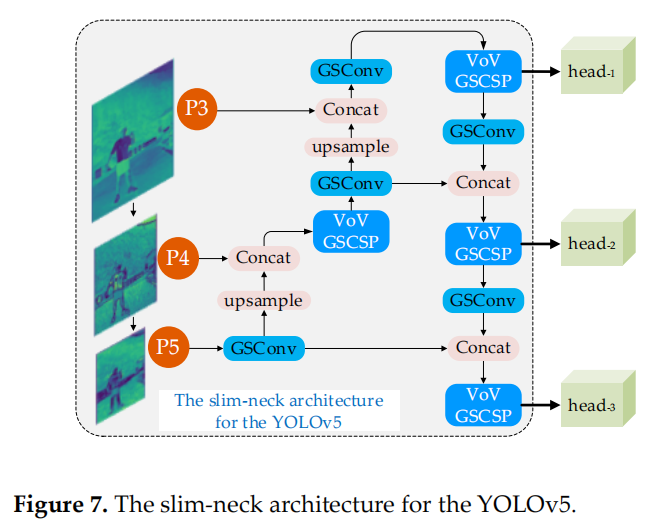
圖 7
3、免費的改進Tricks
可以在基于 CNNs 的檢測器中使用一些局部特征增強方法,結構簡單,計算成本低。這些增強方法,注意力機制,可以顯著提高模型精度,而且比Neck 簡單得多。這些方法包括作用于通道信息或空間信息。SPP 專注于空間信息,它由4個并行分支連接:3個最大池操作(kernel-size為 5×5、9×9 和 13×13)和輸入的 shortcut 方式。它用于通過合并輸入的局部和全局特征來解決對象尺度變化過大的問題。YOLOv5 作者的 SPP 改進模塊 SPPF 提高了計算效率。該效率 增加了近 277.8%。通式為:
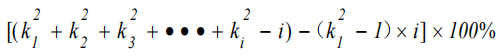
其中,是 SPPF 模塊中第i個分支的最大池化的kernel-size。
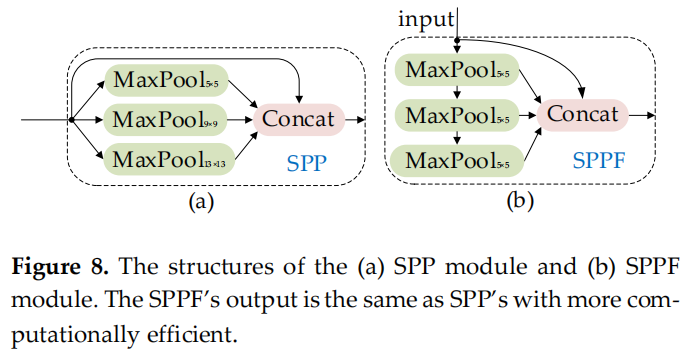
圖 8
圖 8 (a) 和 (b) 顯示了 SPP 和 SPPF 的結構。SE是一個通道注意力模塊,包括兩個操作過程:squeeze和excitation。該模塊允許網絡更多地關注信息量更大的特征通道,而否定信息量較少的特征通道。CBAM 是一個空間通道注意力機制模塊。CA 模塊是一種新的解決方案,可以避免全局池化操作導致的位置信息丟失:將注意力分別放在寬度和高度兩個維度上,以有效利用輸入特征圖的空間坐標信息。圖9(a)、(b)和(c) 顯示了 SE、CBAM 和 CA 模塊的結構。
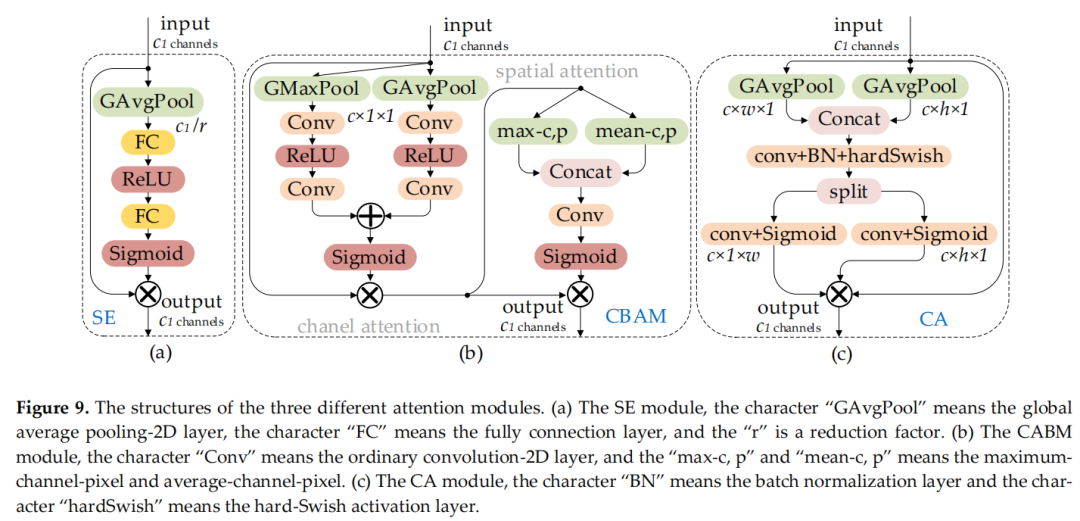
圖 9
4、損失和激活函數
IoU 損失對于基于深度學習的檢測器具有很大的價值。它使預測邊界框回歸的位置更加準確。隨著研究的不斷發展,許多研究人員已經提出了更高級的 IoU 損失函數,例如 GIoU、DIoU、CIoU 和最新的 EIoU。5個損失函數定義如下:
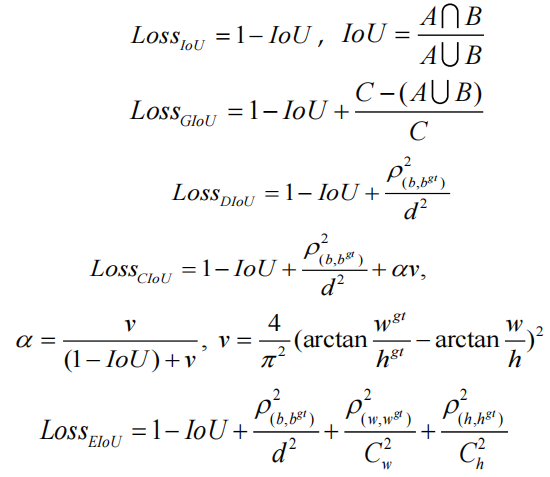
其中參數“A”和“B”表示Ground truth邊界框的面積和預測邊界框的面積;參數“C”表示Ground truth邊界框和預測邊界框的最小包圍框的面積;參數“d”表示封閉框的對角線頂點的歐式距離;參數“ρ”表示Ground truth邊界框和預測邊界框質心的歐式距離;參數“α”是權衡的指標,參數“v”是評價Ground truth邊界框和預測邊界框長寬比一致性的指標。
CIoU loss是目前Anchor-based檢測器中使用最廣泛的損失函數,但CIoU loss仍然存在缺陷:
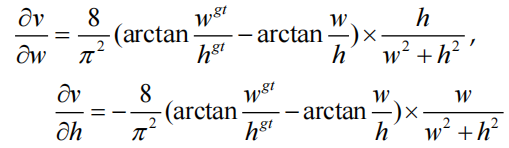
其中“δv /δw”是“v”相對于“w”的梯度,“δv/δh”是“v”相對于“h”的梯度。
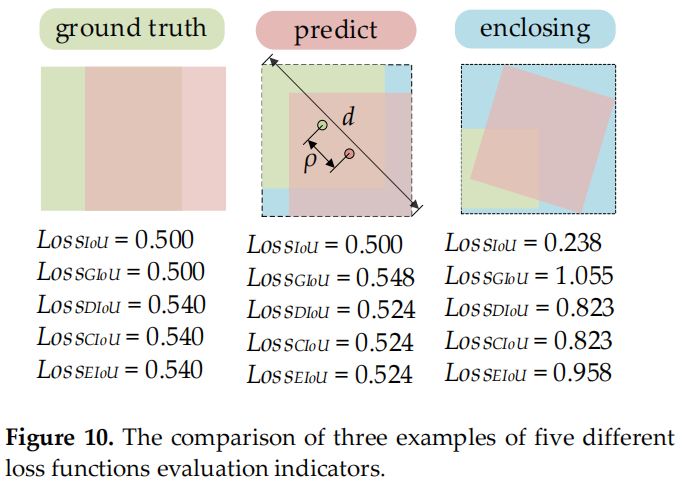
圖 10
根據 CIoU 損失的定義,如果,CIoU 損失將退化為DIoU損失,即CIoU損失中添加的懲罰項的相對比例(αv)將不起作用。此外,w和h的梯度符號相反。
因此,這兩個變量(w或h)只能在同一方向上更新,同時增加或減少。這不符合實際應用場景,尤其是當 且 $hw^{gt}h>h^{gt}$ 時。EIoU loss沒有遇到這樣的問題,它直接使用預測邊界框的w和h獨立作為懲罰項,而不是w和h的比值。圖10是這些損失函數的不同評估指標的3個示例。
在深度網絡上,使用 Swish 和 Mish 的模型的準確性和訓練穩定性通常比 ReLU 差。Swish 和 Mish 都具有無上界和下界、平滑和非單調的特性。它們定義如下:
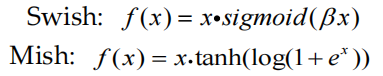
在更深的網絡上,Mish 的模型準確度略好于 Swish,盡管實際上2條激活函數曲線非常接近。與 Swish 相比,Mish 由于計算成本的增加而消耗更多的訓練時間。
3實驗
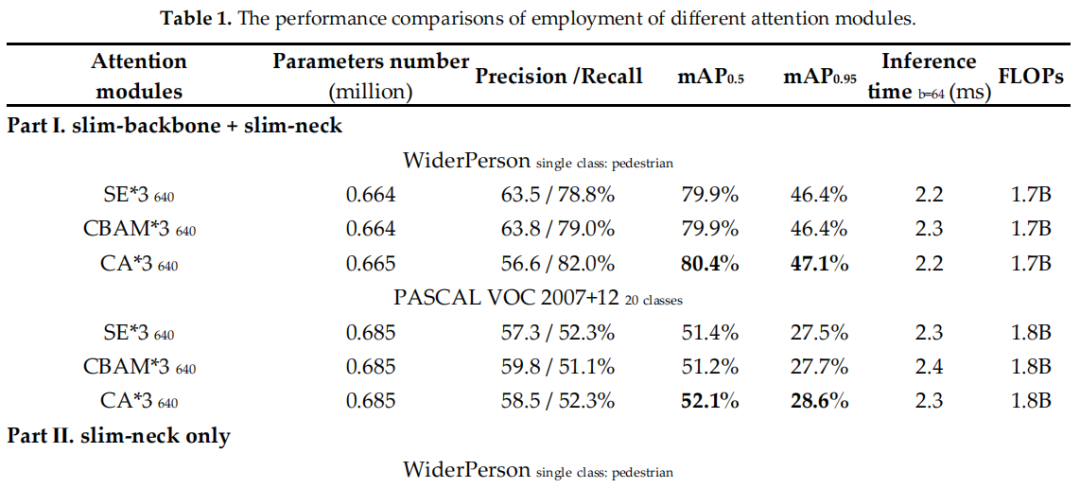
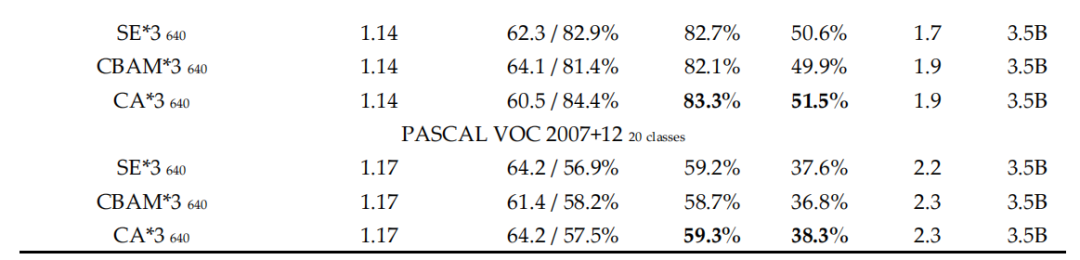
3.1 Trick消融實驗
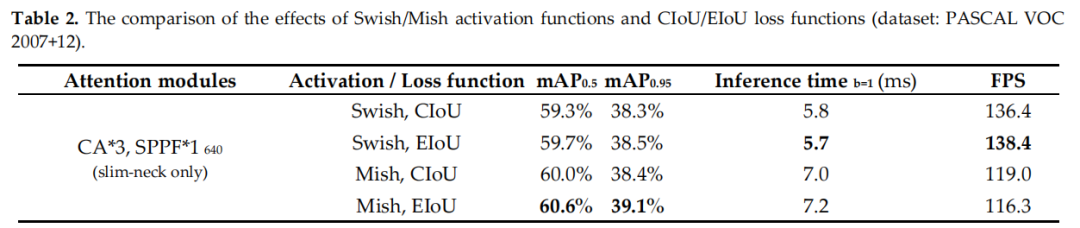
3.2 損失函數對比
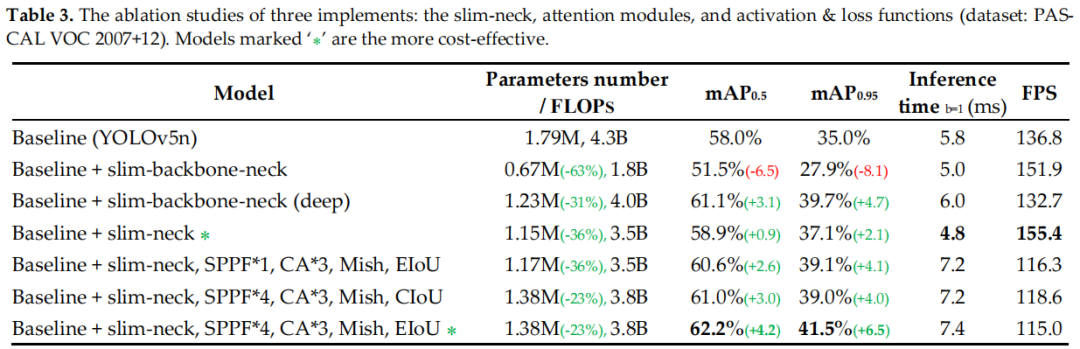
3.3 Yolo改進

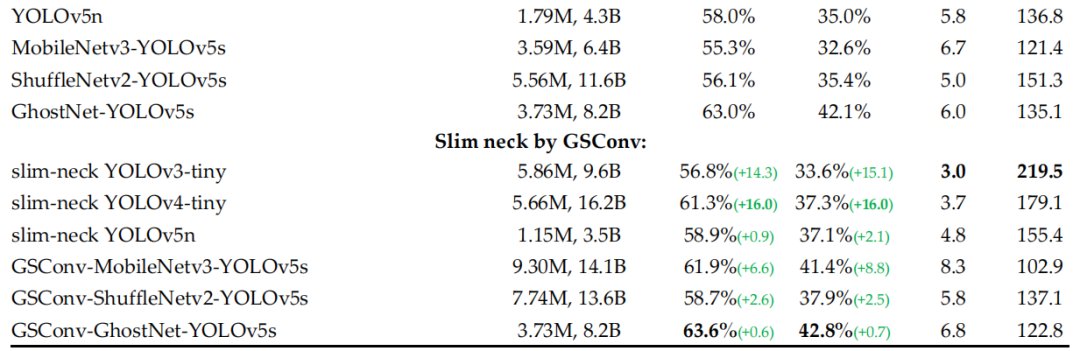

3.4 可視化結果對比

4參考
[1].Slim-neck by GSConv: A better design paradigm of detector architectures for autonomous vehicles
審核編輯 :李倩
-
目標檢測
+關注
關注
0文章
205瀏覽量
15590 -
無人駕駛汽車
+關注
關注
17文章
150瀏覽量
37336 -
深度學習
+關注
關注
73文章
5493瀏覽量
120999
原文標題:改進Yolov5 | 用 GSConv+Slim Neck 一步步把 Yolov5 提升到極致!!!
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何提升ASR模型的準確性
一種創新的動態軌跡預測方法
如何評估 ChatGPT 輸出內容的準確性
如何保證測長機測量的準確性?

業務復雜度治理方法論--十年系統設計經驗總結
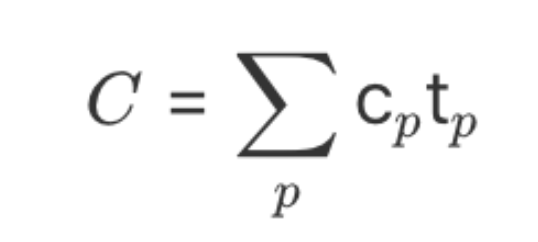
一種無透鏡成像的新方法

一種利用光電容積描記(PPG)信號和深度學習模型對高血壓分類的新方法
【大語言模型:原理與工程實踐】大語言模型的評測
怎樣測試電流探頭的準確性以及保證其精準性

一種產生激光脈沖新方法

降低Transformer復雜度O(N^2)的方法匯總






 工商網監
工商網監
評論