 使用NGC目錄中的生產級模型 加速AI開發工作
使用NGC目錄中的生產級模型 加速AI開發工作
使用 NGC 目錄中的生產級模型,加速 AI 開發工作。
什么是預訓練 AI 模型?
AI 和機器學習模型基于數學算法構建,并使用數據和專業知識進行訓練。這些模型可幫助我們根據圖像、文本或語言等輸入數據準確預測結果。但是,構建、訓練和優化生產級模型成本高昂,需要無數次迭代、諸多專業領域知識以及無數小時的計算。
預訓練模型在代表性數據集上進行訓練,并通過權重和偏差進行調優。這些模型可以使用自定義數據輕松地進行重新訓練,只需從頭開始訓練所需時間的一小部分。
NGC 目錄中的預訓練模型
借助NGC 目錄(NVIDIA 的 GPU 優化 AI 和高性能計算軟件中心)中的生產就緒型 AI 預訓練模型,數據科學家和開發者可以快速適應模型,或直接將模型按原樣部署以進行推理。
多種用例
NGC 提供各種先進的預訓練模型和資源,其中涵蓋了多種用例,從計算機視覺、自然語言理解到語音合成,豐富多樣。這些模型利用Tensor Core上的自動混合精度 (AMP),并且可以從單節點擴展到多節點系統,從而加快訓練和推理速度。
可適應多種領域
借助NVIDIA TAO 工具套件,您可以輕松地使用自定義數據適應和調優預訓練模型。TAO 工具套件將 AI 和深度學習框架的復雜性抽象化,使您能夠在幾個小時(而非數月)內構建生產級計算機視覺或對話式 AI 模型。
透明的模型 “簡歷”
正如簡歷提供了候選人的技能和工作經歷簡況一樣,模型憑據對于模型而言,也是這種作用。許多預訓練模型包括批量大小、訓練次數和準確度等關鍵參數,可為您提供必要的透明度和信心,以便為您的用例選擇合適的模型。
SDK 集成
預訓練模型可集成到各種行業 SDK 中,例如用于醫療健康領域的NVIDIA Clara、用于機器人的NVIDIA Isaac、用于對話式 AI 的NVIDIA Riva等,讓您能夠更輕松地在最終用戶應用和服務中使用這些模型。
適用于各種用例的模型
立即開始使用模型,這些模型涵蓋包括計算機視覺、語音和語言理解在內的多種領域。
計算機視覺
借助計算機視覺,設備可以通過圖像和視頻了解我們周圍的世界。它使用圖像分類、物體檢測和跟蹤、物體識別、語義分割和實例分割等技術。
自然語言處理
自然語言處理 (NLP) 使用算法和技術,使計算機能夠理解、說明、操作和使用人類語言進行交談。它包括情感分析、語音識別、語音合成、語言翻譯和自然語言生成等技術。
語音
語音涉及識別音頻以及將音頻翻譯成文本或合成文本語音。它包括語音合成、自動語音識別 (ASR) 和文本轉語音 (TTS)。
NVIDIA 深度學習培訓中心
我們的 NVIDIA 深度學習培訓中心還推出了預訓練 AI 模型及 NGC 相關課程,您可以復制鏈接查看課程詳情。
使用容器實現高性能計算
學習使用容器化環境開發高性能計算(HPC)應用程序,降低編碼的復雜性和可移植性,從而提高開發效率。
原文標題:DevZone | 預訓練AI模型
文章出處:【微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
審核編輯:湯梓紅
-
NVIDIA
+關注
關注
14文章
4949瀏覽量
102828 -
AI
+關注
關注
87文章
30239瀏覽量
268479 -
機器學習
+關注
關注
66文章
8382瀏覽量
132444 -
NGC
+關注
關注
0文章
8瀏覽量
3834
原文標題:DevZone | 預訓練AI模型
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
華為云徐峰:AI 賦能應用現代化,加速軟件生產力躍升

借助NVIDIA NIM加速AI應用部署
揭秘NVIDIA AI Workbench 如何助力應用開發
聆思CSK6視覺語音大模型AI開發板入門資源合集(硬件資料、大模型語音/多模態交互/英語評測SDK合集)
Snowflake推出企業級AI模型
浪潮信息發布企業大模型開發平臺"元腦企智"EPAI,加速AI創新落地

AI快訊:華為助力金融行業加速擁抱AI 馬斯克xAI 展示首個多模態模型
開發者手機 AI - 目標識別 demo
澎峰科技加速中國“主權級”大模型
防止AI大模型被黑客病毒入侵控制(原創)聆思大模型AI開發套件評測4
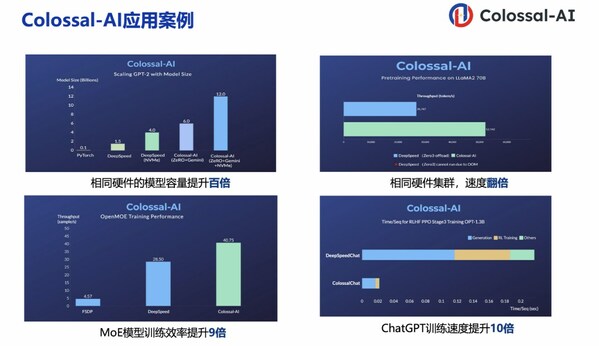
潞晨科技Colossal-AI + 浪潮信息AIStation,大模型開發效率提升10倍
【國產FPGA+OMAPL138開發板體驗】(原創)5.FPGA的AI加速源代碼







 工商網監
工商網監
評論