 機器學習和數據挖掘的關系
機器學習和數據挖掘的關系
在開篇之前,想和大家聊一下機器學習和數據挖掘的關系。
數據挖掘只是機器學習中涉獵的領域之一,機器學習還有模式識別、計算機視覺、語音識別、統計學習以及自然語言處理等。
機器學習即 ML,是一門多領域交叉學科,涉及概率論、統計學、逼近論、凸分析、算法復雜度理論等多門學科。專門研究計算機怎樣模擬或實現人類的學習行為,以獲取新的知識或技能,重新組織已有的知識結構使之不斷改善自身的性能。
機器學習作為人工智能研究較為年輕的分支,機器學習也分監督學習和非監督學習,同時隨著人工智能越來越被人們重視和越熱,深度學習也是機器學習的一個新的領域。
機器學習,從知識清單開始
我們第一天學開車的時候一定不會直接上路,而是要你先學習基本的知識,然后再進行上車模擬。
只有對知識有全面的認知,才能確保在以后的工作中即使遇到了問題,也可以快速定位問題所在,然后找方法去對應和解決。
所以我列了一個機器學習入門的知識清單,分別是機器學習的一般流程、十大算法、算法學習的三重境界,以此來開啟我們的學習之旅。
一、機器學習的基本流程
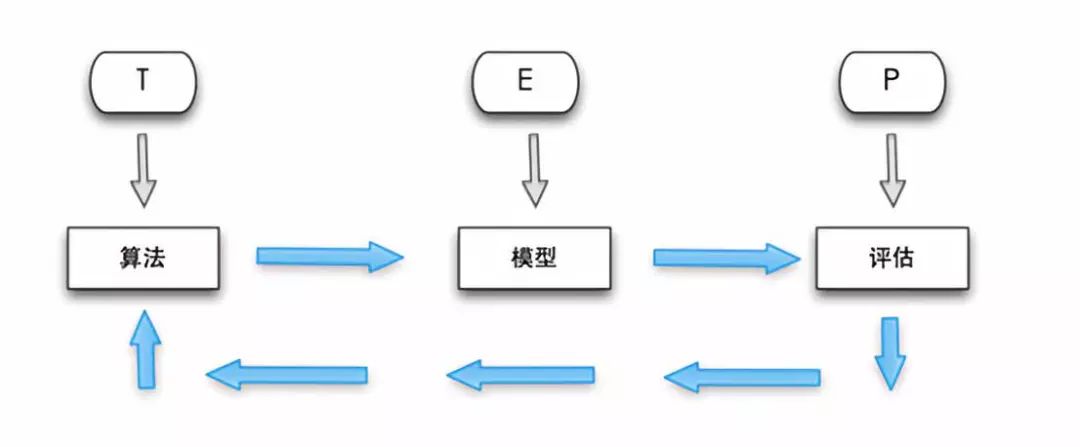
引用大佬的解釋:
A computer program is said to learn fromexperience E with respect to some task T and some performance measure P,if itsperformance on T,as measured by P,improves with experience E. —Tom Mitchell
簡單來說,機器學習就是針對現實問題,使用我們輸入的數據對算法進行訓練,算法在訓練之后就會生成一個模型,這個模型就是對當前問題通過數據捕捉規律的描述。然后我們將模型進一步導入數據,或者引入新的數據集進行評估,根據結果的好壞反過來調整算法,形成反饋和優化閉環。整個過程機器在不斷的學習、訓練和優化迭代,這個也是機器學習強大的地方。
二、機器學習的十大算法
為了進行機器學習和數據挖掘任務,數據科學家們提出了各種模型,在眾多的數據挖掘模型中,國際權威的學術組織 ICDM(the IEEE International Conference on Data Mining)評選出了十大經典的算法。
按照不同的目的,我可以將這些算法分成四類,以便你更好的理解。
分類算法:C4.5,樸素貝葉斯(Naive Bayes),SVM,KNN,Adaboost,CART
聚類算法:K-Means,EM
關聯分析:Apriori
連接分析:PageRank
1. C4.5
C4.5 算法是得票最高的算法,可以說是十大算法之首。C4.5 是決策樹的算法,它創造性地在決策樹構造過程中就進行了剪枝,并且可以處理連續的屬性,也能對不完整的數據進行處理。它可以說是決策樹分類中,具有里程碑式意義的算法。
2.樸素貝葉斯(NaiveBayes)
樸素貝葉斯模型是基于概率論的原理,它的思想是這樣的:對于給出的未知物體想要進行分類,就需要求解在這個未知物體出現的條件下各個類別出現的概率,哪個最大,就認為這個未知物體屬于哪個分類。
3. SVM
SVM 的中文叫支持向量機,英文是 SupportVector Machine,簡稱 SVM。SVM 在訓練中建立了一個超平面的分類模型。
4. KNN
KNN 也叫 K 最近鄰算法,英文是 K-Nearest Neighbor。所謂 K 近鄰,就是每個樣本都可以用它最接近的 K 個鄰居來代表。如果一個樣本,它的 K 個最接近的鄰居都屬于分類 A,那么這個樣本也屬于分類 A。
5. AdaBoost
Adaboost 在訓練中建立了一個聯合的分類模型。boost 在英文中代表提升的意思,所以 Adaboost 是個構建分類器的提升算法。它可以讓我們多個弱的分類器組成一個強的分類器,所以 Adaboost 也是一個常用的分類算法。
6. CART
CART 代表分類和回歸樹,英文是 Classificationand Regression Trees。像英文一樣,它構建了兩棵樹:一顆是分類樹,另一個是回歸樹。和C4.5 一樣,它是一個決策樹學習方法。
7. Apriori
Apriori 是一種挖掘關聯規則(association rules)的算法,它通過挖掘頻繁項集(frequentitem sets)來揭示物品之間的關聯關系,被廣泛應用到商業挖掘和網絡安全等領域中。頻繁項集是指經常出現在一起的物品的集合,關聯規則暗示著兩種物品之間可能存在很強的關系。
8. K-Means
K-Means 算法是一個聚類算法。你可以這么理解,最終我想把物體劃分成 K 類。假設每個類別里面,都有個“中心點”,即意見領袖,它是這個類別的核心。現在我有一個新點要歸類,這時候就只要計算這個新點與K 個中心點的距離,距離哪個中心點近,就變成了哪個類別。
9. EM
EM 算法也叫最大期望算法,是求參數的最大似然估計的一種方法。原理是這樣的:假設我們想要評估參數 A 和參數 B,在開始狀態下二者都是未知的,并且知道了 A 的信息就可以得到 B 的信息,反過來知道了 B 也就得到了 A。可以考慮首先賦予A 某個初值,以此得到 B 的估值,然后從 B 的估值出發,重新估計 A 的取值,這個過程一直持續到收斂為止。
EM 算法經常用于聚類和機器學習領域中。
10. PageRank
PageRank 起源于論文影響力的計算方式,如果一篇文論被引入的次數越多,就代表這篇論文的影響力越強。同樣 PageRank 被 Google 創造性地應用到了網頁權重的計算中:當一個頁面鏈出的頁面越多,說明這個頁面的“參考文獻”越多,當這個頁面被鏈入的頻率越高,說明這個頁面被引用的次數越高。基于這個原理,我們可以得到網站的權重劃分。
算法可以說是機器學習的靈魂,也是最精華的部分。這 10 個經典算法在整個機器學習領域中的得票最高的,后面的一些其他算法也基本上都是在這個基礎上進行改進和創新。今天你先對十大算法有一個初步的了解,你只需要做到心中有數就可以了。
三、機器學習的三大境界
1.掌握算法入口出口
第一重境界,將算法本身是做黑箱,在不知道算法具體原理的情況下能夠掌握算法的基本應用情景(有監督、無監督),以及算法的基本使用情景,能夠調包實現算法。
2.理解原理,靈活調優
第二重境界則是能夠深入了解、掌握算法原理,并在此基礎上明白算法實踐過程中的關鍵技術、核心參數,最好能夠利用編程語言手動實現算法,能夠解讀算法執行結果,并在理解原理的基礎上對通過調參對算法進行優化。
3.融會貫通,設計算法
最后一重境界,實際上也是算法(研發)工程師的主要工作任務,即能夠結合業務場景、自身數學基礎來進行有針對性的算法研發,此部分工作不僅需要扎實的算法基本原理知識,也需要扎實的編程能力。
總結
今天我列了下學習機器學習你要掌握的知識清單,只有你對機器學習的流程、算法、原理有更深的理解,你才能在實際工作中更好地運用,祝你在機器學習的路上越走越遠。
審核編輯 :李倩
-
人工智能
+關注
關注
1791文章
46868瀏覽量
237592 -
數據挖掘
+關注
關注
1文章
406瀏覽量
24206 -
機器學習
+關注
關注
66文章
8378瀏覽量
132415
原文標題:學習機器學習的最佳路徑路?
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
ASR和機器學習的關系
什么是機器學習?通過機器學習方法能解決哪些問題?

NPU與機器學習算法的關系
具身智能與機器學習的關系
AI大模型與深度學習的關系
為AI、ML和數字孿生模型建立可信數據
【「時間序列與機器學習」閱讀體驗】時間序列的信息提取
【「時間序列與機器學習」閱讀體驗】全書概覽與時間序列概述
機器學習中的數據分割方法
圖機器學習入門:基本概念介紹






 工商網監
工商網監
評論