") 基于深度學(xué)習(xí)算法的軟件生態(tài)系統(tǒng)
基于深度學(xué)習(xí)算法的軟件生態(tài)系統(tǒng)
深度學(xué)習(xí)是機(jī)器學(xué)習(xí)的一個(gè)子集,常用于自然語言處理,計(jì)算機(jī)視覺等領(lǐng)域,與眾不同之處在于,DL(Deep Learning )算法可以自動(dòng)從圖像、視頻或文本等數(shù)據(jù)中學(xué)習(xí)數(shù)據(jù)特征。DL可以直接從數(shù)據(jù)中學(xué)習(xí),這比較類似于人腦的運(yùn)行方式,獲得更多數(shù)據(jù)后,準(zhǔn)確度也會(huì)越來越高。TIDL(TI Deep Learning Library) 是TI平臺(tái)基于深度學(xué)習(xí)算法的軟件生態(tài)系統(tǒng),可以將一些常見的深度學(xué)習(xí)算法模型快速的部署到TI嵌入式平臺(tái)。 TDA4擁有TI最新一代的深度學(xué)習(xí)加速模塊C7x DSP與MMA矩陣乘法加速器,可以運(yùn)行TIDL進(jìn)行卷積等基本計(jì)算,從而快速地進(jìn)行前向推理,得到計(jì)算結(jié)果。 當(dāng)深度學(xué)習(xí)遇上TDA4,你的模型部署流程將變得簡(jiǎn)單,你的模型將高效地運(yùn)行在TDA4上。
TI 最新一代的汽車處理器TDA4VM集成了高性能計(jì)算單元C7x DSP(Digital Signal Processor)和Deep-learning Matrix Multiply Accelerator(MMA),可以高效地進(jìn)行卷積計(jì)算、矩陣變換等一些基本地深度學(xué)習(xí)算子。TIDL 是TI的針對(duì)于嵌入式平臺(tái)部署深度學(xué)習(xí)不方便,計(jì)算效率低下而設(shè)計(jì)的一個(gè)軟件生態(tài)系統(tǒng),用于加速 TI 嵌入式設(shè)備上的深度神經(jīng)網(wǎng)絡(luò)Deep Neural Networks (DNN)計(jì)算加速。 上一代產(chǎn)品 TDA2/3 系列處理器,集成了計(jì)算單元 DSP(Digital Signal Processor)和 EVE(Embedded Vision/Vector Engine),用于加速計(jì)算深度學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)。相比于上一代TDA2/TDA3系列處理器,最新一代的TDA4處理器在算例上得到了大幅提高的同時(shí),在軟件方面提供了更好地支持,同時(shí)提供了更多的深度學(xué)習(xí)模型的部署示例,方便開發(fā)人員快速開發(fā)迭代產(chǎn)品,極大地縮短的產(chǎn)品開發(fā)周期。
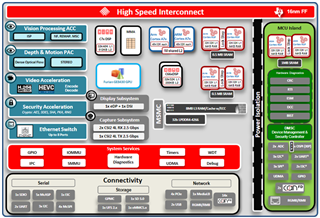
圖1. TIDL SW Framework
基于深度神經(jīng)網(wǎng)絡(luò) (DNN) 的機(jī)器學(xué)習(xí)算法用于許多行業(yè),例如機(jī)器人、工業(yè)和汽車。越來越多的基于 DNN 的機(jī)器學(xué)習(xí)算法被應(yīng)用于 ADAS 產(chǎn)品中,如車道線檢測(cè),交通信號(hào)燈識(shí)別,行人識(shí)別等ADAS基礎(chǔ)功能均采用DNN算法實(shí)現(xiàn)。這些DNN神經(jīng)網(wǎng)絡(luò)算法通常需要大量的計(jì)算,而TI TDA4系列處理器中的C7x和MMA可以將一些DNN中的算子進(jìn)行加速計(jì)算,以實(shí)現(xiàn)快速推理得到識(shí)別結(jié)果。RTOS SDK 中集成了眾多的Demo展示TIDL在TDA4處理器上對(duì)實(shí)時(shí)的語義分割和 SSD 目標(biāo)檢測(cè)的能力。如下圖2:AVP的demo展示了使用TIDL對(duì)泊車點(diǎn)、車輛的檢測(cè)。

圖2. TIDL SW Framework
TIDL當(dāng)前支持的訓(xùn)練框架有Tensorflow、Pytorch、Caffe等,用戶可以根據(jù)需要選擇合適的訓(xùn)練框架進(jìn)行模型訓(xùn)練。TIDL可以將PC端訓(xùn)練好的模型導(dǎo)入編譯生成TIDL可以識(shí)別的模型格式,同時(shí)在導(dǎo)入編譯過程中進(jìn)行層級(jí)合并以及量化等操作,方便導(dǎo)入編譯后的模型高效的運(yùn)行在具有高性能定點(diǎn)數(shù)據(jù)感知能力TDA4硬件加速器上。 TIDL提供了一些的工具,如模型導(dǎo)入工具,模型可視化工具等,非常便捷地可以對(duì)訓(xùn)練好地模型進(jìn)行導(dǎo)入。
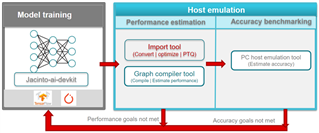
圖3. TIDL Tools
TIDL Runtime 是運(yùn)行在TDA4端的實(shí)時(shí)推理單元,同時(shí)提供了TIDL的運(yùn)行環(huán)境,對(duì)于input tensor,TIDL TIOVX Node 調(diào)用TIDL 的深度學(xué)習(xí)加速庫(kù)進(jìn)行感知,并將結(jié)果進(jìn)行輸出。
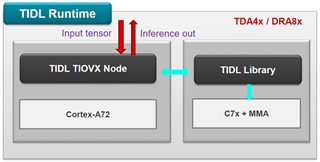
圖4. TIDL Runtime
如圖5所示,是TIDL的軟件框架。在TIDL上,深度學(xué)習(xí)網(wǎng)絡(luò)應(yīng)用開發(fā)主要分為三個(gè)大的步驟(以TI Jacinto7TM TDA4VM處理器為例):
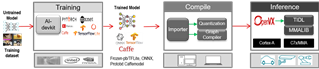
圖5. TIDL SW Framework
基于Tensorflow、Pytorch、Caffe 等訓(xùn)練框架,訓(xùn)練模型:選擇一個(gè)訓(xùn)練框架,然后定義模型,最后使用相應(yīng)的數(shù)據(jù)集訓(xùn)練出滿足需求的模型。
基于TI Jacinto7TM TDA4VM處理器導(dǎo)入模型: 訓(xùn)練好的模型,需要使用TIDL Importer工具導(dǎo)入成可在TIDL上運(yùn)行的模型。導(dǎo)入的主要目的是對(duì)輸入的模型進(jìn)行量化、優(yōu)化并保存為TIDL能夠識(shí)別的網(wǎng)絡(luò)模型和網(wǎng)絡(luò)參數(shù)文件。
基于TI Jacinto7TM SDK 驗(yàn)證模型,并在應(yīng)用里面部署模型:
PC 上驗(yàn)證并部署
在PC上使用TIDL推理引擎進(jìn)行模型測(cè)試。
在PC上使用OpenVX框架開發(fā)程序,在應(yīng)用上進(jìn)行驗(yàn)證。
EVM上驗(yàn)證并部署
在EVM上使用TIDL推理引擎進(jìn)行模型測(cè)試。
在EVM上使用OpenVX框架開發(fā)程序,在應(yīng)用上進(jìn)行驗(yàn)證
當(dāng)深度學(xué)習(xí)遇上TDA4,模型部署變得簡(jiǎn)單的同時(shí),模型也可以更加高效地運(yùn)行。讓我們開啟TDA4的探索之旅,你的AI旅程將變得輕松愉快。
審核編輯:湯梓紅
-
處理器
+關(guān)注
關(guān)注
68文章
19165瀏覽量
229125 -
ti
+關(guān)注
關(guān)注
112文章
7966瀏覽量
212136 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5492瀏覽量
120977
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
對(duì)三星而言開放生態(tài)系統(tǒng)是什么
英特爾和AMD組建x86生態(tài)系統(tǒng)咨詢小組
意法半導(dǎo)體推出圖像傳感器應(yīng)用開發(fā)生態(tài)系統(tǒng)
商湯科技發(fā)布粵語大模型,推動(dòng)香港人工智能生態(tài)系統(tǒng)發(fā)展
蘋果硬件生態(tài)系統(tǒng)豐富,用戶黏性大
淺談AMD Ryzen AI PC生態(tài)系統(tǒng)
萊迪思舉辦2024萊迪思技術(shù)峰會(huì)展示其強(qiáng)大的FPGA合作生態(tài)系統(tǒng)
Meta欲打造巨型AI覆蓋視頻推薦生態(tài)系統(tǒng)
Renesas Ready生態(tài)系統(tǒng)合作伙伴解決方案介紹

RA生態(tài)系統(tǒng)合作伙伴解決方案提供卓越的平面航向和6軸IMU性能
Renesas Ready生態(tài)系統(tǒng)合作伙伴解決方案
芯原攜手趣戴科技擴(kuò)展手表GUI生態(tài)系統(tǒng),以提升用戶體驗(yàn)
芯原攜手趣戴科技擴(kuò)展手表GUI生態(tài)系統(tǒng)
三星攜手紅帽進(jìn)一步擴(kuò)大CXL存儲(chǔ)生態(tài)系統(tǒng)
RA生態(tài)系統(tǒng)合作伙伴解決方案-Aizip缺陷檢測(cè)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論