 基于pipeline的文本糾錯系統框架分析
基于pipeline的文本糾錯系統框架分析
1 簡介
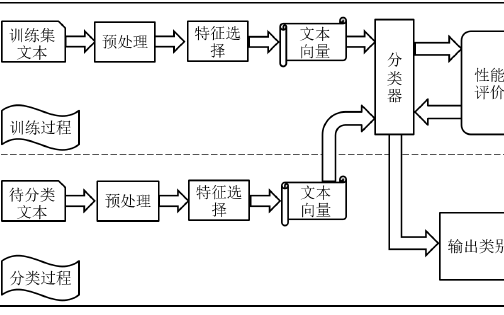
傳統的文本糾錯系統基本都是基于pipeline的,將分詞,文本檢測,文本糾正等模塊等剝離開來,同時經常會在其中插入相應的規則模塊,一環扣一環,如果生產流水線一樣,依次執行,構成一個完整的系統。這種系統設計雖然直觀,容易被人所理解,也方便人工介入去優化和排查問題。但是如果前面環節出現了錯誤,后面的環節很難進行彌補。任何一個環節出現的錯誤,都會影響系統整體的效果。各個子模塊的訓練和優化都是相互隔離的,子模塊的優化并不一定會導致系統整體性能的提升。
2 TM+LMM
這是比較早期的一個中文文本糾錯系統,該系統結合了規則模版和統計的方法,很大程度的解決了同期糾錯系統誤報率過高的問題。TM+LMM中的TM指的是規則模版(template module),LMM指的統計模型(translate module)。
該中文糾錯系統需要提前準備的事項有以下幾種。
a)混淆集,為可能的錯別字提供候選字符。該系統為5401個中文字符準備了相對應的混淆集,每個中文漢字相應的混淆集包含1到20個不等的字符(也就是有1到20個漢字you有可能被誤寫成這個漢字),包括讀音相似和字形相似的字符。同時,混淆集中的元素會根據谷歌搜索的結果進行排序,方便后續的糾正模塊按順序進行糾正。
b) n-gram語言模型,一種可以用來檢測字符是否錯誤的方式。n-gram語言模型通過最大似然估計方法在訓練數據中訓練得到(在訓練語料中不同字符組合同時出現的頻率越大,相應的n-gram模型得分就越大。這些ngram得分可以用來計算句子合理性的得分,如果一個句子所有ngram得分都很大,那么就說明這個句子是合理的,反之,如果一個句子所有的n-game得分都很小,那么說明這個句子很大概率是有問題的,也就是很大概率有錯別字出現。句子的得分跟句子中所有n-game的得分呈正相關,跟句子的長度呈負相關。),從而可以計算不同字符在當前位置的概率得分,更合適的字符可以得到更高的概率值。該系統用到了1-gram跟2-gram的信息。
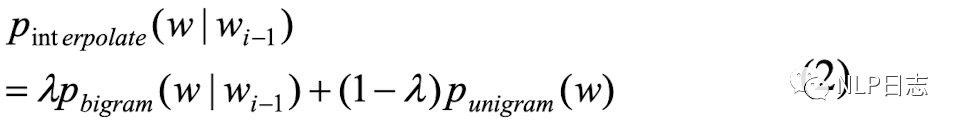
圖1:2gram得分計算
c)統計翻譯模型,可以理解為n-gram語言模型的加強版本。可以計算出將字符A替換成字符B的一個條件概率。
TM+LMM的流程如圖所示,
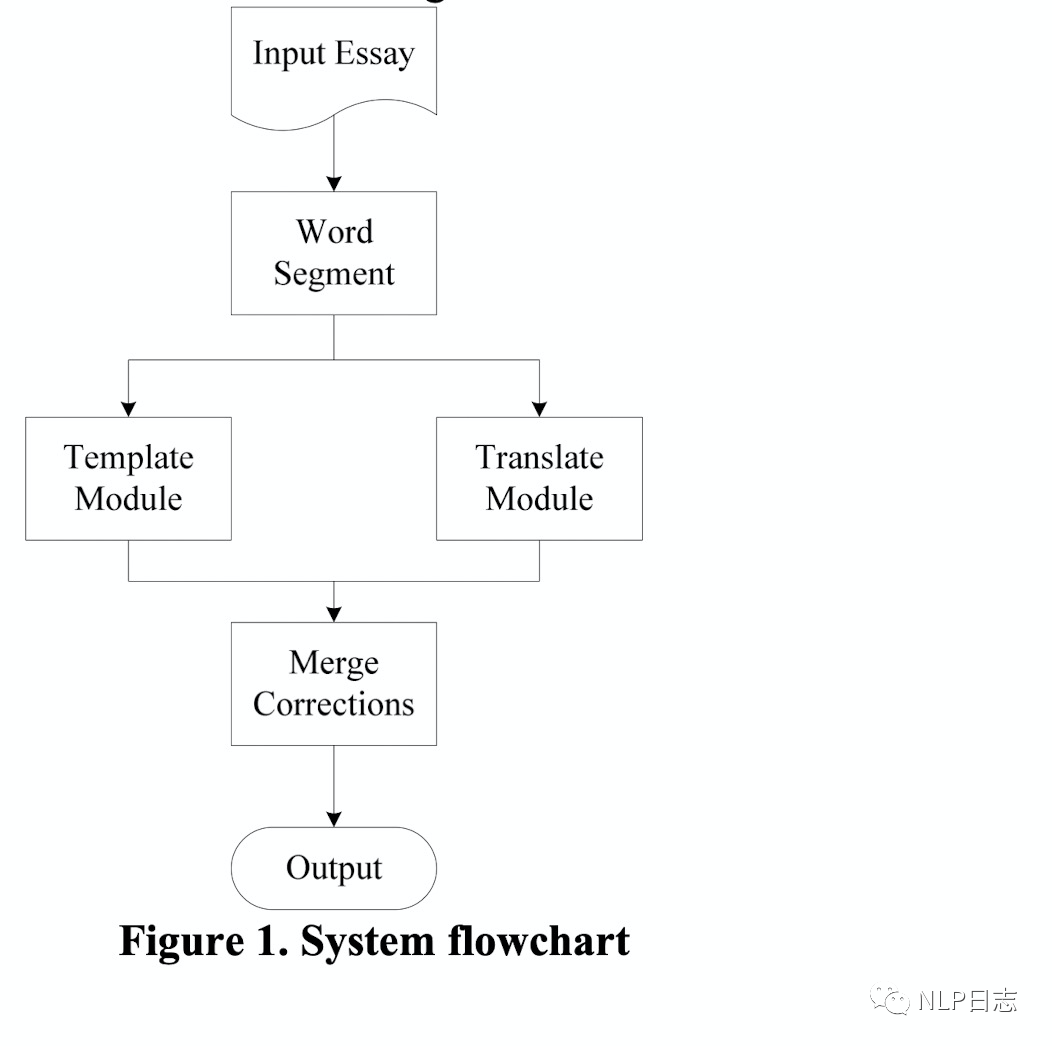
圖2: TM+LMM框架
a)分詞模塊,將句子切分為以詞為基本單位的結構。其中那些單個字符的結果會被額外關注,系統會將其認為有是有更大概率出現錯誤的地方。這也比較好理解,因為句子中錯誤的位置大概率在語法或者語義上不大連貫,所以分詞模塊大概率會把句子中錯誤的位置切分為單個的字。
b)規則模塊,尋找將第一步中可能錯誤位置上的字符對應的混淆集,嘗試將用混淆集中的元素替代當前位置的字符,如果替換結果命中系統中設置的規則模版,則進行相應的替換,反之則不變。這其實就是個規則模版,如果命中系統設置的規則,就進行替換。
c)翻譯模塊,尋找將第一步中可能錯誤位置的字符對應的混淆集,同樣嘗試用混淆集中的元素替代當前位置,通過2-gram語言模型跟翻譯模型計算相應的得分,將兩個模型的得分相乘,計算相應的困惑度分數(如下圖所示,p(S)是句子經過平滑后得到的2-gram語言模型跟翻譯模型乘積得分,N是句子長度),選擇困惑度得分最小的字符作為最終的替換結果。這里可以理解為正確的字符對應的語言模型跟翻譯模型得分乘積更大,困惑度得分更小。
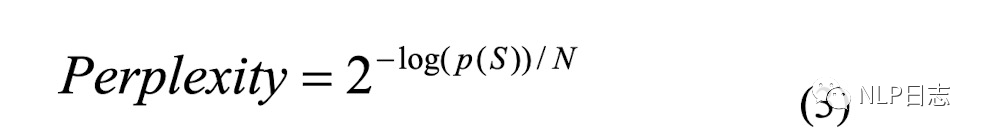
圖3:困惑度計算公式
d)輸出模塊,匯總規則模塊跟翻譯模塊的糾錯結果, 可以求兩者的交集或者并集作為最終的結果輸出。
3LMPS
LMPS是該中文糾錯系統對應的文章標題中最后幾個單詞的首字母(作者沒給自己的文本糾錯系統起名,為了編輯方便,就用LMPS指代這個系統)。構建該文本糾錯系統需要準備的事項如下。
a)混淆集,跟TM+LMM一樣構建基于發音跟字形的常用字符的混淆集。
b) 5-gram語言模型,利用語料訓練一個5-gram語言模型,用于計算不同字符對應的語言得分。
c)一個基于詞的字典,存儲基本的中文詞語,用于判斷不同字符的組合是否合法?如果某字符組合位于這個字典,那么就認為這個字符組合是合法的,是沒有錯誤的。如果某字符組合在該字典中沒有找到,那么這個字符組合大概率是存在錯誤的。這個字典在檢測階段的b)環節跟糾正階段的b)環節都會用到。
該文本糾錯系統流程分為檢測階段跟糾正階段。
檢測階段
a)通過前饋5-gram語言模型計算句子中每個字符的得分,得分低于閾值的字符跟對應位置會被檢測出來并傳遞到下一個階段。
b)判斷上一步檢測出來的字符是否可以用來構建成一個合法的詞,如果不能,則認為這個字符可能是一個錯誤,然后將可能錯誤的字符跟位置傳遞到糾正模塊進行相應的糾正。具體執行方式就是檢查固定窗口位置內的其他字符跟這個字符的組合是否存在于前面提及的字典中。
糾正階段
a)從混淆集中生成錯誤位置的可能候選字符。
b)判斷每一個候選字符是否可以跟附近字符構成一個合法的詞語,如果可以,那么這個候選字符會被留下來。通過這種方式可以過濾到大量不相關候選字符,只保留少量的更有可能作為最終結果的候選字符。
c)利用5-gram語言模型計算上一步保留下來的候選字符的得分,如果得分超過閾值,那么就用候選字符替換掉原來的字符。
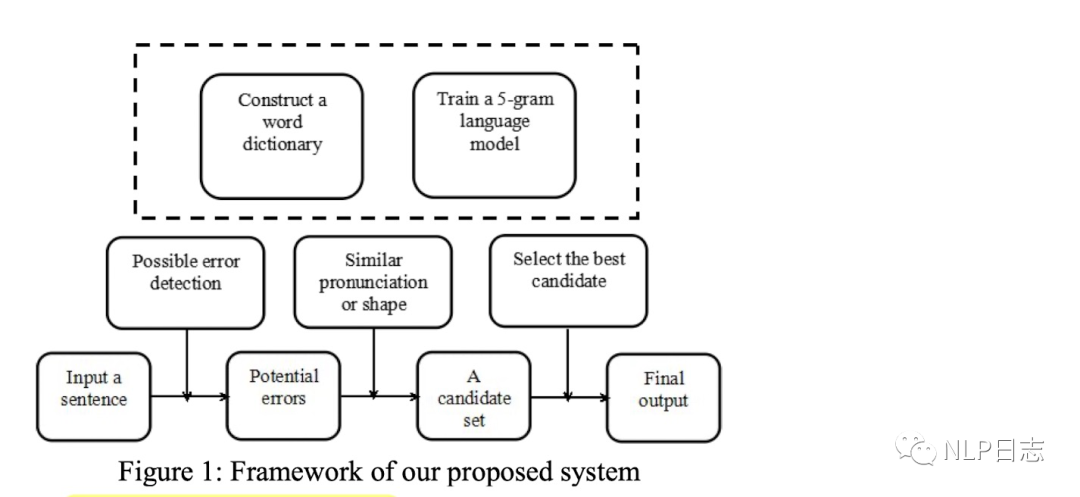
圖4:LMPS框架
4ACE
ACE是針對粵語的一種文本糾錯方法,也是一種n-gram語言模型跟規則的結合,它的思路可以遷移到其他中文的方言中去。ACE需要事先構建的內容包括以下幾個部分。
a)混淆集。
b) 粵語詞表,這個詞表不僅來源于常見的粵語詞組,還加入了當前火熱的新詞。同時給詞表中的每個詞打分,會根據訓練集匯中每個詞的出現概率記錄相應的分值,出現概率高的詞對應的得分也會比較高,然后將常見的詞中得分的最低值作為閾值記錄下來(后面會用到)。
c) n-gram語言模型,用于計算句子的n-gram得分。
ACE的糾錯也是基于pipeline依次進行的。
a)對文本進行分詞。
b) 規則模塊,借助于若干預先定義好的粵語句子結構規則對句子結構進行調整。例如,將“吃飯先”調整為“先吃飯”。
c)查詢句子中每個詞在粵語詞表中的得分,如果得分低于前面提及的閾值,那么就認為這個詞可能是有問題的。
b)知道所有可能有問題的詞后,根據混淆集可以獲得相應的候選,如果將可能有問題的詞替換為相應的候選后,句子的得分(通過n-gram語言模型計算得到)提高了,那么就會把可能有問題的詞替換為相應的候選,反之則還是維持現狀。依次遍歷所有可能出錯的位置,完整所有必要的替換。
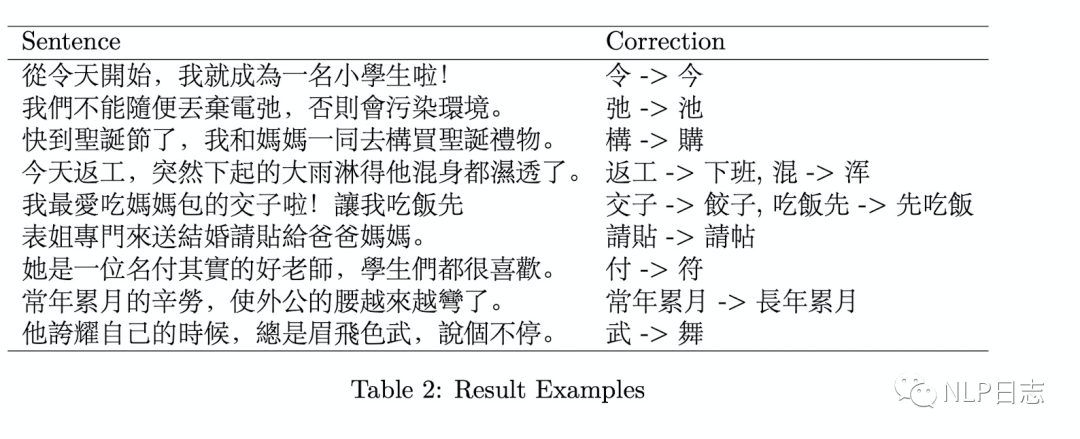
圖5: ACE的糾錯效果演示
5總結
基于pipeline的文本糾錯系統的框架都比較類似,沒有太多驚艷的操作。
a)基本必備混淆集跟語言模型,其中混淆集用于生成字符候選,語言模型用于比較不同字符在當前位置的合理性。
b) 各個模塊都是獨立運轉的,缺乏聯合優化的手段,很難協調好不同的環節的設置,子模塊的優化并不一定會導致系統整體性能的提升。例如,為了保證召回率,就需要把檢測環節放松點,導致很多正確字符都是檢測為錯誤,這樣就會導致糾正環節的準確率下降。如果把檢測任務限制得更緊,提高了糾正環節的準確率,但是相應的召回率又會下降。
c) 整個系統有較多人為的痕跡,包括規則模塊或者相關字典,泛化能力有限,后期需要一定的人力維護成本。例如更新規則或者字典等。
d) 支持解決一些比較常見的文本錯誤,但是對于稍微復雜的情形效果比較差。一方面,混淆集的構建需要成本跟時間,對于新詞或者非常見字符不友好。另一方面,n-gram語言模型作為一種統計模型,沒有考慮到句子的語義信息,效果有限。
參考文獻
1.(2010) Reducing the false alarm rate of Chinese character error detection and correction
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.185.4106&rep=rep1&type=pdf
2.(2015) Chinese Spelling Error Detection and Correction Based on Language Model, Pronunciation, and Shape
https://aclanthology.org/W14-6835.pdf
3.(2016) ACE: Automatic colloquialism, typo- graphical and orthographic errors detection for Chi- nese language.
https://aclanthology.org/C16-2041.pdf
編輯:黃飛
-
Pipeline
+關注
關注
0文章
28瀏覽量
9345 -
N-gram
+關注
關注
0文章
2瀏覽量
6611
原文標題:中文文本糾錯系列之pipeline篇
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
OpenHarmony 3.1 Beta版本關鍵特性解析——HiStreamer框架大揭秘
認證系統與糾錯碼的應用研
Pipeline ADCs Come of Age
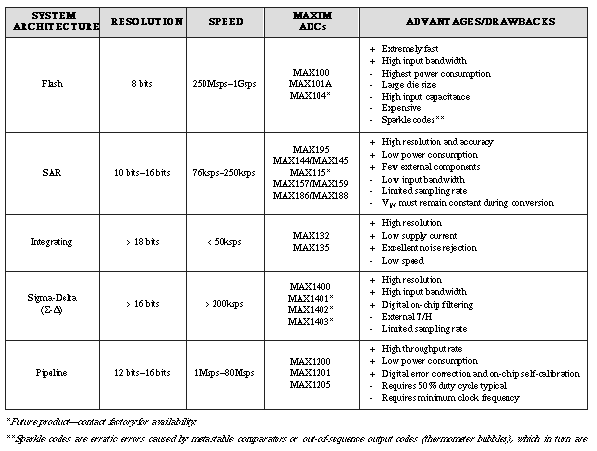
Pipeline ADCs Come of Age
網絡謠言文本句式特征分析與監測系統
基于語義的文本語義分析
如何使用Spark計算框架進行分布式文本分類方法的研究
中文文本糾錯任務
SpinalHDL里pipeline的設計思路






 工商網監
工商網監
評論