 適用于Python代碼的開源式即時編譯器NUMBA介紹
適用于Python代碼的開源式即時編譯器NUMBA介紹
Numba 是一個適用于 Python 代碼的開源式即時編譯器。借助該編譯器,開發者可以使用標準 Python 函數在 CPU 和 GPU 上加速數值函數。
什么是 NUMBA?
為了提高執行速度,Numba 會在執行前立即將 Python 字節代碼轉換為機器代碼。
Numba 可用于使用可調用的 Python 對象(稱為修飾器)來優化 CPU 和 GPU 功能。修飾器是一個函數,它將另一個函數作為輸入,進行修改,并將修改后的函數返回給用戶。這種模組化可減少編程時間,并提高 Python 的可擴展性。
Numba 還可與 NumPy 結合使用,后者是一個復雜數學運算的開源 Python 庫,專為處理統計數據而設計。調用修飾器時,Numa 將 Python 和/或 NumPy 代碼的子集轉換為針對環境自動優化的字節碼。它使用 LLVM,這是一個面向 API 的開源庫,用于以編程方式創建機器原生代碼。Numba 針對各種 CPU 和 GPU 配置,提供了多種快速并行化 Python 代碼的選項,有時僅需一條命令即可。與 NumPy 結合使用時,Numba 會為不同的數組數據類型和布局生成專用代碼,進而優化性能。
為何選擇 NUMBA?
Python 是一種廣泛應用于數據科學的高效動態編程語言。由于其采用簡潔明了的語法,并具有標準數據結構、全面的標準庫、高水準的文檔、龐大的庫和工具生態系統以及大型開放社區,因此深受歡迎。不過,也許最重要的原因是,Python 等動態型態解釋語言能夠帶來超高效率。
但是,對于 Python 來說,這既是最大的優勢,也是最大的劣勢。“它的靈活性和無類型的高級語法可能會導致數據和計算密集型程序的性能不佳,因為運行本地編譯代碼要比運行動態解釋代碼快很多倍。因此,注重效率的 Python 程序員通常會使用 C 語言重寫最內層的循環,然后從 Python 調用已編譯的 C 語言函數。許多項目都力求簡化這種優化(例如 Cython),但它們通常需要學習新的語法。雖然 Cython 顯著提高了性能,但可能需要對 Python 代碼進行艱巨的手動修改工作。
Numba 被視作 Cython 的替代方案,并且要簡單得多。它最大的吸引力在于無需學習新的語法,也無需替換 Python 解釋器、運行單獨的編譯步驟或安裝 C/C++ 編譯器。只需將@jit Numba 修飾器應用于 Python 函數即可。這樣,在運行時即可進行編譯(即“即時”或 JIT 編譯)。Numba 能夠動態編譯代碼,這意味著,您還可以享受 Python 帶來的靈活性。此外,Python 程序中由 Numba 編譯的數值算法,可以接近使用編譯后的 C 語言或 FORTRAN 語言編寫的程序的速度;并且與原生 Python 解釋器執行的相同程序相比,運行速度最多快 100 倍。這是一項重要進步,推動了高效編程與高性能計算的完美結合。
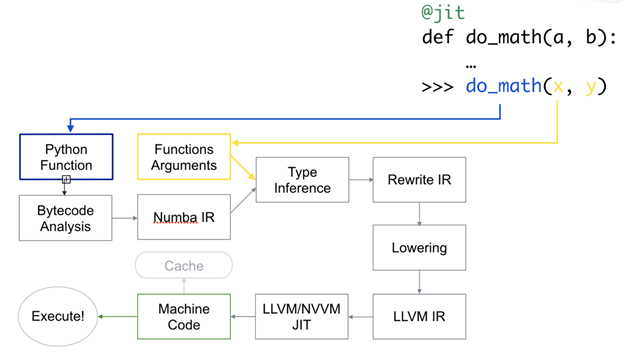
Numba 執行圖
Numba 專為面向數組的計算任務而設計,與應用廣泛的 NumPy 庫類似。在面向數組的計算任務中,數據并行性與 GPU 等加速器自然契合。Numba 理解 NumPy 數組類型,并將其用于生成高效的編譯代碼,以在 GPU 或多核 CPU 上執行。所需的編程工作非常簡單,只需添加一個 @vectorize 函數修飾器,指示 Numba 在運行時生成編譯的向量化函數版本。這樣,它便可用于在 GPU 上并行處理數據數組了。
除了為 CPU 或 GPU 即時編譯 NumPy 數組代碼外,Numba 還公開了“CUDA Python”:這是適用于 NVIDIA GPU 的 NVIDIA CUDA編程模型,采用 Python 語法編寫。加速 Python 后,它可以從膠水語言擴展至可高效執行數字代碼的完整編程環境。
Numba 與 Python 數據科學生態系統中其他工具的結合使用,改變了 GPU 計算的體驗。Jupyter Notebook 提供基于瀏覽器的文檔創建環境,允許結合使用 Markdown 文本、可執行代碼以及繪圖和圖像的圖形輸出。Jupyter 在教學、記錄科學分析和交互式原型設計領域深受歡迎。
Numba 已在 200 多種不同的平臺配置下進行了測試。它基于 Intel 和 AMD x86、POWER8/9、ARM CPU 以及 NVIDIA 和 AMD GPU 上的 Windows、Apple Macintosh、Linux 操作系統運行,大多數系統均可使用預編譯的二進制文件。
用例
科學計算
數組處理應用廣泛,從地理信息系統到計算復雜的幾何形狀,無一不及。電信公司使用數組來優化無線網絡的設計,而醫療健康研究人員則使用數組分析包含內臟器官信息的波形。數組還可用于減少語言處理、天文成像和雷達/聲納中的外部噪聲。
有了 Python 等語言,開發者無需進行大量數學訓練,即可使用這些領域的應用程序。但是,Python 在數值密集型計算中存在性能缺陷,這會嚴重影響某些應用程序的處理速度。Numba 是其中一個解決方案。許多人都認為它易于使用,因此對于沒有 C 語言等比較復雜語言經驗的學生和開發者來說,意義重大。
NUMBA 對數據科學家的重要意義
在數據科學中,迭代開發是一種非常實用的省時方案,因為開發者能夠通過觀察結果來不斷地改進程序。Python 等解釋語言在這種情景中尤為有用。但是,Python 在高度數學運算中存在性能限制,這可能會造成瓶頸,從而減緩整體處理速度并限制開發者的工作效率。
Numba 為開發者提供了一種調用編譯器函數的簡單方法,顯著提升了大型計算和數組的性能,從而解決了這一問題。Numba 簡單易學,并使數據科學家無需執行使用編譯語言編寫子程序這一復雜任務,從而加快速度。
NUMBA 為何可在 GPU 上表現更突出
在架構方面,CPU 僅由幾個具有大緩存內存的核心組成,一次只可以處理幾個軟件線程。相比之下,GPU 由數百個核心組成,可以同時處理數千個線程。

Numba 通過以下方式支持 CUDA GPU 編程:在 CUDA 執行模型后,直接將受限的 Python 代碼子集編譯到 CUDA 內核函數和設備函數中。使用 Numba 編寫的內核看起來可以直接訪問 NumPy 數組,而這些數組在 CPU 和 GPU 之間自動傳輸。這為 Python 開發者提供了一個輕松進行 GPU 加速計算的方法,而且無需學習新語法或語言,即可學會如何應用日益復雜的 CUDA 編碼。借助 CUDA Python 和 Numba,您可以一舉兩得:使用 Python 實現快速迭代開發,同時達到針對 CPU 和 NVIDIA GPU 的編譯語言的速度。
我們使用配備 NVIDIA P100 GPU 和 Intel Xeon E5-2698 v3 CPU 的服務器進行了一次測試,結果顯示,使用 Numba 編譯的 CUDA Python Mandelbrot 代碼比只使用 Python 快了近 1700 倍。與 CPU 上的單線程 Python 代碼相比,性能提升是多個因素的共同作用,包括編譯、并行化和 GPU 加速。但是,它說明單是添加一個 GPU 即可實現加速。
NVIDIA GPU 加速的端到端數據科學
基于 CUDA-X AI 創建的 NVIDIA RAPIDS開源軟件庫套件使您完全能夠在 GPU 上執行端到端數據科學和分析流程。此套件依靠 NVIDIA CUDA 基元進行低級別計算優化,但通過用戶友好型 Python 接口實現了 GPU 并行化和高帶寬顯存速度。
借助 RAPIDS GPU DataFrame,數據可以通過一個類似 Pandas 的接口加載到 GPU 上,然后用于各種連接的機器學習和圖形分析算法,而無需離開 GPU。這種級別的互操作性可通過 Apache Arrow 等庫實現,并有助于實現端到端流程(從數據準備到機器學習再到深度學習)的加速。
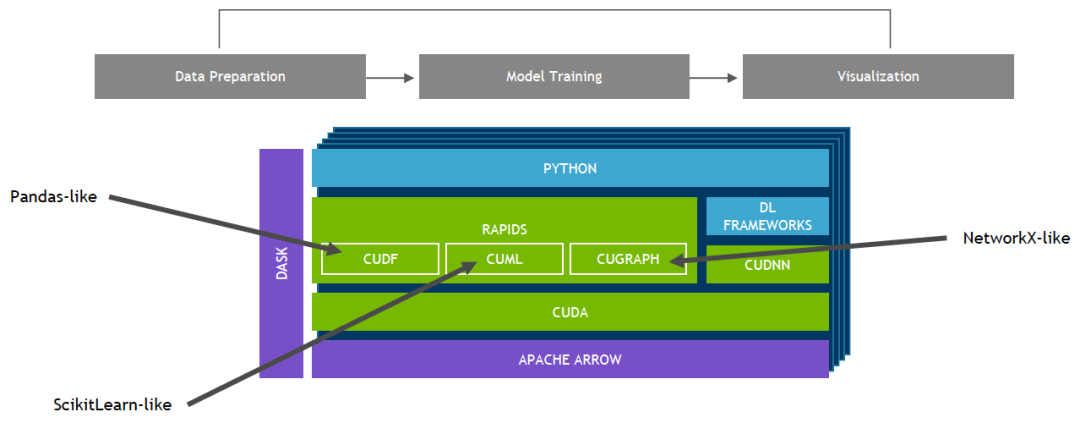
RAPIDS 支持在許多熱門數據科學庫之間共享設備內存。這樣可將數據保留在 GPU 上,并省去了來回復制主機內存的高昂成本。
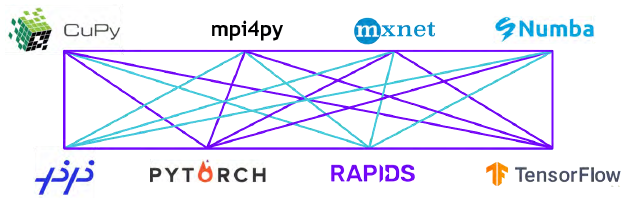
RAPIDS 團隊正在開發和參與許多開源項目,并與眾多開源項目(包括 Apache Arrow、Numba、XGBoost、Apache Spark、scikit-learn 等)密切協作,確保 GPU 加速數據科學生態系統中的所有組件順暢地協同工作。
審核編輯:湯梓紅
-
cpu
+關注
關注
68文章
10825瀏覽量
211140 -
NVIDIA
+關注
關注
14文章
4936瀏覽量
102813 -
編譯器
+關注
關注
1文章
1618瀏覽量
49049 -
python
+關注
關注
56文章
4782瀏覽量
84452
原文標題:NVIDIA 大講堂 | 什么是 NUMBA ?
文章出處:【微信號:NVIDIA_China,微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
NVIDIA推出適用于網絡安全的NIM Blueprint
適用于MSP430? MCU的Code Composer Studio(代碼調試器)? IDE v10.x

適用于可擴展系統的高效、無代碼、無傳感器BLDC電機驅動器
AI編譯器技術剖析
人工智能編譯器與傳統編譯器的區別
Meta發布基于Code Llama的LLM編譯器
SEGGER編譯器優化和安全技術介紹 支持最新C和C++語言

C語言:嵌入式開發中的關鍵編譯器角色
微軟正式發布適用于Windows的Sudo

Triton編譯器的原理和性能

TVM編譯器的整體架構和基本方法





 工商網監
工商網監
評論