 如何更高效地使用預訓練語言模型
如何更高效地使用預訓練語言模型
概覽
本文對任務低維本征子空間的探索是基于 prompt tuning, 而不是fine-tuning。原因是預訓練模型的參數實在是太多了,很難找到這么多參數的低維本征子空間。作者基于之前的工作提出了一個基本的假設:預訓練模型在不同下游任務上學習的過程,可以被重新參數化(reparameterized)為在同一個低維本征子空間上的優化過程。如下圖所示,模型在不同的任務上學習的參數雖然不同,但這些參數共享了同一個低維本征子空間。
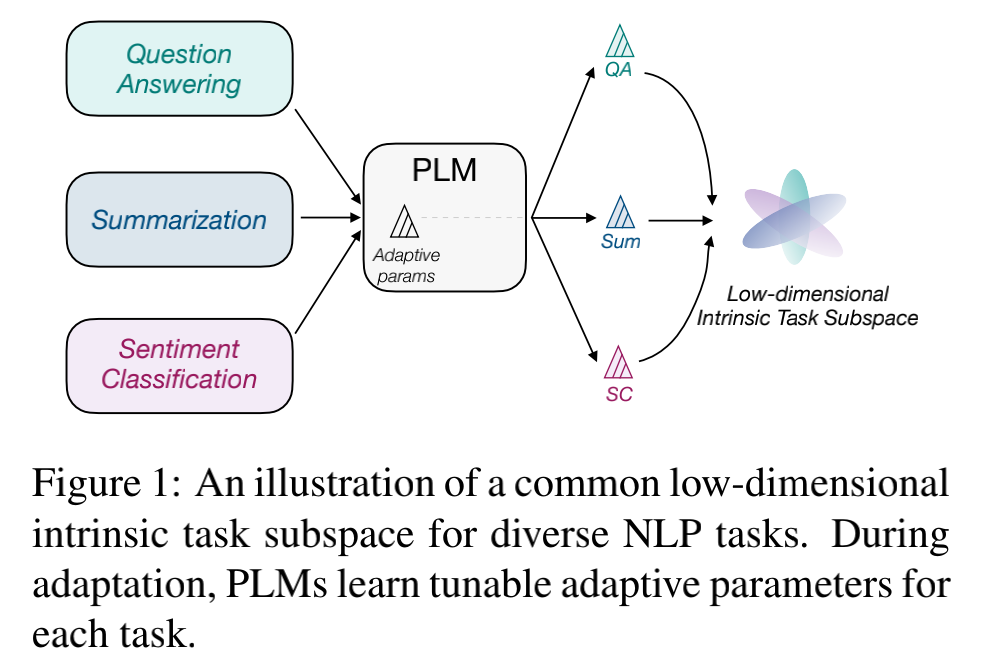
基于這一假設,作者提出了探索公共低維本征子空間的方法:intrinsic prompt tuning (IPT)。
IPT由兩個階段組成:
Multi-task Subspace Finding (MSF):尋找多個任務的公共子空間,這是一個低維的、更為本征的一個空間
Intrinsic Subspace Tuning (IST):在找到的公共本征子空間上進行模型優化
下圖展示了 IPT 與 fine-tuning 和 prompt tuning 的對比。
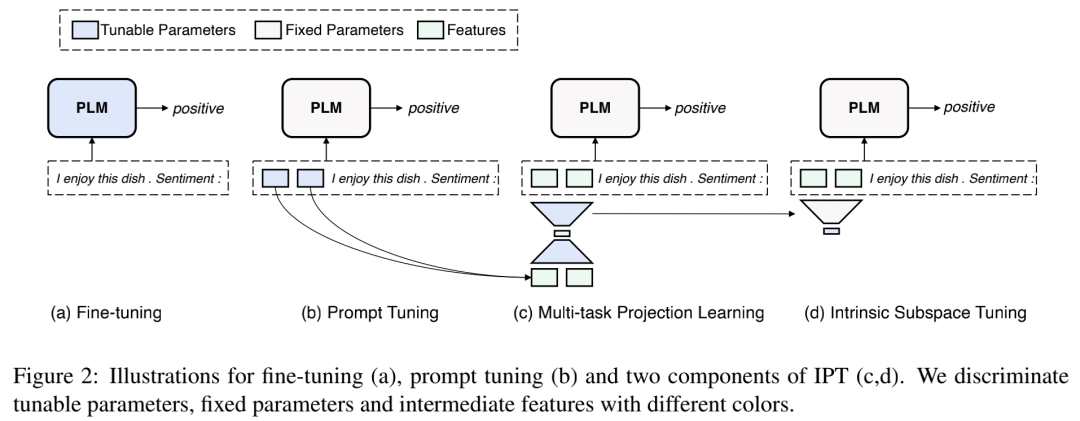
下面我們具體來了解一下IPT的兩個階段
IPT
作者使用intrinsic prompt tuning (IPT)來驗證本文的基本假設: 預訓練模型對多個不同下游任務的學習可以被重新參數化為在同一個低維本征子空間上的優化。
第一個階段是multi-task subspace finding (MSF)。
1. 尋找公共本征子空間(MSF)
MSF階段旨在通過對多個任務進行學習,來找到公共的低維本征子空間。如上圖所示,本質上就是在學習一個自編碼器。
我們用 來代表自編碼器的Encoder部分(上圖中處于下方的梯形),用 來代表自編碼器的Decoder部分(上圖中處于上方的梯形),那么自編碼器會先用把Prompt參數映射為一個低維(維)的向量(向量所在的維空間就是我們想要的低維本征子空間),然后再用把該低維向量重新映射回原始的prompt空間,得到 這樣我們就可以使用 和 的距離來計算自編碼器的重建loss ,形式化表述就是:
另外,使用自編碼器來學習公共低維本征子空間的最終目的還是為了解決多個任務,所以作者引入了面向任務的語言模型loss 來提供任務相關的監督(例如圖中模型生成的結果"positive"和正確標簽之間的交叉熵)。那么MSF階段最終的loss就是:
其中 代表 和 的參數,這也是我們在MSF階段要學習的參數。
2. 本征子空間優化(IST)
在MSF階段中,我們通過對多個任務的學習找到了維的公共本征子空間,然后就進入了第二個階段IST。在這一階段中,我們想評價我們在MSF階段中找到的低維本征子空間是不是能夠很好的泛化到 (a) MSF階段訓練過的任務的新數據,以及 (b) MSF階段沒有訓練過的任務。如果該低維本征子空間在這兩種情況下都有比較好的泛化性能的話,那么在我們在一定程度上就成功地找到了想要的本征子空間。
在本階段中,如上圖 所示, 我們只保留自編碼器的Decoder部分并凍結它的參數。對于每個測試任務,我們只微調本征子空間中的個自由參數 , 會將解碼回原始的prompt空間中來計算loss:
實驗
作者使用了120個few-shot任務來進行實驗,并進行了三種不同的訓練-測試任務劃分
random: 隨機選擇100個任務作為訓練任務,其余20個任務作為測試任務
non-cls: 隨機選擇非分類任務中的35作為訓練任務,其余所有任務作為測試任務
cls: 隨機選擇分類任務中的35個作為訓練任務,其余所有任務作為測試任務
同時,對每一種任務劃分,作者進行了5種不同的實驗
: 在MSF階段,直接使用學習到的低維本征子空間來評估訓練任務在訓練數據上的性能
: 在MSF階段,直接使用學習到的低維本征子空間來評估測試任務(0-shot)的泛化性能
: 在IST階段,微調學習到的低維本征子空間來評估訓練任務在訓練數據上的性能
: 在IST階段,微調學習到的低維本征子空間來評估訓練任務在新數據上的泛化性能
: 在IST階段,微調學習到的低維本征子空間來評估測試任務的泛化性能
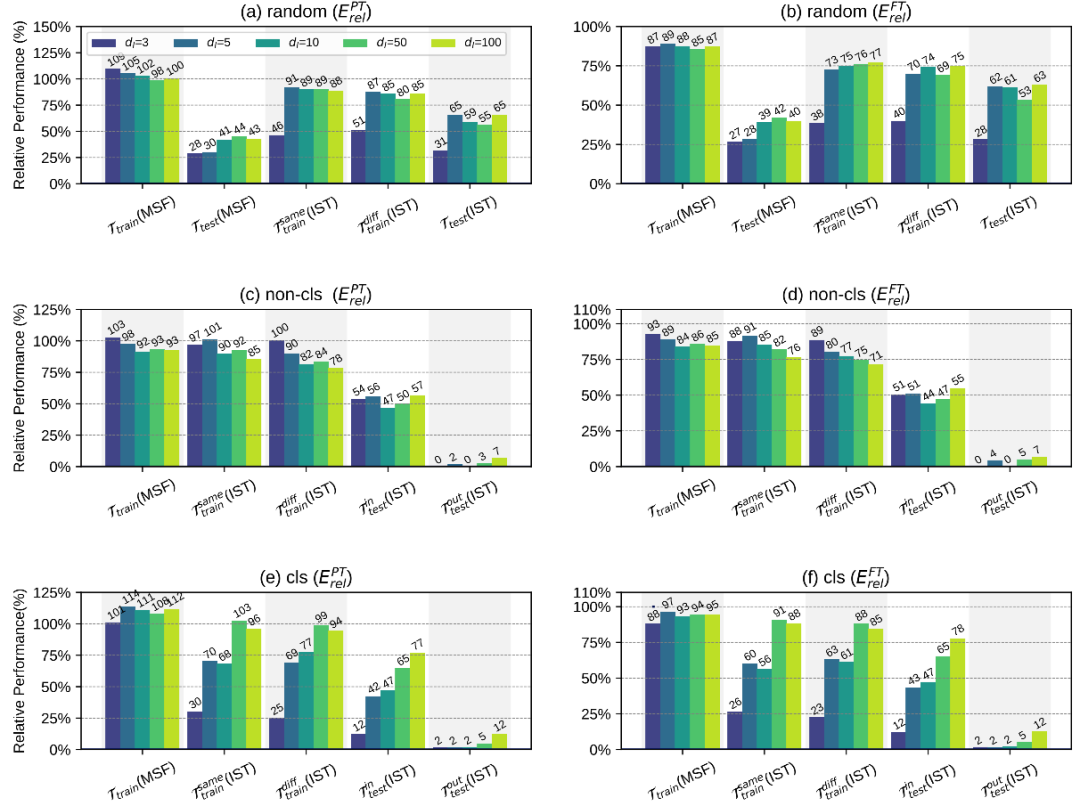
整體的實驗結果如上圖所示,作者通過分析不同實驗的結果,得出了一些比較重要的結論:
在random劃分中,僅僅微調低維本征子空間中的5個自由參數,就可以分別獲得full prompt tuning 87%(訓練過的任務,不同訓練數據)以及65%(未訓練過的任務)的性能,這證明我們在MSF階段中找到的低維本征子空間是比較有效的。但從另一個方面來講,使用低維本征子空間無法獲得和full prompt tuning相當的性能,所以我們不能直接得出預訓練模型對多個任務的學習可以被重新參數化為在完全相同的子空間中的優化的結論。
訓練-測試任務的劃分會對結果有很大的影響。比如在cls劃分中,訓練時找到的本征子空間可以在分類的測試任務上有比較合理的表現,但在非分類的測試任務上表現很差。
隨著MSF階段中訓練任務數量的增加,找到的本征子空間的泛化能力會有所提高。這反映了增加MSF階段中訓練任務的覆蓋范圍和多樣性可以幫助IPT找到更通用的本征子空間。
結論
本文設計了IPT框架來驗證提出的假設: 預訓練模型對多個不同下游任務的學習可以被重新參數化為在同一個低維本征子空間上的優化。詳盡的實驗為假設提供了一定的積極證據,也幫助大家對如何更高效地使用預訓練語言模型有了更好的了解。
思考
雖然文章中的實驗結果不能直接驗證“預訓練模型對多個任務的學習可以被重新參數化為在完全相同的子空間中的優化”這一假設是完全正確的,但起碼它證明了各種任務重參數化后的低維子空間是有比較大的交集的,而且我們可以通過MSF來找到這個交集。
審核編輯:郭婷
-
編碼器
+關注
關注
44文章
3530瀏覽量
133323
原文標題:Prompt Learning | 五個參數解決下游任務 fine-tuning
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
預訓練和遷移學習的區別和聯系
LLM預訓練的基本概念、基本原理和主要優勢
預訓練模型的基本原理和應用
【大語言模型:原理與工程實踐】大語言模型的應用
【大語言模型:原理與工程實踐】大語言模型的預訓練
【大語言模型:原理與工程實踐】大語言模型的基礎技術
【大語言模型:原理與工程實踐】探索《大語言模型原理與工程實踐》
名單公布!【書籍評測活動NO.30】大規模語言模型:從理論到實踐
大語言模型推斷中的批處理效應






 工商網監
工商網監
評論