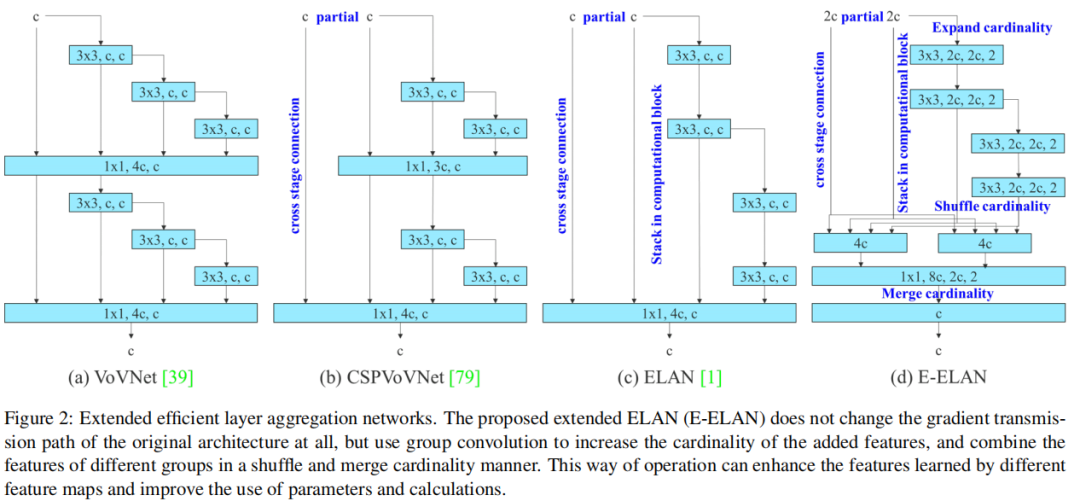
 基于ELAN的Extended-ELAN (E-ELAN)
基于ELAN的Extended-ELAN (E-ELAN)
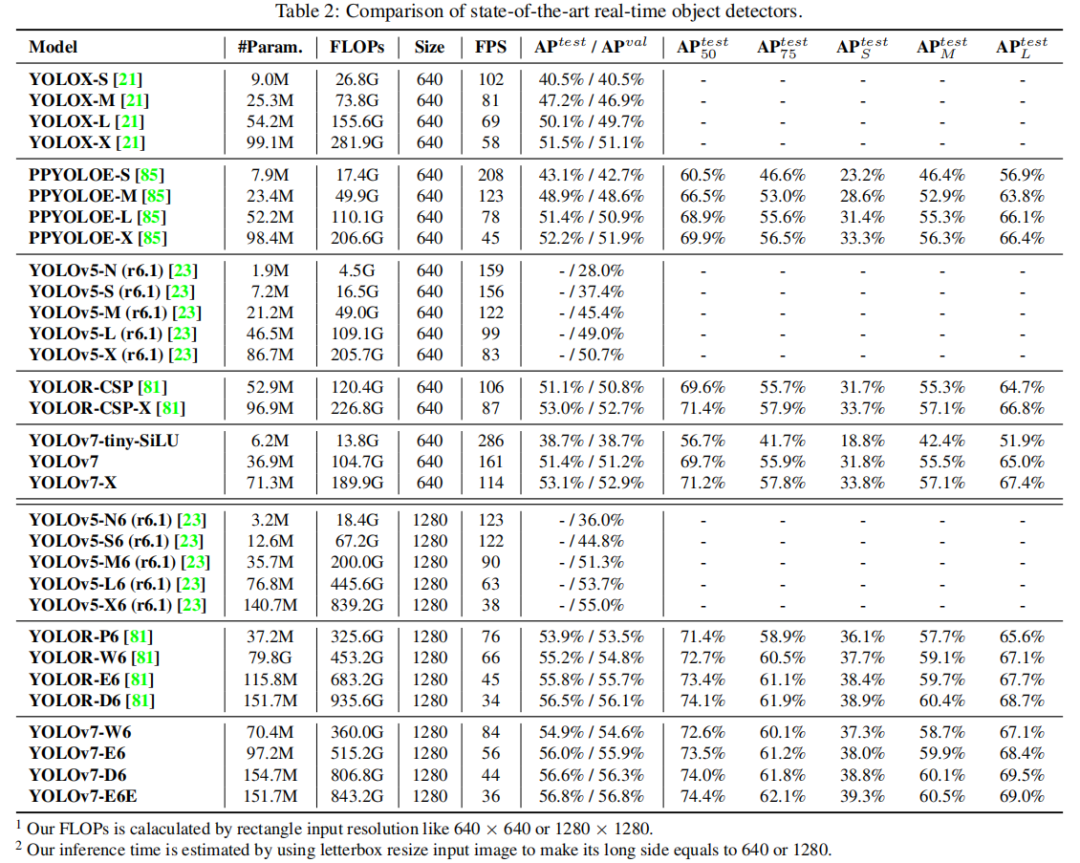
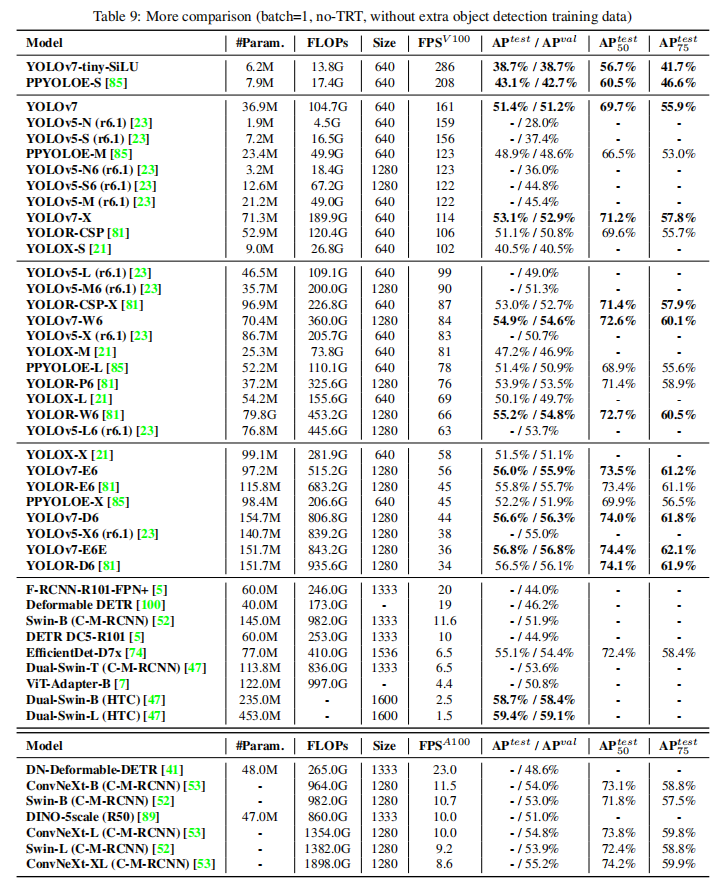
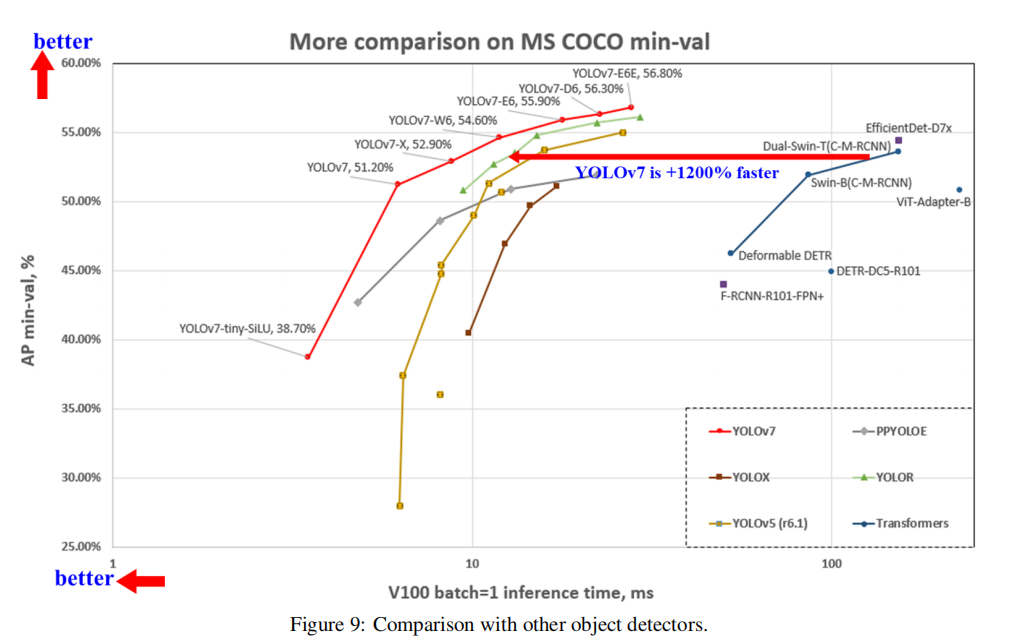
YOLOv7在 5 FPS 到 160 FPS 范圍內的速度和準確度都超過了所有已知的目標檢測器,并且在 GPU V100 上 30 FPS 或更高的所有已知實時目標檢測器中具有最高的準確度 56.8% AP。
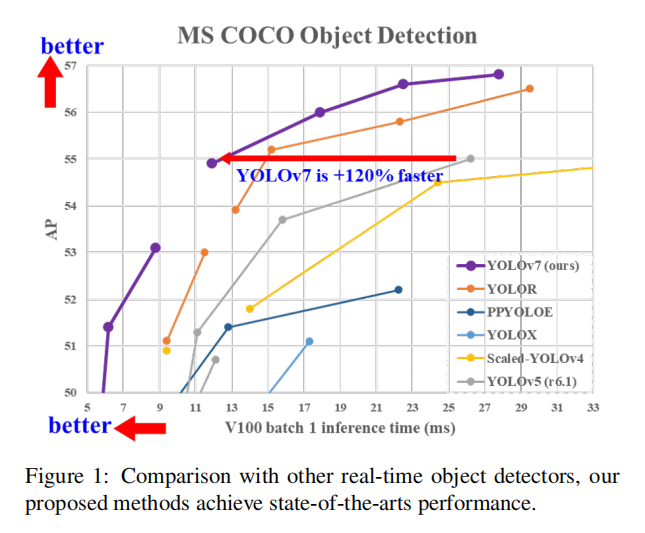
YOLOv7-E6目標檢測器(56 FPS V100,55.9% AP)比基于Transformer的檢測器SWIN-L Cascade-Mask R-CNN(9.2 FPS A100,53.9% AP)的速度和準確度分別高出 509% 和 2%,并且比基于卷積的檢測器ConvNeXt-XL Cascade-Mask R-CNN(8.6 FPS A100, 55.2% AP) 速度提高 551%,準確率提高 0.7%,以及YOLOv7的表現還優于:YOLOR、YOLOX、Scaled-YOLOv4、YOLOv5、DETR、Deformable DETR、DINO-5scale-R50、ViT-Adapter-B和許多其他速度和準確度的目標檢測器。此外,只在MS COCO數據集上從零開始訓練YOLOv7,而不使用任何其他數據集或預訓練的權重。
1模型設計
1.1、擴展的高效層聚合網絡
在大多數關于設計高效架構的文獻中,主要考慮因素不超過參數的數量、計算量和計算密度。Ma 等人還從內存訪問成本的特點出發,分析了輸入/輸出通道比、架構的分支數量以及element-wise 操作對網絡推理速度的影響。多爾阿爾等人在執行模型縮放時還考慮了激活,即更多地考慮卷積層輸出張量中的元素數量。
-
圖 2(b)中
CSPVoVNet的設計是VoVNet的一種變體。CSPVoVNet的架構除了考慮上述基本設計問題外,還分析了梯度路徑,以使不同層的權重能夠學習到更多樣化的特征。上述梯度分析方法使推理更快、更準確。 -
圖 2 (c) 中的
ELAN考慮了以下設計策略——“如何設計一個高效的網絡?”。他們得出了一個結論:通過控制最短最長的梯度路徑,更深的網絡可以有效地學習和收斂。
在本文中,作者提出了基于ELAN的Extended-ELAN (E-ELAN),其主要架構如圖 2(d)所示。
無論梯度路徑長度和大規模ELAN中計算塊的堆疊數量如何,它都達到了穩定狀態。如果無限堆疊更多的計算塊,可能會破壞這種穩定狀態,參數利用率會降低。作者提出的E-ELAN使用expand、shuffle、merge cardinality來實現在不破壞原有梯度路徑的情況下不斷增強網絡學習能力的能力。
在架構方面,E-ELAN只改變了計算塊的架構,而過渡層的架構完全沒有改變。策略是使用組卷積來擴展計算塊的通道和基數。將對計算層的所有計算塊應用相同的組參數和通道乘數。然后,每個計算塊計算出的特征圖會根據設置的組參數g被打亂成g個組,然后將它們連接在一起。此時,每組特征圖的通道數將與原始架構中的通道數相同。最后,添加 g 組特征圖來執行合并基數。E-ELAN除了保持原有的ELAN設計架構外,還可以引導不同組的計算塊學習更多樣化的特征。
1.2、基于concatenate模型的模型縮放
模型縮放的主要目的是調整模型的一些屬性,生成不同尺度的模型,以滿足不同推理速度的需求。例如,EfficientNet的縮放模型考慮了寬度、深度和分辨率。對于Scale-yolov4,其縮放模型是調整階段數。Doll‘ar等人分析了卷積和群卷積對參數量和計算量的影響,并據此設計了相應的模型縮放方法。
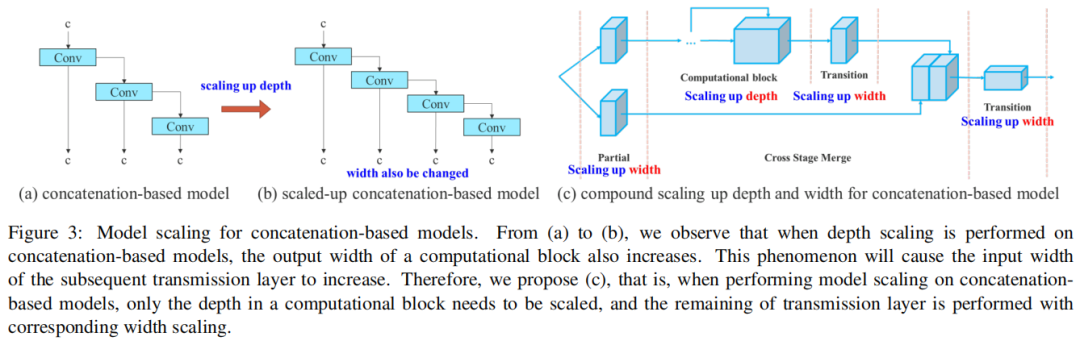
上述方法主要用于諸如PlainNet或ResNet等架構中。當這些架構在執行放大或縮小過程時,每一層的in-degree和out-degree都不會發生變化,因此可以獨立分析每個縮放因子對參數量和計算量的影響。然而,如果這些方法應用于基于concatenate的架構時會發現當擴大或縮小執行深度,基于concatenate的轉換層計算塊將減少或增加,如圖3(a)和(b).所示
從上述現象可以推斷,對于基于concatenate的模型不能單獨分析不同的縮放因子,而必須一起考慮。以scaling-up depth為例,這樣的動作會導致transition layer的輸入通道和輸出通道的比例發生變化,這可能會導致模型的硬件使用率下降。
因此,必須為基于concatenate的模型提出相應的復合模型縮放方法。當縮放一個計算塊的深度因子時,還必須計算該塊的輸出通道的變化。然后,將對過渡層進行等量變化的寬度因子縮放,結果如圖3(c)所示。本文提出的復合縮放方法可以保持模型在初始設計時的特性并保持最佳結構。
2訓練方法
2.1 Planned re-parameterized convolution
盡管RepConv在VGG基礎上取得了優異的性能,但當將它直接應用于ResNet、DenseNet和其他架構時,它的精度將顯著降低。作者使用梯度流傳播路徑來分析重參數化的卷積應該如何與不同的網絡相結合。作者還相應地設計了計劃中的重參數化的卷積。
RepConv實際上結合了3×3卷積,1×1卷積,和在一個卷積層中的id連接。通過分析RepConv與不同架構的組合及其性能,作者發現RepConv中的id連接破壞了ResNet中的殘差和DenseNet中的連接,為不同的特征圖提供了更多的梯度多樣性。
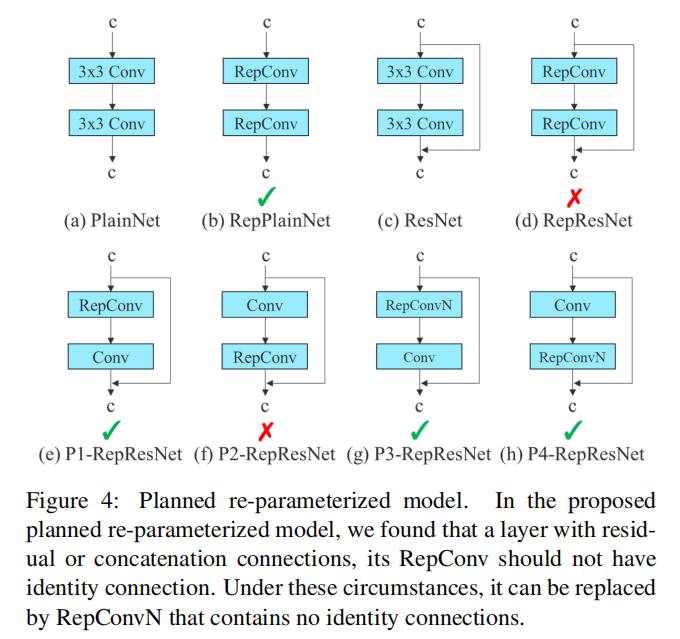
基于上述原因,作者使用沒有id連接的RepConv(RepConvN)來設計計劃中的重參數化卷積的體系結構。在作者的思維中,當具有殘差或連接的卷積層被重新參數化的卷積所取代時,不應該存在id連接。圖4顯示了在PlainNet和ResNet中使用的“Planned re-parameterized convolution”的一個示例。對于基于殘差的模型和基于concatenate的模型中Planned re-parameterized convolution實驗,它將在消融研究環節中提出。
2.2 標簽匹配
深度監督是一種常用于訓練深度網絡的技術。其主要概念是在網絡的中間層增加額外的auxiliary Head,以及以auxiliary損失為導向的淺層網絡權值。即使對于像ResNet和DenseNet這樣通常收斂得很好的體系結構,深度監督仍然可以顯著提高模型在許多任務上的性能。圖5(a)和(b)分別顯示了“沒有”和“有”深度監督的目標檢測器架構。在本文中,將負責最終輸出的Head為lead Head,將用于輔助訓練的Head稱為auxiliary Head。
過去,在深度網絡的訓練中,標簽分配通常直接指GT,并根據給定的規則生成硬標簽。然而,近年來,如果以目標檢測為例,研究者經常利用網絡預測輸出的質量和分布,然后結合GT考慮,使用一些計算和優化方法來生成可靠的軟標簽。例如,YOLO使用邊界框回歸預測和GT的IoU作為客觀性的軟標簽。在本文中,將網絡預測結果與GT一起考慮,然后將軟標簽分配為“label assigner”的機制。
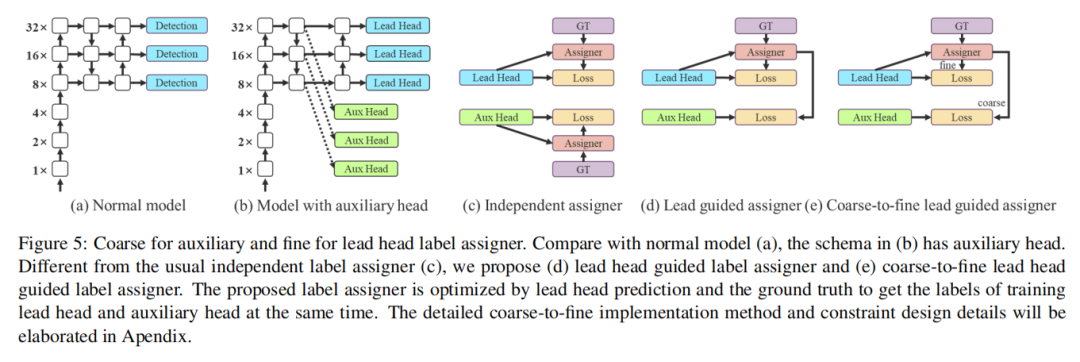
無論auxiliary Head或lead Head的情況如何,都需要對目標目標進行深度監督培訓。在軟標簽分配人相關技術的開發過程中,偶然發現了一個新的衍生問題,即“如何將軟標簽分配給auxiliary head和lead head?”據我們所知,相關文獻迄今尚未對這一問題進行探討。目前最常用的方法的結果如圖5(c)所示,即將auxiliary head和lead head分開,然后使用它們自己的預測結果和GT來執行標簽分配。本文提出的方法是一種新的標簽分配方法,通過lead head預測來引導auxiliary head和lead head。換句話說,使用lead head預測作為指導,生成從粗到細的層次標簽,分別用于auxiliary head和lead head的學習。所提出的2種深度監督標簽分配策略分別如圖5(d)和(e)所示。
1、Lead head guided label assigner
lead head引導標簽分配器主要根據lead head的預測結果和GT進行計算,并通過優化過程生成軟標簽。這組軟標簽將作為auxiliary head和lead head的目標訓練模型。這樣做的原因是lead head具有相對較強的學習能力,因此由此產生的軟標簽應該更能代表源數據與目標之間的分布和相關性。此外,還可以將這種學習看作是一種generalized residual learning。通過讓較淺的auxiliary head直接學習lead head已經學習到的信息,lead head將更能專注于學習尚未學習到的殘余信息。
2、Coarse-to-fine lead head guided label assigner
從粗到細的lead head引導標簽分配器也使用lead head的預測結果和GT來生成軟標簽。然而,在這個過程中,生成了兩組不同的軟標簽,即粗標簽和細標簽,其中細標簽與lead head引導標簽分配器生成的軟標簽相同,而粗標簽是通過允許更多的網格來生成的。通過放寬正樣本分配過程的約束,將其視為正目標。原因是auxiliary head的學習能力不如前lead head強,為了避免丟失需要學習的信息,將重點優化auxiliary head的召回率。
至于lead head的輸出,可以從高recall結果中過濾出高精度結果作為最終輸出。但是,必須注意,如果粗標簽的附加權重接近細標簽的附加權重,則可能會在最終預測時產生不良先驗。因此,為了使那些超粗的正網格影響更小,在解碼器中設置了限制,使超粗的正網格不能完美地產生軟標簽。上述機制允許在學習過程中動態調整細標簽和粗標簽的重要性,使細標簽的可優化上界始終高于粗標簽。
2.3 其他Tricks
這些免費的訓練細節將在附錄中詳細說明,包括:(1)conv-bn-activation topology中的Batch normalization:這部分主要將batch normalization layer直接連接到卷積層。這樣做的目的是在推理階段將批歸一化的均值和方差整合到卷積層的偏差和權重中。
(2) 隱性知識在YOLOR中結合卷積特征圖的加法和乘法方式:YOLOR中的隱式知識可以在推理階段通過預計算簡化為向量。該向量可以與前一個或后一個卷積層的偏差和權重相結合。
(3)EMA模型:EMA是一種在mean teacher中使用的技術,在系統中使用EMA模型純粹作為最終的推理模型。
3實驗
3.1 精度對比
3.2 速度精度對比
審核編輯 :李倩
-
檢測器
+關注
關注
1文章
860瀏覽量
47651 -
數據集
+關注
關注
4文章
1205瀏覽量
24644 -
ELAN
+關注
關注
0文章
3瀏覽量
5116
原文標題:YOLOv7官方開源 | Alexey Bochkovskiy站臺,精度速度超越所有YOLO,還得是AB
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
網線cat6e是什么標準
hsyu-5e網線是什么?
TIDP.SAA接口怎么實現I2C Read Extended功能?
cat5e屬于什么網線
cat6e網線支持千兆嗎
utp6e網線和cat6e網線區別
電力煤礦跑冒滴漏監測系統

詳解TSMaster CAN 與 CANFD 的 CRC E2E 校驗方法

小鵬汽車與大眾汽車宣布簽署E/E架構技術合作框架協議

低功耗250nA IQ和小尺寸電源電壓監控器TLV803E、TLV809E、TLV810E數據表

單電源RS-232收發器 UM3221E/UM3222E/UM3232E數據手冊

E型載波系統基礎知識





 工商網監
工商網監
評論