 Imagen的工作原理解讀
Imagen的工作原理解讀
本文詳細解讀了 Imagen 的工作原理,分析并理解其高級組件以及它們之間的關聯。
近年來,多模態學習受到重視,特別是文本 - 圖像合成和圖像 - 文本對比學習兩個方向。一些 AI 模型因在創意圖像生成、編輯方面的應用引起了公眾的廣泛關注,例如 OpenAI 先后推出的文本圖像模型 DALL?E 和 DALL-E 2,以及英偉達的 GauGAN 和 GauGAN2。 谷歌也不甘落后,在 5 月底發布了自己的文本到圖像模型 Imagen,看起來進一步拓展了字幕條件(caption-conditional)圖像生成的邊界。

僅僅給出一個場景的描述,Imagen 就能生成高質量、高分辨率的圖像,無論這種場景在現實世界中是否合乎邏輯。下圖為 Imagen 文本生成圖像的幾個示例,在圖像下方顯示出了相應的字幕。

這些令人印象深刻的生成圖像不禁讓人想了解:Imagen 到底是如何工作的呢? 近期,開發者講師 Ryan O'Connor 在 AssemblyAI 博客撰寫了一篇長文《How Imagen Actually Works》,詳細解讀了 Imagen 的工作原理,對 Imagen 進行了概覽介紹,分析并理解其高級組件以及它們之間的關聯。 Imagen 工作原理概覽 在這部分,作者展示了 Imagen 的整體架構,并對其它的工作原理做了高級解讀;然后依次更透徹地剖析了 Imagen 的每個組件。如下動圖為 Imagen 的工作流程。
首先,將字幕輸入到文本編碼器。該編碼器將文本字幕轉換成數值表示,后者將語義信息封裝在文本中。Imagen 中的文本編碼器是一個 Transformer 編碼器,其確保文本編碼能夠理解字幕中的單詞如何彼此關聯,這里使用自注意力方法。 如果 Imagen 只關注單個單詞而不是它們之間的關聯,雖然可以獲得能夠捕獲字幕各個元素的高質量圖像,但描述這些圖像時無法以恰當的方式反映字幕語義。如下圖示例所示,如果不考慮單詞之間的關聯,就會產生截然不同的生成效果。

雖然文本編碼器為 Imagen 的字幕輸入生成了有用的表示,但仍需要設計一種方法生成使用這一表示的圖像,也即圖像生成器。為此,Imagen 使用了擴散模型,它是一種生成模型,近年來得益于其在多項任務上的 SOTA 性能而廣受歡迎。 擴散模型通過添加噪聲來破壞訓練數據以實現訓練,然后通過反轉這個噪聲過程來學習恢復數據。給定輸入圖像,擴散模型將在一系列時間步中迭代地利用高斯噪聲破壞圖像,最終留下高斯噪聲或電視噪音靜態(TV static)。下圖為擴散模型的迭代噪聲過程:

然后,擴散模型將向后 work,學習如何在每個時間步上隔離和消除噪聲,抵消剛剛發生的破壞過程。訓練完成后,模型可以一分為二。這樣可以從隨機采樣高斯噪聲開始,使用擴散模型逐漸去噪以生成圖像,具體如下圖所示:

總之,經過訓練的擴散模型從高斯噪聲開始,然后迭代地生成與訓練圖像類似的圖像。很明顯的是,無法控制圖像的實際輸出,僅僅是將高斯噪聲輸入到模型中,并且它會輸出一張看起來屬于訓練數據集的隨機圖像。 但是,目標是創建能夠將輸入到 Imagen 的字幕的語義信息封裝起來的圖像,因此需要一種將字幕合并到擴散過程中的方法。如何做到這一點呢? 上文提到文本編碼器產生了有代表性的字幕編碼,這種編碼實際上是向量序列。為了將這一編碼信息注入到擴散模型中,這些向量被聚合在一起,并在它們的基礎上調整擴散模型。通過調整這一向量,擴散模型學習如何調整其去噪過程以生成與字幕匹配良好的圖像。過程可視化圖如下所示:
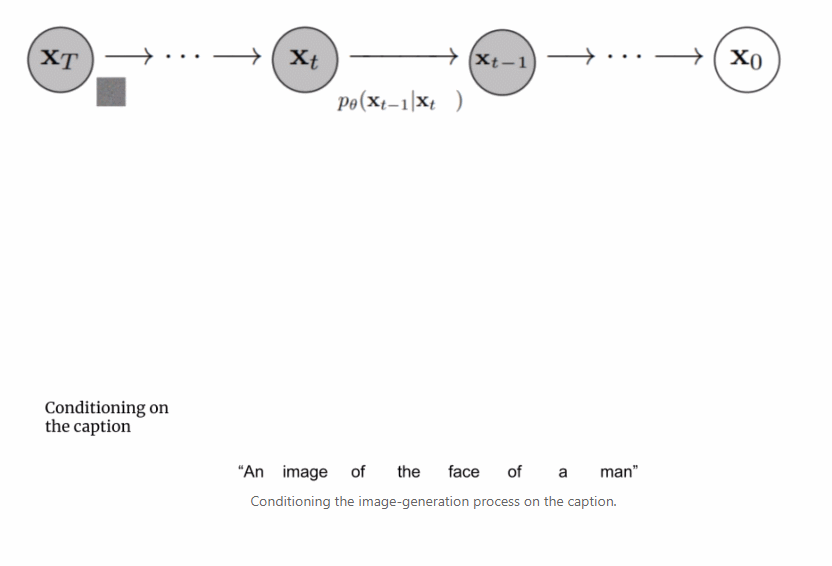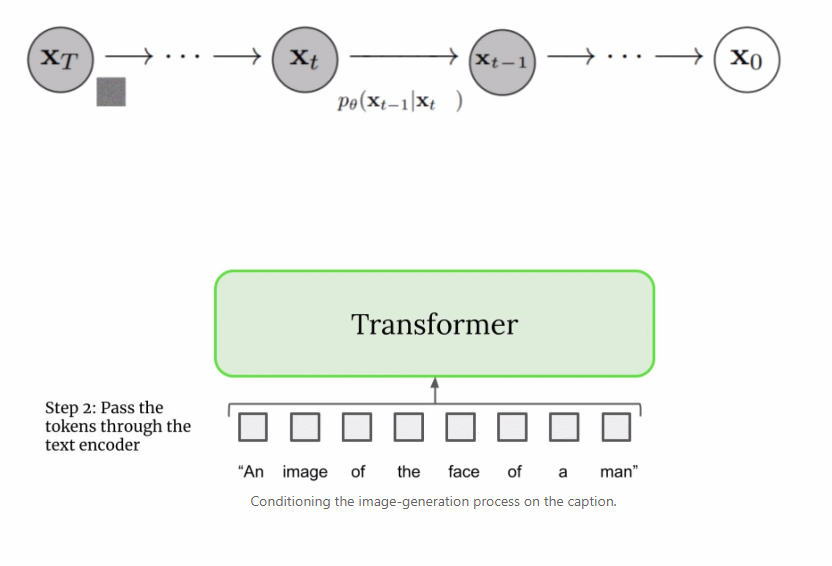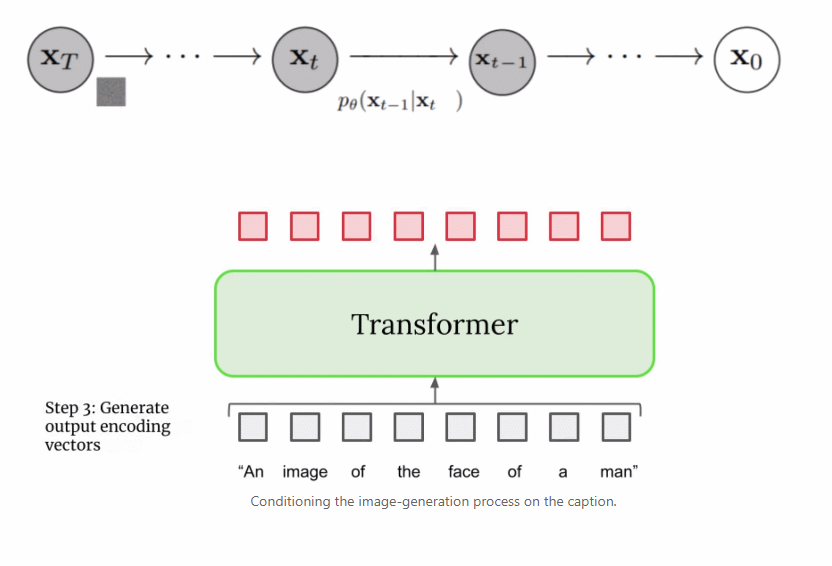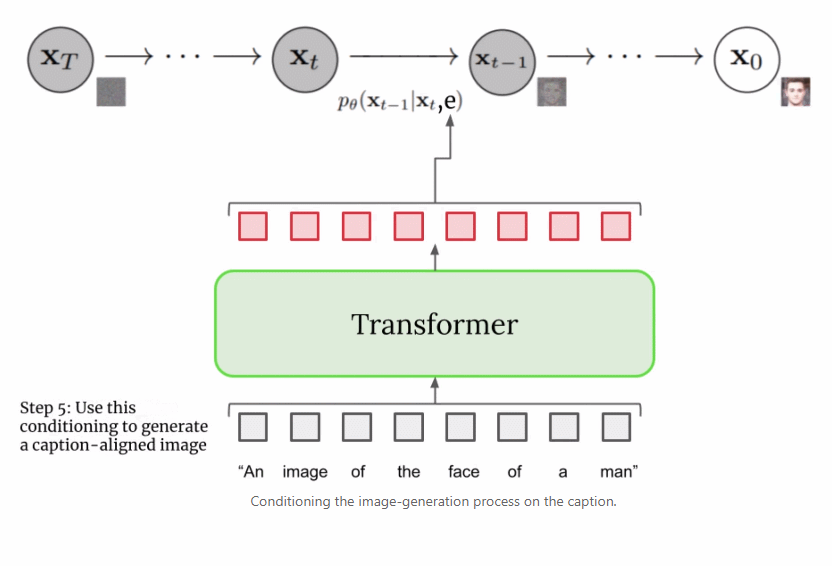
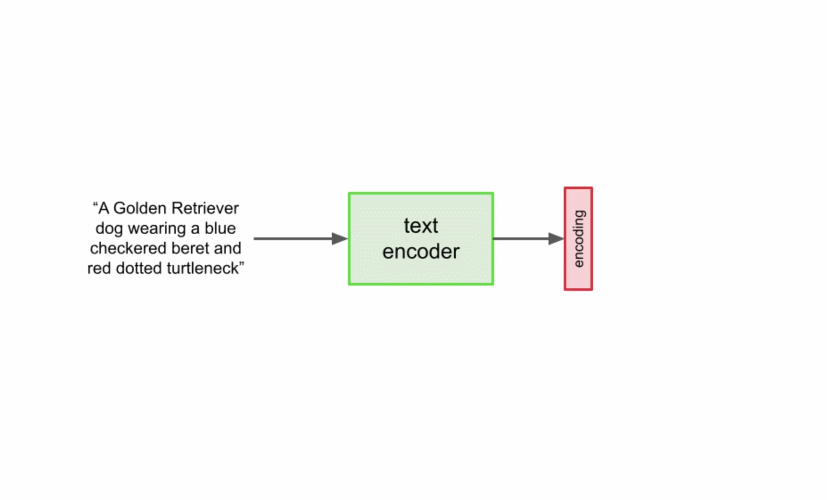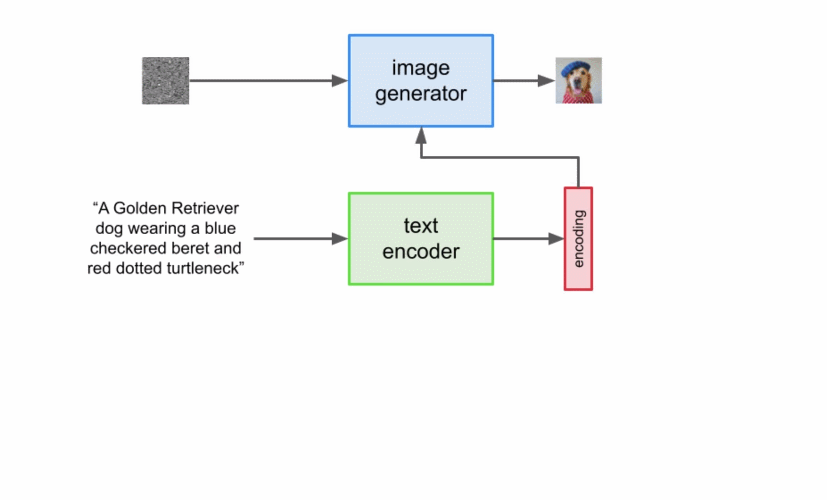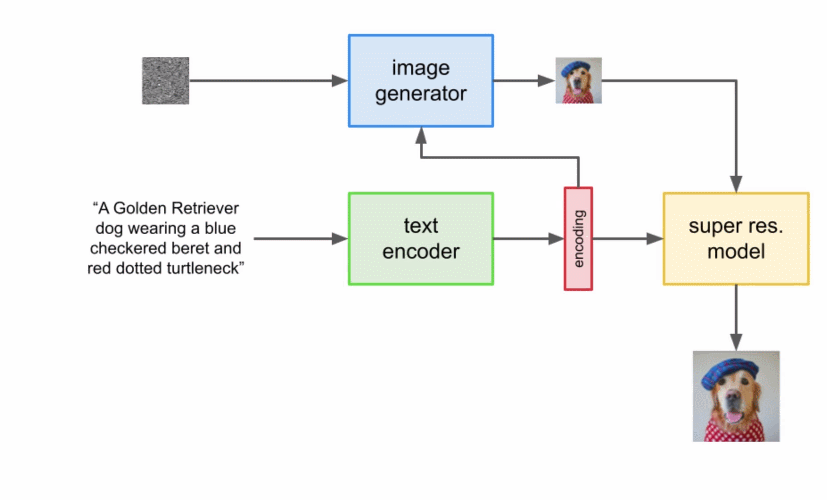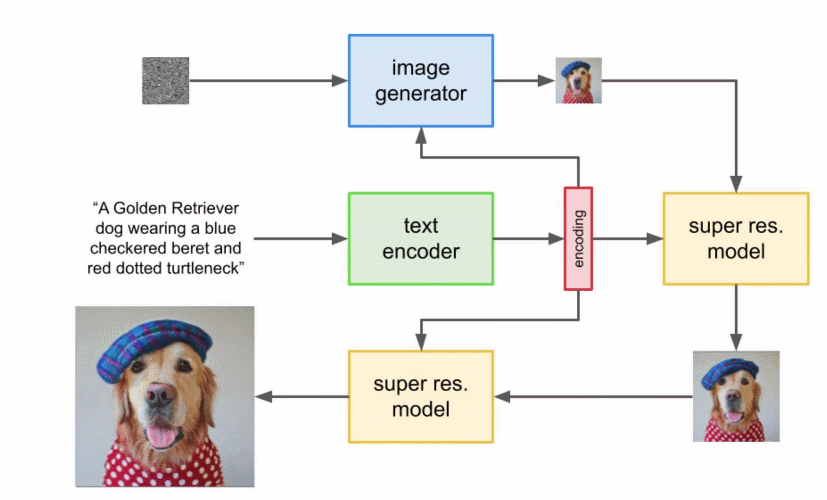
由于圖像生成器或基礎模型輸出一個小的 64x64 圖像,為了將這一模型上采樣到最終的 1024x1024 版本,使用超分辨率模型智能地對圖像進行上采樣。 對于超分辨率模型,Imagen 再次使用了擴散模型。整體流程與基礎模型基本相同,除了僅僅基于字幕編碼調整外,還以正在上采樣的更小圖像來調整。整個過程的可視化圖如下所示:
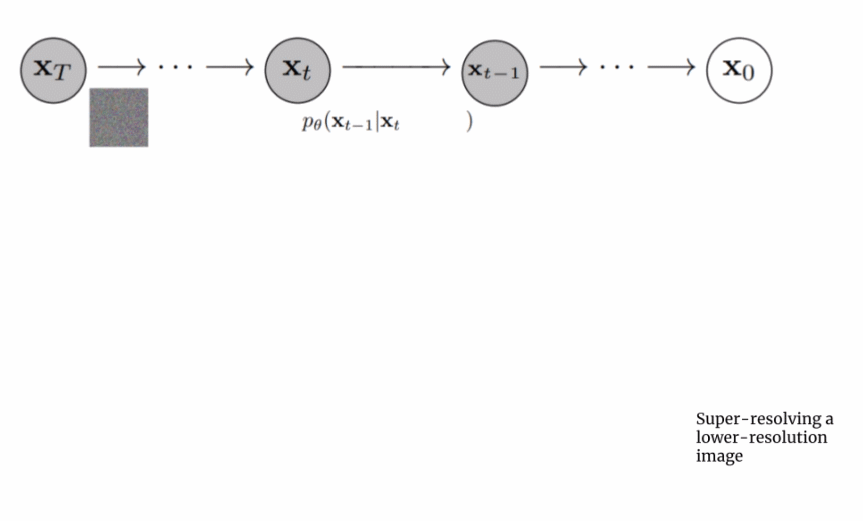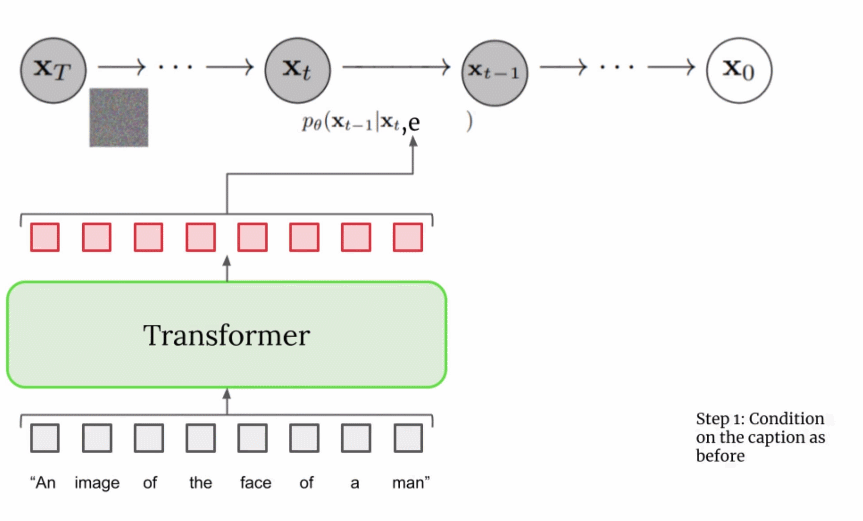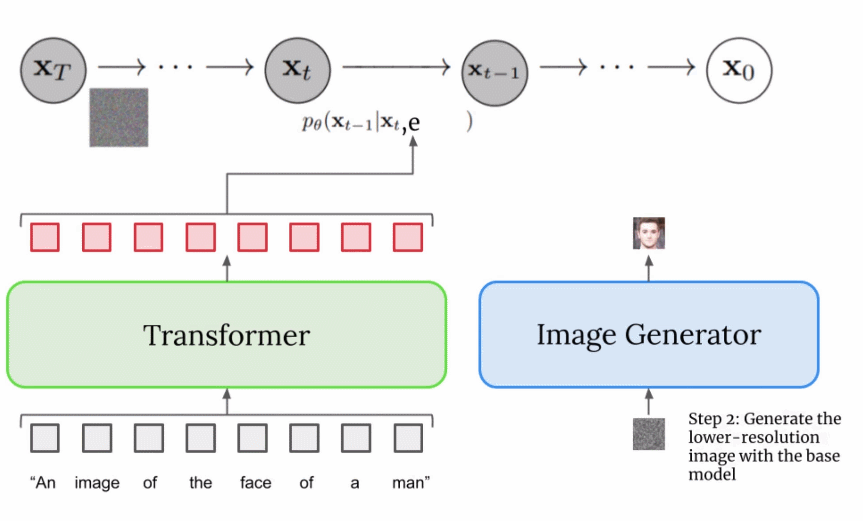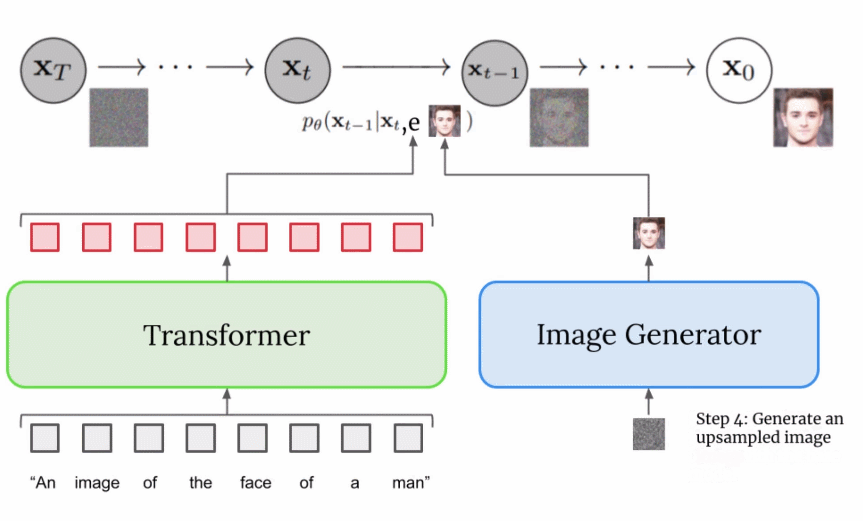
這個超分辨率模型的輸出實際上并不是最終輸出,而是一個中等大小的圖像。為了將該圖像放大到最終的 1024x1024 分辨率,又使用了另一個超分辨率模型。兩個超分辨率架構大致相同,因此不再贅述。而第二個超分辨率模型的輸出才是 Imagen 的最終輸出。 為什么 Imagen 比 DALL-E 2 更好? 確切地回答為什么 Imagen 比 DALL-E 2 更好是困難的。然而,性能差距中不可忽視的一部分源于字幕以及提示差異。DALL-E 2 使用對比目標來確定文本編碼與圖像(本質上是 CLIP)的相關程度。文本和圖像編碼器調整它們的參數,使得相似的字幕 - 圖像對的余弦相似度最大化,而不同的字幕 - 圖像對的余弦相似度最小化。 性能差距的一個顯著部分源于 Imagen 的文本編碼器比 DALL-E 2 的文本編碼器大得多,并且接受了更多數據的訓練。作為這一假設的證據,我們可以在文本編碼器擴展時檢查 Imagen 的性能。下面為 Imagen 性能的帕累托曲線:
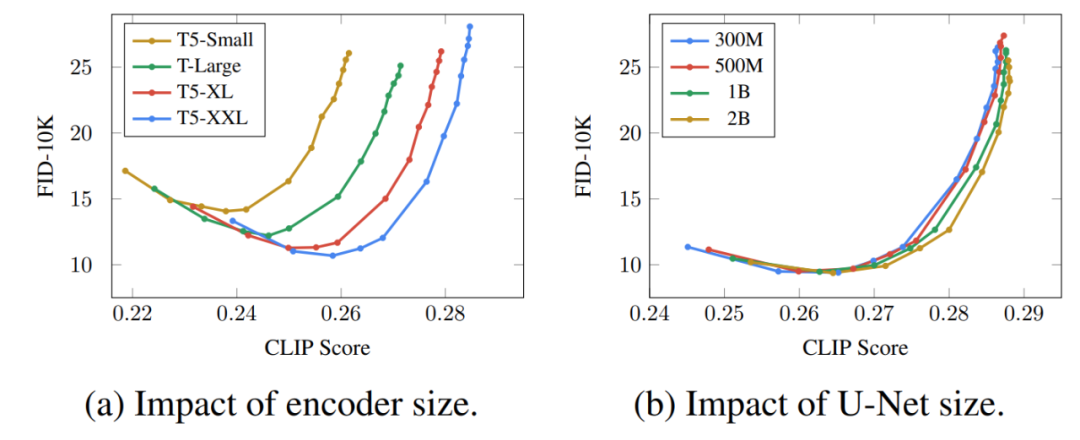
放大文本編碼器的效果高得驚人,而放大 U-Net 的效果卻低得驚人。這一結果表明,相對簡單的擴散模型只要以強大的編碼為條件,就可以產生高質量的結果。 鑒于 T5 文本編碼器比 CLIP 文本編碼器大得多,再加上自然語言訓練數據必然比圖像 - 字幕對更豐富這一事實,大部分性能差距可能歸因于這種差異。 除此以外,作者還列出了 Imagen 的幾個關鍵要點,包括以下內容:
擴展文本編碼器是非常有效的;
擴展文本編碼器比擴展 U-Net 大小更重要;
動態閾值至關重要;
噪聲條件增強在超分辨率模型中至關重要;
將交叉注意用于文本條件反射至關重要;
高效的 U-Net 至關重要。
這些見解為正在研究擴散模型的研究人員提供了有價值的方向,而不是只在文本到圖像的子領域有用。
審核編輯 :李倩
-
編碼器
+關注
關注
45文章
3595瀏覽量
134160 -
圖像
+關注
關注
2文章
1083瀏覽量
40418 -
生成器
+關注
關注
7文章
313瀏覽量
20977
原文標題:擴散+超分辨率模型強強聯合,谷歌圖像生成器Imagen背后的技術
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

數據光端機的工作原理解析
NFC天線的工作原理和結構
CAN總線收發器的工作原理和應用
串行接口的工作原理和結構
前饋神經網絡的工作原理和應用
什么是LLM?LLM的工作原理和結構
伺服控制器的工作原理和基本結構
谷歌發布AI文生圖大模型Imagen
Imagen 2 現已在 Vertex AI 上全面推出






 工商網監
工商網監
評論