 Python編程語言開源庫NUMPY的工作原理及優勢
Python編程語言開源庫NUMPY的工作原理及優勢
NumPy 是一個免費的開源 Python 庫,用于 n 維數組(也稱為張量)處理和數值計算。
什么是 NUMPY?
NumPy 是一個免費的 Python 編程語言開源庫,它功能強大、已經過充分優化,并增加了對大型多維數組(也稱為矩陣或張量)的支持。NumPy 還提供了一系列高級數學函數,可與這些數組結合使用。其中包括基本的線性代數、隨機模擬、傅立葉變換、三角運算和統計運算。
NumPy 代表 “numerical Python”,基于早期的 Numeric 和 Numarray 庫構建而成,旨在為 Python 提供快速的數字計算。如今,NumPy 貢獻者眾多,并得到了 NumFOCUS 的贊助。
作為科學計算的核心庫,NumPy 是 Pandas、Scikit-learn和SciPy等庫的基礎。它廣泛應用于在大型數組上執行優化的數學運算。
選擇 NUMPY 的原因及其工作原理
多維數組是 NumPy 庫的中心數據結構,通常代表值的網格。NumPy 的 ndarray 是一個同構的 n 維數組對象,描述了類似類型的元素或項的集合。在這些ndarrays中,每個項都包含大小相同的內存塊,且每個內存塊都采用同一識別方式。這能夠高效、快速、輕松地處理科學計算的數據。
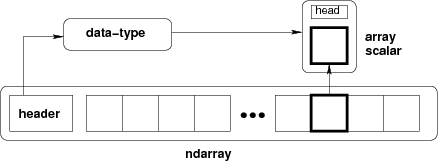
NumPy 數組運算速度比 Python Lists 要快,因為 NumPy 數組是類似數據類型的編譯,并且在內存中密集打包。相比之下,Python Lists 可以具有不同的數據類型,在系統執行計算時會增加對這些數據類型的限制。
| NumPy 的優勢
NumPy 具有以下重要優勢和特性:
NumPy 的 ndarray 計算概念是 Python 和 PyData 科學生態系統的核心。
NumPy 為高度優化的 C 函數提供了 Python 前端,可提供簡單的 Python 接口,并實現編譯代碼的速度。
NumPy 強大的 N 維數組對象可與各種庫集成。
與使用 Python 的內置列表相比,NumPy 數組可以更高效地使用大型數據集來執行高級數學運算,且使用的代碼更少。對于大小和速度至關重要的科學計算序列而言,這一點至關重要。
NUMPY 的重要意義
NumPy 讓數據科學家更易于使用 Python 并提供了 C 級優化,有助于快速創建高效代碼,進行探索數據分析和模型構建。如今,要想在科學計算領域取得成功,對算法進行快速原型設計必不可少,而這二者的實現對此至關重要。因此,可以使用 NumPy 在 Python 中實現多維數據通信。
在架構方面,CPU 僅由幾個具有大緩存內存的核心組成,一次只可以處理幾個軟件線程。相比之下,GPU 由數百個核心組成,可以同時處理數千個線程。

NumPy 已成為在 Python 中實現多維數據通信的實際方法。然而,對于多核 GPU,這種實施并非最佳。因此,對于較新的針對 GPU 優化的庫實施 Numpy 數組或與 Numpy 數組進行互操作。
NVIDIACUDA是 NVIDIA 專為 GPU 通用計算開發的并行計算平臺和編程模型。CUDA 數組接口是描述 GPU 數組(張量)的標準格式,允許在不同的庫之間共享 GPU 數組,而無需復制或轉換數據。CUDA 數組由 Numba、CuPy、MXNet 和 PyTorch 提供支持。
CuPy是一個利用 GPU 庫在 NVIDIA GPU 上實施 NumPy CUDA 數組的庫。
Numba是一個 Python 編譯器,可以編譯 Python 代碼,以在支持 CUDA 的 GPU 上執行。Numba 直接支持 NumPy 數組。
Apache MXNet是一個靈活高效的深度學習庫。可以使用它的 NDArray 將模型的輸入和輸出表示和操作為多維數組。NDArray 類似于 NumPy 的 ndarray,但它們可以在 GPU 上運行,以加速計算。
PyTorch是一種開源深度學習框架,以出色的靈活性和易用性著稱。Pytorch Tensors 與 NumPy 的 ndarray 類似,但它們可以在 GPU 上運行,加速計算。
NVIDIA GPU 加速的端到端數據科學
基于CUDA-X AI創建的 NVIDIARAPIDS開源軟件庫套件使您完全能夠在 GPU 上執行端到端數據科學和分析流程。此套件依靠 NVIDIA CUDA 基元進行低級別計算優化,但通過用戶友好型 Python 接口實現了 GPU 并行化和高帶寬顯存速度。
借助 RAPIDS GPU DataFrame,數據可以通過一個類似 Pandas 的接口加載到 GPU 上,然后用于各種連接的機器學習和圖形分析算法,而無需離開 GPU。這種級別的互操作性是通過 Apache Arrow 這樣的庫實現的。僅需一行代碼,即可從 NumPy 數組、Pandas DataFrame 和 PyArrow 表格創建 GPU 數據框。其他項目可以使用數組接口交換 CUDA 數據。這可加速端到端流程(從數據準備到機器學習,再到深度學習)。
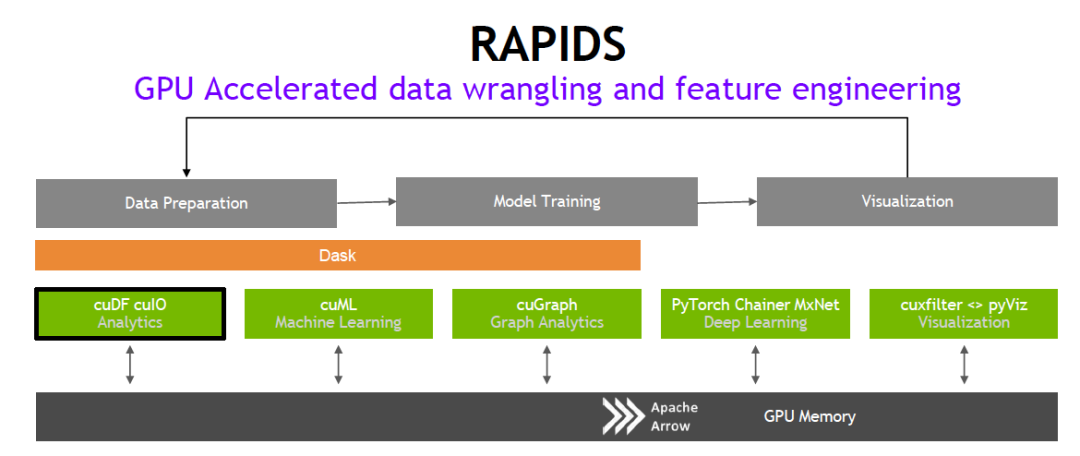
RAPIDS 支持在許多熱門數據科學庫之間共享設備內存。這樣可將數據保留在 GPU 上,并省去了來回復制主機內存的高昂成本。
-
NVIDIA
+關注
關注
14文章
4935瀏覽量
102807 -
gpu
+關注
關注
28文章
4700瀏覽量
128695 -
開源
+關注
關注
3文章
3245瀏覽量
42396 -
python
+關注
關注
56文章
4782瀏覽量
84449
發布評論請先 登錄
相關推薦
什么是NumPy?選擇NUMPY的原因及其工作原理是什么
Python編程語言可以應用在哪些方面?
不得不知的6大Python編程的優勢
Python中NumPy擴展包簡介及案例詳解
Python的兩個基礎包numpy和Matplotlib示例詳解
靈活運用Python中numpy庫的矩陣運算
基于python的numpy深度解析






 工商網監
工商網監
評論