 如何擴大卷積來消除與Transformer的性能差距
如何擴大卷積來消除與Transformer的性能差距
本文分析了是否可以通過策略性地擴大卷積來消除與Transformer的性能差距。
首先,先讓我 brainstorm 一下。當你看到 neural network scaling 這個詞的時候你能想到什么?先不要看下文,把你想到的東西記下來。說不定這個簡單的 brainstorm 能讓你找到絕妙的 idea。
我想大多數人想到的應該是模型大小(寬度 + 深度),數據大小,或者圖片像素等等。有沒有哪位小科學家曾經想過去 scale convolutional kernels?scale 卷積核同樣能增大模型的參數,但能帶來像寬度和深度一樣的增益嗎?我這篇文章從這個角度出發深入探究了超大卷積核對模型表現的影響。我發現現有的大卷積核訓練方法的瓶頸:現有的方法都無法無損的將卷積核 scale 到 31x31 以上,更別說用更大的卷積來進一步獲得收益。
我這篇文章的貢獻可以總結為以下幾點:
(1)現有的方法可以將卷積核增大到 31x31。但在更大的卷積上,例如 51x51 和 61x61,開始出現明顯掉點的現象。(2)經典的 CNN 網絡,如 ResNet 和 ConvNeXt,stem cell 都采用了 4× 降采樣。所以對典型的 224×224 ImageNet 來說,51×51 的極端核已經大致等于全局卷積。和全局注意力機制一樣,我推測全局卷積也存在著捕捉局部低級特征的能力不足的問題。(3)基于此觀察,我提出了一套訓練極端卷積核的 recipe,能夠絲滑的將卷積核增大到 61x61,并進一步提高模型的表現。我的方法論主要是基于人類視覺系統中普遍存在的稀疏性提出來的。在微觀層面上,我將 1 個方形大卷積核分解為 2 個具有動態稀疏結構的,平行的長方形卷積核,用來提高大卷積的可擴展性;在宏觀層面上,我構建了一個純粹的稀疏網絡,能夠在提升網絡容量的情況下保持著和稠密網絡一樣的參數和 FLOPs。(4)根據這個 recipe,我構造了一個新型網絡結構 Sparse Large Kernel Network,簡稱 SLaK。SLaK 搭載著有史以來最大的 51x51 卷積核,能夠在相似的參數量和 FLOPs 的條件下,獲得比最新先進的 ConvNeXt,Swin Transformer 和 RepLKNet 更好的性能。(5)最后,作者認為本文最重要的貢獻是 sparsity,通常作為模型壓縮的“老伙計”,can be a promising tool to boost neural network scaling。
Pytorch 開源代碼:https://github.com/VITA-Group/SLaK
一、引言
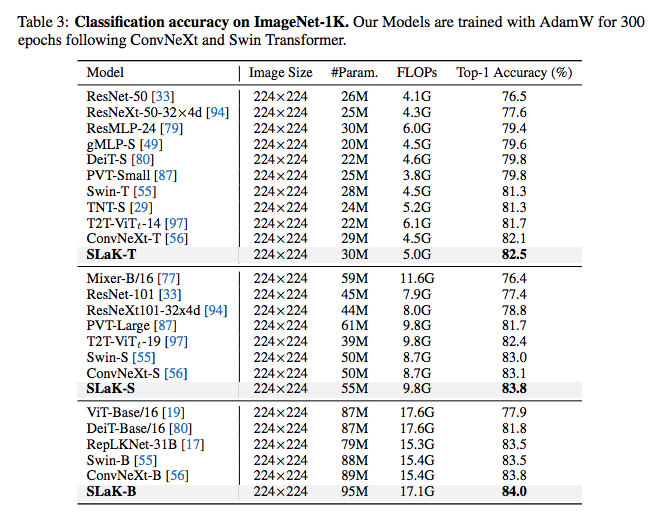
隨著 vison transformer 在各個領域的大放異彩,CNN 和 Vision Transformer 的競爭也愈演愈烈。在愈發強大的各類 attention 變種的推進下,ViT 取代 CNN 這個視覺老大哥的野心已經路人皆知。而 CNN 在全局和局部注意力的啟發下也帶著大卷積乘風破浪回來。前浪有 ConvNeXts 配備著 7x7 卷積核和 swin transformer 精巧的模型設計,成功的超越了后者的表現。
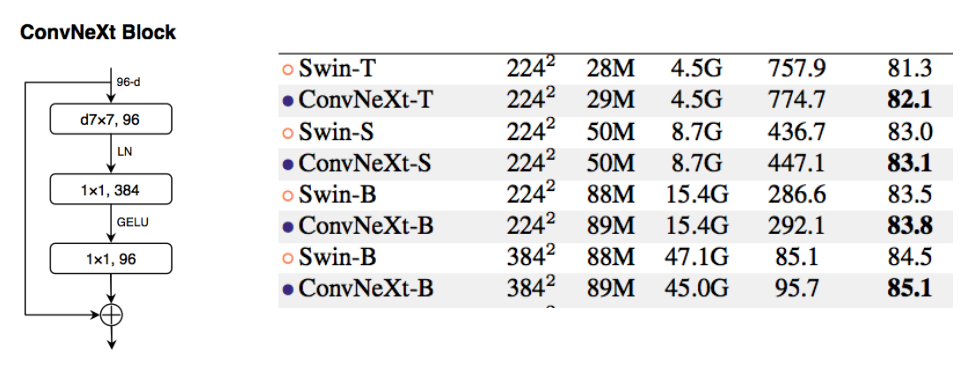
后浪中 RepLKNet 用結構再參數化成功的克服了大卷積在訓練上的困難,一度將卷積增大到了 31x31,并達到了和 Swin Transformer 相當的表現。在下游任務上更是超過了后者。但與 Swin Transformer 等高級 ViT 的擴展趨勢相比,隨著卷積核的持續擴大,大卷積核有著明顯的疲軟趨勢。

二、超越 31x31 超大卷積核的訓練 recipe
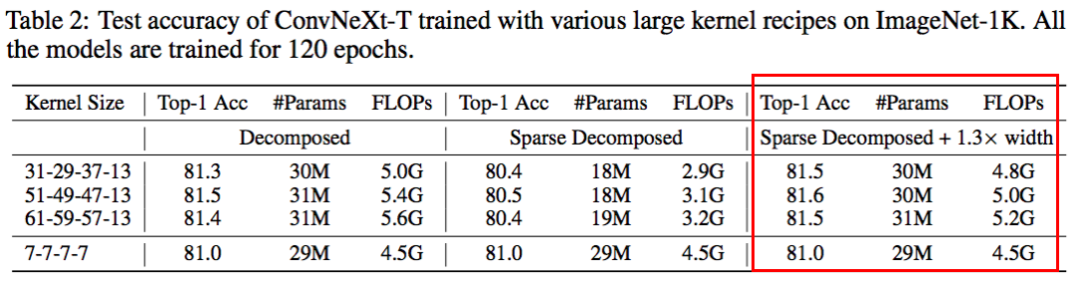
本文主要想探究的問題是:是否可以通過采用極致大卷積核(超過 31x31)來進一步提高 CNNs 的表現?為了回答這個問題,我在最近大火的 ConvNeXt 上對大卷積進行了系統的研究。我采用了和 ConvNeXt 一模一樣的訓練設定和超參并將卷積核放大到 31x31,51x51 和 61x61。受限于計算資源,我這里將模型訓練到 120 個 epoch,僅僅用來觀察卷積增大的趨勢,得到了如下 3 個主要結論。
結論 1:現有的技術無法無損的將卷積核擴展到 31x31 以上
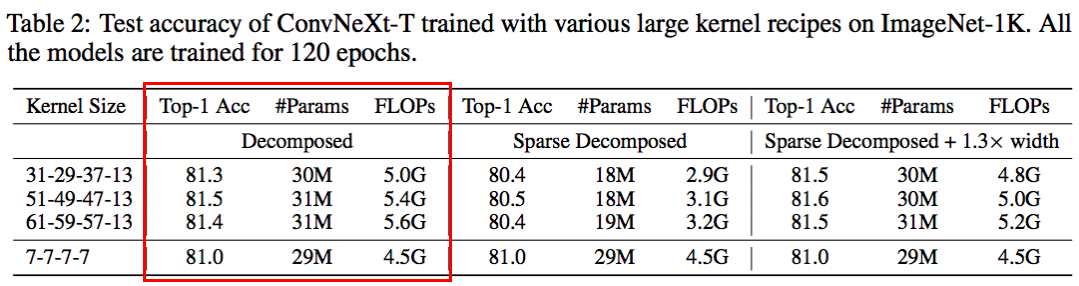
現有的大卷積核技術主要有兩個,一是直接暴力 scale up 卷積核的 ConvNeXt,二是增加一個額外的小卷積層來輔助大卷積的訓練,訓練完成之后再用結構化再參數將小卷積核融入大卷積核里,即 RepLKNet。我分別測試了這兩種方法在極致大卷積上的表現,如下表所示:
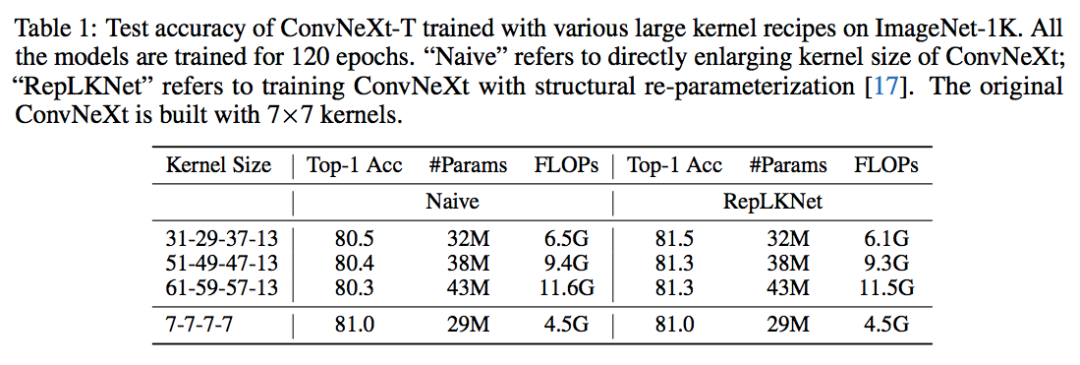
原始 ConvNeXt 采用的是 7x7 卷積核,ImageNet 上能達到 81.0% 的 top1 精度。但是當卷積逐漸增大的時候,ConvNeXt 出現了明顯的掉點。相比之下,RepLKNet 成功的把卷積核增大到 31x31 并帶來了超過 0.5 個點的可觀提升。但是當卷積核增大到 51x51 甚至是 61x61 的時候,RepLKNet 也逐漸乏力。尤其是在 61x61 上,RepLKNet 的 FLOPs 增加了兩倍,精度卻反而降低了 0.2%。
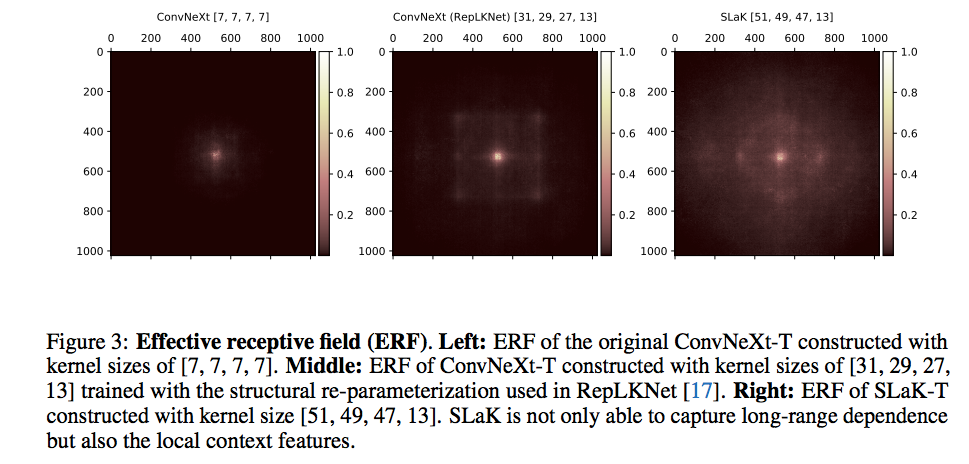
如果仔細分析 ConvNeXt 模型的特點,51x51 和 61x61 卷積核帶來的精度下降是可以理解的。如下圖所示,現階段最先進的模型的 stem cell 都不約而同的采用了 stride=4 的結構將輸入圖片的分辨率縮減到了原來的 1/4。那么對經典的 224x224 iamgenet 來說,通過 stem cell 之后,feature 的大小就只有 56x56 了。所有 51x51 和 61x61 規模的卷積核就已經是全局水平的卷積核。一種合某些理想的特性,比如有效的局部特性。同樣的現象我在 ViTs 的類似機制中也觀察到過,即局部注意力通常優于全局注意力。在此基礎上,我想到了通過引入局部性來解決這個問題的機會。
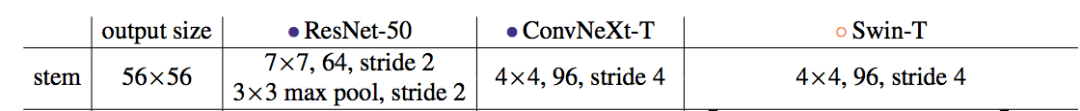
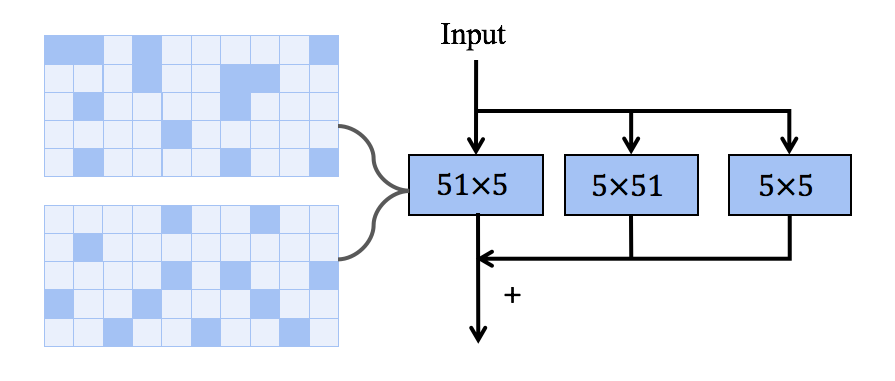
結論 2:用兩個平行的,長方形卷積來代替方形大卷積可以絲滑的將卷積核擴展到 61x61
這里我采用的方法是將一個常用的 MxM 方形卷積核分解為兩個平行的 MxN+NxM 長方形卷積核。如下圖最右邊所示。這里經驗性的設置 N=5。
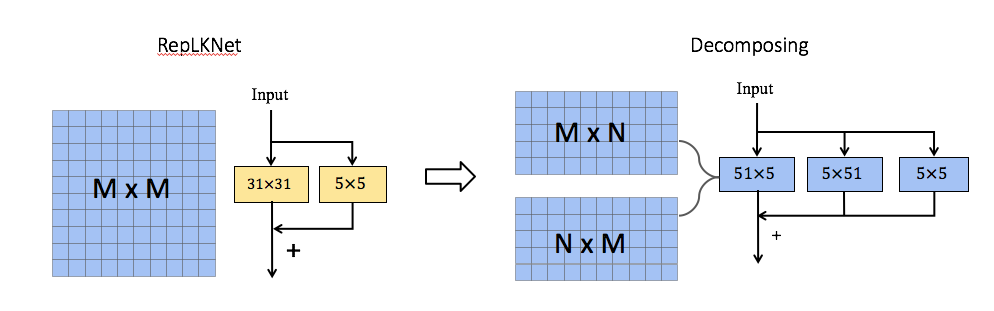
這種分解不僅繼承了大卷積捕獲遠程依賴關系的能力,而且可以利用短邊來提取局部上下文特征。我選用了兩個 parallel 卷積核相加而不是以往的兩個 sequential 卷積核相疊是因為先進行 MxN 卷積再進行 NxM 卷積可能會因為 N 過小而丟失一部分長距離的信息(有待于去驗證)。果然與預想的一樣,這樣分解可以讓我逆轉大卷積帶來精度下降的趨勢。由于該分解減少了 FLOPs,相比不分解(即 RepLKNet)在 31x31 卷積上會犧牲掉少量的精度 (0.2%)。但是,隨著卷積大小增加到全局卷積,它可以驚人地將 Kernel-size 擴展到 61x61 并帶來更好的性能指標。
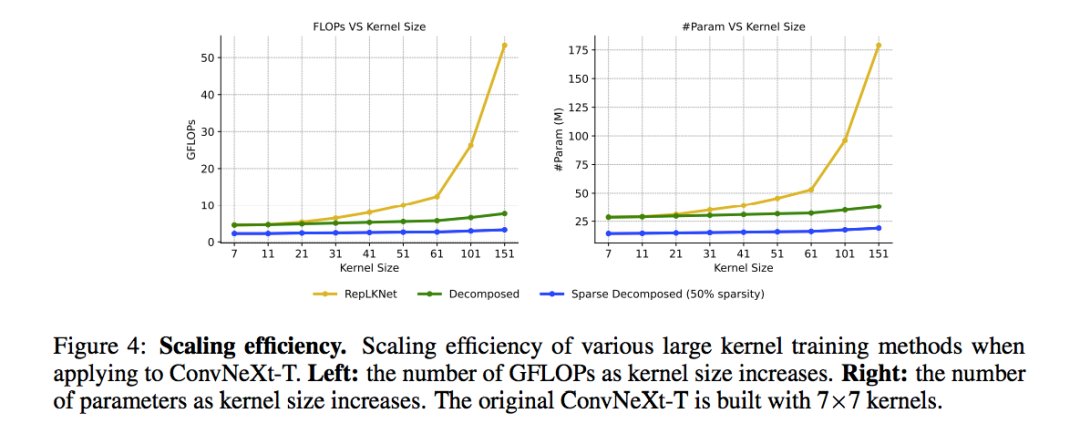
更重要的是,隨著卷積核的增大,現有的大卷積訓練技術的內存和計算開銷會呈現二次方的增長。這種分解方式保持了線性增長的趨勢并且可以極大的減少大卷積核帶來的開銷。如下圖所示。在中等卷積 31x31 上,參數量和計算量基本豆差不多。但是繼續增大卷積核的時候,RepLKNet 的計算量二次方的增長,而我的方法能基本保持不變。不要小看這一點,因為現在已經有很多工作指明了一個明顯的趨勢:高分辨率訓練(Swin Transfermor V2 使用了高達 1536x1536 的像素)能夠帶來明顯的增益。這種極大分辨率上,51x51 分辨率明顯已經不足以去獲得足夠大的感受野。我很可能需要 100 + 的卷積核去獲得足夠大的感受野。
結論 3:擁有動態稀疏性的卷積核極大的提高了模型的容量同時又不增加模型大小
最近提出的 ConvNeXt 重新訪問了 ResNeXt 中 “use more groups, expand width” 的準則,使用增加寬度的 depth-wise 卷積來增加 model capacity。在本文中,我用 dynamic sparsity 進一步擴展的這一原則,即“use sparse groups, expand more”。關于 dynamic sparsity 的介紹,請移步 https://zhuanlan.zhihu.com/p/376304225 看我之前的分享。
具體來說,我首先用稀疏卷積代替密集卷積,其中每一層的稀疏度是基于 SNIP 的稀疏比率提前決定的。構建完成后,我采用了動態稀疏度方法來訓練模型。具體來說就是在模型訓練一段時間后我會采用參數剪枝的方法去 prune 掉一部分相對不重要的參數,緊接著去隨機的漲同樣數量的參數來保證總體訓練參數的固定。這樣做可以動態地適應稀疏權值,從而獲得更好的局部特征。由于在整個訓練過程中模型都是稀疏的,相應的參數計數和訓練 / 推理 FLOPs 只與模型的稀疏度成比例。為了評估,這里以 40% 的稀疏度稀疏化分解后的 kernel,并將其性能報告為 “稀疏分解” 組。可以在表 2 的中間一列中觀察到,動態稀疏性顯著降低了模型的 FLOPs(超過 2.0G),并導致了暫時的性能下降。
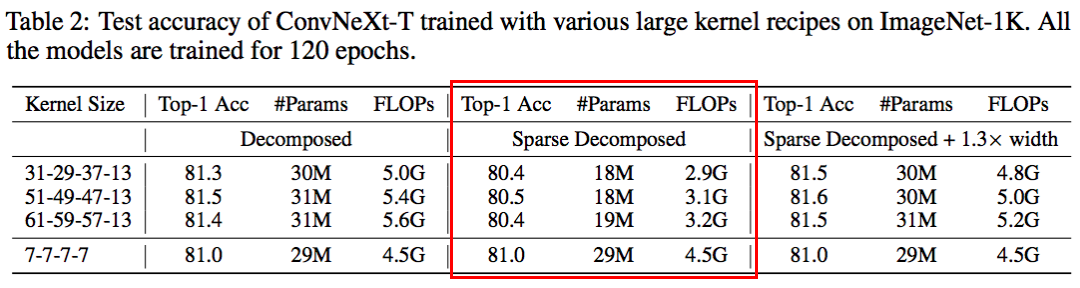
接下來,我展示了動態稀疏性的 high efficiency 可以有效地轉化成 high scalability。例如,使用相同的稀疏性(40%),我可以將模型寬度擴展 1.3 倍,但是總體的模型參數和 FLOPs 卻仍然和稠密網絡一樣,并顯著漲點。在極端的 51×51 卷積下,性能可以從 80.5% 直接提高到 81.6%。值得注意的是,配備了 61×61 的內核之后,我的模型可以超越 RepLKNet 的精度,同時還節省了 55% 的 FLOPs。
三、Sparse Large Kernel Network - SLaK
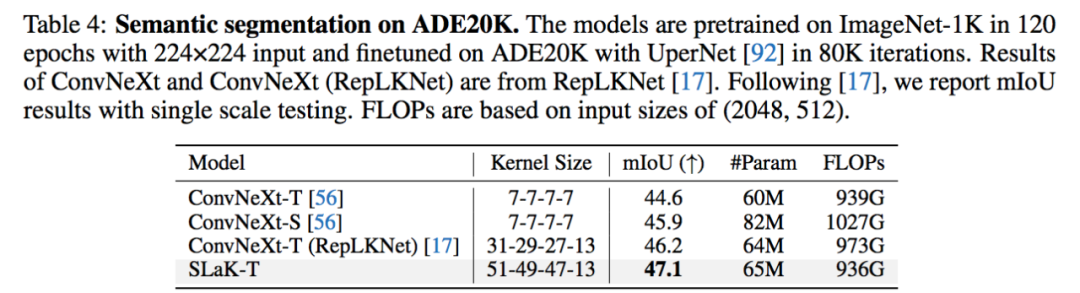
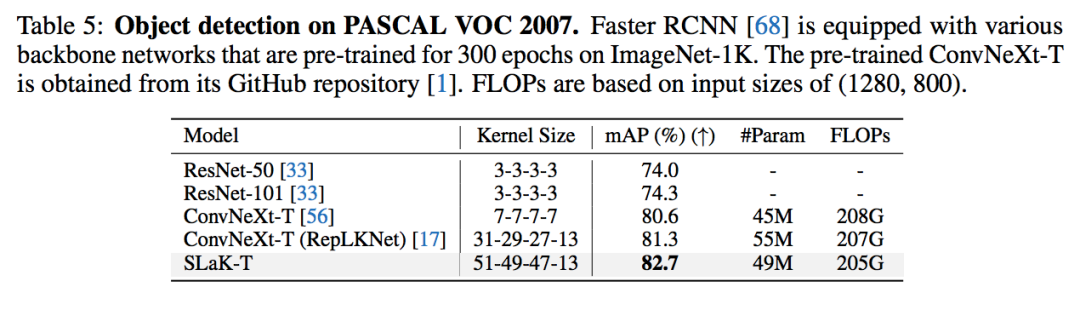
我利用上面發現的 recipe 在 ConvNeXt 上直接加載了 51x51 的卷積核,得到了 SLaK-T/S/B 模型。在不改變任何 ConvNeXt 原有的訓練設置和超參的情況下,SLaK 在 ImageNet-1K 分類數據集,ADE20K 分割數據集、PASCAL VOC 2007 檢測數據集,都超過了 Swin Transformer,ConvNeXt,和 RepLKNet 的表現。實驗結果突出了極致卷積核在下游視覺任務中的關鍵作用。
四、感受野分析
前面我猜測新方法既能夠保證對遠距離相關性的獲取,又能夠捕捉到近距離重要的特征。接下來通過對感受野的分析來證明這種想法。我計算了輸入圖片的像素對不同模型決策的貢獻度,并把貢獻度加加回到 1024x1024 的圖片上。我可以發現原始的 ConvNeXt 用 7X7 卷積只用了中間很小一部分的像素來做決策;RepLKNet 用 31x31 的卷積把感受野擴大了許多;而 SLaK 進一步用 51x51 的卷積核幾乎達到了全局感受野。值得注意的在大的感受野之上,能明顯的看到一個小的正方形堆疊著,證明了我能捕捉小范圍的低級特征的猜想。
-
數據
+關注
關注
8文章
6892瀏覽量
88828 -
網絡容量
+關注
關注
0文章
5瀏覽量
6439 -
Transformer
+關注
關注
0文章
141瀏覽量
5982
原文標題:卷積核擴大到51x51,新型CNN架構SLaK反擊Transformer
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于卷積的基礎模型InternImage網絡技術分析
為什么transformer性能這么好?Transformer的上下文學習能力是哪來的?
什么是卷積碼? 什么是卷積碼的約束長度?
如何更改ABBYY PDF Transformer+界面語言
omniCOOL系統是怎樣來彌補滾珠版與滑動版軸承之間的差距的?
OpenPPL Arm Server卷積實現及性能展示解析
利用卷積調制構建一種新的ConvNet架構Conv2Former
我們可以使用transformer來干什么?
如何使用Transformer來做物體檢測?
基于膨脹卷積和稠密連接的煙霧圖像識別
使用跨界模型Transformer來做物體檢測!






 工商網監
工商網監
評論