") 擴(kuò)散模型和其在文本生成圖像任務(wù)上的應(yīng)用
擴(kuò)散模型和其在文本生成圖像任務(wù)上的應(yīng)用
本文主要介紹擴(kuò)散模型和其在文本生成圖像任務(wù)上的應(yīng)用,從擴(kuò)散模型的理論知識(shí)開始,再到不同的指導(dǎo)技巧,最后介紹文本生成圖像的應(yīng)用,帶讀者初探擴(kuò)散模型的究竟。如有遺漏或錯(cuò)誤,歡迎大家指正。
引言:擴(kuò)散模型是一類生成模型,通過迭代去噪過程將高斯噪聲轉(zhuǎn)換為已知數(shù)據(jù)分布的樣本,生成的圖片具有較好的多樣性和寫實(shí)性。文本生成圖像是多模態(tài)的任務(wù)之一,目前該任務(wù)的很多工作也是基于擴(kuò)散模型進(jìn)行構(gòu)建的,如GLIDE、DALL·E2、Imagen等,生成的圖片讓人驚嘆。本文從介紹擴(kuò)散模型的理論部分開始,主要介紹DDPM一文中涉及到的數(shù)學(xué)公式,然后介紹擴(kuò)散模型中常用到的指導(dǎo)技巧,最后會(huì)介紹文本生成圖像的一些應(yīng)用。 1. 擴(kuò)散模型
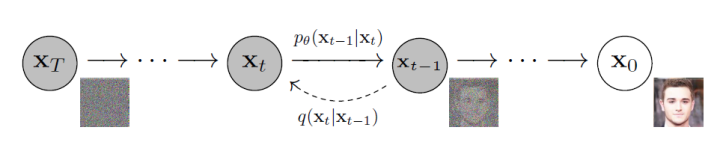
上圖展示了擴(kuò)散模型的兩個(gè)過程。其中,從右到左(從到)表示正向過程或擴(kuò)散過程,從左到右(從到)表示的是逆向過程。擴(kuò)散過程逐步向原始圖像添加高斯噪聲,是一個(gè)固定的馬爾科夫鏈過程,最后圖像也被漸進(jìn)變換為一個(gè)高斯噪聲。而逆向過程則通過去噪一步步恢復(fù)原始圖像,從而實(shí)現(xiàn)圖像的生成。下面形式化介紹擴(kuò)散過程、逆擴(kuò)散過程和目標(biāo)函數(shù),主要參考DDPM[1]論文和What are Diffusion Models?[2]博客內(nèi)容。1.1 擴(kuò)散過程設(shè)原始圖像,擴(kuò)散過程進(jìn)行步,每一步都向數(shù)據(jù)中添加方差為每一步都向數(shù)據(jù)中添加方差為,最終。所以,由馬爾科夫鏈的無記憶性,可對(duì)擴(kuò)散過程進(jìn)行如下定義:
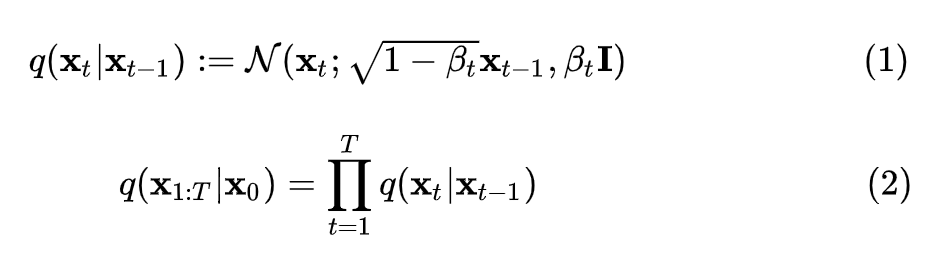
所以,擴(kuò)散過程的均值和方差是已知的,其均值為,方差為。 擴(kuò)散過程有一個(gè)顯著特性,我們可以對(duì)任意 進(jìn)行采樣。為了證明該性質(zhì)需要使用參數(shù)重整化技巧:假設(shè)要從高斯分布中采樣時(shí),可以先從采樣出 ,然后計(jì)算 ,這樣可以解決梯度無法回傳問題。 所以首先將進(jìn)行重參數(shù)化:設(shè), 故: 設(shè),: 其中 ,第三行到第四行進(jìn)行了兩個(gè)正態(tài)分布的相加。所以,重整化后 ,即 1.2 逆擴(kuò)散過程 逆擴(kuò)散過程是從給定的高斯噪聲中恢復(fù)原始數(shù)據(jù),也是一個(gè)馬爾可夫鏈過程,但每個(gè)時(shí)刻 的均值和方差需要我們?nèi)W(xué)習(xí),所以,我們可以構(gòu)建生成模型 : 1.3 目標(biāo)函數(shù)擴(kuò)散模型使用負(fù)對(duì)數(shù)似然最小化的思想,采用近似的技術(shù)等價(jià)地要求負(fù)對(duì)數(shù)似然最小化。同時(shí),由于KL散度具有非負(fù)性,因而將和的KL散度添加至負(fù)對(duì)數(shù)似然函數(shù)中,形成新的上界。 對(duì)于全部的訓(xùn)練數(shù)據(jù),添加上式兩邊同乘 ,即:對(duì)上式進(jìn)行化簡(jiǎn):上式中第四行到第五行,利用了馬爾可夫鏈的無記憶性和貝葉斯公式:第六行到第七行是第二個(gè)求和符號(hào)展開并化簡(jiǎn)的結(jié)果。 上述過程在DDPM論文中的附錄部分也有展示。 觀察可知,項(xiàng)的兩個(gè)分布均已知,同時(shí)DDPM文中將項(xiàng)設(shè)置為一個(gè)特殊的高斯分布。故最后的目標(biāo)只和有關(guān)。 同時(shí),雖然無法直接給出,但當(dāng)我們加入作為條件時(shí),設(shè) 類似上面的處理,根據(jù)貝葉斯公式和馬爾可夫性質(zhì),可知 然后由公式(1)(4)可知: 由于高斯分布的概率密度函數(shù)是: 將上面兩個(gè)式子進(jìn)行一一對(duì)應(yīng),可以得到均值: 所以,由高斯分布的KL散度計(jì)算式可知,可化為: 因此,我們可以直觀地看到其目標(biāo)含義是模型預(yù)測(cè)的均值要盡可能和接近。然后,由公式 可知,輸入 不含參數(shù),則在給定時(shí),若 能夠預(yù)測(cè)出,則也能夠計(jì)算出均值,所以同樣進(jìn)行參數(shù)重整化,可得: 所以: DDPM論文中最終的簡(jiǎn)化目標(biāo)為: 所以可以看出,從預(yù)測(cè)均值變?yōu)榱酥苯宇A(yù)測(cè)噪聲,加快了推理速度。 2. Guided Diffusion DDPM論文提出之后,擴(kuò)散模型就可以生成質(zhì)量比較高的圖片,具有較強(qiáng)的多樣性,但是在具體的指標(biāo)數(shù)值上沒有超過GAN。同時(shí),在協(xié)助用戶進(jìn)行藝術(shù)創(chuàng)作和設(shè)計(jì)時(shí),對(duì)生成的圖像進(jìn)行細(xì)粒度控制也是一個(gè)重要的考慮因素。所以之后嘗試將一些具體的指導(dǎo)融入擴(kuò)散模型中去。 2.1 Classifier Guidance 用于圖像生成的GAN的相關(guān)工作大量使用了類標(biāo)簽,而我們也希望生成的圖片更加寫實(shí),所以有必要探索在類標(biāo)簽上調(diào)整擴(kuò)散模型。具體來說,Diffusion Models Beat GANs[3]一文中使用了額外的分類器,在前面我們描述的無條件的逆向過程的基礎(chǔ)上,將類別作為條件進(jìn)行生成,具體公式如下:
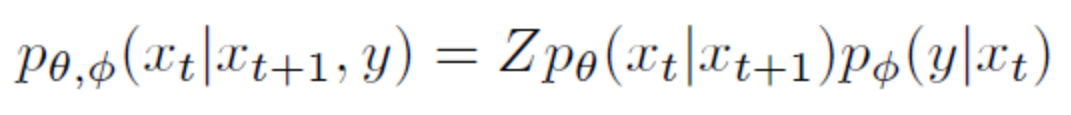
上式的含義是加入類別作為條件進(jìn)行生成,可以看作無條件的生成和分類兩者的結(jié)合。具體而言,用分類模型對(duì)生成的圖片進(jìn)行分類,得到預(yù)測(cè)與目標(biāo)類別的交叉熵,從而使用梯度幫助模型的采樣和生成。 實(shí)際中,分類器是在噪聲數(shù)據(jù)上訓(xùn)練的。 采樣過程的算法如下:

可以看到該過程中同時(shí)學(xué)習(xí)均值和方差,然后加入分類器的梯度引導(dǎo)采樣過程。 2.2 Semantic Diffusion Guidance (SDG) 看到分類器指導(dǎo)的圖像生成的有效性后,自然而然可以想到:是否可以將圖像類別信息換為其他不同類型的指導(dǎo)呢?比如使用CLIP模型作為圖像和文本之間的橋梁,實(shí)現(xiàn)文本指導(dǎo)的圖像生成。 Semantic Diffusion Guidance(SDG)[4]是一個(gè)統(tǒng)一的文本引導(dǎo)和圖像引導(dǎo)框架,通過使用引導(dǎo)函數(shù)來注入語義輸入,以指導(dǎo)無條件擴(kuò)散模型的采樣過程,這使得擴(kuò)散模型中的生成更加可控,并為語言和圖像引導(dǎo)提供了統(tǒng)一的公式。
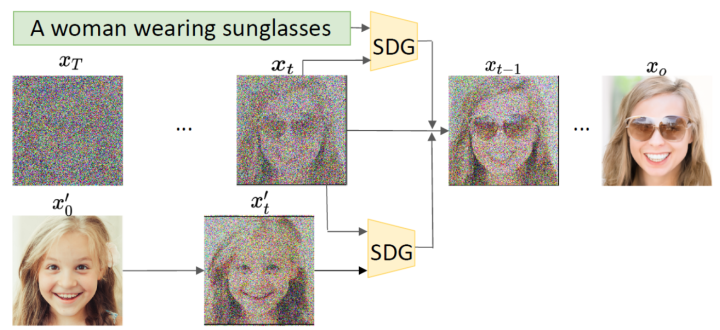

從采樣過程可以看出,不同的引導(dǎo)其實(shí)就是中的不同,可以是文本、圖像,也可以是兩者的結(jié)合。 2.3 Classifier-Free Guidance 以上方法都是使用了額外的模型,成本比較高,而且須在噪聲數(shù)據(jù)上進(jìn)行訓(xùn)練,無法使用預(yù)訓(xùn)練好的分類器。Classifier-Free Guidance[5]一文提出在沒有分類器的情況下,純生成模型可以進(jìn)行引導(dǎo):共同訓(xùn)練有條件和無條件擴(kuò)散模型,并發(fā)現(xiàn)將兩者進(jìn)行組合,可以得到樣本質(zhì)量和多樣性之間的權(quán)衡。 原來分類器指導(dǎo)的式子如下,表示條件,和含義類似:
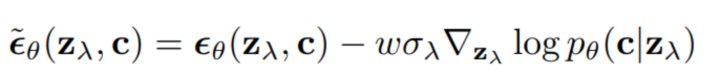
Classifier-Free Guidance方法將模型的輸入分為兩種,一種是無條件的 ,另一種是有條件的,使用一個(gè)神經(jīng)網(wǎng)絡(luò)來參數(shù)化兩個(gè)模型,對(duì)于無條件模型,我們可以在預(yù)測(cè)分?jǐn)?shù)時(shí)簡(jiǎn)單地為類標(biāo)識(shí)符設(shè)為零,即。我們聯(lián)合訓(xùn)練無條件和條件模型,只需將隨機(jī)設(shè)置為無條件類標(biāo)識(shí)符即可。然后,使用以下有條件和無條件分?jǐn)?shù)估計(jì)的線性組合進(jìn)行抽樣:
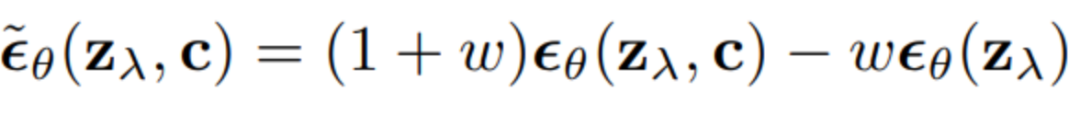
3. 應(yīng)用
3.1 GLIDE OpenAI的GLIDE[6]將擴(kuò)散模型和Classifier-Free Guidance進(jìn)行結(jié)合去生成圖像。同時(shí)文中比較了兩種不同的引導(dǎo)策略:CLIP Guidance和Classifier-Free Guidance,然后發(fā)現(xiàn)Classifier-Free Guidance在照片寫實(shí)等方面更受人類評(píng)估者的青睞,并且通常會(huì)產(chǎn)生很逼真的樣本,并能實(shí)現(xiàn)圖像編輯。其中,Classifier-Free Guidance中的條件是文本。

下表是GLIDE在MS-COCO上的實(shí)驗(yàn)結(jié)果。
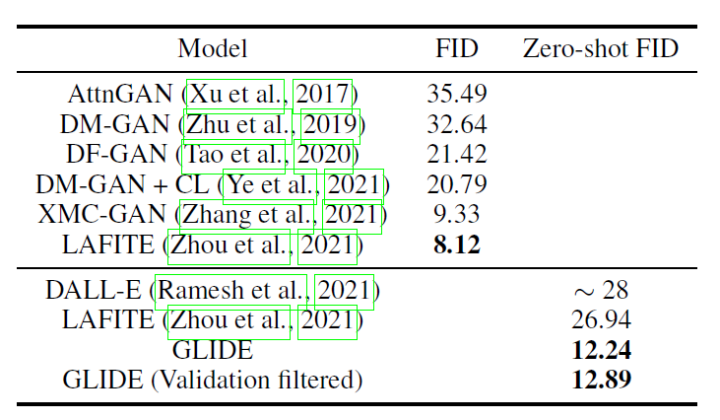
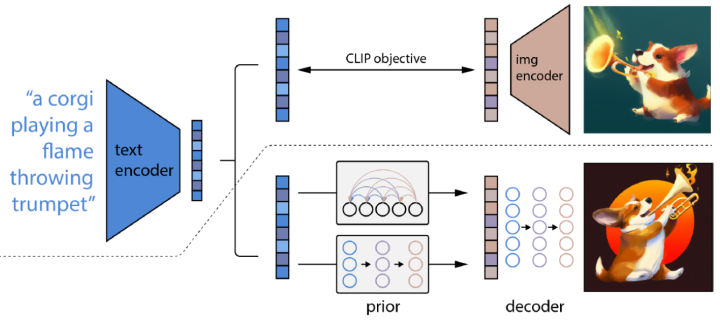
除了零樣本生成之外,GLIDE還具有編輯功能,允許迭代地改進(jìn)模型樣本。 3.2 DALL·E 2 DALL·E2[7]利用CLIP來生成圖像,提出了一個(gè)兩階段模型:一個(gè)先驗(yàn)prior網(wǎng)絡(luò)用于生成一個(gè)給定文本下的 CLIP 圖像嵌入,一個(gè)解碼器decoder在給定圖像編碼的情況下生成圖像。DALL·E2對(duì)解碼器使用擴(kuò)散模型,并對(duì)先驗(yàn)網(wǎng)絡(luò)使用自回歸模型和擴(kuò)散模型進(jìn)行實(shí)驗(yàn),發(fā)現(xiàn)后者在計(jì)算上更高效,并產(chǎn)生更高質(zhì)量的樣本。 具體來說:
prior :在給定文本條件下生成CLIP圖像的編碼,并且文中探索了兩種實(shí)現(xiàn)方式:自回歸和擴(kuò)散,均使用classifier-free guidance,并且發(fā)現(xiàn)擴(kuò)散模型的效果更好:
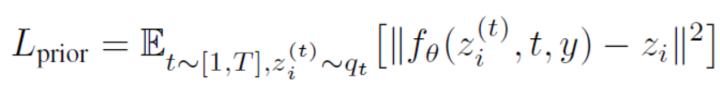
注意此處目標(biāo)和前面有所不同,prior直接去預(yù)測(cè)圖像特征,而不是預(yù)測(cè)噪聲
decoder:在圖像編碼(和可選的文本標(biāo)題)條件下生成圖像;使用擴(kuò)散模型并利用classifier-free guidance和CLIP guidance在給定CLIP圖像編碼的情況下生成圖像。為了生成高分辨率圖像,訓(xùn)練了兩個(gè)擴(kuò)散上采樣模型,分別用于將圖像從64*64上采樣到256*256、進(jìn)一步上采樣到1024*1024。
將這兩個(gè)部分疊加起來會(huì)得到一個(gè)生成模型可以在給定標(biāo)題下生成圖像:。第一個(gè)等號(hào)是由于和是一對(duì)一的關(guān)系。
所以DALL·E2可以先用prior采樣出,然后用decoder得到;
DALL·E2能夠生成高分辨率、風(fēng)格多樣的圖片,并且能夠給定一張圖,生成許多風(fēng)格類似的圖片;可以進(jìn)行兩張圖片的插值,實(shí)現(xiàn)風(fēng)格的融合等,在具體數(shù)值上也超越了GLIDE。
3.3 Imagen 下圖是谷歌提出的Imagen[8]的模型架構(gòu):
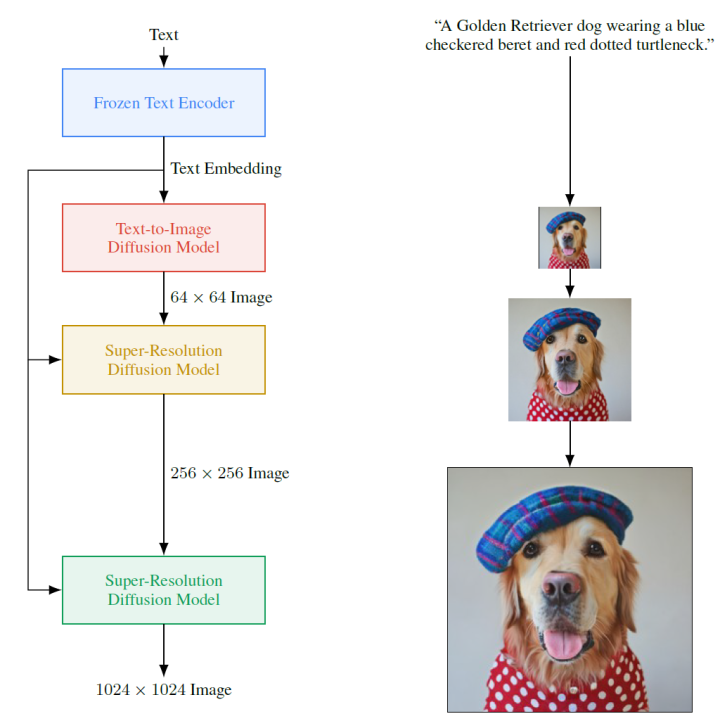
Imagen由一個(gè)文本編碼器和一連串條件擴(kuò)散模型組成。
預(yù)訓(xùn)練文本編碼器:語言模型是在文本語料庫(kù)上訓(xùn)練的,該語料庫(kù)比配對(duì)的圖像-文本數(shù)據(jù)要大得多,因此可以接觸到非常豐富和廣泛的文本分布。文中使用Frozen Text Encoder進(jìn)行文本的編碼
擴(kuò)散模型和classifier-free guidance:使用前面提到的classifier-free guidance,將文本編碼作為條件,進(jìn)行圖像的生成。同樣,后面也有兩個(gè)擴(kuò)散模型進(jìn)行分辨率的提升,最終可以生成1024*1024分辨率的圖像。文本到圖像擴(kuò)散模型使用改進(jìn)的U-Net 架構(gòu),生成64*64 圖像,后面兩個(gè)擴(kuò)散模型使用本文提出Efficient U-Net,可以更節(jié)省內(nèi)存和時(shí)間。
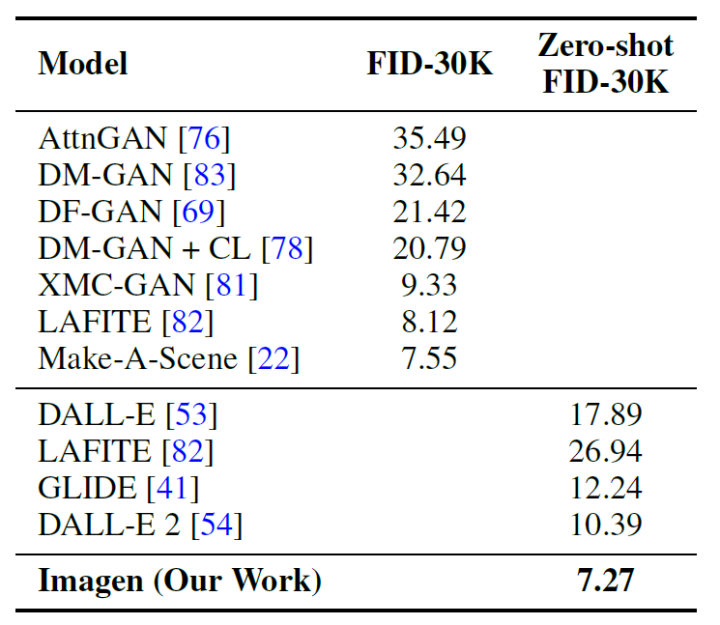
我們使用FID分?jǐn)?shù)在COCO驗(yàn)證集上評(píng)估Imagen,下表展示了結(jié)果。Imagen在COCO上實(shí)現(xiàn)了最好的zero-shot效果,其FID為7.27,優(yōu)于前面的一系列工作。

審核編輯 :李倩
-
圖像
+關(guān)注
關(guān)注
2文章
1083瀏覽量
40418 -
模型
+關(guān)注
關(guān)注
1文章
3174瀏覽量
48716 -
擴(kuò)散模型
+關(guān)注
關(guān)注
0文章
5瀏覽量
5535
原文標(biāo)題:文本生成 | 擴(kuò)散模型與其在文本生成圖像領(lǐng)域的應(yīng)用
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
如何使用 Llama 3 進(jìn)行文本生成
如何評(píng)估AI大模型的效果
AI大模型在自然語言處理中的應(yīng)用
【《大語言模型應(yīng)用指南》閱讀體驗(yàn)】+ 基礎(chǔ)知識(shí)學(xué)習(xí)
Transformer語言模型簡(jiǎn)介與實(shí)現(xiàn)過程
llm模型和chatGPT的區(qū)別
【大語言模型:原理與工程實(shí)踐】揭開大語言模型的面紗
OpenVINO?協(xié)同Semantic Kernel:優(yōu)化大模型應(yīng)用性能新路徑
KOALA人工智能圖像生成模型問世
Stability AI試圖通過新的圖像生成人工智能模型保持領(lǐng)先地位

Adobe提出DMV3D:3D生成只需30秒!讓文本、圖像都動(dòng)起來的新方法!

深入探索知名大模型的實(shí)際應(yīng)用

基于DiAD擴(kuò)散模型的多類異常檢測(cè)工作

高級(jí)檢索增強(qiáng)生成技術(shù)(RAG)全面指南





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論