 簡單講講RISC-V指令集CPU的參數
簡單講講RISC-V指令集CPU的參數
第二代CPU新鮮出爐。
下面簡單講講該CPU的參數。
CPU芯片封裝全貌
本次CPU采用32位RISC-V指令集架構(一代是自己瞎編指令集)。指令集就是程序指令的集合,指引硬件如何設計、如何運行。不同指令集的CPU運行的程序是不同的,相同的指令集的CPU則基本可以兼容為此指令集編寫的程序。目前主流的指令集有電腦中的x86和手機中的ARM。RISC-V作為一種新興的指令集架構,它汲取了之前的指令集的架構的優缺點,有著先天的優勢。此外,它不同于老牌指令集架構,沒有需要為前代軟件兼容的困擾,可以說是無病一身輕,整個架構輕盈簡單卻又高效。
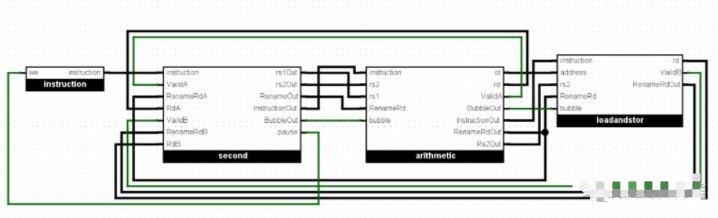
第二級流水線
采用6級流水線設計(一代是單周期設計,可以理解成一級流水線)。流水線設計是CPU設計的一大難點,開始設計之初我曾考慮是否真的要直接上5級經典流水線(一位學長曾勸我再改進一次單周期CPU),最后竟然還多設計出了1級流水線。我先解釋一下流水線是什么。CPU中有很多部件(這些部件不一定有很清楚的邊界并且不一定是處于一個集中的位置),例如譯碼器(將指令翻譯成控制信號)、寄存器組(存放數據),ALU(計算單元)和存儲控制單元(控制讀取和寫入數據)等等。單周期CPU執行一條指令需要一個周期,在這整個周期中執行指令需要分別用到上面所說的所有部件,用是都要用,但是在本周期的一個時間段中至多只能用到一個單元,那么這段時間中總有別的單元被閑置了,而這些單元是線性排布的,在用寄存器組之前必須先經過譯碼器解碼,經過ALU之前必須從寄存器組中讀取數據……比如說:一個時鐘周期是1s。譯碼占0.2s,從寄存器中讀數占0.2s,計算占0.4s,寫回數據占0.2s,加起來一共是1s。
如果我們每周期只用一個單元,讓多個指令依次使用這些單元,那么就可以極大提高CPU的執行速度,這就是流水線技術。那么時鐘周期就縮短至0.4s(與耗時最長的那一步時間齊平),其中譯碼占0.2s,從寄存器中讀數占0.2s,計算占0.4s,寫回數據占0.2s。我們發現時鐘周期可以變短了,也就是頻率變高了,處理速度變快了。
其實聽起來也沒那么難嘛?考慮一下這個問題。假設第一條指令是把A寄存器中的數值和B寄存器的數值加起來放到C的寄存器里,第二條指令是把B寄存器的數值和C的寄存器的數值加起來放到A的寄存器中。那么第二個指令開始執行到ALU(計算單元)的前端的時候就會發現第二條指令要用的C的數值呢?哦,前一條指令還沒算出C的數值,那怎么辦?那第二條指令還不能執行。什么時候能執行?第一條指令算好的時候。第一條指令什么時候算好?不知道……反正一堆麻煩。而且大多數真實情況是前面有十幾條指令要用C的數值,并且指令可能各不相同,有的是做做加法,有的可能是做做除法(異常耗時),有的甚至拿C寄存器的數值作為地址訪問內存。你們可以想想這個問題要怎么解決。
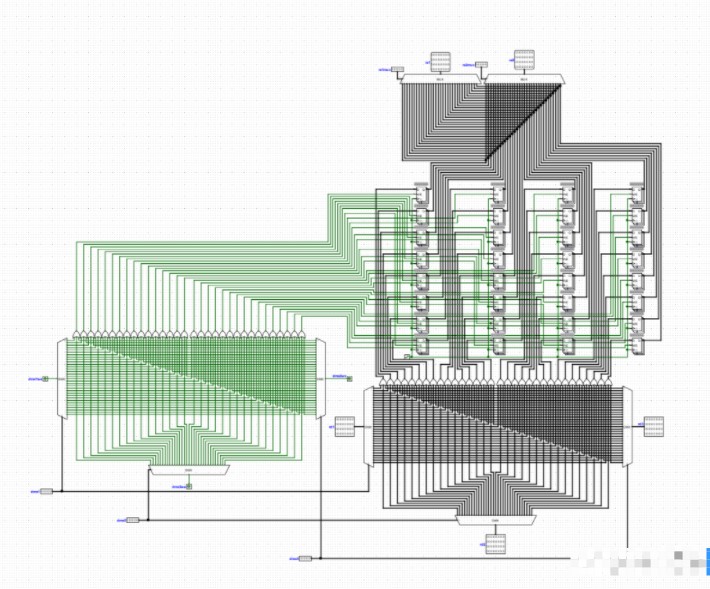
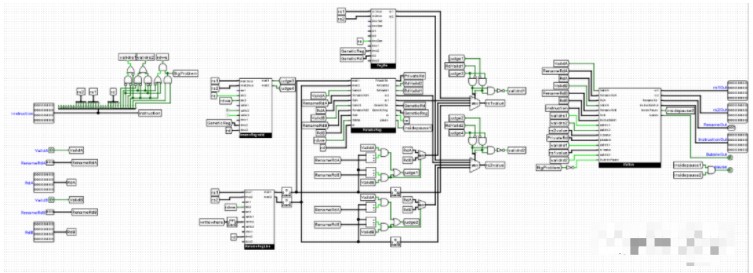
多端口寫入讀取寄存器組
第二條指令要等第一條指令。這種情況又被叫作沖突(hazard),沖突又被分為寄存器沖突和結構沖突(好像是這兩個詞,意思領會到就行),這種屬于寄存器沖突。剛才說到,第二條指令不能等第一條指令,那么我們需要一種特殊的信號控制無指令的單元,這種信號叫作空泡(bubble)。那么回過來想,雖然用了流水線,但是因為各種沖突,指令可能也不能好好執行幾個。相反,可能由于這復雜的控制電路和更高的電路運行頻率,功耗變高了,芯片面積變大了,好像適得其反。那么我們就要講到第二代CPU的第二個亮點。
亂序執行。什么第二個指令不能執行?那第三個能嗎?第三個可以!那就先執行第三個。這就是亂序執行的全部邏輯。看起來也很簡單,但做起來確實不太容易。當時設計之初也在考慮是否要實現亂序執行,因為流水線的難度已經很大了,亂序執行再加下去難度簡直要爆炸,但是我轉念一想,如果流水線沒有亂序執行,就像高樓沒有電梯(原諒我貧窮的比喻),發揮不出任何優勢。最后還是硬著頭皮上了,竟然也成了……
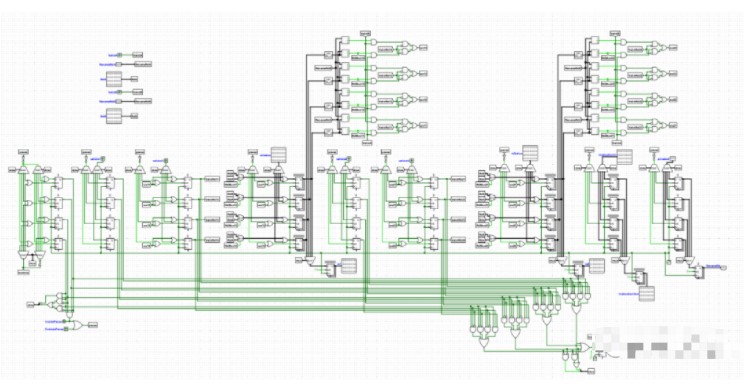
CPU保留站(解決沖突的,亂序執行的重要位置)
除了上述所講的亮點之外,還有一些先進之處。例如寄存器重命名、保留站、FIFO隊列等等。之后會再細講。
審核編輯:劉清
-
ARM
+關注
關注
134文章
9057瀏覽量
366874 -
寄存器
+關注
關注
31文章
5325瀏覽量
120052 -
cpu
+關注
關注
68文章
10829瀏覽量
211185 -
RISC-V
+關注
關注
44文章
2233瀏覽量
46045
發布評論請先 登錄
相關推薦
什么是RISC-V?以及RISC-V和ARM、X86的區別
RISC-V的指令集位寬的幾點學習心得
RISC-V和arm指令集的對比分析
RISC-V指令集的特點總結
CISC(復雜指令集)與RISC(精簡指令集)的區別
RISC-V基礎整數指令集
RISC-V 基礎學習:RISC-V 基礎介紹
什么是RISC-V?RISC-V指令集的優勢






 工商網監
工商網監
評論