 一項新的視聽分割任務
一項新的視聽分割任務
聽到“唔哩——唔哩——”的警笛聲,你可以迅速判斷出聲音來自路過的一輛急救車。
能不能讓AI根據音頻信號得到發聲物完整的、精細化的掩碼圖呢?
來自合肥工業大學、商湯、澳國立、北航、英偉達、港大和上海人工智能實驗室的研究者提出了一項新的視聽分割任務(Audio-Visual Segmentation, AVS)。
視聽分割,就是要分割出發聲物,而后生成發聲物的精細化分割圖。
相應的,研究人員提出了第一個具有像素級標注的視聽數據集AVSBench。
新任務、新的數據集,搞算法的又有新坑可以卷了。
據最新放榜結果,該論文已被ECCV 2022接受。
精準鎖定發聲物
聽覺和視覺是人類感知世界中最重要的兩個傳感器。生活里,聲音信號和視覺信號往往是互補的。
視聽表征學習(audio-visual learning)已經催生了很多有趣的任務,比如視聽通信(AVC)、視聽事件定位(AVEL)、視頻解析(AVVP)、聲源定位(SSL)等。
這里面既有判定音像是否描述同一事件/物體的分類任務,也有以熱力圖可視化大致定位發聲物的任務。
但無論哪一種,離精細化的視聽場景理解都差點意思。

△ AVS 任務與 SSL 任務的比較
視聽分割“迎難而上”,提出要準確分割出視頻幀中正在發聲的物體全貌——
即以音頻為指導信號,確定分割哪個物體,并得到其完整的像素級掩碼圖。
AVSBench 數據集
要怎么研究這個新任務呢?
鑒于當前還沒有視聽分割的開源數據集,研究人員提出AVSBench 數據集,借助它研究了新任務的兩種設置:
1、單聲源(Single-source)下的視聽分割 2、多聲源(Multi-sources)下的視聽分割
數據集中的每個視頻時長5秒。
單聲源子集包含23類,共4932個視頻,包含嬰兒、貓狗、吉他、賽車、除草機等與日常生活息息相關的發聲物。
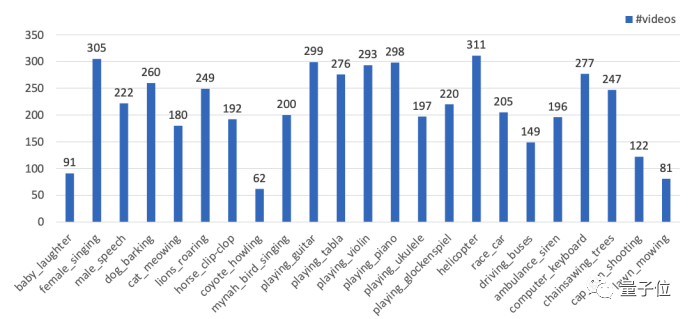
△AVSBench單源子集的數據分布
多聲源子集則包含了424個視頻。
結合難易情況,單聲源子集在半監督條件下進行,多聲源子集則以全監督條件進行。
研究人員對AVSBench里的每個視頻等間隔采樣5幀,然后人工對發聲體進行像素級標注。
對于單聲源子集,僅標注采樣的第一張視頻幀;對于多聲源子集,5幀圖像都被標注——這就是所謂的半監督和全監督。

△對單聲源子集和多聲源子集進行不同人工標注
這種像素級的標注,避免了將很多非發聲物或背景給包含進來,從而增加了模型驗證的準確性。
一個簡單的baseline方法
有了數據集,研究人員還拋磚引玉,在文中給了個簡單的baseline。
吸收傳統語義分割模型的成功經驗,研究人員提出了一個端到端的視聽分割模型。
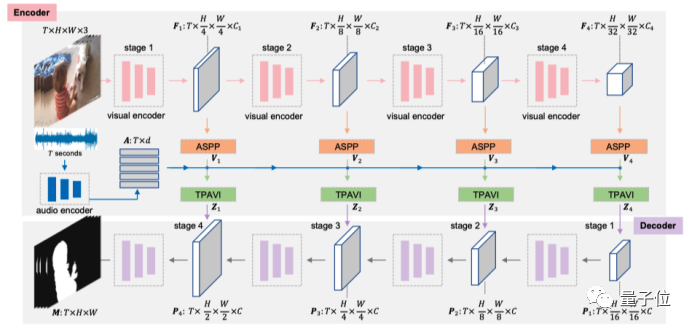
△視聽分割框架圖
這個模型遵循編碼器-解碼器的網絡架構,輸入視頻幀,最終直接輸出分割掩碼。
另外,還有兩個網絡優化目標。
一是計算預測圖和真實標簽的損失。
而針對多聲源情況,研究人員提出了掩碼視聽匹配損失函數,用來約束發聲物和音頻特征在特征空間中保持相似分布。
部分實驗結果
光說不練假把式,研究人員進行了廣泛實驗。
首先,將視聽分割與相關任務的6種方法進行了比較,研究人員選取了聲源定位(SSL)、視頻物體分割(VOS)、顯著性物體檢測(SOD)任務上的各兩個SOTA方法。
實驗結果表明,視聽分割在多個指標下取得了最佳結果。
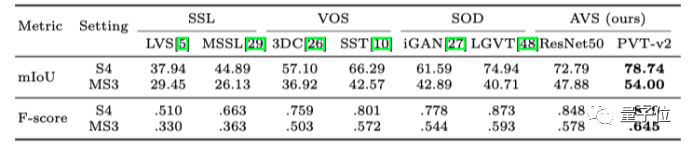
△和來自相關任務方法進行視聽分割的對比結果
其次,研究人員進行了一系列消融實驗,驗證出,利用TPAVI模塊,單聲源和多聲源設置下采用兩種backbone的視聽分割模型都能得到更大的提升。

△引入音頻的TPAVI模塊,可以更好地處理物體的形狀細節(左圖),并且有助于分割出正確的發聲物(右圖)
對于新任務的視聽匹配損失函數,實驗還驗證了其有效性。
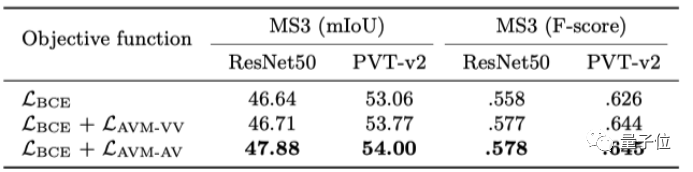
△視聽匹配損失函數的有效性
One More Thing
文中還提到,AVSBench數據集不僅可以用于所提出的視聽分割模型的訓練、測試,其也可以用于驗證聲源定位模型。
研究人員在項目主頁上表示,正在準備比AVSBench大10倍的AVSBench-v2。
-
編碼器
+關注
關注
45文章
3595瀏覽量
134149 -
AI
+關注
關注
87文章
30122瀏覽量
268407 -
數據集
+關注
關注
4文章
1205瀏覽量
24641
原文標題:聽聲辨物,這是AI視覺該干的???|ECCV 2022
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
DropDown小工具不知道當前選擇的是哪一項
漆包線標準中的一項差距
聚焦語義分割任務,如何用卷積神經網絡處理語義圖像分割?
一項新的研究表明,免費上網應該成為一項基本人權
大華股份AI刷新了Cityscapes數據集中語義分割任務的全球最好成績
研究者提出了一項新的視聽分割任務
沒你想的那么難 | 一文讀懂圖像分割

介紹一種自動駕駛汽車中可行駛區域和車道分割的高效輕量級模型

什么是圖像分割?圖像分割的體系結構和方法






 工商網監
工商網監
評論