 用于3D點云形狀分析的跨模態知識遷移統一架構的構建
用于3D點云形狀分析的跨模態知識遷移統一架構的構建
作者:Qijian Zhang, Junhui Hou, Yue Qian
作為 3D 對象的兩種基本表示方式,2D 多視圖圖像和 3D 點云從視覺外觀和幾何結構的不同方面反映了形狀信息。與基于深度學習的 2D 多視圖圖像建模不同,2D 多視圖已經在各種 3D 形狀分析任務中表現出領先的性能,而基于 3D 點云的幾何建模仍然存在學習能力不足等問題。在本文中,我們創新性地構建了一個跨模態知識遷移的統一架構,將 2D 圖像中具有判別性的視覺描述符蒸餾成為 3D 點云的幾何描述符。從技術上講,在經典的 teacher-student學習范式下,我們提出了多視圖 vision-to-geometry 蒸餾,由作為teacher的深度 2D 圖像encoder和作為 student的深度 3D 點云encoder組成。為了實現異構特征的對齊,我們進一步提出了可見性感知的特征投影,通過它可以將各點 embeddings 聚合成多視圖幾何描述符。對 3D 形狀分類、部件分割和無監督學習進行了廣泛實驗,驗證了我們方法的優越性。我們將會公開代碼和數據。
1 引言
在 3D 數據采集和感知方面的一些最新進展的促進下,基于深度學習的 3D 形狀分析在工業界和學術界受到越來越多的關注。根據 3D 形狀模型的不同表征方式,主流的學習范式可分為:
基于圖像的
基于體素的
基于點的
目前,3D 形狀理解沒有統一的建模范式,因為每種方法都有不同的優點和局限性。
基于圖像的方法 通過多個視點渲染出的多視圖 2D 圖像的集合,來表示 3D 模型。受益于先進的圖像建模架構,以及大規模存在豐富標注的圖像數據集,多視圖學習在各種形狀識別任務中展示了主導性能。然而,形狀渲染是基于高質量的人造的多邊形網格來實現的,這些網格不能直接從現實世界的傳感器或掃描儀中獲得,并且不可避免地會丟失內部的幾何結構和詳細的空間紋理信息。
基于體素的方法 使用體積網格來描述 3D 模型的空間占用,這樣標準的 3D 卷積架構可以自然地擴展到用于特征提取,而無需額外去開發特定的學習算子。不幸的是,由于計算復雜度和內存占用的指數增長,這種學習范式更適合處理低分辨率的volumes,并且需要精心配置的、復雜的分層 3D 索引結構,用于處理更密集的體素并獲取幾何細節信息。
基于點的方法 近年來,基于點的方法逐漸流行,能直接對非結構化 3D 點云進行操作而無需任何進行預處理。作為最直接的幾何表征形式,點云是許多 3D 采集設備的原始輸出,并能夠充分的記錄空間信息。然而,與在規則網格上定義的圖像和體素不同,點云具有不規則和無序的特點,這給特征提取帶來了很大困難。因此,基于點的學習框架仍有很大的性能提升空間。
受基于圖像的視覺建模和基于點的幾何建模之間互補特性的啟發,本文探索了從強大的深度圖像encoders中提取的知識遷移到深度點encoders,從而提高下游形狀分析任務的性能。在技術上,我們創新性地提出了多視圖vision-to-geometry蒸餾(MV-V2GD),這是一種遵循標準的 teacher-student架構設計的統一處理pipeline,用于跨模態的知識遷移。如圖1所示,給定一個 3D shape,我們將一組多視圖 2D 圖像輸入到teacher分支的預訓練深度 2D 圖像encoder中,進而生成多視圖的視覺描述符。而在student分支中,我們將3D點云輸入一個深度點encoder,進而產生高維的per-point embeddings。在相同的相機位姿下,我們計算特定視圖的point-wise可見性。在此基礎上,我們生成多視圖的幾何描述符。通過在多視圖視覺和幾何描述符之間執行特征對齊,可以引導student模型學習更多有區分性的point-wise特征,進而理解幾何形狀。為了驗證提出的 MV-V2GD 框架的有效性,我們選擇了常見的深度點encoder作為 student模型的baseline ,并在三個benchmark任務上進行了實驗,包括形狀分類、部件分割和無監督學習,我們實現了明顯且穩定的性能提升。
總之,本文的主要貢獻有三方面:
? 我們提出了一個統一的 MV-V2GD 學習框架,首次嘗試從多視圖 2D 視覺建模將知識遷移到 3D 幾何建模,從而進行 3D 點云的形狀分析。
? 為了促進多視圖visual-geometric特征對齊,我們特別開發了一種簡單而有效的 VAFP 機制,該機制將 per-point embeddings聚合到特定視圖的幾何描述符中。
? 在大量下游任務和baseline模型中,我們觀察到性能的提升很大,這揭示了一種新的用于增強點云網絡學習能力的通用范式。
本文的其余部分安排如下。在第2章中,我們討論了與多視圖 3D 形狀分析、deep set架構以及 2D-3D 知識遷移等密切相關的研究工作。在第3章中,我們首先在3.1 節總結我們提出的方法的工作機制;在 3.2 節和3.3 節分別介紹了主流的深度 2D 圖像和 3D 點encoders的一般形式,且這也基于 3.4節中我們構建的統一的多視圖跨模態的特征對齊方案。然后,介紹了一種新穎的 visibility-aware的特征投影機制(VAFP),它可以較好地生成特定視圖的 visual-geometric表示對。最后,在3.5節中我們總結了總體的訓練目標和策略。在第4章中,我們報告了不同baseline的深度點encoders和benchmark任務的實驗結果。最后,我們在第5章中提出了一些批判性的討論,并在第6章中總結整篇論文。
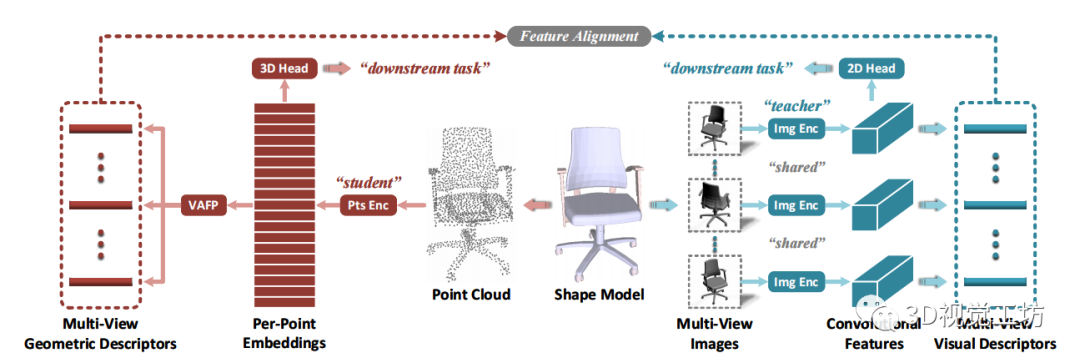
圖 1 提出的 MV-V2GD 跨模態知識遷移框架的總體流程圖,其中包括:一個預訓練的基于圖像的teacher分支(右),一個基于點的、通過多視圖特征對齊進行蒸餾的student分支(左)。在訓練階段,整個teacher分支是固定的,用于提供discriminative knowledge。而在測試階段teacher分支被移除,以便我們僅從點云進行推理。
2 相關工作
多視圖 3D 形狀分析。作為 2D 深度學習的擴展,多視圖 3D 形狀建模,通常建立在多輸入的 2D 卷積神經網絡 (CNNs) 的各種變體之上。由 MVCNN 開創,它輸入從預定義的相機位姿渲染出的多視圖圖像,并通過跨視圖的max-pooling來生成全局的形狀signature。許多后續的工作,致力于設計更高級的視圖聚合或選擇的策略。GVCNN 構建了一個三級分層的相關建模框架,該框架將多視圖描述符自適應地分組到不同的簇中。MHBN 和 RelationNet 進一步利用patch-level的交互來豐富視圖間的關系。RotationNet 將視點索引作為可學習的潛在變量,并提出聯合估計目標姿態和類別。EMV 提出了一種分組卷積的方法,該方法對旋轉組的離散子群進行操作,并提取旋轉等變的形狀描述符。最近,View-GCN將多視圖視為圖節點,從而形成相應的視圖graph,在該視圖graph上應用圖卷積來學習多視圖關系。MVTN通過引入可微分渲染來自適應地回歸得到最佳視點,從而實現端到端訓練。
3D 點云的深度學習。由 PointNet 率先采用point-wise多層感知機 (MLP),實現了置換不變的特征提取,并直接在點云上進行 3D 幾何建模,這樣的深度集architecture迅速流行。PointNet++繼承了深度 CNN 的設計范式,引入了局部鄰域聚合,并采用漸進式的下采樣進行分層提取。在后來的工作中,已經研究了各種各樣的高專業化的點卷積算子。通過學習核匹配的自適應權重,進而來模仿標準卷積進行了更復雜的點特征聚合策略,進而增強網絡容量。DGCNN 提出了一種基于圖的動態特征更新機制,可以捕獲全局的上下文信息。探索了基于學習的,而不是啟發式的子集選擇技術。最近,transformer架構也應用于點云建模。
2D 和 3D 之間的跨模態知識遷移。正如中指出的那樣,盡管知識蒸餾研究激增,但由于缺乏配對樣本,在具有明顯模態差距的跨模態場景上的研究相對較少,而當在 2D域 和 3D 域之間進行時,這項任務變得更具挑戰性。xMUDA 提出通過基于pixel-point對應關系來對齊 2D 和 3D 輸出,從單視圖圖像的源域和點云的目標域實現無監督的域自適應。PPKT 構建了一個 3D 預訓練pipeline,將對比學習策略應用于正負像素點對,從而利用 2D 預訓練知識。在相反的遷移方向上,Pri3D探索了 3D 引導的對比預訓練,用于提升 2D 感知方面。除了保持成對的 2D 像素和 3D 點之間的特征一致性外,這項工作還在于學習不變像素描述符,通過從不同視點捕獲的圖像掃描。在 有更靈活的3Dto-2D的蒸餾框架,通過特定維度的歸一化,進而對齊 2D 和 3D CNN 特征的統計分布。特別地是,為了擺脫對 2D 和 3D 模態之間細粒度對應關系的依賴,且這些模態通常獲取成本很高,這項工作還探索了一種語義感知的對抗訓練方案,用來處理不成對的 2D 圖像和 3D 體積網格。通常,由于 2D 和 3D 數據之間的對應信息的可用性,現有工作主要集中在場景級別的理解上。目前,據我們所知,之前沒有關于形狀分析任務的跨模態知識遷移的研究。
3 提出的方法
3.1 問題概述
我們考慮了兩種互補的 3D 形狀理解的學習范式,即由2D多視圖圖像驅動的2D視覺建模和由 3D點云驅動的3D幾何建模。如上所述,由于規則的數據結構和強大的學習架構,基于圖像的深度模型可以提取 discriminative feature表征,盡管丟失了部分幾何信息。相比之下,3D點云雖然保留了完整的3D幾何結構,但其結構的不規則性給特征提取帶來了很大挑戰,因此基于點的深度模型的學習能力相對不足。因此,我們的目標是從深度 2D 圖像encoder中提取判別知識,蒸餾到深度 3D 點encoder中。這實際上是一個相當具有挑戰性的問題,因為在網絡架構和數據模態方面存在顯著的域差距。

我們的工作機制與多模態融合本質上不同。在多模態融合中,多模態數據在訓練和測試階段都被作為輸入。在功能上,我們強調 MV-V2GD 作為一種通用的學習范式,可以自然地應用于通用深度點的encoders,用于增強網絡容量。
3.2 用于 2D 圖像建模的Teacher網絡
深度卷積架構,已經展示了從 2D 圖像中學習discriminative視覺特征的顯著能力。在大規模圖像數據集上,受益于預訓練的成熟的 2D CNN 的backbone網絡激增 ,我們可以方便地選擇合適且功能強大的現有深度 2D 圖像encoder作為我們的 2D teacher模型Mt ,它分別將多視圖圖像作為輸入,并相應地生成高維卷積特征圖。形式上,我們可以將teacher模型的一般形式表述為:

3.3 3D 點云建模的Student網絡
與成熟的 2D 圖像建模相比,3D 點云的深度學習仍然是一個新興但快速發展的研究領域。受限于大規模形狀數據集的稀缺性和 3D 標注的難度,當前的深度set architectures實際上還遠遠不夠深,為了緩解參數過擬合,在應用于下游任務時通常需要從頭開始訓練。因此,基于點的學習模型,在捕獲discriminative幾何特征表征方面,表現出學習能力不足。
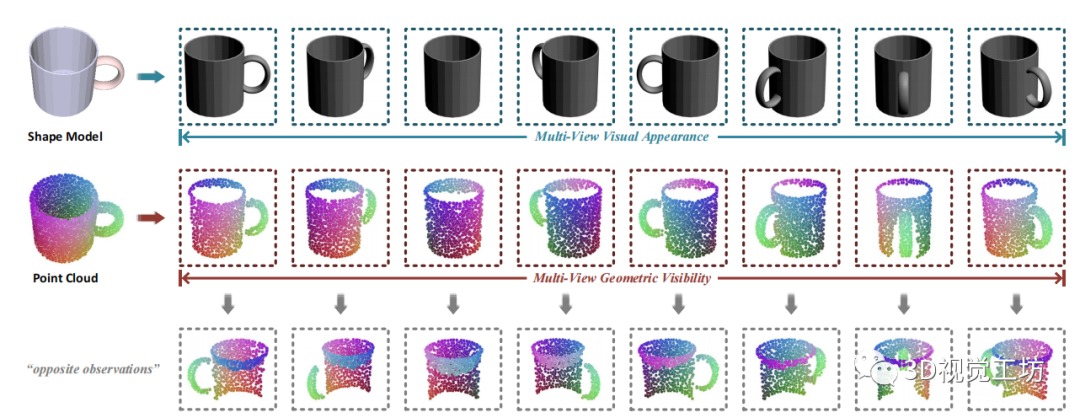
圖 2 多視圖可見性checking示意圖。在預定義的相機位姿下,我們相應地生成了一組多視圖圖像和部分點云,放置在第一行和第二行。在第三行中,我們還提供了從相反的方位角觀察時,可見點的可視化效果。
我們將深度 3D 點encoder Ms視為 3D student模型,也就是被蒸餾的目標。它使用一組不規則的空間點作為輸入,并產生高維的point-wise embeddings。不失一般性,我們可以將student模型的形式描述為:
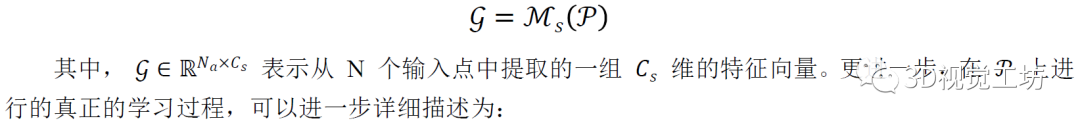

3.4 多視圖可見性感知的特征對齊


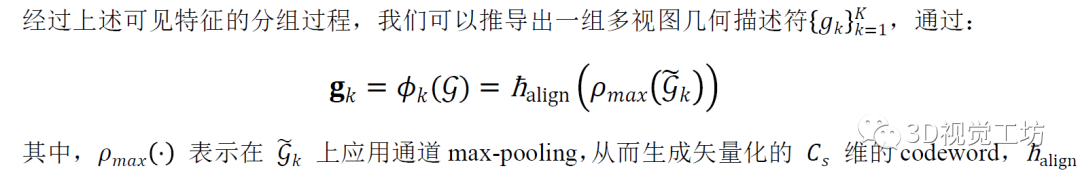
通過單個全連接層 (FC)實現,實現了視覺和幾何描述符之間的通道對齊。在4.4節,我們驗證了 VAFP 驅動的知識遷移框架,相比于傳統蒸餾范式的優越性。
3.5 總體目標

4 實驗
我們評估了我們提出的 MV-V2GD 框架在三個應用場景中的有效性,即形狀分類(第 4.1 節)、部件分割(第 4.2 節)和reconstruction-driven的無監督學習(第 4.3 節)。在每個小節中,我們介紹了benchmark數據集和數據的準備操作,之后我們提供了teacher和student模型架構的主要實現技術。最后,我們提供了具體的對比實驗和性能分析。
4.1 形狀分類
數據準備。ModelNet40 是一個常見的 3D 對象數據集,包含 12311 個多邊形網格模型,涵蓋 40 個人造類別。在官方拆分之后,我們使用 9843 個形狀數據集進行訓練,其余 2468 個數據集進行測試。

具體來說,我們采用輕量級的 2D CNN backbone(即 MobileNetV2 ),從輸入的多視圖圖像中提取深度卷積特征和矢量化視覺描述符。此外,除了從單個的全局形狀signature輸出最終的類別分數(logits)外,我們還傾向于單獨預測來自所有視圖的形狀類別,通過添加側輸出的supervisions。
Student網絡的架構。我們選擇了三種具有代表性的深度點云建模架構,包括 1) PointNet 、2) PointNet++ 和 3) DGCNN 作為目標student點encoder 。此外,我們還嘗試了 CurveNet,一種更新的SOTA學習模型。在最初的實現中,分類頭由三個全連接層組成,它們將全局形狀signature轉換為類別 logits。而在我們所有的實驗中,我們將 統一簡化為單個線性層。請注意,在測試階段,我們沒有采用任何投票技術 ,這些技術變得非常繁瑣且不穩定。
定量結果。我們在表 1 中列出了原始模型和蒸餾模型的形狀分類準確率。作為早期設計的簡單架構的工作,PointNet 官方報告的整體準確率為 89.2%,這被認為遠不能令人滿意。令人驚訝的是,在 MV-V2GD 的驅動下,該模型的性能甚至比原來的 PointNet++ 還要好,后者涉及更復雜的學習patterns。得益于增強的建模能力,PointNet++ 在蒸餾后進一步達到了極具競爭力的 93.3%。DGCNN 代表了一種常見的強大的graph-style點云建模范式,從 92.9% 提升到 93.7%,性能明顯提升 0.8%。即使對于SOTA的 CurveNet,我們的方法仍然獲得了令人滿意的性能提升,從 93.8% 提高到 94.1%。。
4.2 部件分割
數據準備。ShapeNetPart 是一個流行的 3D 對象的部分分割benchmark數據集,它提供了在 16 個對象類上定義的 50 個不同部件類別的語義標注。官方拆分后,我們有 14007 個形狀數據集用于訓練,其余 2874 個數據集用于測試。

Teacher分支的架構。與許多已經存在的成熟的多視圖學習框架的形狀分類或檢索相比,基于圖像的形狀分割方面的研究相對較少。因此,我們設計了一個標準的單圖像分割架構作為teacher分支,如圖4所示。整體的架構設計遵循經典的encoder-decoder pipeline(例如:U-Net [19]),用來生成全分辨率分割圖。在這里,teacher分支單獨使用單視圖的圖像進行預測,而不是同時對同一形狀模型的整組多視圖圖像進行分割。因為我們憑經驗發現,這種學習范式計算量大且在訓練期間難以收斂。
更具體地說,我們選擇 VGG11 作為backbone特征提取器,并移除了最后一個空間max-pooling層,從而擴大了特征圖分辨率。為了增強網絡容量,我們將 中提出的位置和通道上的attention機制添加到了原始的卷積階段。然后,通過重建從訓練shape渲染得到的視圖圖像,進而fine-tune整個backbone網絡。遵循之前部件分割框架中的常見做法,我們還集成了一個分類向量,該向量將輸入圖像的對象類別,encode到中間視覺描述符中。
Student分支的架構。我們再次采用 PointNet、PointNet++ 和 DGCNN 作為student的點encodersMs ,并使用他們初始的head網絡Hs ,用來預測每個點的語義標簽,而無需投票。
定量結果。我們在表 2 中列出了原始模型和蒸餾模型的部件分割精度。從中我們可以觀察到,我們的方法始終增強了不同類型的深度set architectures。特別是,PointNet 從 83.7% 提高到 85.9%,在 mIoU 方面具有很大的獲益。另外兩個更強大的學習框架,即 PointNet++ 和 DGCNN,也從 MV-V2GD 中受益很多,分別有 1.3% 和 1.7% 的明顯性能提升。
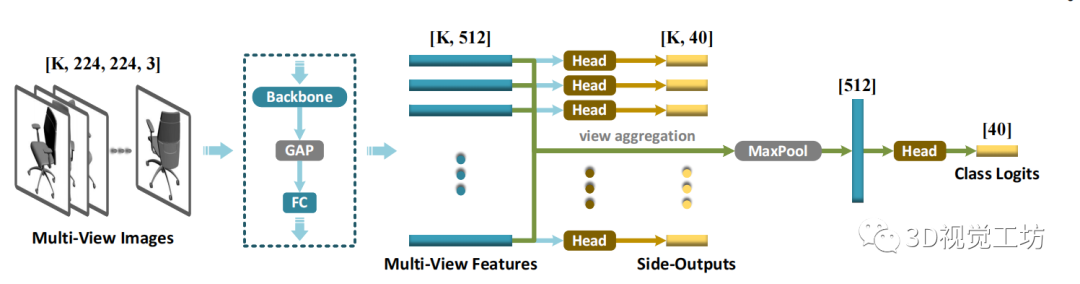
圖 3 用于2D多視圖圖像驅動的形狀分類的的Teacher學習分支表 1 ModelNet40 上 3D 形狀分類的總體準確率 (%)


圖 4 用于 2D 圖像驅動的目標部件分割的Teacher學習分支
表 2 ShapeNetPart 上目標部件分割的實例平均mIoU(%)


圖 5 用于單視圖圖像重建的 Teacher 學習分支
表 3 ModelNet40 上的Transfer分類準確率 (%)

4.3 無監督學習
以前的實驗已經證明了 MV-V2GD 在有監督學習方面的有效性,這需要特定領域的數據和標注。在本節中,我們探討了遷移通過無監督特征學習獲得的通用 2D 視覺知識,從而促進 3D 幾何建模的可能性。
遵循與 中構建的相同開發協議(稱為transfer classification),我們首先在源數據集(即 ShapeNetCoreV2)上預訓練深度點云 auto-encoder。之后,我們部署預訓練的encoder網絡,進而從不同的目標數據集(即 ModelNet40 )生成矢量化的形狀signatures。最后,在目標數據集上訓練線性 SVM 分類器,用來評估形狀signatures的判別能力。
數據準備。 ShapeNetCoreV2 [63] 是一個大型 3D 對象數據集,包含 52472 個多邊形網格模型,涵蓋 55 個對象類別。
對于幾何建模,我們應用 PDS,從 ShapeNetCoreV2 數據集和 ModelNet40 數據集中統一采樣 2048 個空間點。對于視覺建模,我們采用了與第 4.2 節中描述相同的viewpoint配置,進而在ShapeNetCoreV2 數據集上生成多視圖的圖像渲染。
Teacher 分支的架構。如圖 5所示。我們構建了一個標準卷積的 auto-encoder,用于無監督圖像的特征學習。在encode階段,我們應用了與部件分割實驗中采用的相同的backbone網絡,將輸入的視圖圖像緊湊地表征為一個矢量化的形狀signature。在decode階段,我們部署了一個全連接層來提升特征維度,以及多階段的反卷積層來實現全分辨率的圖像重建。
Student分支的架構。我們嘗試了一個經典的點云驅動的無監督幾何特征學習的架構,即 FoldingNet,作為目標student分支。從技術上講,它將給定的點encodes為一個緊湊的全局codeword向量,從而驅動隨后的lattice deformation過程,用來重建輸入的點云。
定量結果。我們在表 3 中列出了原始模型和蒸餾模型的transfer classification的準確率,我們可以觀察到,FoldingNet 從 88.4% 提高到 89.1%。
此外,在沒有特定任務預訓練的情況下,我們對遷移從自然圖像統計中學習到的常見視覺線索的潛力感興趣。為此,我們直接部署了在 ImageNet 上預訓練的原始 VGG11 的backbone網絡,用來提供teacher知識,這也增強了目標student模型,精度提高了 0.4%。
4.4 額外探索
通過設計不同的架構變體,并評估它們在 ModelNet40 上的分類性能,我們進行了額外的探索。
超參數分析。為了全面探索我們的學習框架的特點,我們通過調整兩個關鍵的超參數來修改原始 MV-V2GD 設置:1)視點數量 K ;2)加權因子Wt (等式 6)。

我們嘗試將原始點云而不是網格直接渲染到多視圖圖像中,以訓練教師分支,進一步部署為學生分支提供視覺知識。圖 6 顯示了基于點的渲染的一些典型視覺示例以及它們的網格驅動對應物。顯然,這種學習策略對于無法獲得高質量的基于網格的幾何表示的應用程序更加靈活和實用。如表 6 所示,該變體在所有蒸餾模型上仍然顯示出令人滿意的性能提升,這證明了我們提出的圖像到點知識轉移范式的普遍性。
基于點的渲染Pipeline。我們嘗試直接使用原始點云而不是網格,將其渲染到多視圖圖像中,從而訓練teacher分支,并進一步為student分支提供視覺知識。圖 6 顯示了基于點的渲染的一些典型視覺示例,以及它們的mesh-driven對應物。顯然,對于無法獲得高質量的基于網格的幾何表征的應用程序,這種學習策略更加靈活和實用。如表 6 所示,該變體在所有蒸餾模型上仍然顯示出令人滿意的性能提升,這證明了我們提出的image-to-point知識遷移范式的普遍性。
從頭開始訓練 Teacher 模型。所提出的跨模態(visual-togeometric)知識遷移框架的主要優點之一是,我們可以方便地利用現成成熟的視覺識別網絡,這些網絡在大規模帶標注的 2D 圖像數據集上充分預訓練,例如:ImageNet。一個更有趣且有前景的問題是,探索 2D 視覺和 3D 幾何建模范式之間的交互機制本身是否有益。事實上,在我們的無監督學習實驗中,我們試圖通過從頭開始訓練teacher分支來驗證這個問題,這仍然帶來了性能提升。在這里,我們進一步進行了實驗以在有監督學習場景下加強此類主張。
更具體地說,在這個基于點的渲染實驗中,我們保持所有的開發協議不變。除了,我們沒有為teacher分支的backbone網絡加載 ImageNet 預訓練權重。定量結果如表 7 所示,從中我們可以驚奇地觀察到,在點云渲染上,完全從頭開始訓練teacher分支仍然顯示出極具競爭力的性能,甚至優于其在 PointNet [11] 上的 ImageNet 預訓練和mesh-driven對應物。這種現象有力地證明了,所提出的visual-geometric學習范式的巨大潛力。
表 4 不同的渲染視點數量 (K) 的影響。

表 5 不同加權方案 () 對訓練目標的影響


圖 6 基于網格和基于點的渲染結果的可視化示例傳統蒸餾范式的適應。為了揭示我們方法的必要性和優越性,我們進一步設計了兩個baseline知識遷移pipelines,它們直接改編自經典的基于響應的 [53] 和基于特征的 [64] 蒸餾范式。第一個baseline旨在對齊從teacher分支和student分支的最后一層輸出的最終類 logits,我們稱之為 Lgt-V2GD。第二個baseline稱為 Ftr-V2GD,它專注于feature-level的指導,通過對齊矢量化的全局視覺和幾何描述符,然后將它們輸入到后續的全連接分類器。我們在表 8 中列出了不同baseline框架的性能,并通過結合表 1 中報告的相應實驗結果,觀察了一致性趨勢的幾個方面。
首先,我們的實驗結果強烈表明,vision-to-geometry知識遷移,提供了一種增強點云學習模型的通用且穩定的方法。即使是最直接的蒸餾框架 (Lgt-V2GD) ,也會在所有實驗setups中獲得不同程度的性能提升。其次,特征級的teacher指導往往比軟目標(即 logits)提供更多信息,因為我們發現 Ftr-V2GD 總是優于 LgtV2GD。第三,在我們提出的 MV-V2GD 處理pipeline下,考慮到所有蒸餾模型的性能顯著提升,許多現有點云學習框架的建模能力可能被低估了。
表 6 從原始點云渲染多視圖圖像的有效性

表 7 ModelNet40 上 3D 形狀分類的總體準確率 (%),其中teacher模型是從頭開始訓練的(即,未加載 ImageNet 預訓練的權重)

表 8 logit-driven和feature-driven的蒸餾baselines的比較。

5 討論在本節中,我們重新強調了我們在設計整體處理流程時的核心動機和原則,以及我們論文帶來的新見解,在此基礎上,我們簡要討論了未來工作中可能的擴展。
最終,本文重點揭示了將知識從 2D 視覺領域遷移到 3D 幾何領域的潛力。因此,我們避免在整個工作流程中設計復雜的學習架構或策略,因為我們相信簡潔的技術實現和穩定的性能提升可以有力地證明我們方法的價值。可以預期,更先進的多視圖 visual-geometric特征對齊技術,以及蒸餾目標將進一步增強當前的 MV-V2GD 框架。
在實驗setups方面,我們注意到現有的多視圖學習方法主要針對全局幾何建模任務,例如分類和檢索。由于特定領域的數據集準備不便,而該工作將應用場景擴展到部件分割和無監督學習,形成了更全面的評估協議。
更重要的是,我們令人鼓舞的結果激勵了研究和開發人員,在模型設計之外更加關注數據開發。考慮到大規模豐富標注的 2D 視覺數據的可用性,以及 3D 幾何對應物的稀缺性,通過 image-to-point蒸餾來增強點云學習模型,這是一種非常有前景且低成本的方法。
6 結論
在本文中,我們最先嘗試并探索了將跨模態知識從多視圖 2D 視覺建模遷移到 3D 幾何建模,從而促進 3D 點云形狀的理解。在技術上,我們研究了一個統一的 MV-V2GD 學習pipeline,適用于常見類型的、基于深度 3D 點云的學習范式,并專門定制了一種新穎的 VAFP 機制來實現多視圖圖像和點云之間的異構特征對齊。在各種應用上的大量實驗,有力地證明了我們方法的優越性、普遍性和穩定性。我們相信,我們的工作將為發展強大的深度set architectures開辟新的可能性,并促使沿著這個有前景的方向進行更多的探索。
審核編輯:郭婷
-
3D
+關注
關注
9文章
2863瀏覽量
107324 -
神經網絡
+關注
關注
42文章
4762瀏覽量
100535
原文標題:用于 3D 點云形狀分析的多視圖Vision-to-Geometry知識遷移
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于深度學習的方法在處理3D點云進行缺陷分類應用
Powerpc架構與X86架構的區別
請問在Keil uVision5下怎么為某一架構重新生成libmicroros.a?
面向3D機器視覺應用并采用DLP技術的精確點云生成參考設計
IA:利用SoC實現單一架構的廣泛靈活性
3D點云技術介紹及其與VR體驗的關系
紅獅控制Crimson 3.1新增可用于OPC統一架構的增強型功能
基于圖卷積的層級圖網絡用于基于點云的3D目標檢測





 工商網監
工商網監
評論