 參天生長大模型:昇騰AI如何強壯模型開發與創新之根?
參天生長大模型:昇騰AI如何強壯模型開發與創新之根?
自2018年谷歌發布BERT以來,預訓練大模型經過幾年的發展,以強大的算法效果,席卷了以NLP為代表的各大AI榜單與測試數據集。2020年OpenAI發布的NLP大模型GPT-3,實現了千億級參數。BERT、GPT的強大能力成為AI領域里程碑式的存在,大模型的顯著優勢,也讓產業界巨頭與機構紛紛參與其中。
大模型優秀的泛化能力、通用AI的能力、高精度、覆蓋多業務場景等優勢,降低了AI開發與應用的門檻,也讓“煉大模型”也成為AI產業的潮流。但有了算力、有了大模型,AI產業創新與落地應用就無憂無慮了嗎?答案并沒有這么簡單,很多產業需求是無法用通用模型來處理的,技術理論與應用場景之間仍然存在著代溝;一些超大規模模型在部署時也會面臨一系列問題,如算力、調參難度、硬件兼容性等。
如何讓大模型走出實驗室,走向產業,推動行業的創新,成為橫亙在AI廠商面前的難題。那么,大模型該如何完成自身的進化,去適配使用場景、進一步推動AI產業的發展呢?在這方面,華為有一些方法與路徑值得借鑒與思考。
從刷分轉向全面可用
預訓練大模型是AI持續變革的動力與核心發展方向之一,隨著AI不斷深入產業與各學科領域的過程中,科研院所及各大企業間開始了大模型軍備battle,模型的類型朝著多樣化、參數規模朝著極致化的方向發展。
百家爭鳴中,我們看到模型參數規模越來越大,數據集紀錄不斷被刷新。但在真正的產業空間里,卻很難看到大模型規模化的應用。拼模型參數,拼下游任務打榜成績,是廠商推出大模型后標榜實力的慣常操作。然而到拼落地應用的時候,許多廠商的大模型卻緘默了。
從高分到高能,大模型距離現實中的產業場景還有不短的路程要走。讓大模型從“刷分”走向千行百業,需要一場全面的轉型。
為了更好地推動大模型的發展,華為推出了人工智能大模型全流程使能體系,該體系包含從大模型規劃、開發到產業化全流程,加速大模型產業化進程。
在產業界基于昇騰AI先后推出鵬程.盤古、鵬程.神農、紫東.太初、武漢.LuoJia、華為云盤古系列等有影響力的大模型后,為進一步鼓勵大模型的研究與創新,華為推出了昇騰科研創新使能計劃,通過資金、算力、技術和社區的扶持,鼓勵高校及科研院所基于昇騰大模型沙盤,開展大模型的研究和創新,在前沿領域和熱點行業打造出世界級領先的大模型。
為了讓大模型易開發、易適配、易部署,針對基礎模型開發,華為推出基于昇思MindSpore的大模型開發套件,通過算法開發、并行計算、存儲優化、斷點續訓等技術,實現大模型的高效開發與部署。
從科研創新到行業落地,華為與產業伙伴一起成立了智能遙感開源生態聯盟和多模態人工智能產業聯盟等,目前已經有70余家合作伙伴陸續孵化出多個行業解決方案,未來華為還會聯合伙伴成立AI流體力學、AI生物醫藥及智慧生物育種等產業聯盟,助力相關領域的大模型創新和產業化發展。
大模型全流程使能體系不僅為大模型的研發與創新帶來生長的土壤,也促進著生態伙伴基于已有大模型孵化更多行業應用,同時,大模型也會得到行業更豐富的數據和更泛化應用場景的反哺。在良性循環的過程中,大模型從而生長得更加茁壯,能夠真正枝繁葉茂地賦能產業。
從宏觀的使能體系中,我們能夠感知到大模型賦能千行百業的實力與價值;在微觀個體中,透過大模型的代表紫東.太初,我們也能夠看到其帶來的產業之變。
紫東.太初的開發之根
現階段,產學研界的大模型主要集中在NLP和CV領域。行業內傳統的以文本、圖像為主的單模態或雙模態預訓練模型,覆蓋的范圍與滿足的需求有限,不能充分發揮數據生產力,限制了下一階段AI 的應用創新。多模態大模型應運而生,打通圖像、文本、語音等不同模態數據的協同轉化,進而使AI應用更貼合人類行為習慣與現實需求,成為當前人工智能行業攻堅點之一。
紫東.太初是全球首個三模態千億參數大模型,作為多模態模型的代表,正在全力助推AI研發規則和產業應用模式變革,加速各行業智能化轉型實踐。在7月29日-31日的首屆中國算力大會上,“紫東.太初”大模型榮獲“DC Tech創新先鋒”優秀成果獎。
創新先鋒優秀成果獎評選大模型的維度嚴謹并全面,無論是技術、系統,還是應用賦能等方面,都是重點考量的因素。紫東.太初大模型被業界認可,成為標桿引領多模態大模型,能夠保持優秀并持續創新的前提,源于其強壯的AI根技術,在AI框架、AI算力等層面滿足大模型的“創新”需求。
紫東.太初是中科院自動化所以昇騰AI基礎軟硬件為基礎,基于全場景AI框架昇思MindSpore打造的三模態模型,紫東.太初兼具跨模態理解和生成能力,與單模態和圖文兩模態相比,其采用一個大模型就可以靈活支撐圖-文-音全場景AI應用,具有在無監督情況下多任務聯合學習、并快速遷移到不同領域數據的強大能力。
紫東.太初目前已經具備領先的圖文音跨模態理解與生成能力,可輕松完成智能問答、圖片生成、視頻理解與等任務,這些能力將在工業質檢、影視創作、互聯網推薦、智能駕駛等領域廣泛應用。例如在紡織工業生產線中的應用案例中,紫東.太初融合多模態信息,可以通過聲音識別來判斷紡織機運轉過程中斷經和斷緯的情形,同時通過視覺識別來判斷布匹的缺陷,展示出綜合研判的能力和廣闊的應用前景。
由于三模態大模型非常接近人類的信息處理方式,其對信息數據有非常好的協同掌握能力,因此可以非常廣泛地應用于產學各領域,孵化出更多新應用。新華社技術局、長安汽車、中國移動、千博手語等企業通過加盟多模態人工智能產業聯盟,將開源的多模態大模型與自身業務融合創新,基于紫東.太初陸續孵化出新媒體內容檢索平臺、智能座艙、南宋御街數字人、手語教考一體機等場景化行業應用,充分展現了大模型的潛力與產業價值。
從大模型技術深處挖掘,我們會發現紫東.太初的打造,得益于昇騰AI的產業底座,尤其是昇思對大模型的原生支持,讓大模型具備了快速開發、極簡訓練的“開發之根”。
澆灌創新之花
從昇思AI框架中汲取“創新”的營養澆灌大模型,是使能其發展的關鍵。昇思 MindSpore 在進行架構設計時就考慮了大模型開發時遇到的內存占用、通信瓶頸、調試復雜、部署難等問題,針對性進行技術研究與創新。
在大模型支持方面,昇思實現了原生支持大模型,能夠在業界率先支持全自動并行計算。在大模型訓練中,可以同時使用數據并行、算子級模型并行、Pipeline 模型并行、優化器模型并行、異構并行、重計算、高效內存復用多維度、全種類的分布式并行策略;原創集群拓撲感知的多維度自動混合并行,實現超大模型自動切分、并行計算,顯著提升集群加速能力;新的 DNN分布式并行編程范式,可以實現低代碼算法切換,大幅節省開發時間。
在科研創新和應用領域,昇思面向 8 大科學計算場景推出 MindSpore Science 系列套件,其包含業界領先的數據集、基礎模型、預置高精度模型和前后處理工具,可以加速科學行業應用開發。
面向產業生態的開放,昇思正在與產學研各界一同推進開源開放,昇思 MindSpore AI 框架已經成為大模型開發的技術支撐,開源開放更使得產學界可以基于它研發自己的大模型。昇騰社區和昇思MindSpore社區一直在加強對大模型開源開放的支持。截至7月,昇思社區下載量已經突破200萬,社區貢獻者超過5900人。
目前,華為聯合科研機構和產業界,基于昇思 MindSpore AI 框架與昇騰 AI 強大算力,不斷發展基礎大模型和行業大模型的產業生態,賦能千行百業數字化、智能化。
例如,鵬城實驗室基于昇思 MindSpore 先后推出了業界首個 2000 億參數中文預訓練語言模型鵬程.盤古和面向生物醫學領域的鵬程.神農大模型,深度賦能文本生成領域與生物制藥;武漢大學在嵌入昇思MindSpore先進技術特性后打造了全球首個遙感影像智能解譯專用框架武漢.LuoJiaNet和業界最大遙感樣本庫武漢.LuoJiaSET,為遙感應用開發提供便利。
從根技術創新提升大模型的性能,到賦能不同科學計算行業應用的加速開發,大模型全流程使能體系的構建,產業生態的開源開放與架橋連接,基于昇騰AI軟硬協同的技術創新與產業服務助力,大模型的創新與產業落地之路越來越寬敞,加速各行業智能化轉型實踐,未來會有更多不同領域的原創技術成果誕生。
華為為大模型確立了從研致用的范式,推動大模型走向服務產業的新階段,不同的行業在各類應用場景中驗證著大模型的能力。遍地花開的成果,離不開昇騰 AI 提供的強大算力底座與昇思 MindSpore AI 框架的賦能,澆灌著大模型的研發與創新,為其注入活力與生命力,大模型的產業之花得以在數智時代的原野中爭奇斗艷,盎然生機,一幅智慧生活的圖景正在徐徐展開。
-
華為
+關注
關注
216文章
34327瀏覽量
251220 -
算法
+關注
關注
23文章
4601瀏覽量
92671 -
AI
+關注
關注
87文章
30239瀏覽量
268475 -
nlp
+關注
關注
1文章
487瀏覽量
22015 -
昇騰
+關注
關注
1文章
132瀏覽量
6586 -
昇騰AI
+關注
關注
0文章
79瀏覽量
538 -
大模型
+關注
關注
2文章
2339瀏覽量
2500
發布評論請先 登錄
相關推薦
谷東科技民航維修智能決策大模型榮獲華為昇騰技術認證
研華發布高性能工業邊緣 AI 算力方案 攜手昇騰引領邊緣 AI 革新


基于昇騰AI,迅龍軟件發布OrangePi AIpro 20T,共推AI應用落地

香橙派亮相昇騰AI開發者創享日,打造“AI+鴻蒙”高算力開發板

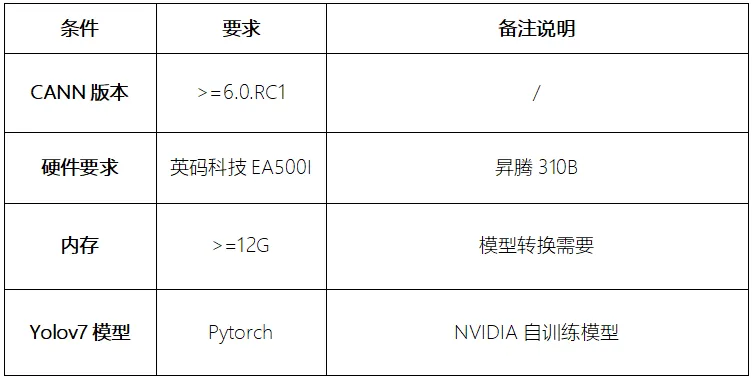
基于昇騰AI Yolov7模型遷移到昇騰平臺EA500I邊緣計算盒子的實操指南
華為云昇騰AI云服務可適配100多個大模型
畢昇大模型應用開發平臺+浪潮信息AIStation,讓大模型定制更簡單

華為發布會大模型翻車?昇騰社區回應!
軟通動力受邀參加華為舉辦的“昇思AI框架及大模型技術論壇”
防止AI大模型被黑客病毒入侵控制(原創)聆思大模型AI開發套件評測4
云知聲山海大模型獲得華為昇騰技術認證


香橙派聯合華為發布基于昇騰的Orange Pi AIpro開發板 業界首款基于昇騰AI開發板






 工商網監
工商網監
評論