 CXL將成為跨計算引擎的內存結構標準
CXL將成為跨計算引擎的內存結構標準
系統架構師通常對未來不耐煩,尤其是當他們看到好的東西即將到來時。因此,當談到英特爾創建的 Compute Express Link 或 CXL 互連時,我們可以有一定的期待,因為該互連現在已經吸收了 Hewlett Packard Enterprise 的 Gen-Z 技術和IBM 的 OpenCAPI 技術。
在可預見的未來, CXL將成為跨計算引擎的內存結構標準。
CXL 2.0 規范在 PCI-Express 5.0 外圍互連中帶來內存池(memory pooling),這很快將在 CPU 引擎上可用,這是偉大的。但是所有的目光都已經轉向剛剛發布的 CXL 3.0 規范,該規范建立在 2023 年推出的 PCI-Express 6.0 互連之上,帶寬是上一代的2倍。
人們也已經開始考慮 CXL 4.0 ,在PCI Express 7.0之上提供另一個 2 倍帶寬。根據預測,這將于 2025 年推出。
在某種程度上,我們預計 CXL 將遵循 IBM 的“Bluelink”OpenCAPI 互連所開辟的道路。“藍色巨人”在“Cumulus”和“Nimbus”Power9 處理器中使用 Bluelink 互連來提供跨多個處理器的 NUMA 互連,運行 Nvidia 的 NVLink 協議以提供跨 Power9 CPU 和 Nvidia“Volta”V100 GPU 加速器的內存一致性,并通過 OpenCAPI 端口為其他類型的加速器提供更通用的內存連貫鏈接。
但顯然,OpenCAPI 和 CXL 的路徑不會完全相同。OpenCAPI 是 kaput,CXL 是數據中心內存一致性的標準。
IBM 在“Cirrus”Power10 處理器上放置了更快的 OpenCAPI 端口,它們用于提供與 Power9 芯片一樣的 NUMA 鏈接,以及使用 Bluelink SerDes 作為內存控制器的新 OpenCAPI 內存接口。與 DDR4 或 DDR5 控制器相比,運行速度稍慢。但它占用的芯片空間要少得多,消耗的功率也更少——并且具有與芯片中的其他 I/O 完全相同的優點。
理論上,IBM 可以支持在 Power10 上的 OpenCAPI 互連上運行 CXL 和 NVLink 協議,但 Nvidia 有一些我們不理解的酸葡萄——不提供與 Nvidia 當前的“Ampere”A100 和即將推出的“Hopper”H100 GPU相干的內存。在 OpenCAPI 和 NVLink 之間的信號速率和通道數方面,IBM 和 Nvidia 之間可能存在阻抗不匹配。IBM 在其 Power10 芯片上有 PCI-Express 5.0 控制器——這些是獨特的控制器,不是 Bluelink SerDes——因此本可以支持 CXL 一致性協議,但據我們所知,藍色巨人也選擇不這樣做.
鑒于我們認為 CXL 是許多 GPU 加速器及其內存將在未來鏈接到 CPU 的方式,IBM 的這一策略似乎很奇怪。因此,我們正在推動 IBM 推出支持 CXL 2.0 和 NVLink 3.0 相干鏈路(coherent links)的 Power10+ 處理器,以及更高的核心數和更高的時鐘速度,這可能發生在一年或一年半之后。
鑒于其 OpenCAPI 內存的巨大優勢,IBM 沒有理由無法獲得部分 AI 和 HPC 預算,該內存通過 24 核雙芯片模塊驅動 818 GB/秒的內存帶寬。我們還預計未來來自 Nvidia 的數據中心 GPU 計算引擎將以某種方式支持 CXL,但具體如何與 NVLink 并排或合并尚不清楚。
目前還不清楚HPE 如何將 Gen-Z 知識產權捐贈給 CXL 聯盟。但IBM 上周捐贈給 CXL 指導組織的 OpenCAPI 知識產權將用于打造 CXL 4.0 標準,這兩家系統供應商正在給CXL方面提供他們必須力所能及的幫助。為此,他們應該受到贊揚。
換句話說,我們認為 Gen-Z 和 OpenCAPI 都遠遠領先于 CXL,并且可以很容易地被用作節點內(in-node)和節點間(inter-node)內存和加速器結構。HPE 已經設計了一套非常優雅的內存結構開關和光收發器,IBM 是唯一一家在其Bluelink SerDes 上提供跨 Nvidia GPU 的 CPU-GPU 一致性以及通過其 OpenCAPI 內存接口連接盒內或盒內內存的能力的 CPU 供應商。
我們相信 Gen-Z 和 OpenCAPI 技術將有助于使 CXL 變得更好,并改進所提供的一致性的種類。CXL 最初提供了一種非對稱一致性,其中 CPU 可以像本地一樣讀取和寫入加速器中的遠程存儲器,但使用 PCI-Express 總線而不是專有的 NUMA 互連——這是一個巨大的過度簡化——而不是擁有完整的緩存CPU 和加速器之間的一致性,這會產生大量開銷,并且會產生自身的阻抗不匹配,因為過去 PCI-Express 比 NUMA 互連要慢。
但正如我們之前指出的那樣,隨著 PCI-Express 的速度每兩年左右翻一番,并且隨著帶寬的跳躍,延遲保持穩定,我們認為 CXL 很有可能成為一種通用的 NUMA 互連和內存控制器,就像 IBM 對 OpenCAPI 所做的那樣,英特爾已經為 CXL 內存和 CXL NUMA 提出了這一建議,Marvell 對 CXL 內存當然也是這么想的也是。這就是為什么在 CXL 3.0 中,該協議提供了所謂的“增強的一致性”,這是另一種說法,它恰好是設備之間的那種完全一致性。
例如,Nvidia 在一個NVSwitch 網絡或 IBM 在 Power9 CPU 和 Nvidia Volta GPU 之間提供。英特爾一開始不想做的那種完全一致性。這意味著支持 CXL.memory 子協議的設備可以通過 CXL 交換機或直接點對點網絡直接訪問彼此的內存,而不是不對稱地訪問。
CXL 沒有理由不能成為內存區域網絡的基礎,因為 IBM在 Power10 芯片上通過其OpenCAPI 內存的“memory inception””實現創建了內存區域網絡。正如英特爾和 Marvell 在他們的概念演示中所展示的那樣,chippery和interconnects的調色板對于像 CXL 這樣的標準是非常開放的,并且在許多向量上對其進行改進非常重要。行業讓英特爾贏得了這一場競爭,從長遠來看,我們會因此而變得更好。英特爾在很大程度上放棄了 CXL,現在各種外部創新都可以承擔。
英特爾將 Universal Chiplet Interconnect Express推廣為用于連接計算引擎插槽內的chiplet的標準也是如此。基本上,我們將生活在這樣一個世界中:運行 UCI-Express 的 PCI-Express 連接插槽內的chiplet,運行 CXL 的 PCI-Express 連接節點內的插槽和芯片(這變得越來越短暫),并且 PCI-Express 交換結構跨越有朝一日,一些機架甚至一行可能會使用 CXL 將 CPU、加速器、內存和閃存連接在一起,形成可分解和可組合的虛擬硬件服務器。
目前,即將出現的是在 PCI-Express 6.0 傳輸之上運行的 CXL 3.0,以下是 CXL 3.0 如何與之前的 CXL 1.0/1.1 版本和當前在 PCI-Express 之上的 CXL 2.0 版本疊加5.0 運輸:
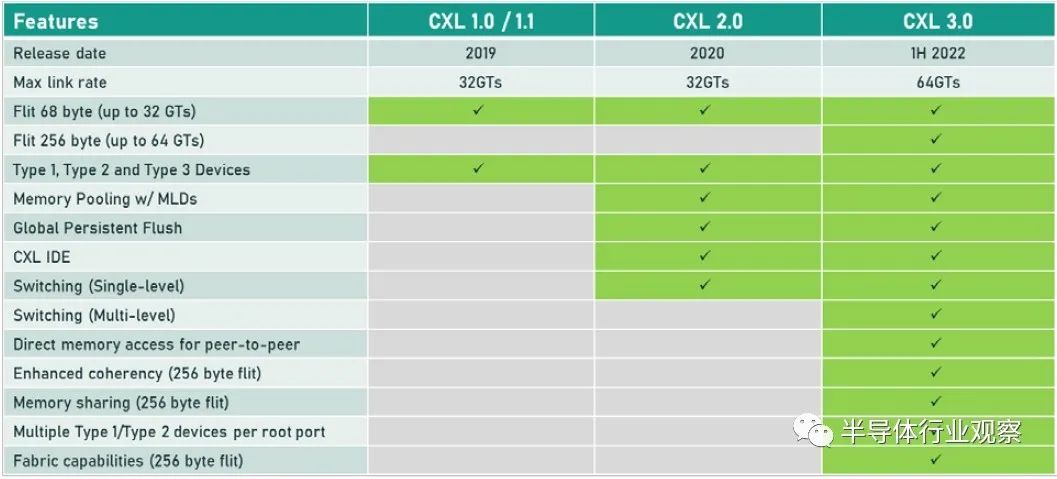
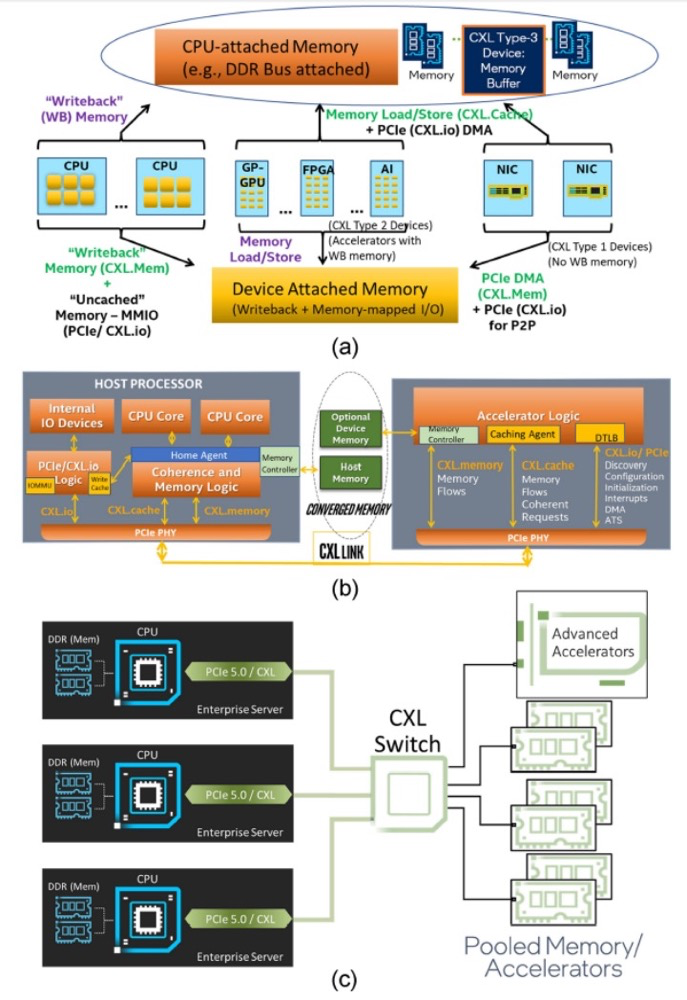
當 CXL 協議在 I/O 模式下運行時——即所謂的 CXL.io——它本質上與用于 I/O 設備的 PCI-Express 外圍協議相同。CXL.cache 和 CXL.memory 協議在 PCI-Express 傳輸之上添加緩存和內存尋址,并以 PCI-Express 協議的大約一半延遲運行。 舉例而言,就像我們在 2021 年 9 月與英特爾交談時所做的那樣,CXL 協議規范要求當緩存線丟失時對 snoop 命令的 snoop 響應必須低于 50 納秒(引腳到引腳),而對于內存讀取(引腳到引腳),延遲必須低于 80 納秒。相比之下,在典型的 X86 服務器中,本地 DDR4 內存訪問 CPU 插槽大約需要 80 納秒,而 NUMA 訪問相鄰 CPU 插槽中的遠程內存大約需要 135 納秒。 通過在 PCI-Express 6.0 傳輸之上運行 CXL 3.0 協議,所有三種類型的驅動程序的帶寬都增加了一倍,而延遲沒有任何增加。由于 256 字節流控制單元或 flit 固定數據包大小(大于 PCI-Express 5.0 傳輸中使用的 64 字節數據包),帶寬增加到 256 GB/秒 x16 通道(包括兩個方向) ) 和 PAM-4 脈沖幅度調制編碼,可將 PCI-Express 傳輸上的每個信號的比特數加倍。PCI-Express 協議結合使用循環冗余校驗 (CRC:cyclic redundancy check) 和三向前向糾錯 (FEC :three-way forward error correction) 算法來保護通過線路傳輸的數據,這是一種比以前的 PCI-Express 協議更好的方法因此為什么選擇 PCI-Express 6.0 和 CXL 3。 CXL 3.0 協議確實具有低延遲 CRC 算法,該算法將 256 B flit 分成 128 B 半 flit,并在這些子 flit 上進行 CRC 檢查和傳輸,這可以將傳輸延遲減少 2 納秒到 5 納秒之間。 CXL 3.0 帶來的新功能是內存共享,這與 CXL 2.0 提供的內存池不同。這是內存池的樣子:
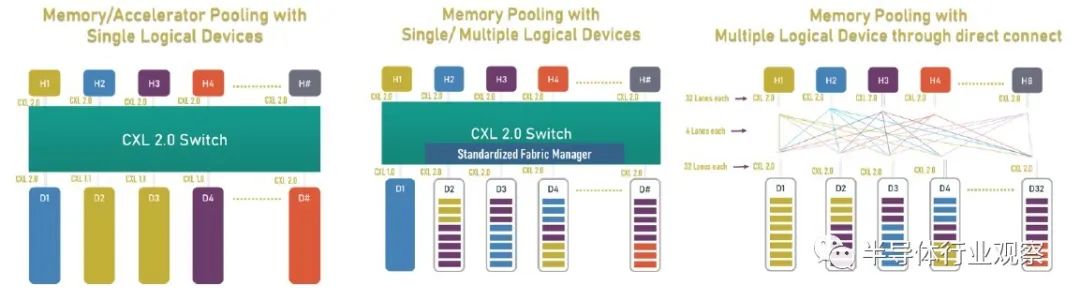
借助內存池,您可以在帶有 CPU 的主機和帶有自己內存的加速器的機箱之間使用 CXL 的 PCI-Express 交換機,或者只是原始內存塊(有或沒有結構管理器),然后分配加速器(及其內存) 或根據需要分配給主機的內存容量。如上圖右側所示,如果您想硬編碼 PCI-Express 拓撲以供它們鏈接,您也可以在所有主機和所有加速器或內存設備之間進行點對點互連,而無需交換機。 使用 CXL 3.0 內存共享,設備上的內存可以同時與多個主機同時共享。下圖顯示了 CXL 3.0 啟用的設備共享內存和共享區域的一致副本的組合:
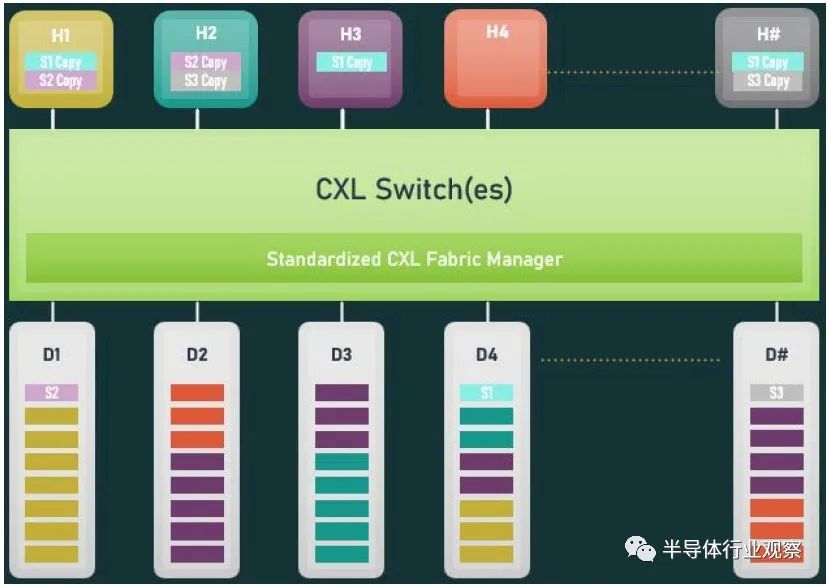
系統和集群設計人員將能夠將內存池和內存共享技術與 CXL 3.0 混合和匹配。CXL 3.0 也將允許多層交換機,這在 CXL 2.0 中是不可能的,因此您可以想象具有各種拓撲和層的 PCI-Express 網絡能夠將各種設備和存儲器捆綁到交換機結構中。在超大規模和云構建者中常見的 Spine/Leaf 網絡是可能的,包括僅共享其緩存的設備、僅共享其內存的設備以及共享其緩存和內存的設備。(即 CXL 設備命名法中的Type 1、Type 3 和Type 2。) CXL 結構將是真正有用的,并且在 3.0 規范中啟用。使用結構,您可以獲得支持 CXL 的設備的軟件定義的動態網絡,而不是使用鏈接特定 CXL 設備的特定拓撲設置的靜態網絡。以下是在 CXL 2.0 中無法實現的結構中實現的非樹拓撲的簡單示例:
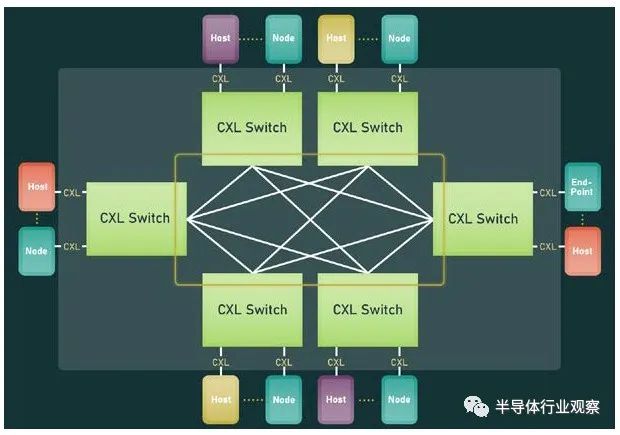
這是整潔的一點。CXL 3.0 結構可以擴展到 4,096 個 CXL 設備。現在,問問自己這個問題:世界上有多少大型iron NUMA系統和 HPC 或 AI 超級計算機擁有超過 4,096 臺設備?沒有你想的那么多。因此,正如我們多年來一直在說的那樣,對于特定類別的集群系統,無論節點在其內存中是松散耦合還是緊密耦合,運行 CXL 的 PCI-Express 結構幾乎就是它們聯網所需的全部。以太網或 InfiniBand 將僅用于與外界對話。我們也希望看到 DRAM 前端的閃存設備作為存儲集群下的硬件作為快速緩存。(傲騰 3D XPoint 持久內存不再是一個選項. 但對于某種形式的 PCM 存儲器或另一種形式的 ReRAM,總是有希望的。) 當我們坐在這里思考所有這些時,我們不禁思考內存共享如何簡化 HPC 和 AI 應用程序的編程,特別是如果共享內存中有足夠的計算來對數據進行一些集體操作處理,這就有各種有趣的可能性。. 無論如何, CXL 結構將會很有趣,它將成為許多系統架構的核心。訣竅在于共享內存以降低 DRAM 的有效成本——微軟 Azure的研究表明,在其云上,內存容量利用率平均僅為 40% 左右,而運行的虛擬機中有一半從未觸及超過一半從底層硬件分配給他們的管理程序的內存——通過 CXL 切換和具有內存的設備和作為內存的設備的可組合性帶來的靈活性。 我們想要的,也是我們一直想要的,是以內存為中心的系統架構,它允許各種計算引擎在內存中共享被操作的數據,并盡可能少地移動這些數據。至少在理論上,這是提高系統能效的途徑。幾年之內,我們將在實踐中對這一切進行測試,這確實令人興奮。我們現在需要的只是兩年前的 PCI-Express 7.0,我們可以享受一些真正的樂趣。
系統內存的未來主要是 CXL
超大規模制造商和云構建者在其 X86 服務器中投入的最昂貴的組件是什么?它是 GPU 加速器,正確。因此,讓我們以另一種方式問這個問題:在構成其大部分服務器機群的更通用、非加速服務器中,最昂貴的組件是什么?存儲。 如果你計算一下隨著時間推移的成本,大約十年前,CPU 曾經占數據中心基礎設施工作負載基本服務器成本的一半左右;HPC 系統在內核上的強度更高,在內存上的強度更低。內存約占系統成本的 15%,主板約占 10%,本地存儲(即磁盤驅動器)約占 5% 到 10%,具體取決于您想要該磁盤的容量或速度。其余部分由電源、網絡接口和機箱組成,在很多情況下,網絡接口已經在主板上,因此除了公司想要更快的以太網或 InfiniBand 接口的情況外,成本已經捆綁在一起。 隨著時間的推移,閃存被添加到系統中,服務器的主內存成本飆升至頂峰(但相對于其他組件的價格有所下降),隨著 AMD 的重新進入,X86 CPU 又回到了競爭。因此,通用服務器的服務器成本餅中的相對切片大小在這里和那里擴大和縮小。根據配置,CPU 和主內存各占系統成本的三分之一左右,而如今,內存通常比 CPU 更昂貴。對于超大規模和云建設者來說,內存絕對是最昂貴的項目,因為 X86 CPU 上的競爭更加激烈,從而降低了成本。 有趣的是:據英特爾稱,CPU 仍占 IT 設備功耗預算的 32% 左右,內存僅消耗 14%,外圍設備成本約為 20%,主板約為 10%,磁盤驅動器約為 5%。(我們推測,閃存是功耗預算派的外圍部分)。包括計算、存儲和網絡在內的IT 設備消耗的功耗不到一半,而電源調節、照明、安全系統和其他方面數據中心設施消耗了一半多一點,這給出了相當可憐的 1.8 的電源使用效率。典型的超大規模和云構建者數據中心的 PUE 約為 1.2。 可以這么說,內存是一個很大的成本因素,并且由于許多應用程序受到內存帶寬和內存容量的限制,將主內存與 CPU 以及實際上任何計算引擎分離,是我們所寫的可組合數據中心的一部分很多在下一個平臺。 原因很簡單:我們希望來自芯片的 I/O 也是可配置的,這意味著,從長遠來看,融合內存控制器和 PCI-Express 控制器,或者提出通用傳輸和控制器它可以根據插入端口的內容說出 I/O 或內存語義。IBM在 Power10 處理器上使用其 OpenCAPI 內存接口完成了后者,但我們認為隨著時間的推移英特爾和其他公司將使用在 PCI-Express 傳輸之上運行的 CXL 協議執行前者。 芯片制造商 Marvell 不再試圖將其 ThunderX 系列 Arm 服務器 CPU 銷售到數據中心,但仍希望參與 CXL 內存游戲。為此,早在 5 月初,它就收購了一家名為 Tanzanite Silicon Solutions 的初創公司,用于其智能邏輯接口連接器,這是 CPU 和內存之間的 CXL 橋,將幫助打散服務器,并將其重新組合在一起方式——自下一個平臺建立之前我們就一直在談論的事情。Tanzanite 成立于 2020 年,去年展示了第一個使用 FPGA 的服務器 CXL 內存池,因為它正在對其 SLIC 芯片進行最后潤色。
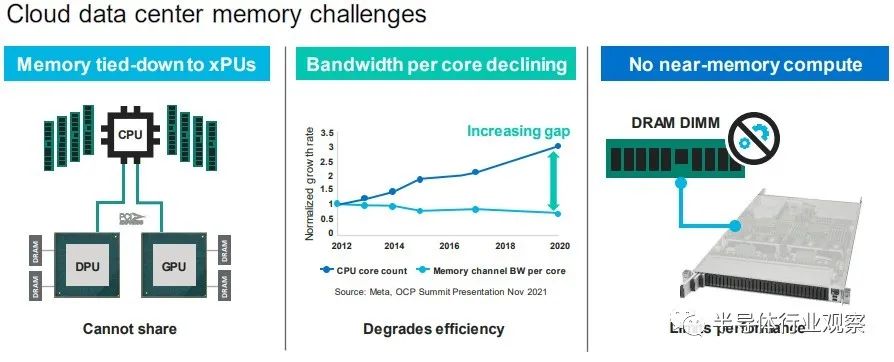
“今天,內存必須通過內存控制器連接到 CPU、GPU、DPU,”Marvell 閃存業務部副總裁 Thad Omura 告訴The Next Platform。“這有兩個問題。一是非常昂貴的內存要么未被充分利用,要么更糟糕的是,未被使用。在某些情況下,還有更多的未充分利用,而不僅僅是內存。如果您需要更多內存來處理大型工作負載,有時您會在系統中添加另一個 CPU 以提高內存容量和帶寬,但該 CPU 也可能未得到充分利用。這實際上是第二個問題:這種基礎設施無法擴展。如果不添加更多 CPU,就無法向系統添加更多內存。 所以問題是這樣的:你如何讓內存成為可共享和可擴展的?” 正如 Omura 在上表中指出的那樣,另一個問題是 CPU 上的內核數量比內存帶寬增長得更快,因此內核的性能與為其供電的 DIMM 之間的差距越來越大,正如上面的 Meta Platforms 數據所示. 最后,除了一些科學項目之外,沒有辦法聚合內存并將計算移近它以便可以就地處理,這限制了系統的整體性能。 來自 Hewlett Packard Enterprise 的Gen Z 、來自 IBM 的 OpenCAPI 以及來自 Xilinx 和 Arm 陣型的 CCIX 都是融合內存和 I/O 傳輸的競爭者,但從長遠來看,顯然英特爾的 CXL 已成為每個人都將支持的標準,且他已經獲得了Gen Z和OpenCAPI 的支持。 “CXL 獲得了很大的吸引力,并且基本上與所有主要的超大規模廠商合作,幫助他們弄清楚如何部署這項技術,”Omura 說。因此,對Tanzanite的收購(其價值未披露)于 5 月底完成。 借助 SLIC 芯片,Marvell 將能夠通過 CXL 擴展控制器以及比 DIMM 尺寸更大的更胖更高的擴展內存模塊,幫助行業創建標準 DIMM 尺寸。(IBM 已經用它的幾代 Power Systems 服務器和他們自己開發的“Centaur”:緩沖內存控制器完成了后者。) Omura 說,CXL 內存要做的第一件事就是打開現代處理器上 DRAM 和 PCI-Express 控制器的內存帶寬,我們同意這個觀點。
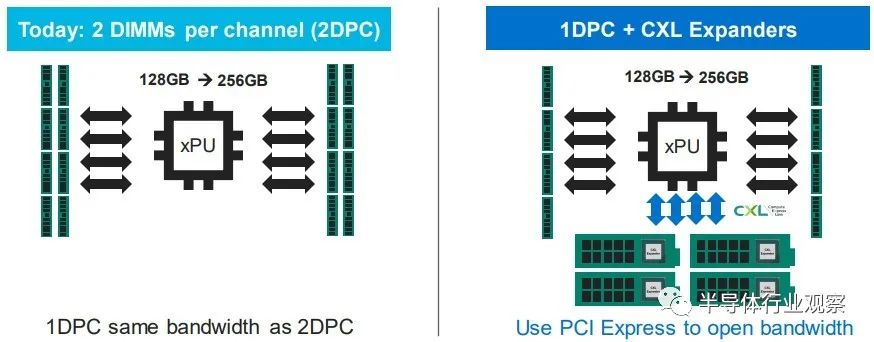
如果您現在有一個系統并且您在其內存插槽中設置了帶寬,您可以通過為每個內存通道添加兩個 DIMM 來增加容量,但是每個 DIMM 獲得一半的內存帶寬。但是隨著使用 SLIC 芯片向系統添加 CXL 內存 DIMM,您可以使用大部分 PCI-Express 總線為系統添加更多內存通道。 誠然,來自 PCI-Express 5.0 插槽的帶寬沒有芯片上的 DRAM 控制器那么高,延遲也沒有那么低,但它可以工作。在某些時候,當 PCI-Express 6.0 推出時,某些類別的處理器可能不需要 DDR5 或 DDR6 內存控制器,DDR 控制器可能會變成奇特的部件,就像 HBM 堆疊內存是奇特的并且只用于特殊的用例。希望 CXL 內存超過 PCI-Express 5.0 和 6。0 不會比通過 NUMA 鏈接到多插槽系統中的相鄰插槽更糟糕(如果有的話),而且一旦 CXL 端口實際上是系統和 DDR 上的主內存端口,它可能更不麻煩和 HBM 是專用的、奇異的內存,僅在必要時使用。至少這是我們認為可能發生的事情。 CXL 內存擴展只是這一演變的第一階段。不久之后,像 Marvell 的 SLIC 之類的 CXL 芯片將被用于創建跨多種(通常是不兼容的)計算引擎的共享內存池,甚至更進一步,我們可以期待 CXL 交換基礎設施創建一個不同類型的存儲設備和不同類型的計算引擎之間的可組合結構。像這樣:
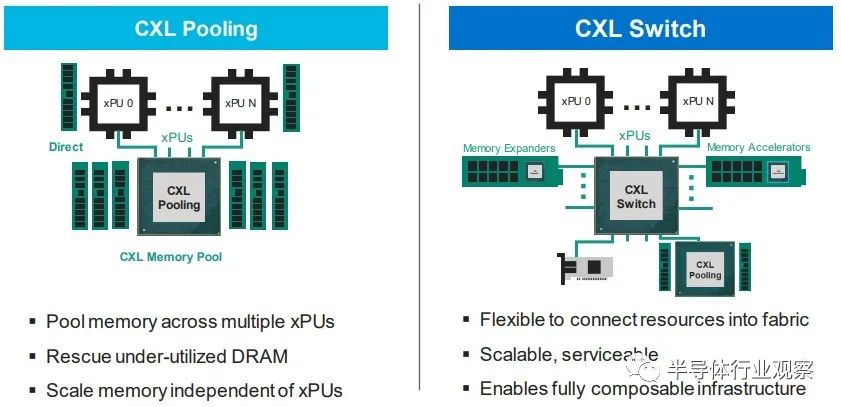
在 Marvell 的完整愿景中,有時 XPU 上會有一些本地內存——X 是指定 CPU、GPU、DPU 等的變體——而 PCI-Express 上的 CXL ink將連接到內存模塊它已在其上集成計算以執行專門的功能——您可以打賭,Marvell 希望使用其定制處理器設計團隊來幫助超大規模、云構建者和其他任何擁有合理容量的人將計算放在內存上并將其鏈接到 XPU。Marvell 顯然也熱衷于使用它通過 Tanzanite 收購獲得的 CXL 控制器來創建具有原生 CXL 功能和可組合性的 SmartNIC 和 DPU。 然后,幾年后,正如我們多次談到的那樣,我們將在數據中心機架內獲得真正的可組合性,而不僅僅是 GPU 和通過 PCI-Express 工作的閃存。但跨越各種計算、內存和存儲。
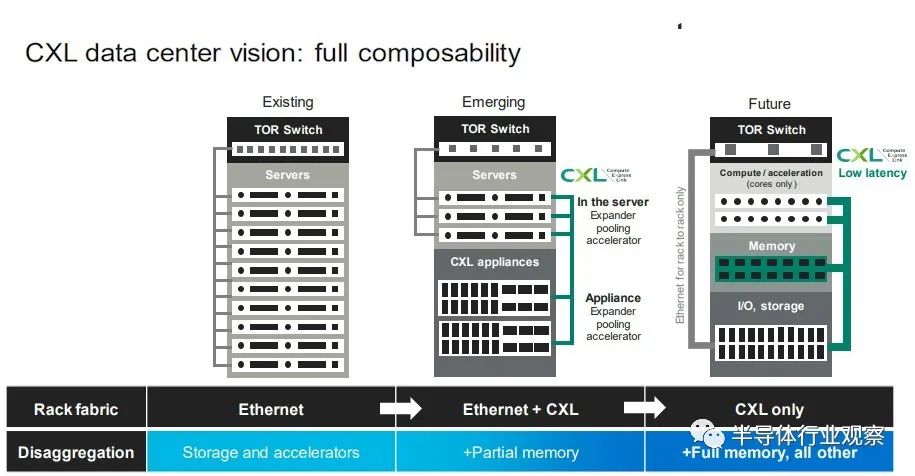
Marvell 已經擁有數據中心服務器和機架架構所需的計算(Octeon NPU 和定制的 ThunderX3 處理器)、DPU 和 SmartNIC、電光、重定時器和 SSD 控制器,現在 Tanzanite 為其提供了一種供應方式CXL 擴展器、CXL 光纖交換機和其他芯片共同構成了 Omura 所說的“數十億美元”的機會。 這是 Tanzanite 被創造出來追逐的機會,以下是它在 Marvell 交易之前設想的原型用例:

我們認為,只要 DRAM 內存的價格稍微下降一點,上述這些機器中的每一臺都會賣得很好。內存還是太貴了。
CXL 3.0標準發布,速度翻番
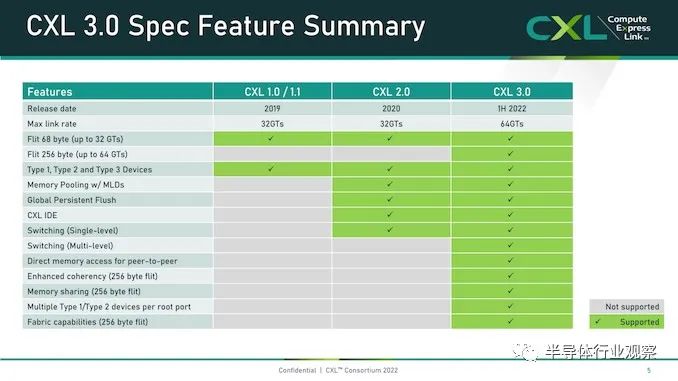
雖然在技術上仍然是新事物,但用于主機到設備連接的 Compute Express Link (CXL) 標準已迅速在服務器市場占據一席之地。 據報道,該標準旨在提供建立在現有 PCI-Express 標準之上更豐富的 I/O 功能集,其最顯著的是優勢在于設備之間的緩存一致性。從相關組織處獲悉,CXL的主要應用方向是把CPU連接到服務器中的加速器,但希望能夠在物理上仍然是通過 PCIe 接口上連接 DRAM 和非易失性存儲。 這是一個雄心勃勃但得到廣泛支持的路線圖,在短短三年內使,CXL 便成為事實上的先進設備互連標準,這就導致競爭對手標準 Gen-Z、CCIX 以及截至昨天的 OpenCAPI 都退出了競爭。 雖然 CXL 聯盟在贏得互連戰爭后快速取得勝利,但聯盟及其成員還有很多工作要做。假如在產品方面,第一批帶有 CXL 的 x86 CPU 幾乎沒有出貨——這很大程度上取決于你所說的英特爾 Sapphire Ridge 芯片所處的邊緣狀態。 來到功能方面,設備供應商要求獲得比比 CXL 的原始 1.x 版本更多的帶寬和更多的功能。贏得互連戰爭使 CXL 成為互連之王,但在此過程中,這意味著 CXL 需要能夠解決競爭對手標準設計的一些更復雜的用例。 為此,在本周的 2022 年閃存峰會上,CXL 聯盟在展會上宣布了 CXL 標準的下一個完整版本 CXL 3.0。這是繼2020 年底發布 2.0 標準并引入了內存池和 CXL 開關等功能之后的一次重要更新。 報道指出,CXL 3.0 側重于互連的幾個關鍵領域的重大改進。第一個是物理方面,CXL 將其每通道吞吐量翻了一番,達到 64 GT/秒。同時,在邏輯方面,CXL 3.0 大大擴展了標準的邏輯能力,允許復雜的連接拓撲和結構,以及在一組 CXL 設備內更靈活的內存共享和內存訪問模式。
CXL 3.0:建立在 PCI-Express 6.0 之上
首先,我們從物理方面開始了解新版本的CXL 技術。資料顯示,新版本的標準提供了期待已久的更新,以合并 PCIe 6.0。CXL 之前的兩個版本,也就是 1.x 和 2.0,都是建立在 PCIe 5.0 之上的,所以這是自 2019 年 CXL 推出以來,其物理層的首次更新。 PCIe 6.0本身是對 PCI-Express 標準內部工作的重大更新,它再次將總線上的可用帶寬量翻了一番,達到 64 GT/秒,對于 x16 卡來說,這可以達到 128GB/秒。據報道,這個速度是通過將 PCIe 從使用二進制 (NRZ) 信號轉換為四態 (PAM4) 信號并結合固定數據包 (FLIT) 接口來實現的。借助這種方法,能使其速度翻倍而不會在更高頻率下運行的缺點。由于 CXL 反過來構建在 PCIe 之上,這意味著需要更新標準以應對 PCIe 的操作變化。

CXL 3.0 的最終結果是它繼承了 PCIe 6.0 的全部帶寬改進——以及前向糾錯 (FEC) 等所有有趣的東西——與 CXL 2.0 相比,CXL 的總帶寬增加了一倍。 值得注意的是,根據 CXL 聯盟的說法,他們能夠在不增加延遲的情況下完成所有這些工作。這是 PCI-SIG 在設計 PCIe 6.0 時面臨的挑戰之一,因為必要的糾錯會增加進程的延遲,導致 PCI-SIG 使用低延遲形式的 FEC。盡管如此,CXL 3.0 在嘗試減少延遲方面更進了一步,導致 3.0 具有與 CXL 1.x/2.0 相同的延遲。 除了基本的 PCIe .60 更新之外,CXL 聯盟還調整了他們的 FLIT size。CXL 1.x/2.0 使用了一個相對較小的 68 字節數據包,而 CXL 3.0 將其增加到了 256 字節。更大的 FLIT size是 CXL 3.0 的關鍵通信變化之一,因為它在header FLIT 中為標準提供了更多位,而這些位又是啟用 3.0 標準引入的復雜拓撲和結構所必需的。盡管作為一項附加功能,CXL 3.0 還提供了一種低延遲“變體”FLIT 模式,該模式將 CRC 分解為 128 字節“sub-FLIT granular transfers”,旨在減輕物理層中的存儲和轉發開銷. 值得注意的是,256 字節的 FLIT 大小使 CXL 3.0 與 PCIe 6.0 保持一致,后者本身使用 256 字節的 FLIT。和它的底層物理層一樣,CXL 不僅支持在新的 64 GT/秒傳輸速率下使用大型 FLIT,而且還支持 32、16 和 8 GT/秒,本質上允許新協議功能以更慢的傳輸速率使用. 最后,CXL 3.0 完全向后兼容早期版本的 CXL。因此,設備和主機可以根據需要降級以匹配硬件鏈的其余部分,盡管在此過程中會失去更新的功能和速度。
CXL 3.0 特性:增強的一致性、內存共享、多級拓撲和結構
除了進一步提高整體 I/O 帶寬外,上述針對 CXL 的協議更改也已實施,以支持標準內的新功能。CXL 1.x 是作為(相對)簡單的主機到設備標準而誕生的,但現在 CXL 是服務器的主要設備互連協議,它需要擴展其功能以適應更高級的設備,并最終適應更大的用例。 從特性級別開始,這里最大的新聞是該標準更新了具有內存的設備的緩存一致性協議(Type-2 和 Type-3,用 CXL 的說法)。正如 CXL 所說,增強的一致性允許設備支持使主機緩存的數據無效。這取代了 CXL 早期版本中使用的基于偏差的一致性方法,為了保持簡潔,保持一致性不是通過共享內存空間的控制,而是通過讓主機或設備負責控制訪問。相比之下,Back invalidation更接近真正的共享/對稱方法,允許 CXL 設備在設備進行更改時通知主機。 包含Back invalidation也為設備之間的新對等連接打開了大門。在 CXL 3.0 中,設備現在可以直接訪問彼此的內存,而無需通過主機,使用增強的一致性語義來通知彼此它們的狀態。從延遲的角度來看,跳過主機不僅速度更快,而且在涉及交換機的設置中,這意味著設備不會通過請求占用寶貴的主機到交換機帶寬。雖然我們稍后會進入拓撲,但這些變化與更大的拓撲密切相關,允許將設備組織成虛擬層次結構,其中層次結構中的所有設備共享一個一致性域。
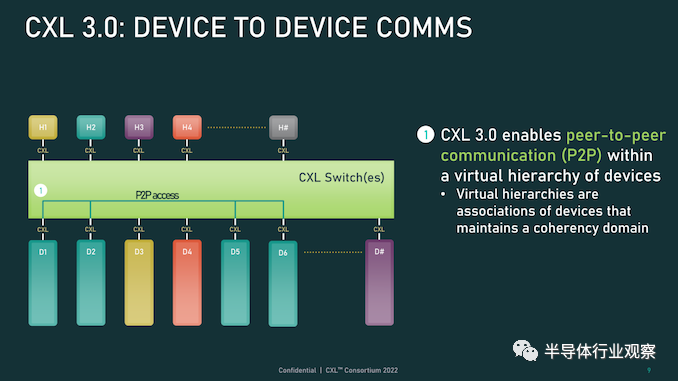
除了調整緩存功能外,CXL 3.0 還對主機和設備之間的內存共享進行了一些重要更新。CXL 2.0 提供了內存池,其中多個主機可以訪問設備的內存,但必須為每個主機分配自己的專用內存段,而 CXL 3.0 引入了真正的內存共享。利用新的增強一致性語義,多個主機可以擁有一個共享段的一致副本,如果設備級別發生變化,可以使用反向失效來保持所有主機同步。
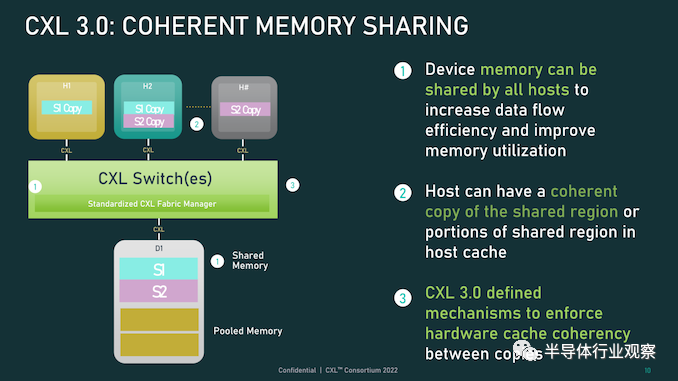
然而,應該注意的是,這并不能完全取代池化。在某些用例中,CXL 2.0 風格的池更可取(保持一致性需要權衡取舍),并且 CXL 3.0 支持根據需要混合和匹配這兩種模式。 CXL 3.0 進一步增強了這種改進的主機設備功能,消除了之前對可以連接到單個 CXL 根端口下游的 Type-1/Type-2 設備數量的限制。 CXL 2.0 只允許這些處理設備中的一個出現在根端口的下游,而 CXL 3.0 則完全解除了這些限制。現在,CXL 根端口可以支持 Type-1/2/3 設備的完全混合匹配設置,具體取決于系統構建者的目標。值得注意的是,這意味著能夠將多個加速器連接到單個交換機,提高密度(每個主機更多的加速器),并使新的點對點傳輸功能更加有用。
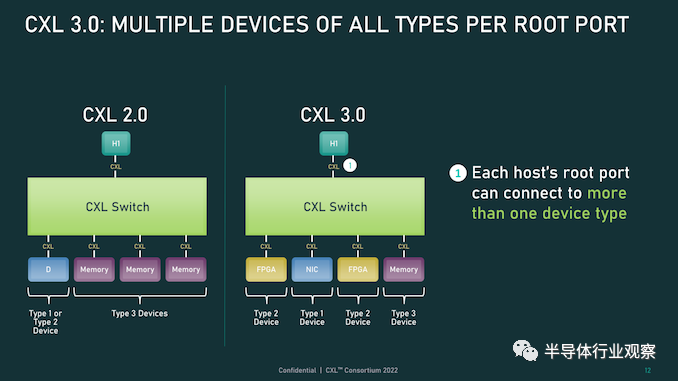
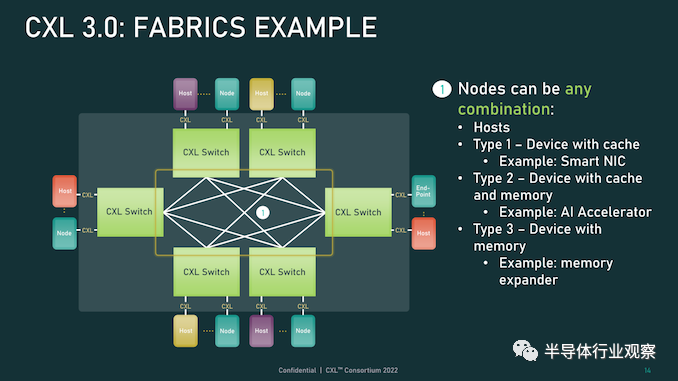
CXL 3.0 的另一大特性變化是支持多級切換。這建立在 CXL 2.0 的基礎上,該版本引入了對 CXL 協議交換機的支持,但僅允許單個交換機駐留在主機及其設備之間。另一方面,多級交換允許多層交換機——也就是說,交換機饋入其他交換機——這極大地增加了所支持的網絡拓撲的種類和復雜性。
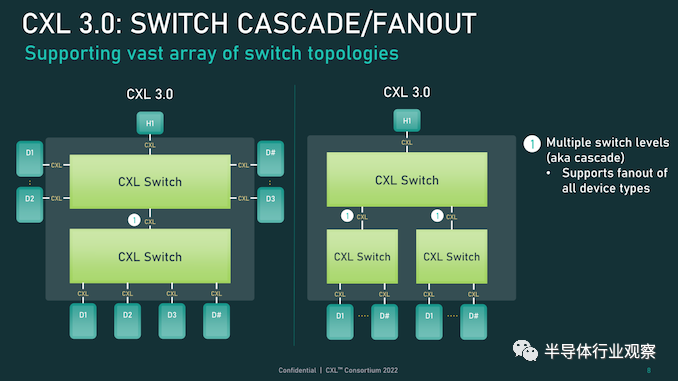
即使只有兩層交換機,這也足以實現非樹狀拓撲結構,例如環形、網狀結構和其他結構設置。并且各個節點可以是主機或設備,對類型沒有任何限制。
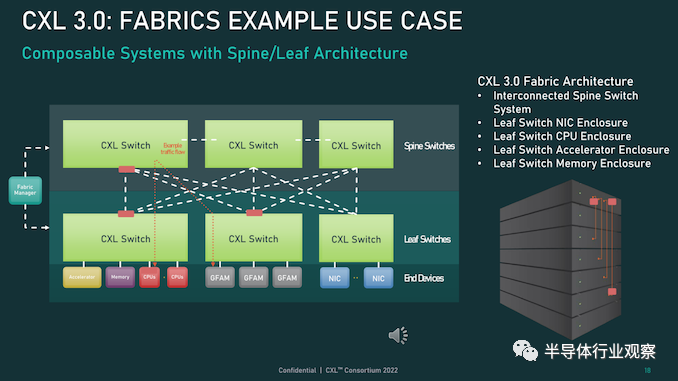
同時,對于真正奇特的設置,CXL 3.0 甚至可以支持主干/葉架構,其中流量通過頂級主干節點路由,其唯一工作是將流量進一步路由回包含實際主機的低級(葉)節點/設備。
最后,所有這些新的內存和拓撲/結構功能都可以在 CXL 聯盟所稱的全球結構附加內存 (GFAM) 中一起使用。簡而言之,GFAM 通過進一步分解來自給定主機的內存,將 CXL 的內存擴展板(Type-3)理念提升到了一個新的水平。在這方面,GFAM 設備在功能上是它自己的共享內存池,主機和設備可以根據需要訪問它。GFAM 設備可以同時包含易失性和非易失性存儲器,例如 DRAM 和閃存。
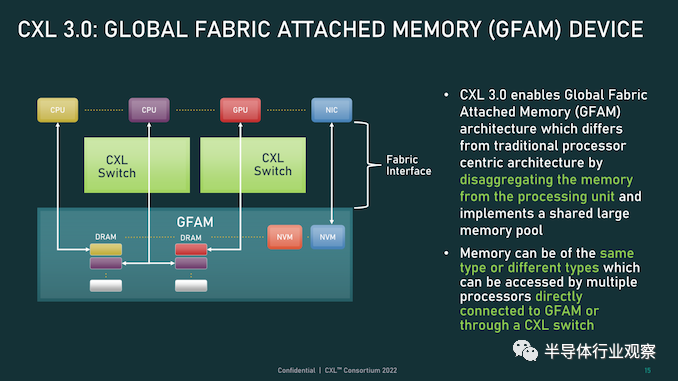
反過來,GFAM 將使 CXL 能夠有效地支持大型多節點設置。正如 Consortium 在他們的一個示例中使用的那樣,GFAM 允許 CXL 3.0 為在 CXL 連接的機器集群上實施 MapReduce 提供必要的性能和效率。當然,MapReduce 是一種非常流行的用于加速器的算法,因此擴展 CXL 以更好地處理集群加速器常見的工作負載是標準的下一步明顯(并且可以說是必要的)。盡管它確實模糊了 CXL 等本地互連的結束位置和 InfiniBand 等網絡互連的開始位置之間的界限。 最終,最大的區別可能是支持的節點數量。CXL 的尋址機制,聯盟稱之為基于端口的路由 (PBR),最多支持 2^ 12(4096) 個設備。因此,CXL 設置只能擴展至此,尤其是當加速器、附加內存和其他設備迅速占用端口時。 總結一下,完整的 CXL 3.0 標準將于今天,即 FMS 2022 的第一天向公眾發布。官方上,該聯盟沒有提供任何關于何時期望 CXL 3.0 出現在設備中的指導——這取決于設備制造商- 但有理由說它不會馬上。隨著 CXL 1.1 主機剛剛交付——更不用說 CXL 2.0 主機——CXL 的實際產品化比標準落后幾年,這對于這些大型行業互連標準來說是典型的。

審核編輯 :李倩
-
處理器
+關注
關注
68文章
19165瀏覽量
229124 -
控制器
+關注
關注
112文章
16203瀏覽量
177404 -
內存
+關注
關注
8文章
3002瀏覽量
73883
原文標題:系統內存的未來,屬于CXL
文章出處:【微信號:芯長征科技,微信公眾號:芯長征科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
內存擴展CXL加速發展,繁榮AI存儲

拓展AI數據中心內存,第二代AMD Versal Premium系列自適應SoC,首發支持CXL 3.1、 PCIe Gen6

研華科技推出SQRAM CXL 2.0 Type 3內存模塊SQR-CX5N
如何利用CXL協議實現高效能的計算架構
業界首創512GB CXL AIC內存擴展卡,江波龍革新AI與高性能計算領域內存技術

FORESEE CXL 2.0內存拓展模塊

利用CXL技術重構基于RDMA的內存解耦合
什么是CXL技術?CXL的三種模式、類型、應用
三星與Red Hat成功驗證CXL內存在真實用戶環境中的運行
三星電子與紅帽成功驗證CXL內存操作
三星與紅帽聯合驗證CXL內存與最新操作系統的兼容性
佰維發布CXL 2.0 DRAM,賦能高性能計算
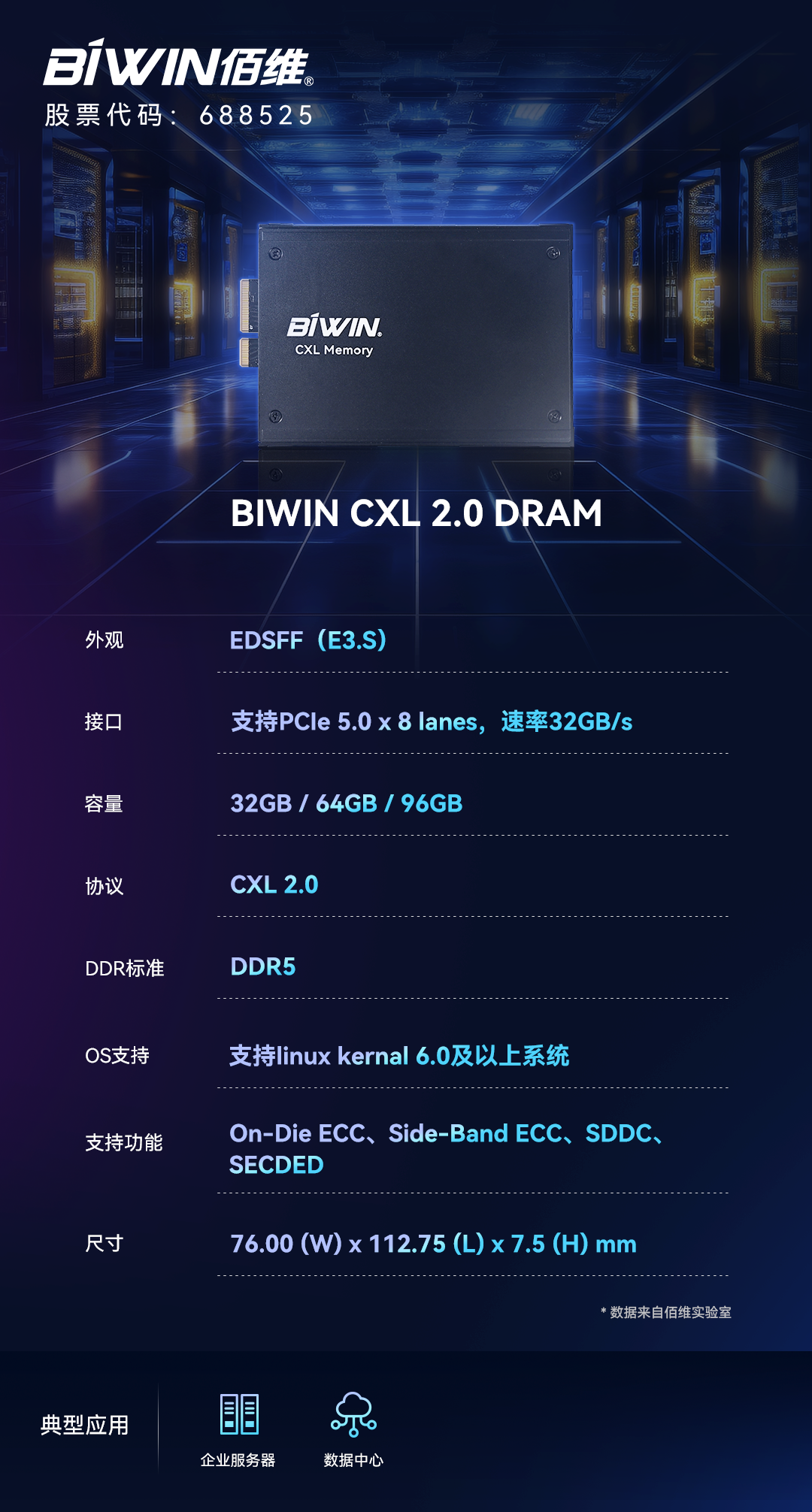
佰維公司成功推出支持CXL 2.0規范的CXL DRAM內存擴展模塊
三星攜手紅帽在真實用戶環境下驗證CXL內存技術
佰維發布CXL 2.0 DRAM,賦能高性能計算





 工商網監
工商網監
評論