 FS-NER 的關鍵挑戰
FS-NER 的關鍵挑戰
小樣本 NER 需要從很少的實例和外部資源中獲取有效信息。本文提出了一個自描述機制,可以通過使用全局概念集(universal concept set)描述實體類型(types)和提及(mentions)來有效利用實例和外部資源的知識。
具體來講,我們設計了自描述網絡(SDNet),一個 Seq2Seq 的生成模型可以使用概念來全局地描述提及,自動將新的實體類型映射到概念中,然后對實體進行識別。SDNet 在一個大規模語料中預訓練,在 8 個 benchmarks 上進行實驗,實驗結果表明,SDNet 取得了很有競爭力的效果,并且在 6 個 benchmarks 上達到了 SOTA。
Intro
小樣本 NER(FS-NER)的目標是通過很少的樣本來識別出屬于新實體類的實體提及。FS-NER 面臨兩個主要的挑戰:
1. limited information challenge:少量樣本所包含的語義信息有限。
2. knowledge mismatch challenge:使用外部的知識直接與新任務進行匹配可能有各種偏差甚至產生沖突。
具體來說,在 Wikipedia,OntoNotes 和 WNUT17 中,“America” 的標注分別為 “geographic entity”、“GPE” 和 “location”。因此,如何有效利用少量數據并且準確遷移外部知識是 FS-NER 的關鍵挑戰。
為此,作者提出了自描述機制,其主要思想是將所有的實體類型描述為同一個概念集,類型和概念之間的映射是可以建模和學習的,這種方式可以解決知識不匹配的問題。同時,因為這種映射是全局的,對于少量新實體類樣本來說,只需要將這部分數據用來構建新實體類型和概念之間的映射,也解決了信息不足的問題。
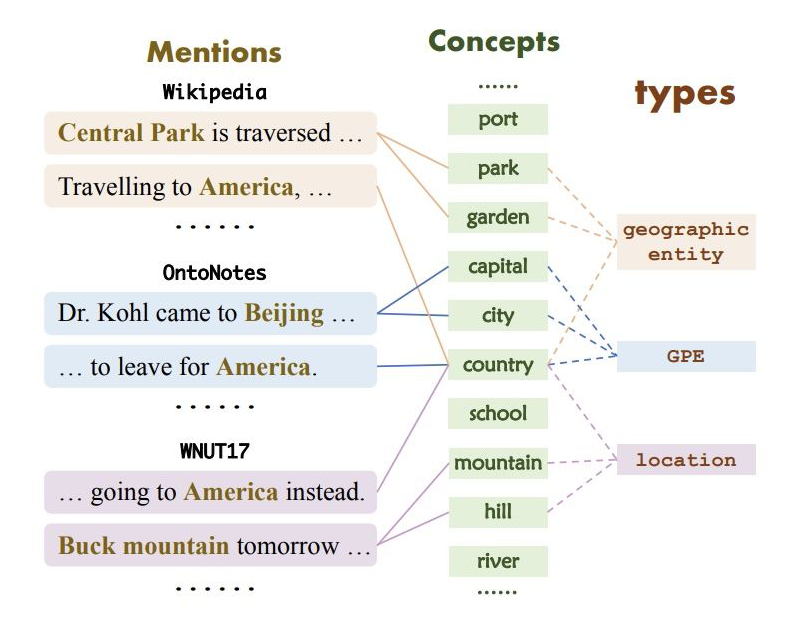
▲ 實體類型、提及和概念映射示例
基于以上想法,我們提出了一個自描述網絡——SDNet,是一個 Seq2Seq 的生成模型,可以全局的使用概念來描述提及,自動將新實體類型映射到概念集,并且能夠識別實體。
具體來講,為了獲取一個提及的語義,SDNet 生成一個全局的概念集作為描述。例如:生成 {capital,city} 對于句子“Dr。Kohl came to [Beijing].”。為了映射實體類型和概念,SDNet 將屬于同一實體類型的提及映射到這些提及所對應的概念中。例如:對于 [Beijing] 和 [America] 兩個屬于 GPE 類型的提及,將 GPE 這一類型映射到 {country,capital,city}。
對于實體識別,SDNet 使用 concept-enriched 的前綴 prompt 的方式直接在一個句子中生成出所有的實體。例如:在 “France is beautiful.” 這句話中通過生成出 “France is GPE.” 來識別實體,構建一個前綴 prompt“[EG] GPE:{country,capital,city}”。因為概念是全局的,所以我們可以在 SDNet上使用大規模語料庫預訓練,并且可以很容易的使用 web 資源,具體來說,我們通過使用 wikipedia 錨詞到 wikidata items 之間的連接構建了包含 56M 個句子,31K 個概念的數據集。
本文的主要貢獻總結如下:
1. 我們提出了自描述機制來解決 FS-NER 問題,可以有效解決信息限制和知識不匹配的挑戰通過使用一個全局的概念集描述實體類型和提及;
2. 我們提出 SDNet,一個可以全局的使用概念描述提及,自動映射新實體類型和概念并且識別實體的 Seq2Seq 生成模型;
3. 我們在一個大規模的公開數據集上預訓練 SDNet,對 FS-NER 提供了全局信息并且對未來 NER 的研究有益。
Method
模型整體流程包含兩部分:
1. Mention describing:生成提及的概念描述;
2. Entity generation:生成屬于新實體類的提及。
模型結構圖如下:
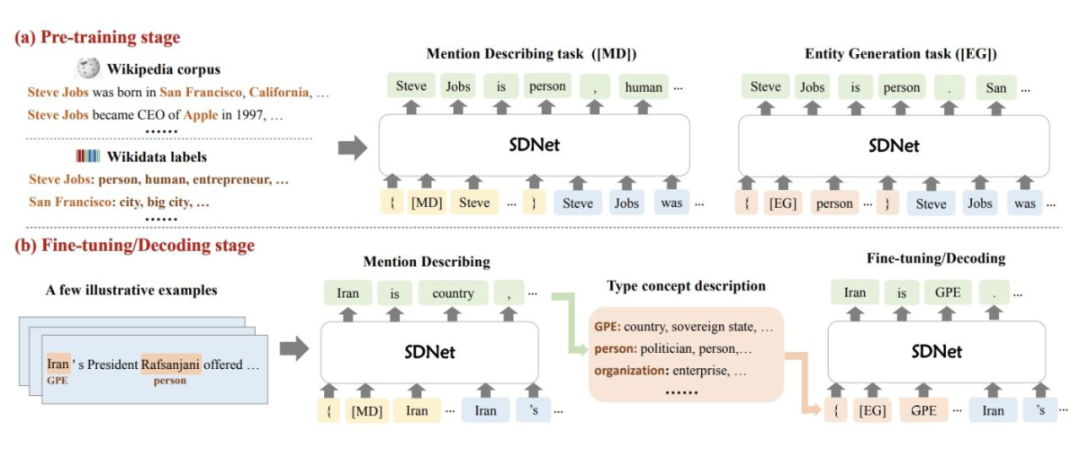
▲ 模型結構
2.1 Self-describing Networks
SDNet 可以完成兩個生成任務,就是上文提到的 mention describing 和 entity generation,分別使用了不同的提示 P 并且生成不同的輸出 Y。具體形式如下圖所示:
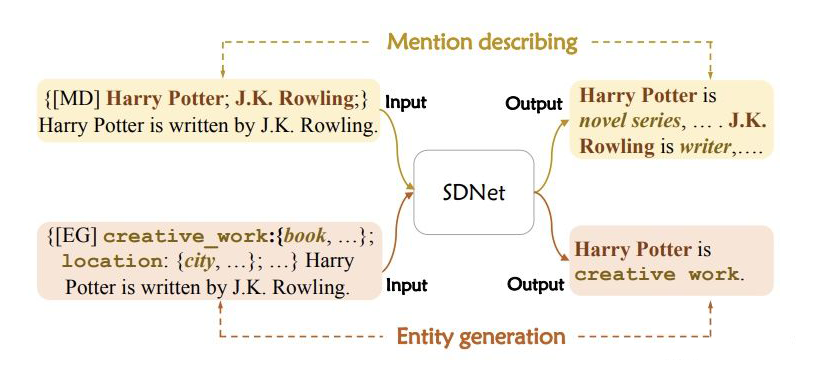
▲mention describing和entity generation示例
對于 mention describing,提示模板由一個標識 [MD] 和一個目標實體提及組成;對于 entity generation,提示模板由標識 [EG] 和一個新實體類型和其對應的描述組成。上述兩個過程是一組對稱的過程:一個是給定實體提及,獲取其概念描述;另一個是識別包含特定概念的實體。
2.2 Entity Recognition via Entity Generation
具體來講,entity generation 的輸入提示為
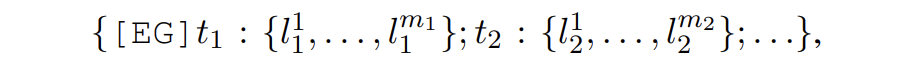
其中 t 是實體類型,l 是實體類型對應的概念。SDNet 會生成如下形式的輸出:
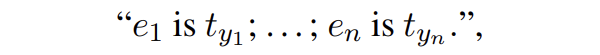
這里就相當于獲取了每個實體對應的實體類型:
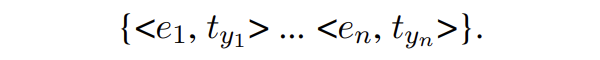
可以看出,SDNet 可以實時進行控制,通過使用不同的 prompts。例如:給一個句子 “Harry Potter is written by J.K. Rowling.”,如果想要識別 person 類,提示模板采用 {[EG] person: {actor, writer}},如果想要識別 creative work 類,則模板采用 {[EG] creative work: {book, music}} 即可。
2.3 Type Description Construction via Mention Describing
Mention Describing
給定一個句子 X,包含新類的實體提及{e1, e2, ...},使用的提示模板為:
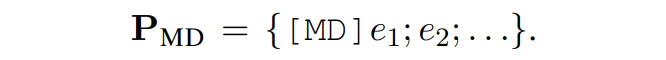
SDNet 會產生如下形式的輸出:
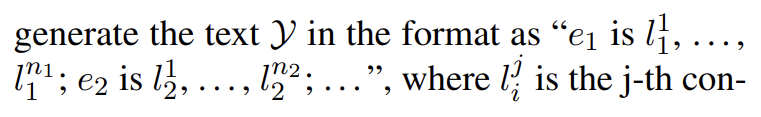
這一步會生成每個實體提及的概念。
Type Description Construction
SDNet 會將屬于同一實體類型的提及生成的概念,融合成一個概念集合 C,將這個概念集合 C 作為類型 t 的描述。
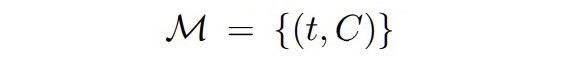
Filtering Strategy
由于下游任務含有大量新的實體類型,SDNet 對于其中某些類型沒有足夠的知識來描述,如果強制進行生成會導致一些不準確的描述。本文提出一個過濾策略解決這個問題。具體來講,SDNet 會對那些不確定的樣本生成 other 這一描述。我們會計算生成 other 描述的概率,如果對于一個樣本生成的 other 超過 0.5,則會去除掉類型描述,在 P_EG 模板中直接使用類型。
Learning
接下來說明 SDNet 如何進行預訓練和微調。
3.1 SDNet Pre-training
本文使用 wikipedia 和 wikidata 數據來構建數據集。
Entity Mention Collection
對于 SDNet 的預訓練,我們需要收集
1. 首先,從 wikidata 中構建實體字典。我們將 wikidata 中每個 item 作為實體并且使用 “instance of”、“subclass of” 和 “occupation” 三個屬性值作為其對應的實體類型。我們使用所有的實體類型,除去那些實例少于 5 個的。對于那些類型名長度超過 3 個 token 的,采用其 head word 作為最終的實體類型來簡化。通過這種方式,我們收集了 31K 個類型;
2. 其次我們使用其在 wikipedia 中的錨文本和其條目頁面的前 3 個頻繁出現的名詞短語來收集每個實體的提及。然后對于每一個提及,通過將其連接到 wikidata 中 item 的類型來識別實體類型。如果 wikidata 的 item 沒有實體類型,則給其分配 other。對于每一個百科頁,將文本分割成句子,并且將沒有實體的句子過濾掉。最終我們構建出了含有 56M 個實例的數據集。
Type Description Building
文本將上述獲取的實體類型作為概念,對于給定的一個實體類型,使用與其共同出現的實體類型作為其描述。舉例來說,Person 類可以描述為 {businessman, CEO, musician, pianist} 通過以下兩個實例 “Steve Jobs:{person, businessman, CEO}” 和 “Beethoven:{person, musician, pianist}”。通過這種方式生成每個實體類型的描述概念集。因為有些類型的概念集特別大,因此本文為每個實體隨機采樣不超過 10 個概念作為概念集合。
Pretraining via Mention Describing and Entity Generation
給定一個句子 X 以及它的提及-類型元組:
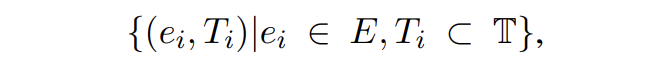
我們從 E 中采樣一些目標提及 E' 輸入到模板 P_MD 中生成它的對應概念。對于實體生成,從正類型和負類型中采樣類型集輸入到模板 P_EG 中生成提及對應的實體類型。模型損失如下:
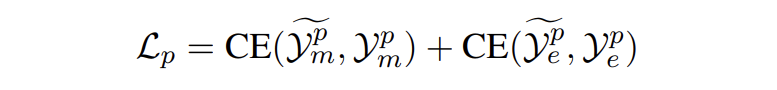
▲ 交叉熵損失
3.2 Entity Recognition Fine-tuning
微調階段給定一個樣本三元組
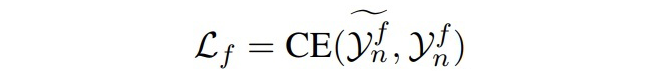
▲EG過程的損失
Experiments
4.1 主實驗
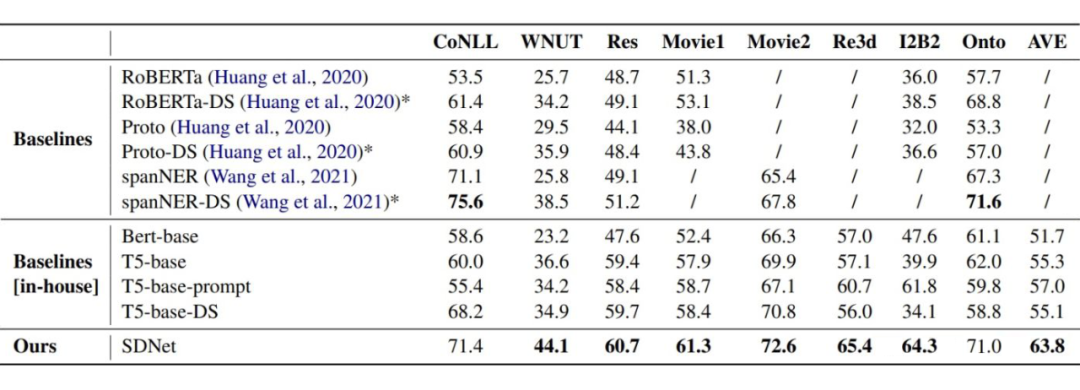
▲ 主實驗,評價指標采用 micro-F1
實驗結果可以看出,在 6 個 benchmark 中 SDNet 達到了 SOTA。作者也分析了在 Res 這一 benchmark 上與 T5 表現接近的原因,因為 Res 與 wikipedia 數據有巨大的領域漂移,導致模型經常生成 other。
4.2 樣本數的影響
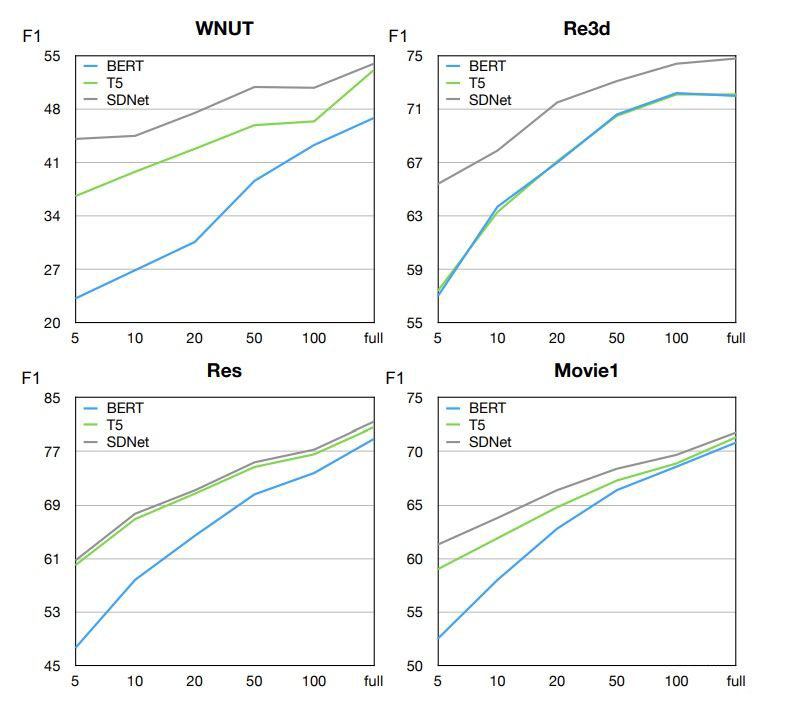
▲ 樣本數的影響
實驗結果可以看出,SDNet 在任何樣本數設置下都有更好的表現。作者認為,基于生成的模型要比基于分類的模型有更好的表現,因為生成模型可以利用標簽的 utterance 更有效的獲取實體類型的語義。
4.3 消融實驗
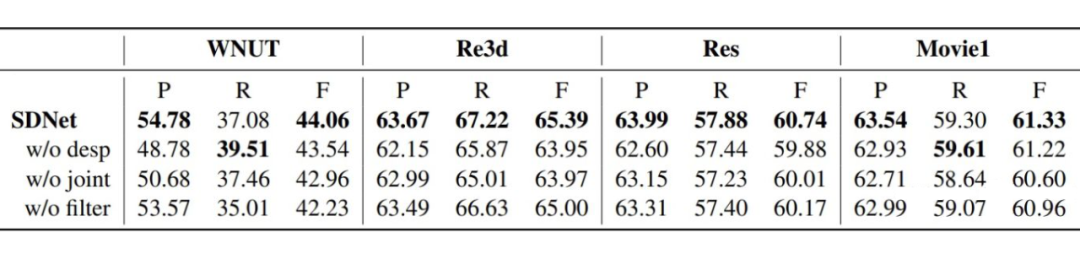
(1)w/o desp:在EG過程直接使用實體類型,而不加入全局的概念描述,例如:
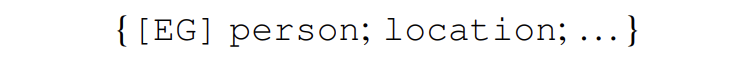
(2)w/o joint:將 MD 和 EG 過程分為兩個單獨的過程分開訓練。
(3)w/o filter:不進行過濾策略。
4.4 零樣本實驗
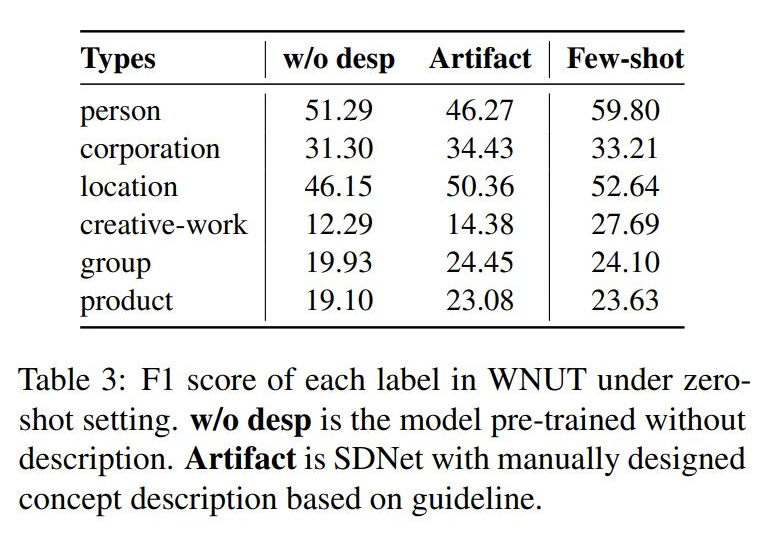
4.4 EG模板的影響

總結
本文一大優點是為 FS-NER 引用外部知識提供了一個新的思路,本文的預訓練模型也可以直接做遷移。
不足之處在于在與 Wikipedia 之間存在巨大的領域漂移的情況下,模型會生成大量 other 從而嚴重影響效果。在維基百科中可能存在大量人名地名等常見實體,而在一些實際問題中,可能存在很多不常見的實體,模型可能很難對這些實體做到很好的描述。
-
數據
+關注
關注
8文章
6898瀏覽量
88839 -
模型
+關注
關注
1文章
3174瀏覽量
48718
原文標題:ACL2022 | 自描述網絡的小樣本命名實體識別
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
光學傳感器的系統NER模擬

一些NER的英文數據集推薦
一種單獨適配于NER的數據增強方法
如何解決NER覆蓋和不連續問題
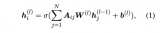







 工商網監
工商網監
評論